小白学 Python 爬虫(10):Session 和 Cookies

人生苦短,我用 Python
前文传送门:
小白学 Python 爬虫(2):前置准备(一)基本类库的安装
小白学 Python 爬虫(3):前置准备(二)Linux基础入门
小白学 Python 爬虫(4):前置准备(三)Docker基础入门
小白学 Python 爬虫(6):前置准备(五)爬虫框架的安装
引言
先说一个题外话,今天老司机翻车了,内容小编今天来不及写了,后面会整理下,分享给大家。
在介绍 Session 和 Cookies 之前,先介绍一个另外的概念 —— 静态网页和动态网页。
静态网页
静态网页就是我们上一篇写的那种 html 页面,后缀为 .html 的这种文件,直接部署到或者是放到某个 web 容器上,就可以在浏览器通过链接直接访问到了,常用的 web 容器有 Nginx 、 Apache 、 Tomcat 、Weblogic 、 Jboss 、 Resin 等等,很多很多。
如果说要举例子的话那么小编的个人博客站:https://www.geekdigging.com/ 就是一个纯粹的静态网页。
这种网页的内容是通过纯粹的 HTML 代码来书写,包括一些资源文件:图片、视频等内容的引入都是使用 HTML 标签来完成的。
它的好处当然是加载速度快,编写简单,访问的时候对 web 容器基本上不会产生什么压力。但是缺点也很明显,可维护性比较差,不能根据参数动态的显示内容等等。
有需求就会有发展么,这时动态网页就应运而生了。
动态网页
我们先不说动态网页的概念,先说说有哪些网站是由动态网页来构建的。大家常用的某宝、某东、拼夕夕等网站都是由动态网页组成的。
动态网页可以解析 URL 中的参数,或者是关联数据库中的数据,显示不同的网页内容。
现在各位同学访问的网站大多数都是动态网站,它们不再简简单单是由 HTML 堆砌而成,可能是由 JSP 、 PHP 等语言编写的,当然,现在很多由前端框架编写而成的网页小编这里也归属为动态网页。
说到动态网页,各位同学可能使用频率最高的一个功能是登录,像各种电商类网站,肯定是登录了以后才能下单买东西。那么,问题来了,后面的服务端是如何知道当前这个人已经登录了呢?
HTTP/1.1
现在大多数的网站使用的协议都是 HTTP/1.1 ,而 HTTP/1.1 最大的特点就是无状态、无连接的。
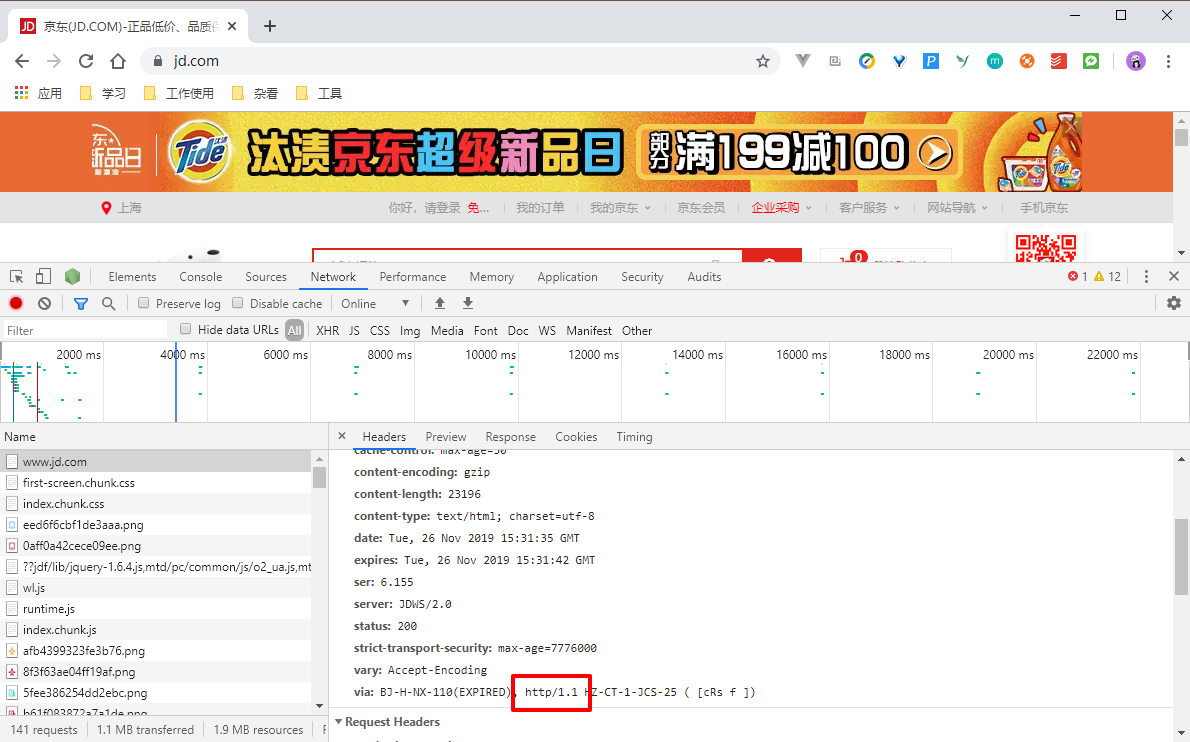
无状态就是指 HTTP 协议对于请求的发送处理是没有记忆功能的,也就是说每次 HTTP 请求到达服务端,服务端都不知道当前的客户端(浏览器)到底是一个什么状态。客户端向服务端发送请求后,服务端处理这个请求,然后将内容响应回客户端,完成一次交互,这个过程是完全相互独立的,服务端不会记录前后的状态变化,也就是缺少状态记录。
这就产生了上面的问题,服务端如何知道当前在浏览器面前操作的这个人是谁?
其实,在用户做登录操作的时候,服务端会下发一个类似于 token 凭证的东西返回至客户端(浏览器),有了这个凭证,才能保持登录状态。
那么这个凭证是什么?
这就是本篇文章要解释的核心内容,Session 和 Cookies 了。
Session 是会话的意思,会话是产生在服务端的,用来保存当前用户的会话信息,而 Cookies 是保存在客户端(浏览器),有了 Cookie 以后,客户端(浏览器)再次访问服务端的时候,会将这个 Cookie 带上,这时,服务端可以通过 Cookie 来识别本次请求到底是谁在访问。
可以简单理解为 Cookies 中保存了登录凭证,我们只要持有这个凭证,就可以在服务端保持一个登录状态。
在爬虫中,有时候遇到需要登录才能访问的网页,只需要在登录后获取了 Cookies ,在下次访问的时候将登录后获取到的 Cookies 放在请求头中,这时,服务端就会认为我们的爬虫是一个正常登录用户。
Session 保持
那么,Cookies 是如何保持会话状态的呢?
在客户端(浏览器)第一次请求服务端的时候,服务端会返回一个请求头中带有 Set-Cookie 字段的响应给客户端(浏览器),用来标记是哪一个用户,客户端(浏览器)会把这个 Cookies 给保存起来。
我们来使用工具 PostMan 来访问下某东的登录页,看下返回的响应头:
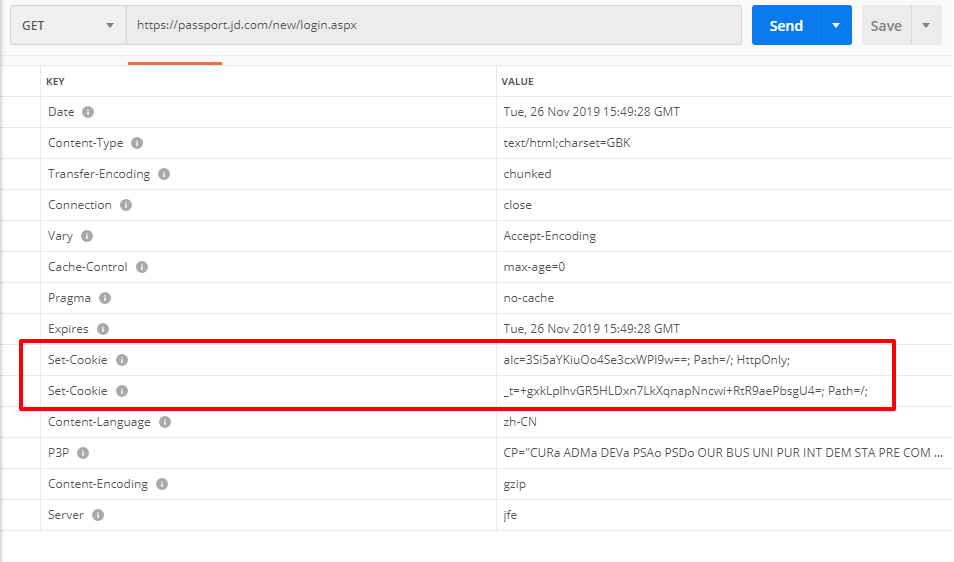
当我们输入好用户名和密码时,客户端会将这个 Cookies 放在请求头一起发送给服务端,这时,服务端就知道是谁在进行登录操作,并且可以判断这个人输入的用户名和密码对不对,如果输入正确,则在服务端的 Session 记录一下这个人已经登录成功了,下次再请求的时候这个人就是登录状态了。
如果客户端传给服务端的 Cookies 是无效的,或者这个 Cookies 根本不是由这个服务端下发的,或者这个 Cookies 已经过期了,那么接下里的请求将不再能访问需要登录后才能访问的页面。
所以, Session 和 Cookies 之间是需要相互配合的,一个在服务端,一个在客户端。
Cookies
我们还是打开某东的网站,看下这些 Cookies到底有哪些内容:
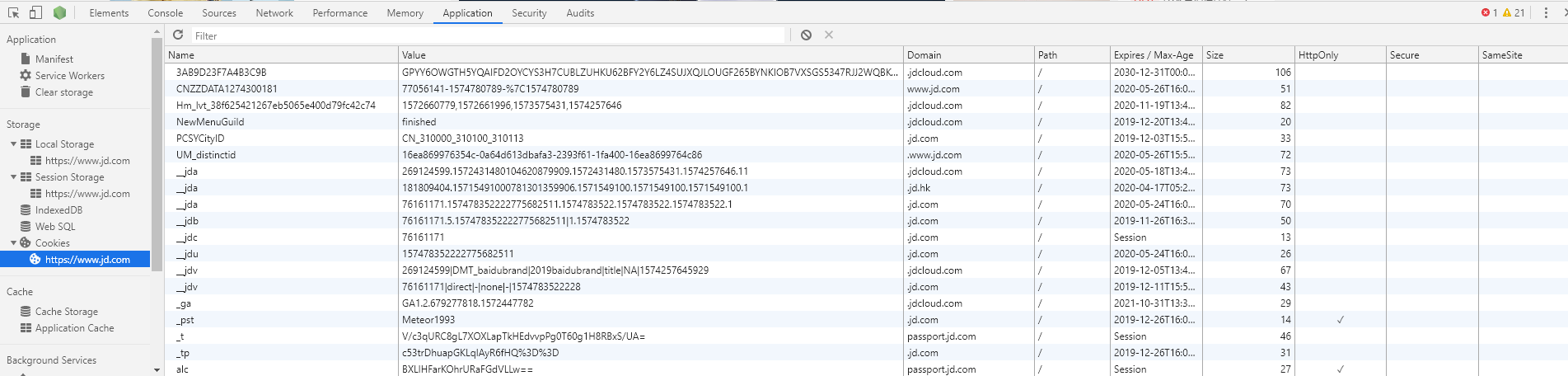
具体操作方式还是在 Chrome 中按 F12 打开开发者工具,选择 Application 标签,点开 Cookies 这一栏。
- Name:这个是 Cookie 的名字。一旦创建,该名称便不可更改。
- Value:这个是 Cookie 的值。
- Domain:这个是可以访问该 Cookie 的域名。例如,如果设置为 .jd.com ,则所有以 jd.com ,结尾的域名都可以访问该Cookie。
- Max Age:Cookie 失效的时间,单位为秒,也常和 Expires 一起使用。 Max Age 如果为正数,则在 Max Age 秒之后失效,如果为负数,则关闭浏览器时 Cookie 即失效,浏览器也不会保存该 Cookie 。
- Path:Cookie 的使用路径。如果设置为 /path/ ,则只有路径为 /path/ 的页面可以访问该 Cookie 。如果设置为 / ,则本域名下的所有页面都可以访问该 Cookie 。
- Size:Cookie 的大小。
- HTTPOnly:如果此项打勾,那么通过 JS 脚本将无法读取到 Cookie 信息,这样能有效的防止 XSS 攻击,窃取 Cookie 内容,可以增加 Cookie 的安全性。
- Secure:如果此项打勾,那么这个 Cookie 只能用 HTTPS 协议发送给服务器,用 HTTP 协议是不发送的。
那么有的网站为什么这次关闭了,下次打开的时候还是登录状态呢?
这就要说到 Cookie 的持久化了,其实也不能说是持久化,就是 Cookie 失效的时间设置的长一点,比如直接设置到 2099 年失效,这样,在浏览器关闭后,这个 Cookie 是会保存在我们的硬盘中的,下次打开浏览器,会再从我们的硬盘中将这个 Cookie 读取出来,用来维持用户的会话状态。
第二个问题产生了,服务端的会话也会无限的维持下去么,当然不会,这就要在 Cookie 和 Session 上做文章了, Cookie 中可以使用加密的方式将用户名记录下来,在下次将 Cookies 读取出来由请求发送到服务端后,服务端悄悄的自己创建一个用户已经登录的会话,这样我们在客户端看起来就好像这个登录会话是一直保持的。
理解误区
当我们关闭浏览器的时候会自动销毁服务端的会话,这个是错误的,因为在关闭浏览器的时候,浏览器并不会额外的通知服务端说,我要关闭了,你把和我的会话销毁掉吧。
因为服务端的会话是保存在内存中的,虽然一个会话不会很大,但是架不住会话多啊,硬件毕竟是会有限制的,不能无限扩充下去的,所以在服务端设置会话的过期时间就非常有必要。
当然,有没有方式能让浏览器在关闭的时候同步的关闭服务端的会话,当然是可以的,我们可以通过脚本语言 JS 来监听浏览器关闭的动作,当浏览器触发关闭动作的时候,由 JS 像服务端发起一个请求来通知服务端销毁会话。
由于不同的浏览器对 JS 事件的实现机制不一致,不一定保证 JS 能监听到浏览器关闭的动作,所以现在常用的方式还是在服务端自己设置会话的过期时间。
参考
https://baike.baidu.com/item/cookie/1119
小白学 Python 爬虫(10):Session 和 Cookies的更多相关文章
- 小白学 Python 爬虫(11):urllib 基础使用(一)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(12):urllib 基础使用(二)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(13):urllib 基础使用(三)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(14):urllib 基础使用(四)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(15):urllib 基础使用(五)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(16):urllib 实战之爬取妹子图
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(17):Requests 基础使用
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(18):Requests 进阶操作
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(19):Xpath 基操
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- IntelliJ IDEA 配置Maven仓库
1. 下载Maven 官方地址:http://maven.apache.org/download.cgi 2. 修改本地仓库路径 3. 设置环境变量 MAVEN_HOME: E:\DevelopEnv ...
- Java HashSet对txt文本内容去重(统计小说用过的字或字数)
Java HashSet对txt文本内容去重(统计小说用过的字或字数) 基本思路: 1.字节流读需要去重的txt文本.(展示demo为当前workspace下名为utf-8.txt的文本) 2.对读取 ...
- oracle数据库锁表,什么SQL引起了锁表?ORACLE解锁的方法
--查询数据库锁表记录 select sess.sid, sess.serial#, lo.oracle_username, lo.os_user_name, ao.object_name, lo.l ...
- AtCoder Grand Contest 038E - Gachapon
\(\bf Description\) 一个 \(0\) 到 \(n-1\) 的随机数生成器,生成 \(i\) 的概率是 \(A_i/S\) ,其中 \(S=\sum_{i=0}^{n} A_i\) ...
- docker已运行容器添加或修改端口映射
# 不推荐方法:将原来的容器提交成镜像,然后利用新的建立的镜像重新建立一个带有端口映射的容器# 推荐方法:## 查看id 就是 容器的 hash_of_the_container 数值 docker ...
- Eclipse对Java项目打Jar包
在本Java项目中,如下图一所示,Java项目含有外部依赖Jar包 -- fastjson-1.2.29.jar 包. 在经历了多次的失败后,最后我终于使用 Eclipse 对 "Java ...
- 关于Pycharm的注册码
最近安装pycharm,需要注册码,我在网上搜索了许多,这里一一记录下来,供大家参考: 在License server里面尝试输入下面任一地址: http://elporfirio.com:1017 ...
- JavaWeb核心知识点
一:HTTP协议 一.概述 1. 概念:超文本传输协议 2. 作用:规范了客户端(浏览器)和服务器的数据交互格式 3. 特点 1. 简单快速:客户端向服务器请求服务时,仅通过键值对来传输请求方 ...
- RHEL7.2 安装Hadoop-2.8.2
创建三台虚拟机,IP地址为:192.168.169.101,192.168.169.102,192.168.169.103 将192.168.169.102为namenode,192.168.169. ...
- systemd单元文件
前面我们提到过systemd启动可以对相相互依赖的串行的服务,也是可以并行启动的.在systemd中使用单元替换init的脚本来进行系统初始化.这节将要介绍系统初始化中,作为systemd的最小单元, ...