Flink之state processor api原理
无论您是在生产环境中运行Apache Flink or还是在过去将Flink评估为计算框架,您都可能会问自己一个问题:如何在Flink保存点中访问,写入或更新状态?不再询问!Apache Flink 1.9.0引入了State Processor API,它是DataSet API的强大扩展,它允许读取,写入和修改Flink的保存点和检查点中的状态。
在这篇文章中,我们解释了为什么此功能对Flink来说是重要的一步,它的用途以及使用方法。最后,我们将讨论状态处理器API的未来,以及它如何与我们将Flink发展成为用于统一批处理和流处理的系统的计划保持一致。
使用Apache Flink进行状态流处理,直到Flink 1.9
很多流处理应用程序都是有状态的,并且大多数设计运行数月或数年。随着时间的流逝,它们中的许多会累积大量有价值的状态,如果状态由于故障而丢失,则可能非常昂贵,甚至无法重建。为了保证应用程序状态的一致性和持久性,Flink从一开始就采用了复杂的检查点和恢复机制。在每个版本中,Flink社区都添加了越来越多的与状态相关的功能,以提高检查点和恢复速度,应用程序的维护以及管理应用程序的实践。
但是,Flink用户通常要求的功能是“从外部”访问应用程序状态的能力。此请求的动机是需要验证或调试应用程序的状态,将应用程序的状态迁移到另一个应用程序,将应用程序从堆状态后端演进到RocksDB状态后端或导入的初始状态。来自外部系统(如关系数据库)的应用程序。
尽管有所有令人信服的理由在外部公开应用程序状态,但到目前为止,您的访问选项一直受到限制。Flink的Queryable State功能仅支持键查找(点查询),并且不能保证返回值的一致性(在应用程序从故障中恢复之前和之后,键的值可能不同)。而且,可查询状态不能用于添加或修改应用程序的状态。另外,保存点是应用程序状态的一致快照,因此无法访问,因为应用程序状态是使用自定义二进制格式编码的。
使用状态处理器API读取和写入应用程序状态
Flink 1.9附带的State Processor API确实改变了应用程序状态的游戏规则!简而言之,它使用Input和OutputFormats扩展了DataSet API以读取和写入保存点或检查点数据。由于DataSet和Table API的互操作性,您甚至可以使用关系Table API或SQL查询来分析和处理状态数据。
例如,您可以获取正在运行的流处理应用程序的保存点,并使用DataSet批处理程序对其进行分析,以验证该应用程序的行为是否正确。或者,您可以从任何存储中读取一批数据,对其进行预处理,然后将结果写入保存点,以用于引导流应用程序的状态。现在也可以修复不一致的状态条目。最后,状态处理器API开辟了许多方法来开发有状态的应用程序,这些方法以前被参数和设计选择所阻塞,这些参数和设计选择在启动后不会丢失应用程序的所有状态的情况下无法更改。例如,您现在可以任意修改状态的数据类型,调整运算符的最大并行度,拆分或合并运算符状态,重新分配运算符UID等。
将应用程序状态映射到数据集
状态处理器API将流应用程序的状态映射到一个或多个可以单独处理的数据集。为了能够使用API,您需要了解此映射的工作方式。
但是,让我们首先看看有状态的Flink作业是什么样的。Flink作业由operator组成,通常是一个或多个source operator,一些实际处理的operator以及一个或多个sink operator。每个operator在一个或多个任务中并行运行,并且可以使用不同类型的状态。operator可以具有零个,一个或多个“operator states”,这些状态被组织为以operator任务为范围的列表。如果将运算符应用于键控流,它还可以具有零个,一个或多个“keyed states”,它们的作用域范围是从每个已处理记录中提取的键。您可以将keyed states视为分布式键-值映射。
下图显示了应用程序“ MyApp”,该应用程序由称为“ Src”,“ Proc”和“ Snk”的三个运算符组成。Src具有一个operator state(os1),Proc具有一个operator state(os2)和两个keyed states(ks1,ks2),而Snk是无状态的。

MyApp的savepoint或checkpoint由所有状态的数据组成,这些数据的组织方式可以恢复每个任务的状态。在使用批处理作业处理savepoint(或checkpoint)的数据时,我们需要一个思维模型,将每个任务状态的数据映射到数据集或表中。实际上,我们可以将savepoint视为数据库。每个operator(由其UID标识)代表一个名称空间。operator的每个operator state都通过一个列映射到名称空间中的专用表,该列保存所有任务的状态数据。operator的所有keyed states都映射到一个表,该表由用于key的列和用于每个key state的一列组成。下图显示了MyApp的保存点如何映射到数据库
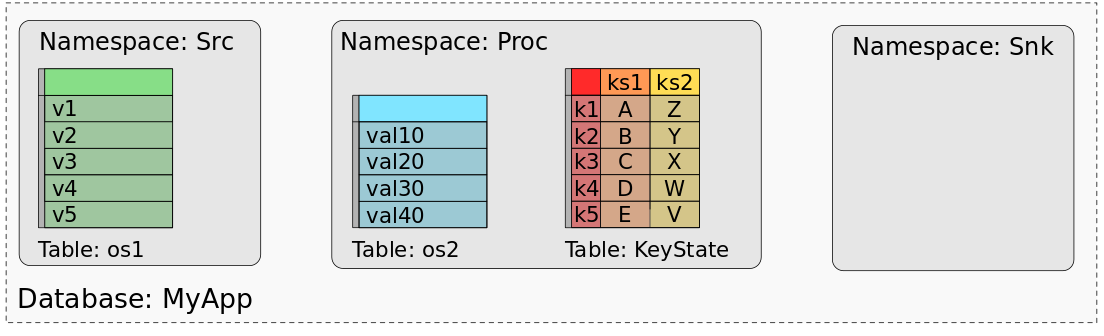
该图显示了“Src”的operator state的值如何映射到具有一列和五行的表,一行数据代表对于Src的所有并行任务中的一个并行实例。“ Proc”的operator state——os2,类似地映射到单个表。keyed state,ks1和ks2被组合到具有三列的单个表中,一列用于键,一列用于ks1,一列用于ks2。keyed表为两个keyed state的每个不同key保持一行。由于“ Snk”没有任何状态,因此其名称空间为空。
状态处理器API现在提供了创建,加载和编写savepoint的方法。您可以从已加载的savepoint读取dataSet,也可以将dataSet转换为状态并将其添加到savepoint。可以使用DataSet API的全部功能集来处理DataSet。使用这些构建块,可以解决所有前面提到的用例(以及更多用例)。如果您想详细了解如何使用State Processor API,请查看文档。
为什么要使用DataSet API?
如果您熟悉Flink的路线图,您可能会对State Processor API基于DataSet API感到惊讶。Flink社区计划使用BoundedStreams的概念扩展DataStream API,并弃用DataSet API。在设计此功能时,我们还评估了DataStream API或Table API,但他们都不能提供相应的支持。由于我们不想在Flink API的开发过程中阻止此功能,因此我们决定在DataSet API上构建该功能,但将其对DataSet API的依赖性降到最低。因此,将其迁移到另一个API应该相当容易。
总结
Flink用户很长时间以来一直要求一种功能来从外部访问和修改流应用程序的状态。使用state processor api,Flink 1.9.0最终将应用程序状态公开为可以操纵的数据格式。此功能为用户如何维护和管理Flink流应用程序打开了许多新可能性,包括流应用程序的任意演变以及应用程序状态的导出和引导。简而言之,state processor api使得savepoint不再是一个黑匣子。
本文翻译自https://flink.apache.org/feature/2019/09/13/state-processor-api.html
Flink之state processor api原理的更多相关文章
- Flink之state processor api实践
前不久,Flink社区发布了FLink 1.9版本,在其中包含了一个很重要的新特性,即state processor api,这个框架支持对checkpoint和savepoint进行操作,包括读取. ...
- State Processor API:如何读取,写入和修改 Flink 应用程序的状态
过去无论您是在生产中使用,还是调研Apache Flink,估计您总是会问这样一个问题:我该如何访问和更新Flink保存点(savepoint)中保存的state?不用再询问了,Apache Flin ...
- Win32调试API原理
在Win32中自带了一些API函数,它们提供了相当于一般调试器的大多数功能,这些函数统称为Win32调试API(Win32 Debug API).利用这些API可以做到加载一个程序或捆绑到一个正在运行 ...
- PHP服务器端API原理及示例讲解(接口开发)
http://www.jb51.net/article/136816.htm 下面小编就为大家分享一篇PHP服务器端API原理及示例讲解(接口开发),具有很好的参考价值,希望对大家有所帮助 相信大家都 ...
- state thread api 查询
state thread api 查询: http://state-threads.sourceforge.net/docs/reference.html
- vue 快速入门 系列 —— 侦测数据的变化 - [vue api 原理]
其他章节请看: vue 快速入门 系列 侦测数据的变化 - [vue api 原理] 前面(侦测数据的变化 - [基本实现])我们已经介绍了新增属性无法被侦测到,以及通过 delete 删除数据也不会 ...
- 从udaf谈flink的state
1.前言 本文主要基于实践过程中遇到的一系列问题,来详细说明Flink的状态后端是什么样的执行机制,以理解自定义函数应该怎么写比较合理,避免踩坑. 内容是基于Flink SQL的使用,主要说明自定义聚 ...
- 协程库st(state threads library)原理解析
协程库state threads library(以下简称st)是一个基于setjmp/longjmp实现的C语言版用户线程库或协程库(user level thread). 这里有一个基本的协程例子 ...
- 如何在 Apache Flink 中使用 Python API?
本文根据 Apache Flink 系列直播课程整理而成,由 Apache Flink PMC,阿里巴巴高级技术专家 孙金城 分享.重点为大家介绍 Flink Python API 的现状及未来规划, ...
随机推荐
- 3-美团 HTTP 服务治理实践
参考: 美团 HTTP 服务治理实践 Oceanus:美团HTTP流量定制化路由的实践
- csp 201809-1卖菜
问题描述 在一条街上有n个卖菜的商店,按1至n的顺序排成一排,这些商店都卖一种蔬菜. 第一天,每个商店都自己定了一个价格.店主们希望自己的菜价和其他商店的一致,第二天,每一家商店都会根据他自己和相邻商 ...
- apicloud开发app
1.apicloud官网 2.注册登录 3.开发控制台 4.创建应用 5.代码=>svn拉取代码,账号:注册账号的邮箱,密码:获取分支密码中的密码 6.编辑器下载对应的插件或者直接使用apicl ...
- 英语Lignaloes沉香木LIGNALOES单词
中文名沉香木 外文名Lignaloes 国内分布两广以及云南和福建等地 国外分布印度尼西亚.马来西亚.新加坡 沉香木是珍贵的香料,被用作燃烧熏香.提取香料.加入酒中,或直接雕刻成装饰品.沉香木又名沉水 ...
- <转>WPF 中的绑定
在WPF应用的开发过程中Binding是一个非常重要的部分. 在实际开发过程中Binding的不同种写法达到的效果相同但事实是存在很大区别的. 这里将实际中碰到过的问题做下汇总记录和理解. 1. so ...
- install和cp
在Makefile里会用到install,其他地方会用cp命令 主要区别: 如果目标文件存在,cp会先清空文件后往里写入新文件,而install则会先删除掉原先的文件然后写入新文件.这是因为往正在 使 ...
- Xcode修改项目名称
http://blog.sina.com.cn/s/blog_a42013280101blxo.html
- Spring事务部分知识点整理
目录 1.数据库事务基础概念 2.Spring中注解事务的使用 3.Spring事务使用注意场景 1.数据库事务基础概念 数据库事务是对数据库一次一系列的操作组成的单元,可以包含增删改查或者只有单 ...
- day9_7.9 函数的定义
一.基础 1.什么是函数? 函数就是工具,方便开发人员开发软件,非常简洁的工具. 函数的关键字是def 在函数的编写阶段,只检验其语法是否正确,不检验代码. 在函数的调用阶段,可以通过函数名+()来调 ...
- LeetCode 611. Valid Triangle Number有效三角形的个数 (C++)
题目: Given an array consists of non-negative integers, your task is to count the number of triplets c ...