Solr_全文检索引擎系统
Solr介绍:
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务。Solr可以独立运行在Jetty、Tomcat等这些Servlet容器中。
Solr的作用:
solr是一个现成的全文检索引擎系统, 放入tomcat下可以独立运行, 对外通过http协议提供全文检索服务(就是对索引和文档的增删改查服务), 在代码中可以通过solrJ(solr的客户端的jar包)来调用solr服务。
Lucene和solr的区别:
lucene是一个全文检索引擎工具包, 就是一堆jar包, 它放入tomcat下不能独立运行, 但是我们可以使用lucene来构建全文检索引擎系统;
solr底层是用lucene来开发的一个全文检索引擎系统, 放入tomcat下就可以独立运行, 对外通过http的形式,提供全文检索服务(索引和文档的增删改查服务)。
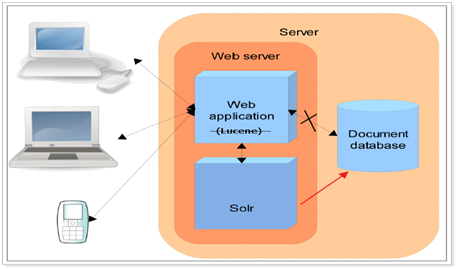
在Tomcat容器中部署solr工程的步骤:
1、下载solr压缩包,下载地址:http://archive.apache.org/dist/lucene/solr/(我这里使用的是solr-4.10.3);
2、准备好一个干净的Tomcat容器,并配置好JDK;
3、找到solr解压后的目录,将solr-4.10.3\example\webapps目录下的solr.war包放进Tomcat容器中运行,直接运行的目的是解压该war包,解压好之后关闭Tomcat容器并删除war包(必须要删除war包,否则再次运行时就覆盖了以前配置好的solr服务),开始部署solr服务;
4、找到solr解压后的目录,将solr-4.10.3\example\lib\ext目录下的所有jar包复制到Tomcat容器下的solr项目中的WEB-INF/lib目录下;
5、为solr服务准备家目录,找打solr解压后的目录,将solr-4.10.3\example目录下的有一个名称为solr的目录直接拷贝到硬盘根目录下,并且命名为solrHome(一般推荐这样做);
6、开始配置solr服务,找到Tomcat容器中部署的solr项目中的WEB-INF/web.xml文件,进行配置,首先打开<env-entry>标签,并且将刚刚拷贝好的solr的家目录的路径配置进去。
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>G:\solrHome</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
7、启动Tomcat容器,并通过http://127.0.0.1:8080/solr地址访问即可,如果看到以下界面则配置成功。

8、 solr服务配置成功之后,就会默认有一个collection1的实例,如果需要的话也可以配置多个,将solrHome目录下的collection1目录拷贝多个并将每个目录下的core.properties配置文件中修改一下即可,记得重启Tomcat容器。
通过SolrJ操作并访问solr服务中的数据:
什么是solrj?
solrj是访问solr服务的Java客户端,提供索引和搜索的请求方法。

创建工程,并引入solrj所需的jar包:
需求一:向solr服务中的collection1实例中添加数据?
//向solr服务器中的collection1实例中添加数据
@Test
public void add() throws Exception{
//1、创建与solr服务器的连接
/*
* http://localhost:8080/solr默认连接的是collection1实例
* 如果想连接其他的实例,如collection2、collection3则在连接时必须指定:http://localhost:8080/solr/实例名称
*/
SolrServer server = new HttpSolrServer("http://localhost:8080/solr"); //2、创建solr的文档对象并添加数据
SolrInputDocument document = new SolrInputDocument();
document.addField("id", "003");
document.addField("title", "solr"); //3、将文档对象添加到solr服务器
server.add(document); //4、提交
server.commit();
}
需求二:修改solr服务中collection3实例中的数据?
//修改solr服务器上collection3实例中的数据
@Test
public void update() throws Exception{
//1、连接solr服务器上collection3实例中的数据
SolrServer server = new HttpSolrServer("http://localhost:8080/solr/collection3");
//2、创建solr的文档对象并将数据修改
SolrInputDocument document = new SolrInputDocument();
document.addField("id", "001");
document.addField("title", "博学谷");
//3、将文档对象添加到solr服务器
server.add(document);
//4、提交
server.commit();
}
需求三:对solr服务中的数据进行删除操作,根据id删除、删除所有数据?
//删除solr服务器上collection2实例中的指定数据:
@Test
public void delete() throws Exception{
//1、连接solr服务器
SolrServer server = new HttpSolrServer("http://localhost:8080/solr/collection2");
//2、根据id删除数据
server.deleteById("002");
//3、提交
server.commit();
} //删除solr服务器上collection1实例中的所有数据:
@Test
public void deleteAll() throws Exception{
//1、连接solr服务器
SolrServer server = new HttpSolrServer("http://localhost:8080/solr/collection1");
//2、删除指定实例下的所有数据
server.deleteByQuery("*:*");
//3、提交
server.commit();
}
需求四:检索solr服务中collection3实例中的全部数据?
//查询solr服务器上collection3实例中所有的数据:
@Test
public void findAll() throws Exception{
//1、连接solr服务器
SolrServer server = new HttpSolrServer("http://localhost:8080/solr/collection3");
//2、创建查询对象
SolrQuery query = new SolrQuery();
//3、给查询对象中设置查询条件
query.setQuery("*:*");
//4、查询并获取响应
QueryResponse response = server.query(query);
//5、从响应中获得结果集
SolrDocumentList results = response.getResults();
//6、处理结果集
//输出结果集的总查询条数
System.out.println(results.getNumFound());
for (SolrDocument solrDocument : results) {
System.out.println("id*************"+solrDocument.get("id"));
System.out.println("title**********"+solrDocument.get("title"));
System.out.println("===========================================");
}
}
Solr_全文检索引擎系统的更多相关文章
- solr服务中集成IKAnalyzer中文分词器、集成dataimportHandler插件
昨天已经在Tomcat容器中成功的部署了solr全文检索引擎系统的服务:今天来分享一下solr服务在海量数据的网站中是如何实现数据的检索. 在solr服务中集成IKAnalyzer中文分词器的步骤: ...
- Lucene总结
数据的分类 结构化数据:有固定类型或者有固定长度的数据 例如:数据库中的数据(mysql,oracle等), 元数据(就是windows中的数据) 结构化数据搜索方法: 数据库中数据通过sql语句可以 ...
- Solr入门介绍
solr入门案例 solr是apache下的一个全文检索引擎系统. 我们需要在服务器上单独去部署solr, 通过它的客户端工具包solrJ, 就是一个 jar包, 集成到我们项目中来调用服务器中 ...
- [IR] Open Source Search Engines
From:http://blog.csdn.net/xum2008/article/details/8740063 本文档是对现有的开源的搜索引擎的一个简单介绍 1. Lucene Lucene ...
- 全文搜索技术—Lucene
1. 内容安排 实现一个文件的搜索功能,通过关键字搜索文件,凡是文件名或文件内容包括关键字的文件都需要找出来.还可以根据中文词语进程查询,并且支持多种条件查询. 本案例中的原始内容就是磁盘上的文件 ...
- 全文搜索技术—Solr
1. 学习计划 1. Solr的安装及配置 a) Solr整合tomcat b) Solr后台管理功能介绍 c) 配置中文分析器 2. 使用Solr的后台管理索引库 a) ...
- solr简单学习---1
*服务器配置略,比较复杂,看视频 1.导入jar包 package cn.itcast.solr; import org.apache.solr.client.solrj.SolrServer; im ...
- Solr全文检索框架
概述: 什么是Solr? Solr是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务.Solr可以独立运行在Jetty.tomcat.webLogic.webSh ...
- lucene 全文检索工具的介绍
Lucene:全文检索工具:这是一种思想,使用的是C语言写出来的 1.Lucene就是apache下的一个全文检索工具,一堆的jar包,我们可以使用lucene做一个谷歌和百度一样的搜索引擎系统 2. ...
随机推荐
- MySQL设置字段的默认值为当前系统时间
问题产生: 当我们在对某个字段进行设置时间默认值,该默认值必须是的当前记录的插入时间,那么就将当前系统时间作为该记录创建的时间. 应用场景: 1.在数据表中,要记录每条数据是什么时候创建的,应该由数据 ...
- 算法与数据结构(十一) 平衡二叉树(AVL树)
今天的博客是在上一篇博客的基础上进行的延伸.上一篇博客我们主要聊了二叉排序树,详情请戳<二叉排序树的查找.插入与删除>.本篇博客我们就在二叉排序树的基础上来聊聊平衡二叉树,也叫AVL树,A ...
- hadoop2.7之Mapper/reducer源码分析
一切从示例程序开始: 示例程序 Hadoop2.7 提供的示例程序WordCount.java package org.apache.hadoop.examples; import java.io.I ...
- [转载]Cookie/Session的机制与安全
Cookie和Session是为了在无状态的HTTP协议之上维护会话状态,使得服务器可以知道当前是和哪个客户在打交道.本文来详细讨论Cookie和Session的实现机制,以及其中涉及的安全问题. 因 ...
- 获取打开的Word文档
using Word = Microsoft.Office.Interop.Word; int _getApplicationErrorCount=0; bool _isMsOffice = true ...
- CSS入门常见的问题
写在前面:本文简单介绍一下css的三大特性:层叠性.继承性.优先级.以及margin,padding,浮动,定位几个知识点.限于水平,不深入探讨,仅作为学习总结. 1,三特性 1)层叠性:同标签同权重 ...
- C语言可以开发哪些项目?
C语言是我们大多数人的编程入门语言,对其也再熟悉不过了,不过很多初学者在学习的过程中难免会出现迷茫,比如:不知道C语言可以开发哪些项目,可以应用在哪些实际的开发中--,这些迷茫也导致了我们在学习的过程 ...
- Linux下用netstat查看网络状态、端口状态(转)
转:http://blog.csdn.net/guodongdongnumber1/article/details/11383019 在linux一般使用netstat 来查看系统端口使用情况步. ...
- appium+robotframework环境搭建
appium+robotframework环境搭建步骤(Windows系统的appium自动化测试,只适用于测试安卓机:ios机需要在mac搭建appium环境后测试) 搭建步骤,共分为3部分: 一. ...
- 支付宝web支付
过程 1. 用户下单 2. 商户后台产生订单 3. 请求支付宝web支付页面(将订单信息返回给用户---放在form里面---隐藏起来-----并通过脚本自动提交此form到支付宝web支付页) 4. ...