hdfs、yarn集成ranger
一、安装hdfs插件
从源码安装ranger的服务器上拷贝hdfs的插件到你需要安装的地方
1、解压安装
# tar zxvf ranger-2.1.0-hdfs-plugin.tar.gz -C /data1/hadoop
2、修改插件配置文件,如下
# cd /data1/hadoop/ranger-2.1.0-SNAPSHOT-hdfs-plugin/
修改install.properties文件
主要修改以下几个参数:
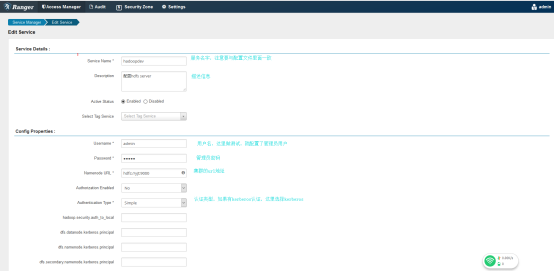
POLICY_MGR_URL= http://192.168.4.50:6080 #policy地址,也就是ranger-admin地址
REPOSITORY_NAME=hadoopdev #服务名字,在ranger-admin前台创建的时候,需要与这个参数值一样。
XAAUDIT.SOLR.ENABLE=true #开启审计日志
XAAUDIT.SOLR.URL=http://192.168.4.50:6083/solr/ranger_audits #solr地址
CUSTOM_USER=hduser #定义插件用户,我猜这个值是启动集群的用户
CUSTOM_GROUP=hduser
3、修改hdfs配置文件
# vim hdfs-site.xml
添加如下配置:
<property>
<name>dfs.namenode.inode.attributes.provider.class</name>
<value>org.apache.ranger.authorization.hadoop.RangerHdfsAuthorizer</value>
</property>
<property>
<name>dfs.permissions</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions.ContentSummary.subAccess</name>
<value>true</value>
</property>
4、启动插件
# sudo ./enable-hdfs-plugin.sh (需要root权限)
二、安装yarn插件
1、解压安装
# tar zxvf ranger-2.0.0-yarn-plugin.tar.gz -C /data1/hadoop
2、修改配置文件install.properties
修改如下属性:
POLICY_MGR_URL=http://192.168.4.50:6080
REPOSITORY_NAME=yarndev
XAAUDIT.SOLR.ENABLE=true
XAAUDIT.SOLR.URL=http://192.168.4.50:6083/solr/ranger_audits
CUSTOM_USER=hduser
CUSTOM_GROUP=hduser
3、修改yarn-site.xml配置文件
添加如下属性:
<property>
<name>yarn.acl.enable</name>
<value>true</value>
</property>
<property>
<name>yarn.authorization-provider</name>
<value>org.apache.ranger.authorization.yarn.authorizer.RangerYarnAuthorizer</value>
</property>
4、启动yarn插件
# ./enable-yarn-plugin.sh
# 重启集群
三、前台配置
1、hdfs配置
(1) 登录:http/192.168.4.50:6080
(1) 添加服务

点击加号添加服务
点击测试
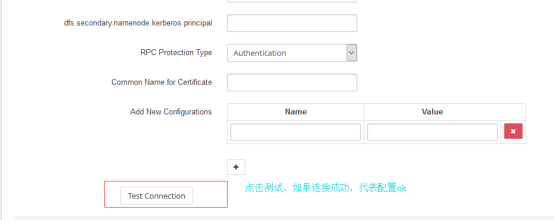

配置完了不要忘记点击保存。
配置完在前台界面如下:

(1) 配置策略
点击hadoopdev进行策略的配置

默认已经有两个策略,这里点击右上角进行策略的添加
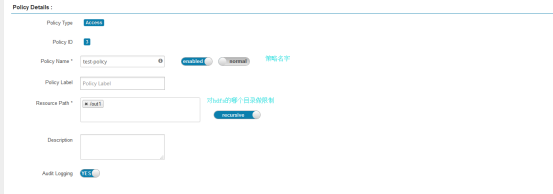

保存。
(1) 测试yjt这个用户是否还有对/out1这个目录有权限。

分析:
从上述可以看到,对于这个目录只要没有对用户或者组加决绝的ACL,正常是可以读取的,但是上述我们对yjt这个用户对/out1这个目录进行了策略控制(拒绝访问)的限制,可以看到,目前这个用户对于该目录没有权限读取了,说明配置成功。
2、yarn配置
(1) 添加服务
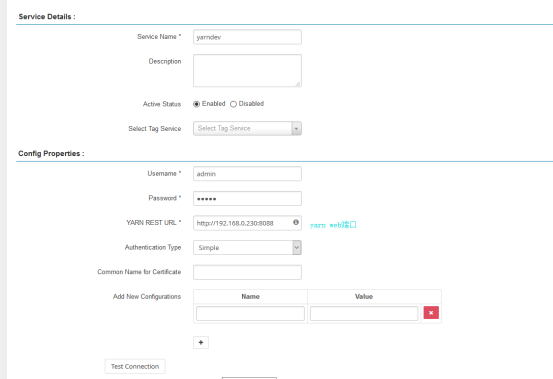
配置完可以进行测试连接,看配置是否ok
(1) 添加策略
对yarn的限制,主要是对于用户对队列的访问,以及任务提交限制
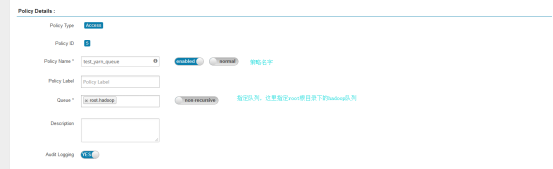
添加权限控制

(1) 测试yjt这个用户是否可以提交任务

从上可以看出,yjt这个用户,不允许提交任务到hadoop队列。
hdfs、yarn集成ranger的更多相关文章
- 2.安装hdfs yarn
下载hadoop压缩包设置hadoop环境变量设置hdfs环境变量设置yarn环境变量设置mapreduce环境变量修改hadoop配置设置core-site.xml设置hdfs-site.xml设置 ...
- Hue联合(hdfs yarn hive) 后续......................
1.启动hdfs,yarn start-all.sh 2.启动hive $ bin/hive $ bin/hive --service metastore & $ bin/hive --ser ...
- hdfs、yarn集成kerberos
1.kdc创建principal 1.1.创建认证用户 登陆到kdc服务器,使用root或者可以使用root权限的普通用户操作: # kadmin.local -q “addprinc -randke ...
- Hadoop HDFS, YARN ,MAPREDUCE,MAPREDUCE ON YARN
HDFS 系统架构图 NameNode 是主节点,存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在的DataNode等.NameNode将 ...
- hadoop/hdfs/yarn 详细命令搬运
转载自文章 http://www.cnblogs.com/davidwang456/p/5074108.html 安装完hadoop后,在hadoop的bin目录下有一系列命令: container- ...
- centos7 hdfs yarn spark 搭建笔记
1.搭建3台虚拟机 2.建立账户及信任关系 3.安装java wget jdk-xxx rpm -i jdk-xxx 4.添加环境变量(全部) export JAVA_HOME=/usr/java/j ...
- Hadoop源代码点滴-系统结构(HDFS+YARN)
Hadoop建立起HDFS和YARN两个字系统,前者是文件系统,管数据存储:后者是计算框架,管数据处理. 如果只有HDFS而没有YARN,那么Hadoop集群可以被用作容错哦的文件服务器,别的就没有什 ...
- hadoop集群的各部分一般都会使用到多个端口,有些是daemon之间进行交互之用,有些是用于RPC访问以及HTTP访问。而随着hadoop周边组件的增多,完全记不住哪个端口对应哪个应用,特收集记录如此,以便查询。这里包含我们使用到的组件:HDFS, YARN, Hbase, Hive, ZooKeeper:
组件 节点 默认端口 配置 用途说明 HDFS DataNode 50010 dfs.datanode.address datanode服务端口,用于数据传输 HDFS DataNode 50075 ...
- kerberos系列之hdfs&yarn认证配置
一.安装hadoop 1.解压安装包重命名安装目录 [root@cluster2_host1 data]# tar -zxvf hadoop-2.7.1.tar.gz -C /usr/local/ [ ...
随机推荐
- 混沌理论(Chaos theory)和非线性系统
混沌理论(Chaos theory)是关于非线性系统在一定参数条件下展现分岔(bifurcation).周期运动与非周期运动相互纠缠,以至于通向某种非周期有序运动的理论.在耗散系统和保守系统中,混沌运 ...
- AS shortcuts
stl => statelessstf => statefulalt+enter, select element => add pading or somethingselect c ...
- 【面试突击】-Redis常见面试题(二)
1.什么是Redis?简述它的优缺点? Redis本质上是一个Key-Value类型的内存数据库,很像memcached,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据flush到 ...
- Unicode 字符和UTF编码的理解
Unicode 编码的由来 我们都知道,计算机的内部全部是由二进制数字0, 1 组成的, 那么计算机就没有办法保存我们的文字, 这怎么行呢? 于是美国人就想了一个办法(计算机是由美国人发明的),也把文 ...
- Github强制找回管理员账号密码
步骤: 1. 登录Github所在的服务器,切换用户为git:su git 2. 进入Github的Rails控制台:gitlab-rails console production 3. 查看超级管理 ...
- .gitignore详解(附上eclipse的java项目的 .gitignore文件)
今天讲讲Git中非常重要的一个文件――.gitignore. 首先要强调一点,这个文件的完整文件名就是“.gitignore”,注意最前面有个“.”.这样没有扩展名的文件在Windows下不太好创建, ...
- Flink Runtime核心机制剖析(转)
本文主要介绍 Flink Runtime 的作业执行的核心机制.本文将首先介绍 Flink Runtime 的整体架构以及 Job 的基本执行流程,然后介绍在这个过程,Flink 是怎么进行资源管理. ...
- oracle 11g goldengate搭建(一)
初学ogg,基本了解ogg原理及架构之后,趁热打铁,搭建一个简单的学习环境,以实现目标:将sourcedb数据库的2个表:sourceuser.test01和sourceuser.dept通过ogg分 ...
- Linux DNS 分离解析
设置DNS分离解析可以对不同的客户端提供不同的域名解析记录.来自不同地址的客户机请求同一域名时,为其提供不同的解析结果. 安装 bind 包 [root@localhost ~]# yum insta ...
- kafka安装测试报错 could not be established. Broker may not be available.
修改 config 下配置文件 vim server.properties 配置本机ip listeners=PLAINTEXT://192.168.174.128:9092 执行命令时 bin/ka ...