oracle性能优化(项目中的一个sql优化的简单记录)
在项目中,写的sql主要以查询为主,但是数据量一大,就会突出sql性能优化的重要性。其实在数据量2000W以内,可以考虑索引,但超过2000W了,就要考虑分库分表这些了。本文主要记录在实际项目中,一个需要查询很慢的sql的优化过程,如果有更好的方案,请在下面留言交流。
很多文章都有关于sql优化的方法,这里就不一一陈述了。如果有需要可以查看博客:https://blog.csdn.net/linhaiyun_ytdx/article/details/79101122
SELECT T.YHBH,
(SELECT NAME FROM DIM_REGION WHERE CODE = SUBSTR(T.GDDWBM, 0, 4)) GDDWMC,
(SELECT NAME FROM DIM_REGION WHERE CODE = T.GDDWBM) FJMC,
T.DFNY,
T.YHMC,
T.YDDZ,
(SELECT NAME FROM DIM_ELECTRICITY_TYPE WHERE CODE = T.YHLBDM) YDLBMC
FROM (SELECT DISTINCT T.YHBH,
DECODE(T.GDDWBM,
NULL,
'',
DECODE(T.GDDWBM, '', '', T.GDDWBM)) AS GDDWBM,
T.BBNY AS DFNY,
T.YHLBDM AS YHLBDM,
T.YHMC,
T2.YDDZ
FROM V_TEMP_TABLE_JHCBHSTJ_HISTORY T, TMP_KH_YDKH T2
WHERE T.YHBH = T2.YHBH(+)
AND NOT EXISTS (SELECT 1
FROM DJHJSL_LSB_FZ_HISTORY B
WHERE B.BBNY = T.BBNY
AND B.YHBH = T.YHBH
AND B.GDDWBM = T.GDDWBM
AND B.YHLBDM = T.YHLBDM
AND B.ZDCBZHS <> '')
) T
WHERE SUBSTR(T.GDDWBM, 0, 4) = ''
AND T.DFNY = ''
这个是我的sql脚本。其实这个脚本一点都不复杂。其中V_TEMP_TABLE_JHCBHSTJ_HISTORY,DJHJSL_LSB_FZ_HISTORY每个月增加330万,目前有1960多万, TMP_KH_YDKH表有330多万。DIM_REGION 和DIM_ELECTRICITY_TYPE 是两个数据字典项表。
在没有索引的情况下,这个脚本执行需要30s,看到执行过程,现在都是全表扫描的。接下来开始优化。
1.修改脚本的查询,将外层的查询条件放到里面,减少数据量。
SELECT T.YHBH,
(SELECT NAME FROM DIM_REGION WHERE CODE = SUBSTR(T.GDDWBM, 0, 4)) GDDWMC,
(SELECT NAME FROM DIM_REGION WHERE CODE = T.GDDWBM) FJMC,
T.DFNY,
T.YHMC,
T.YDDZ,
(SELECT NAME FROM DIM_ELECTRICITY_TYPE WHERE CODE = T.YHLBDM) YDLBMC
FROM (SELECT DISTINCT T.YHBH,
DECODE(T.GDDWBM,
NULL,
'',
DECODE(T.GDDWBM, '', '', T.GDDWBM)) AS GDDWBM,
T.BBNY AS DFNY,
T.YHLBDM AS YHLBDM,
T.YHMC,
T2.YDDZ
FROM V_TEMP_TABLE_JHCBHSTJ_HISTORY T, TMP_KH_YDKH T2
WHERE T.YHBH = T2.YHBH(+)
AND NOT EXISTS (SELECT 1
FROM DJHJSL_LSB_FZ_HISTORY B
WHERE B.BBNY = T.BBNY
AND B.YHBH = T.YHBH
AND B.GDDWBM = T.GDDWBM
AND B.YHLBDM = T.YHLBDM
AND B.ZDCBZHS <> '')
AND SUBSTR(T.GDDWBM, 0, 4) = ''
AND T.BBNY = ''
) T
2.对三个表都建上索引
对V_TEMP_TABLE_JHCBHSTJ_HISTORY根据DFNY,SUBSTR(T.GDDWBM, 0, 4)建上联合索引。
CREATE INDEX IDX_TMP_JHCBHSTJ_HISTORY_UNION ON V_TEMP_TABLE_JHCBHSTJ_HISTORY(BBNY,SUBSTR(GDDWBM, 0, 4));
对TMP_KH_YDKH表,使用了关联,所以需要对yhbh建个索引
create index IDX_YHBH_KH on TMP_KH_YDKH (YHBH);
对于DJHJSL_LSB_FZ_HISTORY表,在not EXISTS里面,会全表扫描这个表,现在对他建立联合索引试试。
CREATE INDEX IDX_DJHJSL_FZ_HISTORY_UNION ON V_TEMP_TABLE_JHCBHSTJ_HISTORY(BBNY,YHBH,GDDWBM,YHLBDM);

查看oracle的执行计划,建立联合索引,并没有让这个表走索引,还是在全表扫描的,但是查询已经提升到9s了。
接下来对分别对这四个字段建立索引:
create index IDX_DJHJSL_FZ_HISTORY_BBNY on DJHJSL_LSB_FZ_HISTORY (BBNY);
create index IDX_DJHJSL_FZ_HISTORY_YHBH on DJHJSL_LSB_FZ_HISTORY (YHBH);
create index IDX_DJHJSL_FZ_HISTORY_GDDWBM on DJHJSL_LSB_FZ_HISTORY (GDDWBM);
create index IDX_DJHJSL_FZ_HISTORY_YHLBDM on DJHJSL_LSB_FZ_HISTORY (YHLBDM);
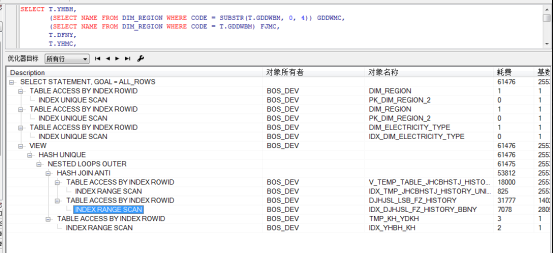
从执行计划来看,oracle只走了IDX_DJHJSL_FZ_HISTORY_BBNY这个索引,现在最快已经到1.95s了。
虽然现在已经满足了查询3s内的要求,但是考虑到以后,每个月的数据增长,数据量有5000万,一亿这样的大数据量的时候还是会很慢。
其实我在正式环境测试的时候,NOT EXISTS 里面的这个表,建立单个索引是没有用的,建立联合索引才会使这个表走索引,可能是因为电脑的cpu不同等因素影响的。
上面的优化方法当然不能满足项目的需求,接下来结合业务进行优化。作为一个监控系统,数据是T+1的,不需要追求实时性,这些数据,都是使用etl抽取工具每天定时抽取的。而且每个月300万数据,用户只关注的只有几千条。所以结合业务,我们在使用etl抽取完数据后,将用户关注的数据插入到另一张表中,这样,每个月只有几千条数据,这样的话,一年也才几万条数据,对oracle来说决定是零压力的。
-----------------------------------------------------我是分界线---------------------------------------------------------
2020年5月1日更新:前一天我有点空闲时间,想起来对这个sql再做一次优化(经过几个月的增长,已经有了4000万的数据,就算上面的那个脚本查询还有有点慢),因为我们的表数据是按月插入的,客户查询也是按月查询的,所以我就对 V_TEMP_TABLE_JHCBHSTJ_HISTORY,DJHJSL_LSB_FZ_HISTORY 这两个月进行了按月分区(列表分区)。
下面是执行脚本(我这里没有建默认分区,在项目中一定要建立默认分区):
-- Create table 分母
create TABLE JHCBHSTJ_HISTORY1
(
BBNY VARCHAR2(6),
BBNYR VARCHAR2(8),
GDDWBM VARCHAR2(20),
YHLBDM VARCHAR2(20),
DYLBBM VARCHAR2(20),
YHBH VARCHAR2(50),
YHMC VARCHAR2(200),
DYJHCBKHS NUMBER(10)
)
partition by LIST(BBNY)
(
partition P_JHCBHSTJ_HISTORY_201905 values (''),
partition P_JHCBHSTJ_HISTORY_201906 values (''),
partition P_JHCBHSTJ_HISTORY_201907 values (''),
partition P_JHCBHSTJ_HISTORY_201908 values (''),
partition P_JHCBHSTJ_HISTORY_201909 values (''),
partition P_JHCBHSTJ_HISTORY_201910 values (''),
partition P_JHCBHSTJ_HISTORY_201911 values (''),
partition P_JHCBHSTJ_HISTORY_201912 values (''), partition P_JHCBHSTJ_HISTORY_202001 values (''),
partition P_JHCBHSTJ_HISTORY_202002 values (''),
partition P_JHCBHSTJ_HISTORY_202003 values (''),
partition P_JHCBHSTJ_HISTORY_202004 values (''),
partition P_JHCBHSTJ_HISTORY_202005 values (''),
partition P_JHCBHSTJ_HISTORY_202006 values (''),
partition P_JHCBHSTJ_HISTORY_202007 values (''),
partition P_JHCBHSTJ_HISTORY_202008 values (''),
partition P_JHCBHSTJ_HISTORY_202009 values (''),
partition P_JHCBHSTJ_HISTORY_202010 values (''),
partition P_JHCBHSTJ_HISTORY_202011 values (''),
partition P_JHCBHSTJ_HISTORY_202012 values (''), partition P_JHCBHSTJ_HISTORY_202101 values (''),
partition P_JHCBHSTJ_HISTORY_202102 values (''),
partition P_JHCBHSTJ_HISTORY_202103 values (''),
partition P_JHCBHSTJ_HISTORY_202104 values (''),
partition P_JHCBHSTJ_HISTORY_202105 values (''),
partition P_JHCBHSTJ_HISTORY_202106 values (''),
partition P_JHCBHSTJ_HISTORY_202107 values (''),
partition P_JHCBHSTJ_HISTORY_202108 values (''),
partition P_JHCBHSTJ_HISTORY_202109 values (''),
partition P_JHCBHSTJ_HISTORY_202110 values (''),
partition P_JHCBHSTJ_HISTORY_202111 values (''),
partition P_JHCBHSTJ_HISTORY_202112 values ('')
);; ALTER SESSION ENABLE PARALLEL DML;
--插入数据 (采用并发,依据服务器性能和核数而定)
INSERT /*+PARALLEL(JHCBHSTJ_HISTORY1,30)*/ INTO JHCBHSTJ_HISTORY1
SELECT /*+PARALLEL(V_TEMP_TABLE_JHCBHSTJ_HISTORY,30)*/ * FROM V_TEMP_TABLE_JHCBHSTJ_HISTORY; COMMIT; --替换之前的表
RENAME V_TEMP_TABLE_JHCBHSTJ_HISTORY TO JHCBHSTJ_HISTORY_BAK;
RENAME JHCBHSTJ_HISTORY1 TO V_TEMP_TABLE_JHCBHSTJ_HISTORY;
-- Create table 分子
create table DJHJSL_LSB_FZ_HISTORY_1
(
BBNY VARCHAR2(6),
BBNYR VARCHAR2(8),
GDDWBM VARCHAR2(20),
YHLBDM VARCHAR2(20),
DYLBBM VARCHAR2(20),
YHBH VARCHAR2(50),
YHMC VARCHAR2(200),
ZDCBZHS NUMBER(10)
)
partition by LIST(BBNY)
(
partition P_DJHJSL_LSB_FZ_HISTORY_201905 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_201906 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_201907 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_201908 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_201909 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_201910 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_201911 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_201912 values (''), partition P_DJHJSL_LSB_FZ_HISTORY_202001 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_202002 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_202003 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_202004 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_202005 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_202006 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_202007 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_202008 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_202009 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_202010 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_202011 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_202012 values (''), partition P_DJHJSL_LSB_FZ_HISTORY_202101 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_202102 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_202103 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_202104 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_202105 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_202106 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_202107 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_202108 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_202109 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_202110 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_202111 values (''),
partition P_DJHJSL_LSB_FZ_HISTORY_202112 values ('')
);; ALTER SESSION ENABLE PARALLEL DML;
--插入数据 (采用并发,依据服务器性能和核数而定)
INSERT /*+PARALLEL(DJHJSL_LSB_FZ_HISTORY_1,30)*/ INTO DJHJSL_LSB_FZ_HISTORY_1
SELECT /*+PARALLEL(DJHJSL_LSB_FZ_HISTORY,30)*/ * FROM DJHJSL_LSB_FZ_HISTORY; COMMIT; -- Create/Recreate indexes
create index IDX_DJHJSL_FZ_HISTORY_UNION1 on DJHJSL_LSB_FZ_HISTORY_1 (BBNY, YHBH, GDDWBM, YHLBDM); --替换之前的表
RENAME DJHJSL_LSB_FZ_HISTORY TO DJHJSL_LSB_FZ_HISTORY_bak;
RENAME DJHJSL_LSB_FZ_HISTORY_1 TO DJHJSL_LSB_FZ_HISTORY;
同时在两个表插入完成之后,对两个表收集了执行信息:
--收集执行信息
EXEC DBMS_STATS.gather_table_stats(user,'V_TEMP_TABLE_JHCBHSTJ_HISTORY',cascade=>true); --收集执行信息
EXEC DBMS_STATS.gather_table_stats(user,'DJHJSL_LSB_FZ_HISTORY',cascade=>true);
这样我在执行查询的时候,下面的图可以看到效果,性能提升还是很大的。
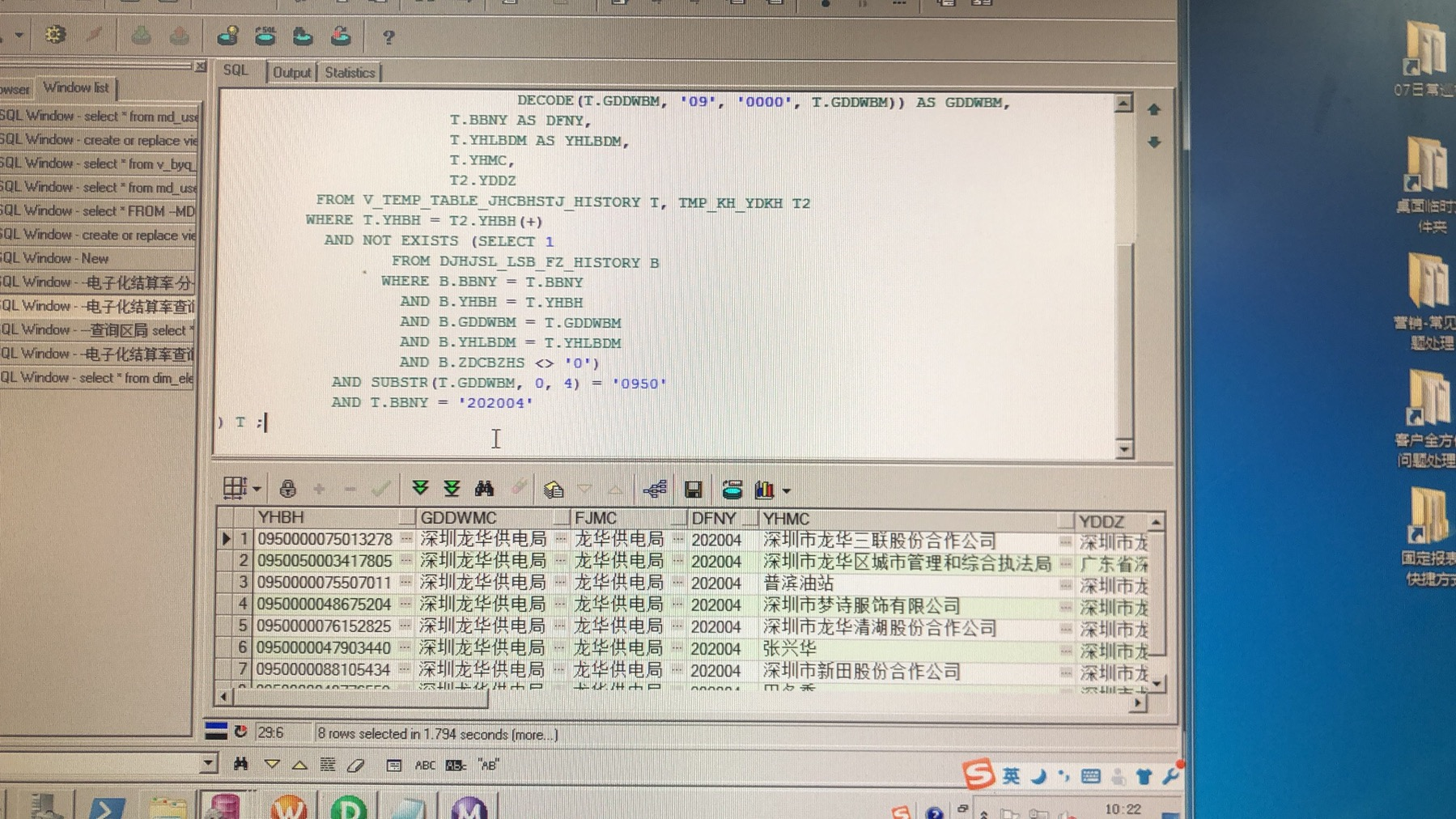
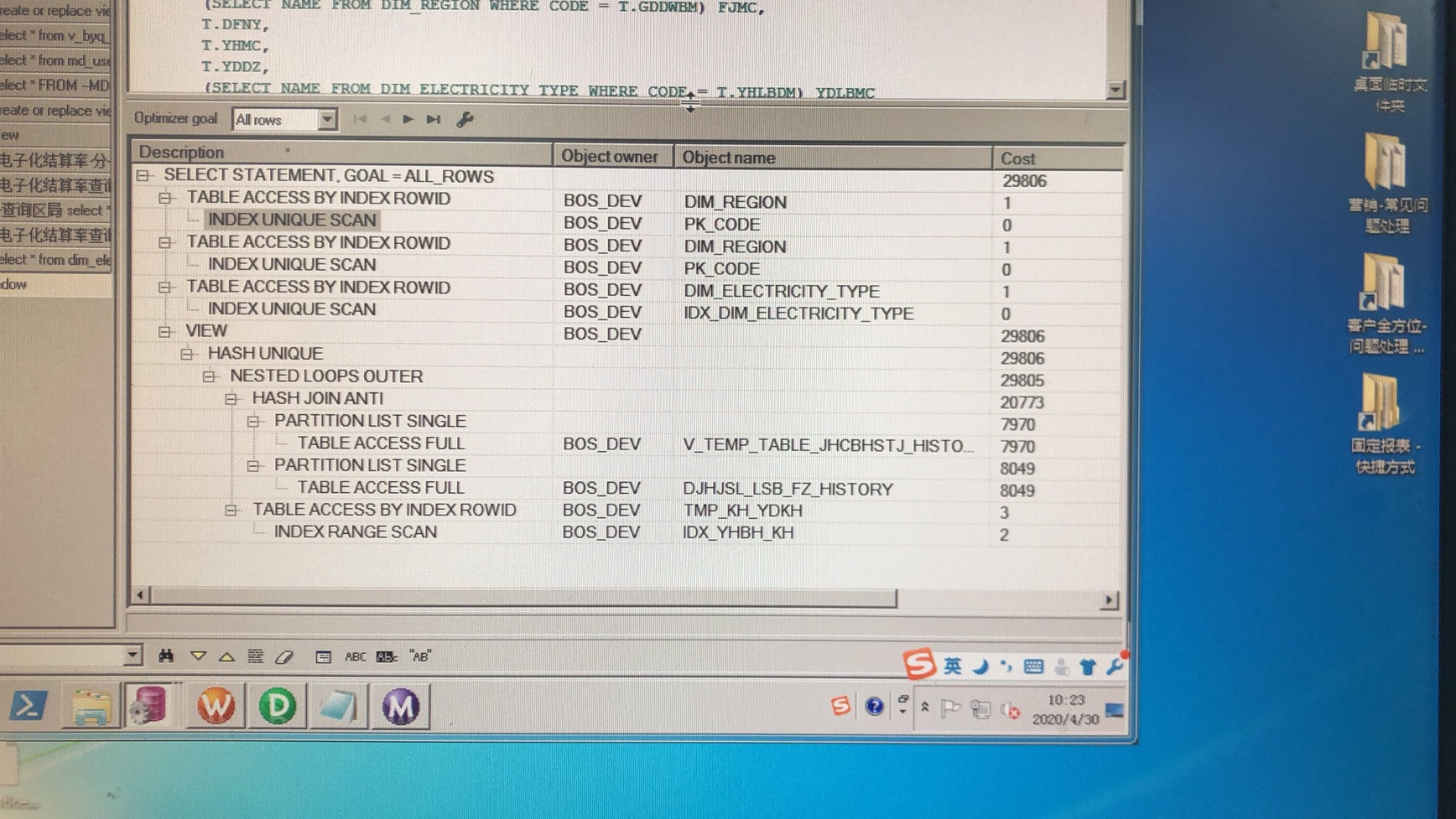
如果大家还有其他的方式优化,请在下方留言交流。
oracle性能优化(项目中的一个sql优化的简单记录)的更多相关文章
- 项目中常用的MySQL 优化
本文我们来谈谈项目中常用的MySQL优化方法,共19条,具体如下: 一.EXPLAIN 做MySQL优化,我们要善用EXPLAIN查看SQL执行计划. 下面来个简单的示例,标注(1.2.3.4.5)我 ...
- Entity Framework 的小实例:在项目中添加一个实体类,并做插入操作
Entity Framework 的小实例:在项目中添加一个实体类,并做插入操作 1>. 创建一个控制台程序2>. 添加一个 ADO.NET实体数据模型,选择对应的数据库与表(Studen ...
- 【Filter 不登陆无法访问】web项目中写一个过滤器实现用户不登陆,直接给链接,无法进入页面的功能
在web项目中写一个过滤器实现用户不登陆,直接给链接,无法进入页面,而重定向到登陆界面的功能. 项目是用springMVC+spring+hibernate实现 (和这个没有多大关系) 第一步: 首先 ...
- 项目中的一个分页功能pagination
项目中的一个分页功能pagination <script> //总页数 ; ; //分页总数量 $(function () { // $("#pagination"). ...
- 如何在 GitHub 的项目中创建一个分支呢?
如何在 GitHub 的项目中创建一个分支呢? 其实很简单啦,直接点击 Branch,然后在弹出的文本框中添加自己的 Branch Name 然后点击蓝色的Create branch就可以了,这样一来 ...
- Java项目中每一个类都可以有一个main方法
Java项目中每一个类都可以有一个main方法,但只有一个main方法会被执行,其他main方法可以对类进行单元测试. public class StaticTest { public static ...
- Spring+SpringMVC+MyBatis+easyUI整合优化篇(十二)数据层优化-explain关键字及慢sql优化
本文提要 从编码角度来优化数据层的话,我首先会去查一下项目中运行的sql语句,定位到瓶颈是否出现在这里,首先去优化sql语句,而慢sql就是其中的主要优化对象,对于慢sql,顾名思义就是花费较多执行时 ...
- oracle定时器在项目中的应用
业务需求: 现在业务人员提出了一个需求: 在项目中的工作流,都要有一个流程编号,此编号有一定的规则: 前四五位是流程的字母缩写,中间是8位的日期,后面五位是流水码,要求流水码每天从00001开始.即: ...
- Javaweb项目中出现java.sql.SQLException: The server time zone value '�й���ʱ��' is unrecognized or represents more than one time zone.异常
javaweb项目中java.sql.SQLException: The server time zone value '�й���ʱ��' is unrecognized or represent ...
随机推荐
- Linux的curl和wget
wget wget命令用来从指定的URL下载文件.wget非常稳定,它在带宽很窄的情况下和不稳定网络中有很强的适应性,如果是由于网络的原因下载失败,wget会不断的尝试,直到整个文件下载完毕.如果是服 ...
- JAVA中字符串常见操作
String str1="hello,world";String str2="Hello,World"; 1.字符串的比较:例,System.out.print ...
- 【开发工具 - Android Studio】之AndroidStudio使用笔记
一.关闭自动更新: 问题:刚刚安装Android Studio的童鞋可能会遇到这样一个问题:Android Studio在打开的时候一直在下载一些东西,浪费很多时间,而且最终大多都会显示下载失败等等, ...
- kubeadm 报错 error execution phase preflight: couldn’t validate the identity of the API Server: abort connecting to API servers after timeout of 5m0s
原因:master节点的token过期了 解决:重新生成新token 在master重新生成token # kubeadm token create 424mp7.nkxx07p940mkl2nd # ...
- Java工作流引擎-中间件模式代码集成
关键词:工作流快速开发平台 工作流流设计 业务流程管理 asp.net 开源工作流 bpm工作流系统 java工作流主流框架 自定义工作流引擎 表单设计器 流程设计器 前端代码集成步骤 ...
- python函数-参数
python函数-参数 实验室 # 演示形参是可变类型 def register(name, hobby, hobby_list=[]): hobby_list.append(hobby) print ...
- ElasticSearch的API使用
前言:之前写过如何安装ElasticSearch(以下简称ES)以及简单的crud的使用实例的博客,不过ElasticSearch的版本变化太快,像之前的5.6版本使用的TransPortClient ...
- PAT(甲级)2019年春季考试
7-1 Sexy Primes 判断素数 一个点没过17/20分 错因:输出i-6写成了输出i,当时写的很乱,可以参考其他人的写法 #include<bits/stdc++.h> usin ...
- 全新一代云服务器S6,重新定义性价比
S6通用计算型云服务器,搭载全新一代处理器,配套华为自研高性能智能网卡,计算与网络性能全面升级.S6进一步强化高性价比定位,满足企业性能要求的同时,降低中小企业上云成本. 更多详情请访问ECS产品介绍 ...
- UVa-10652 包装木板
Input: standard inputOutput: standard output Time Limit: 2 seconds The small sawmill in Mission, Bri ...