Ganglia与Centreon整合构建智能化监控报警平台
一、智能运维监控报警平台的组成
随着大数据时代的来临,运维工作的难度越来越大,每个运维人员都要面临不计其数的服务器和海量的数据,如何保证众多服务器和业务系统稳定高效地运行并尽量减少死机时间,成为考核运维工作的重要指标,而要实现大规模的运维,必须要有一套行之有效的智能运维监控管理系统,本章就详细介绍下如何构建一套完善的运维监控报警平台。
运维的核心工作可以分为运行监控和故障处理两个方面,对业务系统进行精确、完善的监控,保证能够在第一时间发现故障并迅速通知运维人员处理故障是运维监控系统要实现的基础功能;一个功能完善的智能监控系统,不但可以自动处理一些简单故障,减少运维工作量,还应该在应用可能出现故障时预先发出报警,预防故障的发生。因此,构建一个智能的运维监控平台,必须以运行监控和故障报警这两个方面为重点,将所有业务系统中涉及的网络资源、硬件资源、软件资源、数据库资源等纳入统一的运维监控平台中,并通过消除管理软件的差别,数据采集手段的差别,对各种不同的数据来源实现统一管理、统一规范、统一处理、统一展现、统一用户登录、统一权限控制,最终实现运维规范化、自动化、智能化的大运维管理。
一个智能的运维监控平台,一般的设计架构从低到高可以分为6层,三大模块,如下图所示。
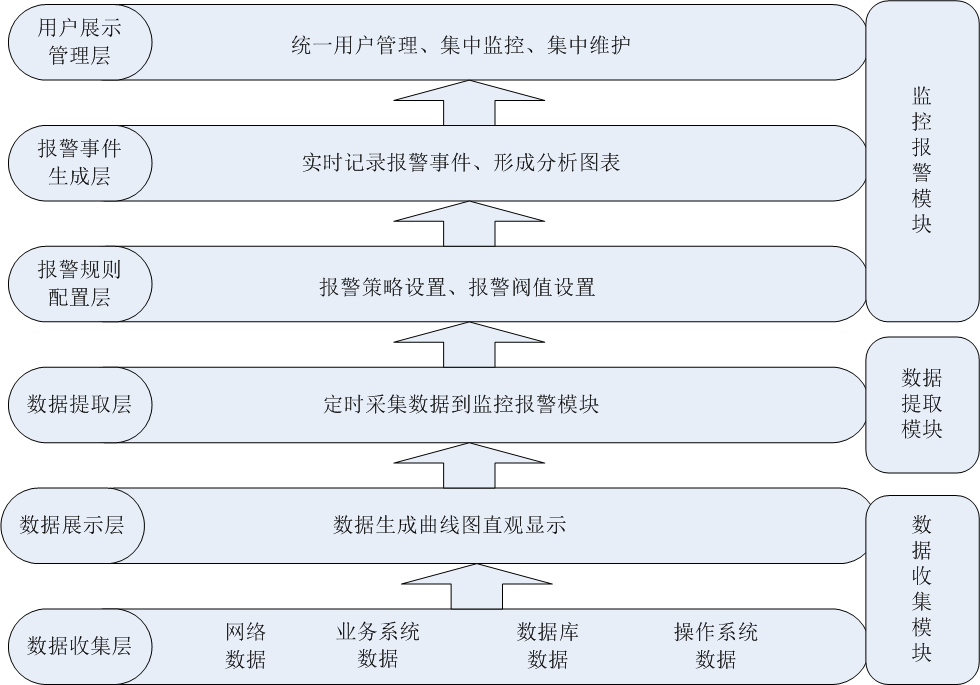
其中:
数据收集层:位于最底层,主要收集网络数据、业务系统数据、数据库数据、操作系统数据等,然后将收集到的数据进行规范化并进行存储。
数据展示层:位于第二层,是一个Web展示界面,主要是将数据收集层获取到的数据进行统一展示,展示的方式可以是曲线图、柱状图、饼状态等,通过将数据图形化,可以帮助运维人员了解一段时间内主机或网络的运行状态和运行趋势,并作为运维人员排查问题或解决问题的依据。
数据提取层:位于第三层,主要是对从数据收集层获取到的数据进行规格化和过滤处理,提取需要的数据到监控报警模块,这个部分是监控和报警两个模块的衔接点。
报警规则配置层:位于第四层,主要是根据第三层获取到的数据进行报警规则设置、报警阀值设置、报警联系人设置和报警方式设置等。
报警事件生成层:位于第五层,主要是对报警事件进行实时记录,将报警结果存入数据库以备调用,并将报警结果形成分析报表,以统计一段时间内的故障率和故障发生趋势。
用户展示管理层:位于最顶层,是一个Web展示界面,主要是将监控统计结果、报警故障结果进行统一展示,并实现多用户、多权限管理,实现统一用户和统一权限控制。
在这6层中,从功能实现划分,又分为三个模块,分别是数据收集模块、数据提取模块和监控报警模块,每个模块完成的功能如下:
数据收集模块:此模块主要完成基础数据的收集与图形展示。数据收集的方式有很多种,可以通过SNMP实现,也可以通过代理模块实现,还可以通过自定义脚本实现。常用的数据收集工具有Cacti、Ganglia等。
数据提取模块:此模板主要完成数据的筛选过滤和采集,将需要的数据从数据收集模块提取到监控报警模块中。可以通过数据收集模块提供的接口或自定义脚本实现数据的提取。
监控报警模块:此模块主要完成监控脚本的设置、报警规则设置,报警阀值设置、报警联系人设置等,并将报警结果进行集中展现和历史记录。常见的监控报警工具有Nagios、Centreon等。
在了解了运维监控平台的一般设计思路之后,接下来详细介绍下如何通过软件实现这样一个智能运维监控系统。
上图是根据上图的设计思路形成的一个运维监控平台实现拓扑图,从图中可以看出,主要有三大部分组成,分别是数据收集模块、监控报警模块和数据提取模块,其中,数据提取模块用于其他两个模块之间的数据通信,而数据收集模块可以有一台或多台数据收集服务器组成,每个数据收集服务器可以直接从服务器群组收集各种数据指标,经过规范数据格式,最终将数据存储到数据收集服务器中。监控报警模块通过数据抽取模块从数据收集服务器获取需要的数据,然后设置报警阀值、报警联系人等,最终实现实时报警。报警方式支持手机短信报警、邮件报警等,另外,也可以通过插件或者自定义脚本来扩展报警方式。这样一整套监控报警平台就基本实现了。
二、Ganglia作为数据收集模块
关于Ganglia的基本应用,在前面章节已经详细介绍过,这里将Ganglia作为监控报警平台的数据收集模块,主要基于以下几方面的原因:
1、灵活的分布式、分层体系结构,使Ganglia支持上万个监控节点的数据收集,并且性能表现稳定,同时,Ganglia也可以根据地域环境、网络结构的不同,分地域、分层次灵活部署Ganglia数据收集点,而对于数据收集节点可以动态添加或删除,对Ganglia整体监控不产生任何影响,因此,可以灵活扩展Ganglia数据收集节点。
2、收集数据更加精确,不但可以收集实时数据,以图表的形式展示出来,而且还允许用户查看历史统计数据,因此,用户可以通过这些数据,做出性能调整、升级、扩容等决策,从而保证应用系统能够满足不断增长的业务需求。
3、可以通过组播、单播的方式收集数据。在监控的节点较多时通过组播方式收集数据可以大大降低数据收集的负载,提高监控和数据收集性能。而对于不能使用组播收集数据的网络环境,还可以通过单播的方式收集数据,因此Ganglia在数据收集方式上非常灵活。
4、可收集各种度量的数据。Ganglia默认可收集cpu、memory、disk、I/O、process、network六大方面的数据,同时还提供了C或者Python接口,用户通过这个接口可以自定义数据收集模块,并且这些模块可以被直接插入到Ganglia中以监控用户自定义的应用。
基于以上这些优点,Ganglia非常适合作为监控报警平台的数据收集模块。虽然Cacti也可以实现数据的收集和图形报表的展示,但是当监控节点越来越多时,Cacti的缺点就慢慢暴露出来了,数据收集的准确性、实时性就很难得到保障了。因此,要构建一个高性能的监控报警平台,Ganglia是首选的数据收集模块。
三、Centreon作为监控报警模块
有了Ganglia收集数据还是不够的,运维人员不可能天天盯着数据报表,因此,还需要对收集到的数据进行监控和报警:对每个需要监控的主机或服务,设置一个报警阀值,当收集到的数据超过这个阀值时,在第一时间能自动报警并通知运维人员,而在收集到的数据没有超过指定的报警阀值时,运维人员就可以去做别的事情,而不用时刻盯着数据报表,这是构建智能监控报警平台必须要实现的一个功能。
对主机或服务的状态值进行监控,当达到指定阀值时进行报警,要实现这个功能并不是什么难的事情,写个简单的脚本就能实现,但是这样太原始了,没有层次,维护性差,并且当需要监控报警的主机或服务越来越多时,脚本的性能就变得很差,管理也非常不方便,更别说有什么可视化效果了,因此,需要有一个专业的监控报警工具来实现这个功能。
Centreon就是这样一个专业的分布式监控、报警工具,它通过第三方组件可以实现对网络、操作系统和应用程序的监控与报警。在底层,Centreon通过nagios作为监控软件;在数据层,Centreon通过ndoutil模块将监控到的数据定时写入数据库中;在展示层,Centreon提供了Web界面来配置、管理需要监控的主机或服务,并提供多种报警通知方式,同时还可以展现监控数据和报警状态,并且可查询历史报警记录。
关于Centreon的介绍和使用,在前面专栏已经做过非常详细的介绍,这里不再多说。通过对Centreon的使用可知,Centreon无论在配置、管理、可视化等方面都做得非常专业和完善,并且在多主机、多服务监控的环境下,性能表现也非常稳定,因此,将Centreon作为智能监控报警平台的监控报警模块非常适合。
四、Ganglia与Centreon的无缝整合
通过前面的介绍,确定了以Ganglia作为数据收集模块,Centreon作为监控报警模块的方案,这样,一个智能监控报警平台两大主要功能模块已经基本实现了。但现在的问题是,如何将收集到的数据传送给监控报警模块呢,这就是数据抽取模块要完成的功能。
数据抽取模块要完成的功能是:从数据收集模块中定时采集指定的数据,然后将采集到的数据与指定的报警阀值进行比较,如果发现采集到的数据大于或小于指定的报警阀值,那么就通过监控报警模块设置的报警方式进行故障通知。在这个过程中,只有采集数据在数据收集模块中完成,其他操作,例如:采集数据时间间隔、报警阀值设置、报警方式设置、报警联系人设置等都在监控报警模块中完成。
从数据抽取模块完成的功能可以看出,此模块主要用来衔接数据收集模块和监控报警模块,进而实现Ganglia和Centreon的无缝整合。要实现数据抽取模块的功能,方法有很多,最简单最直接的方法就是编写监控脚本,这里提供几个常用的数据抽取脚本,然后将脚本添加到Centreon中,下面介绍具体的操作过程。
4.1、数据抽取脚本
这里提供一个数据抽取脚本,是基于Python编写的,介绍如下。
这个脚本的原理是通过Ganglia提供的数据汇总端口来获取数据,然后将获取到的数据与指定的阀值进行对比,以判断服务是否有异常。脚本内容如下:
#!/usr/bin/env python
import sys
import getopt
import socket
import xml.parsers.expat
class GParser:
def __init__(self, host, metric):
self.inhost =0
self.inmetric = 0
self.value = None
self.host = host
self.metric = metric
def parse(self, file):
p = xml.parsers.expat.ParserCreate()
p.StartElementHandler = parser.start_element
p.EndElementHandler = parser.end_element
p.ParseFile(file)
if self.value == None:
raise Exception('Host/value not found')
return float(self.value)
def start_element(self, name, attrs):
if name == "HOST":
if attrs["NAME"]==self.host:
self.inhost=1
elif self.inhost==1 and name == "METRIC" and attrs["NAME"]==self.metric:
self.value=attrs["VAL"]
def end_element(self, name):
if name == "HOST" and self.inhost==1:
self.inhost=0
def usage():
print """Usage: check_ganglia_metric \
-h|--host= -m|--metric= -w|--warning= \
-c|--critical= """
sys.exit(3)
if __name__ == "__main__":
##############################################################
ganglia_host = '127.0.0.1'
ganglia_port = 8651
host = None
metric = None
warning = None
critical = None
try:
options, args = getopt.getopt(sys.argv[1:],
"h:m:w:c:s:p:",
["host=", "metric=", "warning=", "critical=", "server=", "port="],
)
except getopt.GetoptError, err:
print "check_gmond:", str(err)
usage()
sys.exit(3)
for o, a in options:
if o in ("-h", "--host"):
host = a
elif o in ("-m", "--metric"):
metric = a
elif o in ("-w", "--warning"):
warning = float(a)
elif o in ("-c", "--critical"):
critical = float(a)
elif o in ("-p", "--port"):
ganglia_port = int(a)
elif o in ("-s", "--server"):
ganglia_host = a
if critical == None or warning == None or metric == None or host == None:
usage()
sys.exit(3)
try:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((ganglia_host,ganglia_port))
parser = GParser(host, metric)
value = parser.parse(s.makefile("r"))
s.close()
except Exception, err:
print "CHECKGANGLIA UNKNOWN: Error while getting value \"%s\"" % (err)
sys.exit(3)
if critical > warning:
if value >= critical:
print "CHECKGANGLIA CRITICAL: %s is %.2f" % (metric, value)
sys.exit(2)
elif value >= warning:
print "CHECKGANGLIA WARNING: %s is %.2f" % (metric, value)
sys.exit(1)
else:
print "CHECKGANGLIA OK: %s is %.2f" % (metric, value)
sys.exit(0)
else:
if critical >= value:
print "CHECKGANGLIA CRITICAL: %s is %.2f" % (metric, value)
sys.exit(2)
elif warning >= value:
print "CHECKGANGLIA WARNING: %s is %.2f" % (metric, value)
sys.exit(1)
else:
print "CHECKGANGLIA OK: %s is %.2f" % (metric, value)
sys.exit(0)你可以下载源码:https://www.ixdba.net/jk/ganglia_shell.tar.gz
在这个脚本中,需要修改的地方有两个,分别是ganglia_host和ganglia_port。ganglia_host表示gmetad服务所在服务器的IP地址,Ganglia可以和Centreon安装到一起,也可以分开部署,当Ganglia和Centreon安装在一起时,这个值就是“127.0.0.1”。ganglia_port表示gmetad收集数据汇总的交互端口,默认是8651。
本例中,我们的centreon和ganglia gmetad没在一起,因此,ganglia_host要填写ganglia gmetad的IP为172.16.213.157,需要注意的是,因为是centreon主机要访问ganglia gmetad主机,所以还需要在ganglia gmetad的配置文件gmetad中增加如下选项:
[root@centreonserver bestjob]# cat gmetad.conf |grep “trusted_hosts”
trusted_hosts 127.0.0.1 172.16.213.229其中,172.16.213.229是centreon主机的ip地址。
上面所有配置完成后,将此脚本命名为check_ganglia.py,然后放到Centreon存放nagios插件的目录下,默认为/usr/lib64/nagios/plugins,并授予可执行权限。接着介绍此脚本的用法。
[root@centreonserver plugins]# chmod 755 check_ganglia.py在命令行直接执行check_ganglia.py脚本,即可获得使用帮助:
[root@centreonserver plugins]# python check_ganglia.py
Usage: check_ganglia_metric -h|--host= -m|--metric= -w|--warning= -c|--critical=下面分别介绍其中各个参数的意义。
-h:表示从哪个主机上提取数据,后跟主机名或IP地址。这里需要注意的是,Ganglia默认将收集到的数据存放在gmetad配置文件中“rrd_rootdir”参数指定的目录下,如果被监控的主机没有主机名或主机名没有进行DNS解析,那么Ganglia就会用此主机的IP地址作为目录名来存储收集到的数据,反之,就会以主机名作为存储数据的目录名称。
因此,这里的“-h“参数就要以Ganglia存储rrds数据的目录名称为准。下面是Ganglia收集到的rrds数据的存储结构:
[root@centreonserver bestjob]# pwd
/data/rrdsdata/rrds/bestjob
[root@centreonserver bestjob]# ls
192.168.11.188 host0080.bestjob.com host0078.bestjob.com
192.168.16.10 host0022.bestjob.com host0065.bestjob.com
[root@centreonserver bestjob]# cd 192.168.11.188
[root@centreonserver 192.168.11.188]# ls
cpu_num.rrd cpu_system.rrd disk_free.rrd
load_five.rrd mem_cached.rrd mem_total.rrd
cpu_speed.rrd cpu_user.rrd disk_total.rrd
load_one.rrd mem_free.rrd part_max_used.rrd -m:表示要收集的指标值,例如cpu_num、disk_free、cpu_user、disk_total、load_one、part_max_used等,这些指标值可以在Ganglia存储rrds数据的目录中找到,也可以在Ganglia的Web界面中查找到。
-w:表示警告的阀值,当此脚本收集到的指标值低于或者高于指定的警告阀值时,此脚本就会发出告警通知,同时此脚本返回状态值1。
-c:表示故障阀值,当此脚本收集到的指标值低于或者高于指定的故障阀值事,此脚本就会发出故障通知,同时此脚本返回状态值2。
下面演示一下此脚本的用法,这里以检测host0080.bestjob.com主机的磁盘剩余空间为例,其他指标值以此类推:
[root@centreonserver plugins]# ./ check_ganglia.py \
> -h host0080.bestjob.com -m disk_free -w 1000 -c 500
CHECKGANGLIA OK: disk_free is 3045.75
[root@centreonserver plugins]# echo $?
0
[root@centreonserver plugins]# ./ check_ganglia.py \
> -h host0080.bestjob.com -m disk_free -w 3045 -c 3000
CHECKGANGLIA WARNING: disk_free is 3043.68
[root@centreonserver nagios]# echo $?
1
[root@centreonserver plugins]# ./ check_ganglia.py \
> -h host0080.bestjob.com -m disk_free -w 3050 -c 3045
CHECKGANGLIA CRITICAL: disk_free is 3044.55
[root@centreonserver plugins]# echo $?
2
[root@centreonserver plugins]# ./ check_ganglia.py \
> -h host0080.bestjob.com -m part_max_used -w 90 -c 95
CHECKGANGLIA OK: part_max_used is 81.70前三个例子主要用来检测磁盘的剩余空间。在检测磁盘剩余空间时使用的是“disk_free”这个指标值,这个“disk_free”是host0080.bestjob.com主机所有磁盘剩余空间的总和,这里的指标单位为GB。
脚本的执行过程为:如果剩余磁盘空间正常,将输出OK字样,同时输出剩余磁盘空间量,并返回状态值0,;如果检测磁盘处于WARNING状态,将返回状态值1;如果检测磁盘处于CRITICAL状态,将返回状态值2。这其实就是Nagios下状态检测脚本的基本写法,Nagios就是通过脚本的返回状态值来判断服务处于何种状态。
接着看最后一个例子,这个例子用到了“part_max_used”这个指标。这个指标表示磁盘分区的最大使用率,单位是百分比,它用来输出系统中磁盘分区使用率的最大值。这个指标非常有用,经常用来判断系统中某个磁盘分区是否已满。在这个例子中,指定WARNING状态的阀值是90%,CRITICAL状态的阀值是95%,也就是当系统磁盘最大使用率达到95%时将发出CRITICAL报警。
最后,登录Ganglia的web界面,查看host0080.bestjob.com主机的“disk_free”和“part_max_used”状态图,检查一下通过Python脚本输出的值是否和Ganglia生成的状态图一致,如下图所示。
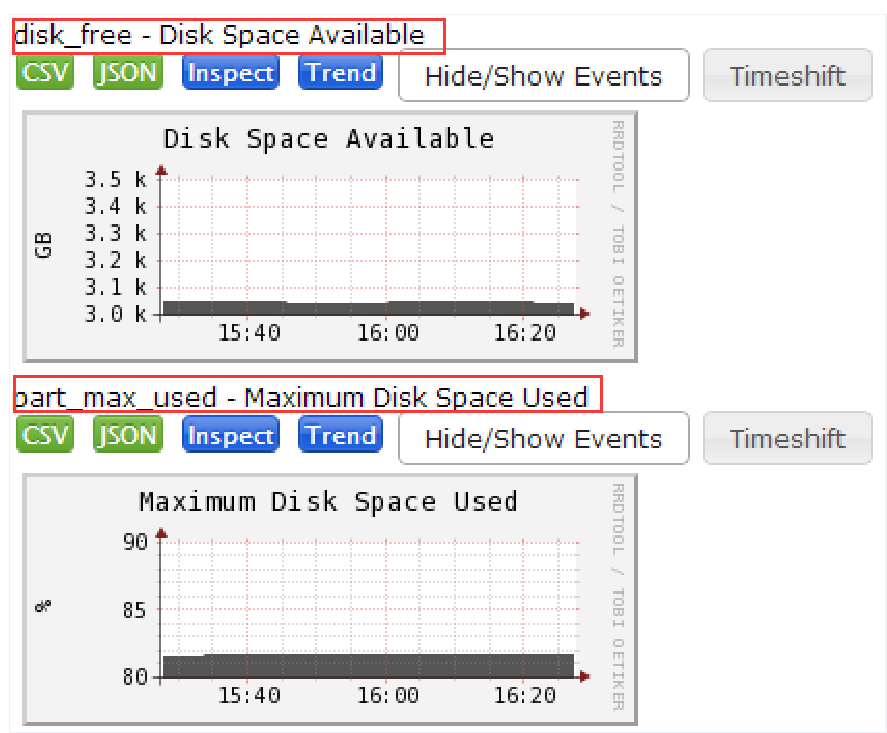
从图中可以看出,通过Python提取到的数值和Ganglia生成的状态图基本一致,如果要查看更详细的统计,可以点击上图进入详细统计页面,在这个详细页面,可以查看每小时、每天、每周的磁盘状态统计图。另外,通过上图还可以发现,统计的指标值“disk_free”和“part_max_used”就在状态图的左上角,并配有指标含义解释。
4.2、实现Ganglia与Centreon的完美整合
上面介绍了一个常用的数据抽取脚本及其用法,在实际应用中要实现对主机的监控报警,最简单的方法是将上面例子中的操作命令写到一个脚本,然后将这个脚本放到系统守护进程中,定期执行脚本检测即可,但是这种方法不够灵活,无法设定详细的联系人和联系人组,并且维护也不方便。
由于Centreon底层监控引擎跟Nagios类似,因此将这些脚本作为Nagios的插件,即可实现灵活的报警设置和便捷的管理。接下来以check_ganglia.py脚本为例,演示下如何将此脚本集成到Centreon平台上来,将其他脚本集成到Centreon的方法与此完全相同。
Ganglia和Centreon可以分开独立部署在两台服务器上,也可以部署在一起,这里设定Ganglia和Centreon部署在两台服务器上。结合前面介绍的Centreon知识,在监控服务器的Centreon Web界面,选择 Configuration—>Commands—>Checks,然后点击Add新建一个Command,如下图所示。
在上图中,创建了一个名为check_ganglia_py的Command,选择“Command Type”为“Check”。接着重点看“Command Line”的内容,其中,“$USER1$”就是Centreon服务器上Nagios监控插件的路径,默认是“/usr/lib64/nagios/plugins”,前面已经把这个监控脚本放到了此路径下,这里直接引用即可。在这个脚本对应的参数中定义了三个参数变量“$ARG1$”、“$ARG2$”和“$ARG3$”,分别用于指定Ganglia metric、警告条件和CRITICAL阀值。这里建议将每个参数变量的作用都在“Argument Descriptions”选项中做个描述,以保证在添加服务时不容易出错。
这样,就将check_ganglia.py脚本作为一个命令集成到Centreon中了。接下来演示一下如何通过这个脚本检测一批主机的磁盘空间最大占用率。首先在Centreon Web界面选择Configuration—>Services—>Services by host group,点击Add添加一个主机组服务,如下图所示。
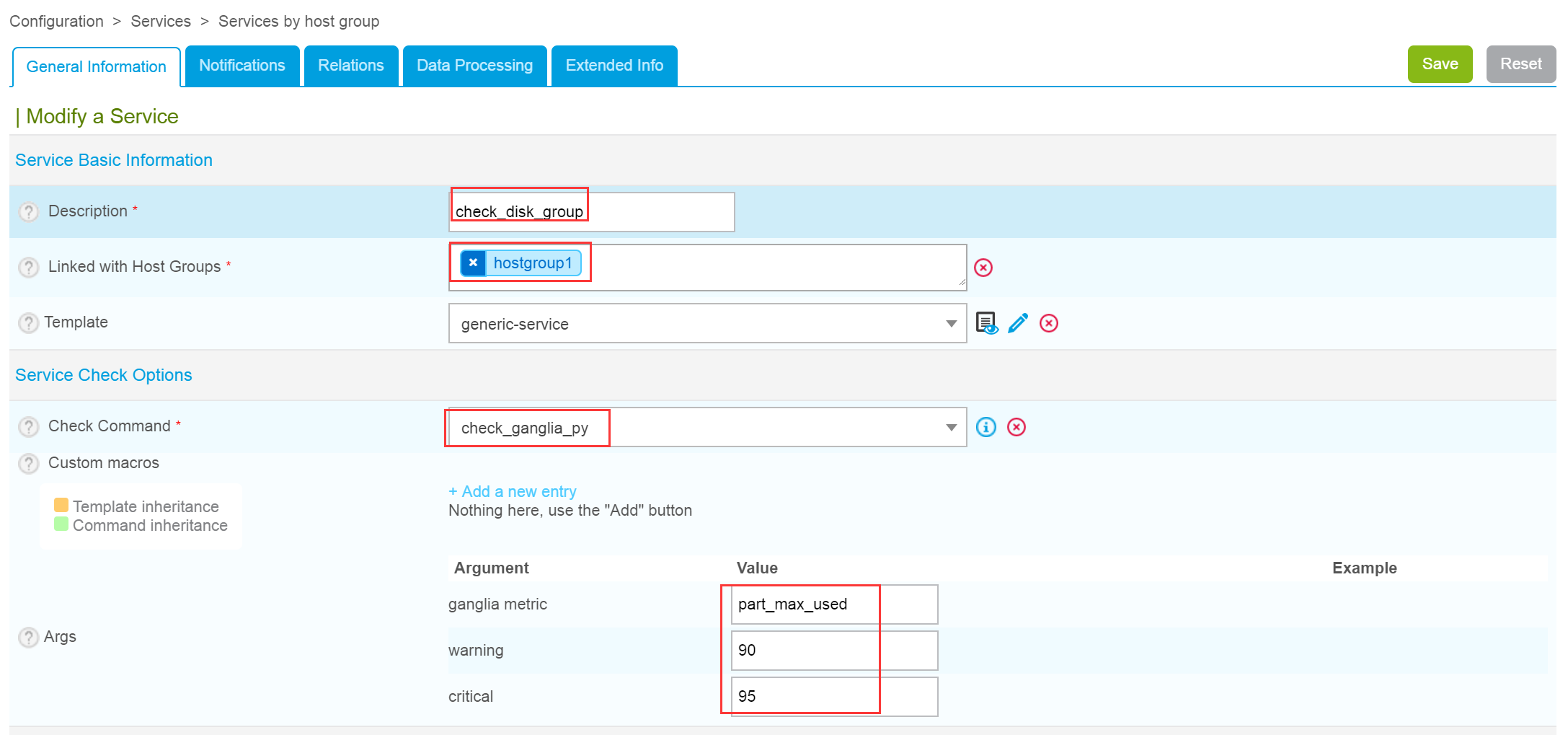
这里先看一下“General Information”标签中的几个选项:“Description”就是监控服务的名称,这里定义为check_disk_group ;“Linked with Host Groups”是指定此服务链接的主机组,如果有很多主机都需要监控同一个服务时,向主机一个一个添加服务就变得十分繁琐,此时通过添加主机组的方式,一次性完成主机组下所有主机的监控,简单而灵活。
接下来,“Template”是指定服务的模板,这里仍然选择“generic-service”; “Service Check Options”选项下的“Check Command”选项用来指定服务检查的命令,从下拉菜单中选择刚才创建的命令check_ganglia_py即可;最后一个选项“Args”就是刚才创建check_ganglia_py命令时指定的三个变量,根据每个变量的含义,依次填写Ganglia metric、警告条件和CRITICAL阀值。
对于“Service Scheduling Options”选项以及“Notifications”标签的报警通知的设置,因为已经在服务模板中都统一配置过了,所以无需设置。在完成所有设置后,保存退出,check_disk_group服务添加完成。
至此,已经完成check_ganglia.py脚本和Centreon的集成,其实也就是Ganglia和Centreon的集成,而这个脚本就是两者集成的桥梁而已。
在完成所有配置后,需要重启Centreon服务,这样所有的配置和修改才能生效。在重启Centreon服务后,查看check_disk_group服务的运行状态,如下图所示。

从上图中可以看出,hostgroup1主机组中包含了四台主机,每个主机的磁盘最大占用率都处于正常状态,并且输出了目前磁盘最大占用率的比值。由此可知,check_ganglia.py脚本集成到Centreon后工作正常,完美实现了从Ganglia采集数据,在Centreon中设置报警规则的监控、报警一体化过程。
五、在Centreon中实现批量数据收集与监控报警
在上面已经介绍了如何通过数据抽取脚本从Ganglia中抽取数据,然后通过脚本的判断最终实现在Centreon上的报警通知。这个过程看似很完美,其实隐藏着一些问题,比如,从给出的两个数据抽取文件中,脚本每次只能检测一台主机的一个服务状态,如果要检测多台主机的多个服务状态,就需要多次重复执行这个脚本。例如,要检测100台主机的磁盘最大占用率,脚本就要重复执行100次,同理,要检测100台主机中的10个服务状态,脚本就要执行1000次,在Centreon平台中,脚本检测是定期执行的,如果每个小时执行一次检测,那么每个小时就要执行脚本1000次。由此可知,这种脚本执行方式效率低下,严重浪费服务器资源,在监控主机较少的环境中,监控效率还勉强能够接受,但是当监控的主机超过500台或更多,监控的服务超过100或更多时,监控效率将更加低下,监控脚本从Ganglia抽取数据的时间也将变得很长,可能还会发生获取监控数据超时的情况,这对于要求监控精度很高、报警及时性强的监控报警平台来说,是不可容忍的。
如果能将监控脚本重复执行检查的次数减少,或者让脚本一次检查多台服务器的多个服务状态,那么脚本的执行效率将大大提升。在上节介绍的第二个脚本中,是通过读取Ganglia Web的页面信息来获取监控数据的,既然通过此脚本能一次获取某台主机的信息,那么也能一次获取多台主机的数据。非常幸运,这个功能Ganglia本身已经实现了,这里只需稍作修改拿过来使用即可。在Ganglia Web的程序目录下,有一个nagios目录,这个目录下有多个shell脚本和PHP脚本,这里重点介绍下check_host_regex.sh和check_host_regex.php这两个脚本,其他脚本的使用方法与此类似。
经过修改后的check_host_regex.sh脚本内容如下:
GANGLIA_URL="http:// 172.16.213.157/ganglia/nagios/check_host_regex.php"
# Build the rest of the arguments into the arg string for the URL.
CHECK_ARGS=''
if [ "$#" -gt "0" ]
then
CHECK_ARGS=$1
shift
for ARG in "$@"
do
CHECK_ARGS=${CHECK_ARGS}"&"${ARG}
done
else
echo "Sample invocation $0 hreg=web|apache checks=load_one,more,1:load_five,more,2 ignore_unknowns=0"
echo " Set ignore_unknowns=1 if you want to ignore hosts that don't posses a particular metric."
echo " This is useful if you want to use a catchall regex e.g. .* however some hosts lack a metric"
exit 1
fi
RESULT=`curl -s -g "${GANGLIA_URL}?${CHECK_ARGS}"`
EXIT_CODE=`echo $RESULT | cut -f1 -d'!'`
REST=`echo $RESULT | cut -f2 -d'!'`
for x in $EXIT_CODE; do
case $x in
OK)
echo $REST
exit 0;;
WARNING)
echo $REST
exit 1;;
CRITICAL)
echo $REST
exit 2;;
*)
echo $REST
exit 3;;
esac
done你可以下载源码:https://www.ixdba.net/jk/ganglia_shell.tar.gz
这里主要看下此文件第一行“GANGLIA_URL”的内容,这个变量用于指定http方式访问check_host_regex.php脚本的路径,后面跟的URL只要服务器本身能够访问到即可。默认是http://localhost, 表示centreon服务器和gmetad服务器在一起,如果centreon服务器和gmetad服务器不在一起的话,那么就需要修改GANGLIA_URL的值为centreon服务器的地址。我们这里修改为:
GANGLIA_URL=http://172.16.213.157/ganglia/nagios/check_host_regex.php。从脚本内容看,check_host_regex.sh主要用于对获取的监控数据进行判断,而check_host_regex.php脚本主要用来获取监控数据。check_host_regex.php脚本在ganglia web安装包中自带,因此这里不在讲述。
下面介绍check_host_regex.sh脚本的用法。直接在命令行执行check_host_regex.sh脚本,即可显示详细用法,例如:
[root@centreonserver plugins]# ./check_host_regex.sh
Sample invocation ./check_host_regex.sh hreg=Hostname checks=load_one,more,1:load_five,more,2 ignore_unknowns=0
Set ignore_unknowns=1 if you want to ignore hosts that don't posses a particular metric.下面介绍其中各个参数的意义。
hreg:后面跟主机名或主机名标识。这个参数的含义与check_ganglia_metric.php脚本中“hostname”参数的含义相同,但用法稍有不同。如果在hreg后面指定一个完整的主机名,那么就收集此台主机的状态信息。同时,hreg参数还支持正则表达式,只需提供一个主机名的标识,就可以批量检测包含此标识的所有主机,例如,有800台主机,主机名都包含有“bestjob”这个字符,那么只需设置“hreg=bestjob”即可实现一个脚本一次检查800台主机的服务状态。
checks:后面跟检测服务的指标值、检查条件和告警阀值。常见的服务指标有load_one、disk_free、swap_free、part_max_used等,检查条件有more(大于)、less(小于)、equal(等于)、notequal(不等于)四种,告警阀值根据实际应用环境来设置。这个参数还有个功能就是可以一次设置多个服务状态,每个服务之间用“:”进行分割即可。有了这个功能,就可以通过一个脚本一次检测多个服务的运行状态,大大提高了脚本检测的效率。
ignore_unknowns:此参数用来设置是否忽略UNKNOWN状态的服务。设置此参数为1表示忽略UNKNOWN状态的服务,反之,设置为0表示不忽略。
下面演示一下此脚本的用法,这里以检测主机名含有”bestjob“标识的主机为例,操作过程如下:
[root@centreonserver plugins]# ./check_host_regex.sh \
hreg=bestjob checks=load_one,more,15
Services OK = 796, CRIT/UNK = 4 ;
CRITICAL host0089.bestjob.com load_one = 16.96,
CRITICAL host0133.bestjob.com load_one = 22.91,
CRITICAL host0028.bestjob.com load_one = 15.02,
CRITICAL host0329.bestjob.com load_one = 16.68
此命令用来检测主机名含有”bestjob“标识的主机1分钟内的负载状态,当负载超过15时进行告警通知。从输出可知,主机名含有”bestjob“标识的主机共有800台,其中4台主机在一分钟内的负载状态超过15,并给出了超载主机的主机名和当前的负载状态值。
下面是一个脚本检测多台主机的多个服务的用法,操作过程如下:
[root@centreonserver plugins]# ./check_host_regex.sh \
hreg=bestjob checks=load_one,more,15:disk_free,less,900 ignore_unknowns=1
Services OK = 787, CRIT/UNK = 13 ;
CRITICAL host0081.bestjob.com load_one = 25.51 ,
CRITICAL host0246.bestjob.com load_one = 16.86 ,
CRITICAL host0003.bestjob.com disk_free = 576.318 GB,
CRITICAL dbmysql.bestjob.com disk_free = 520.721 GB,
CRITICAL webapp.bestjob.com disk_free = 461.966 GB,
CRITICAL host0200.bestjob.com disk_free = 852.420 GB,
CRITICAL host0055.bestjob.com disk_free = 279.465 GB,
CRITICAL dbdata.bestjob.com disk_free = 636.190 GB,
CRITICAL webui.bestjob.com disk_free = 525.538 GB,
CRITICAL server0232.bestjob.com disk_free = 861.330 GB,
CRITICAL server0159.bestjob.com disk_free = 801.443 GB,
CRITICAL host0080.bestjob.com disk_free = 739.467 GB,
CRITICAL etlserver.bestjob.com disk_free = 826.477 GB
此命令检测含有”bestjob“标识在主机1分钟内的负载状态和剩余空闲磁盘空间情况,并忽略UNKNOWN状态的服务。从检测结果中发现,在800台主机中,有13台主机出现负载或磁盘空闲空间告警问题,并输出了详细的告警信息。
最后,还需要将此脚本集成到Centreon平台上,以实现主机和服务的批量监控与批量报警。集成方法与上节介绍的集成check_ganglia.py的方法完全相同。
首选将check_host_regex.sh脚本放到/usr/lib64/nagios/plugins目录下,然后授权:
[root@localhost plugins]# chmod 755 check_host_regex.sh接着,在Centreon Web界面,选择 Configuration—>Commands—>Checks,然后点击Add新建一个Command,如下图所示。
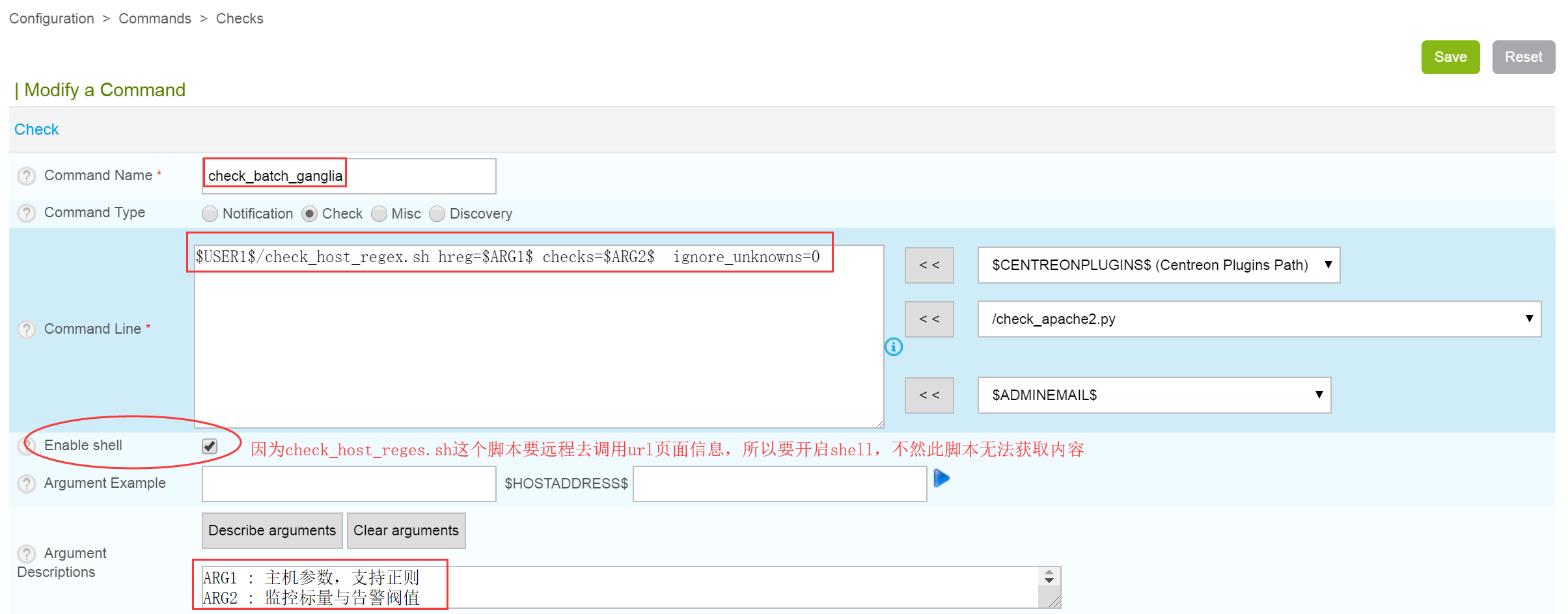
这里注意,“Enable shell”要选择启用。
然后,在Centreon Web界面选择Configuration—>Services—>Services by host,点击Add添加一个主机组服务,如下图所示。
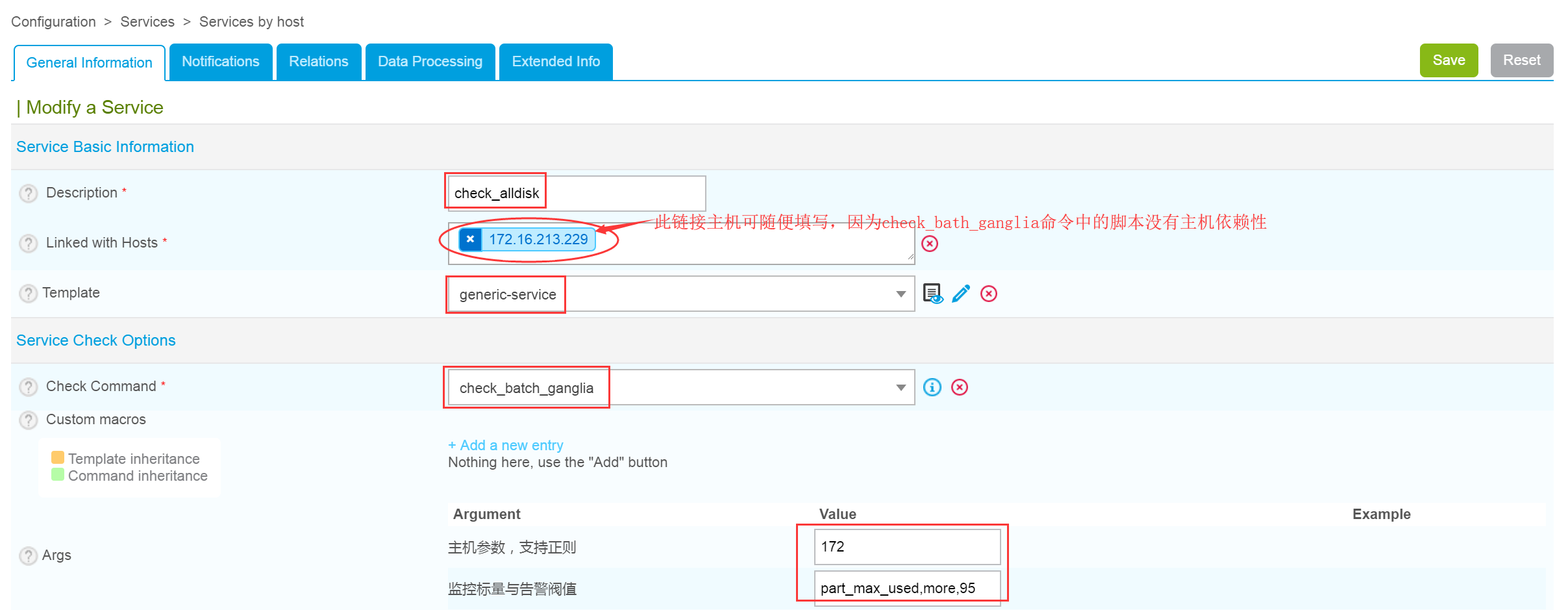
这里注意命令的引用以及命令中监控参数的写法。其中,“172”是引用的参数,表示以172开头的所有主机。“part_max_used,more,95”表示对磁盘分区最大占用空间做监控,当某分区或磁盘空间占用率超过95%,那么就告警。
在完成脚本集成后,重启Centreon服务,即可实现主机和服务的批量监控与报警,通过批量的方式监控主机状态。对于500台以上主机的运维环境来说,如果需要监控100个服务,那么每个脚本监控20个服务,5个脚本执行1次即可完成所有主机服务状态的监控,大大减少了脚本的执行次数,同时每个脚本的执行时间也不会显著加长。实践证明,通过批量监控的方式基本解决了大运维环境下的监控报警性能问题。
下图是Centreon在批量监控下的一个运行状态截图,通过此图可以清晰地看出哪些主机出现了告警问题,以及服务上次检测的时间和下次检测的时间。
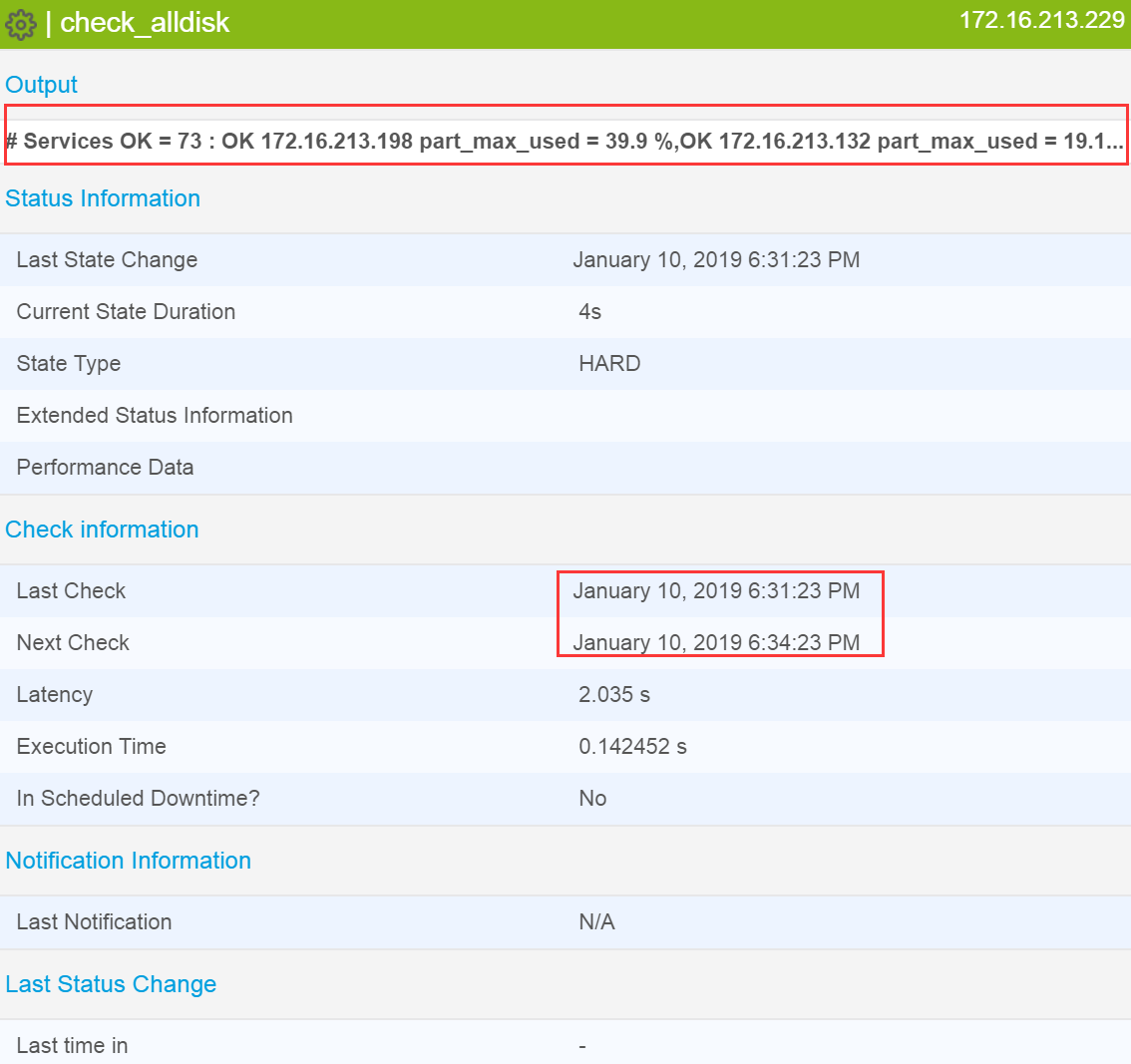
至此,在Centreon中实现批量数据收集和监控报警的方法已经介绍完毕。总体来说,都是借助现有的脚本稍作修改实现的,整个过程比较简单。
Ganglia与Centreon整合构建智能化监控报警平台的更多相关文章
- 分布式监控告警平台Centreon快速使用
一. Centreon概述 Centreon是一款功能强大的分布式IT监控系统,它通过第三方组件可以实现对网络.操作系统和应用程序的监控:首先,它是开源的,我们可以免费使用它:其次,它的底层采用nag ...
- Windows Azure功能更新:弹性伸缩(autoscale)、监控报警、移动服务及网站服务商用、新的虚拟机镜像
Windows Azure功能又更新了.此次更新包括1项重要更新和两个功能更新: 重要更新:云服务.网站支持按策略进行弹性伸缩 功能更新:两个预览版的服务(网站和移动)进入商用,虚拟机服务支持SQL ...
- MaxCompute 助力衣二三构建智能化运营工具
摘要:本文由衣二三CTO程异丁为大家讲解了如何基于MaxCompute构建智能化运营工具.衣二三作为亚洲最大的共享时装平台,MaxCompute是如何帮助它解决数据提取速度慢.数据口径差异等问题呢?程 ...
- SQL Server监控报警架构_如何添加报警
一.数据库邮件报警介绍 数据库邮件是从SQL Server数据库引擎发送电子邮件企业解决方案,使用简单传输协议(SMTP)发送邮件.发送邮件进程与数据库的进程隔离,因此可不用担心影响数据库服务器. 数 ...
- Python-WXPY实现微信监控报警
概述: 本文主要分享一下博主在学习wxpy 的过程中开发的一个小程序.博主在最近有一个监控报警的需求需要完成,然后刚好在学习wxpy 这个东西,因此很巧妙的将工作和学习联系在一起. 博文中主要使用到的 ...
- 持续集成之②:整合jenkins与代码质量管理平台Sonar并实现构建失败邮件通知
持续集成之②:整合jenkins与代码质量管理平台Sonar并实现构建失败邮件通知 一:Sonar是什么?Sonar 是一个用于代码质量管理的开放平台,通过插件机制,Sonar 可以集成不同的测试工具 ...
- Kubernetes集群的监控报警策略最佳实践
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/M2l0ZgSsVc7r69eFdTj/article/details/79652064 本文为Kub ...
- linux下日志文件error监控报警脚本分享
即对日志文件中的error进行监控,当日志文件中出现error关键字时,即可报警!(grep -i error 不区分大小写进行搜索"error"关键字,但是会将包含error大小 ...
- zabbix实现企业微信监控报警
一.zabbix基本说明 简介:zabbix基于Web界面的分布式系统监控的企业级开源软件.可以监控各种系统与设备,网络参数,保证服务器设备安全运营:提供灵活的通知机制.如果检测到的指标不达标,就实现 ...
随机推荐
- Md5实例
MD5实例 我的md5源码 当我们对数据进行操作时,存储到数据库时,有时候不希望别人能够看到,通过md5能够实现对数据的加密. java代码 ```javaimport org.springframe ...
- PHP Laravel 中使用简单的方法跟踪用户是否在线
今天,我的任务是,在 Laravel 应用程序用户个人资料页面上,用户名旁边添加一个绿点,表示他们是否在线.我首先想到的是,我们将需要启动一个 node.js 服务器并跟踪每个用户的活动套接字连接.然 ...
- libdispatch.dylib中dispatch_group的实现
semaphore和group都是libdispatch提供的基于信号量的同步机制,dispatch_group继承自dispatch_semaphore,使用libdispatch层的信号量算法.d ...
- java快速复习 一 基础语法
最近看很多算法书,比较不错的有不少都是java语言描述,所以用一天时间快速研究并整理java ,参考资料:java入门经典 Call this file "Example2.java&qu ...
- 使用zuul实现验证自定义请求头中的token
路由:她会把外部所有对请求转发到具体的微服务实例上,是实现外部访问同一接口的基础 过滤: 就是权限的检查, 判断当前的请求是否有权限区访问那些服务集群 搭建后台网关: 导入eureka - clien ...
- 有趣的动态规划(golang版本)
多年前就听过这个动态规划,最近在复习常用算法的时候才认真学习了一下,发现蛮有意思,和大家安利一波. 定义: 准确来说,动态规划师吧一个复杂问题分解成若干个子问题,并且寻找最优子问题的一种思想,而不是一 ...
- 第一次c语言作业。
第一次c语言作业 作业1 2.1 你对软件工程专业或者计算机科学与技术专业了解是怎样? 我认为计算机科学与技术是研究信息过程.用以表达此过程的信息结构和规则及其在信息处理系统中实现的学科.这门学科是为 ...
- Day01-初识 Python
1.CPU/内存/硬盘/操作系统 CPU :计算机的运算和处理中心,相当于人类的大脑. 内存 :暂时存储数据,临时加载数据应用程序. 硬盘 :长期存储数据. 操作系统:一个软件,连接计算机的硬件与所有 ...
- MATLAB中cell函数用法
cell元包是matlab中提供的一种数据类型,功能强大. 关于cell的创建: 1.跟一般创建举证一样,直接使用C = {A B D E}这种形式,不过这里把"[]"改成了}&q ...
- sina中的附件图片处理
这样写就会频繁的创建和销毁对象 因为setPhotos这个方法调用频繁 如果在里面直接用for循环创建9个UIImageView如果因为cell重用 比如在上一个cell中本来就有UIImageVie ...