1. Spark基础解析
1.1 Spark概述
1.1.1 什么是Spark
官网:http://spark.apache.org
Spark是一种快速、通用、可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache顶级项目。项目使用Scala进行编写。
目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLib、SparkR等子项目,Spark是基于内存计算的大数据并行计算框架。除了扩展了广泛使用的MapReduce计算模型,而且高效的支持更多计算模式,包括交互式查询和流处理。Spark适用于各种各样原先需要多种不同的分布式平台场景,包括批处理、迭代算法、交互式查询、流处理。通过在一个统一的框架下支持这些不同的计算,Spark使我们可以简单而低耗地把各种处理流程整合在一起。而这样的组合,在实际的数据分析过程中是很有意义的。不仅如此,Spark的这种特性还大大减轻了原先需要对各种平台分别管理的负担。
大一统的软件栈,各个组件关系密切并且可以相互调用,这种设计有几个好处:
1、软件栈中所有的程序库和高级组件都可以从下层的改进中获益
2、运行整个软件栈的代价变小了,不需要运行5到10套独立的软件系统了,一个机构只需要运行一套软件系统即可。系统的部署、维护、测试、支持等大大缩减。
3、能够构建出无缝整合不同处理模型的应用
Spark的内置项目如下:
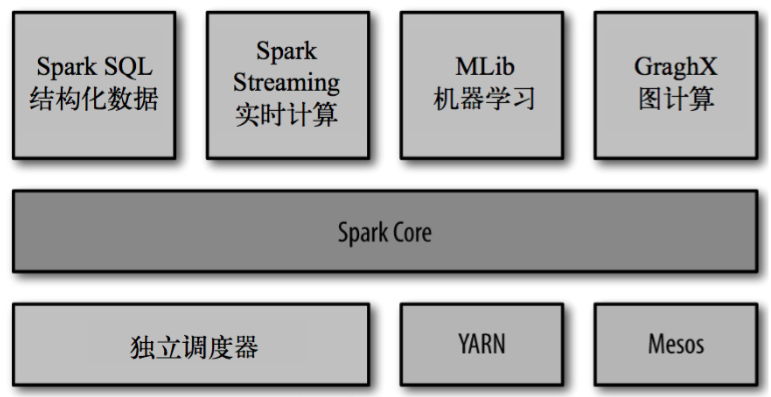
Spark Core:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(resilient distributed dataset,简称RDD)的API的定义
Spark SQL:是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用SQL或者Apache Hive版本的SQL方言(HQL)来查询数据。Spark SQL支持多种数据源,比如Hive表、Parquet以及JSON等
Spark Streaming:是Spark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API,并且与Spark Core中的RDD API高度对应
Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能
集群管理器:Spark设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器(cluster manager)上运行,包括Hadoop YARN、Apache Mesos,以及Spark自带的一个简易调度器,叫做独立调度器
Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于凤巢、大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群
1.2 Spark特点
1.2.1 快
与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理流数据。计算的中间结果是存在于内存中的。

1.2.2 易用
Spark支持Java、Python、Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法

1.2.3 通用
Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本
1.2.4 兼容性
Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark也可以不依赖第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用Spark。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具

1.3 Spark的用户和用途
大致把Spark的用例分为两类:数据科学应用和数据处理应用。也就对应的有两种人群:数据科学家和工程师
1.3.1 数据科学任务
主要是数据分析领域,数据科学家要负责分析数据并建模,具备SQL、统计、预测建模(机器学习)等方面的经验,以及一定的使用Python、Matlab或R语言进行编程的能力
1.3.2 数据处理应用
工程师定义为使用Spark开发生产环境中的数据处理应用的软件开发者,通过对接Spark的API实现对数据的处理和转换等任务
1.4 Spark核心概念
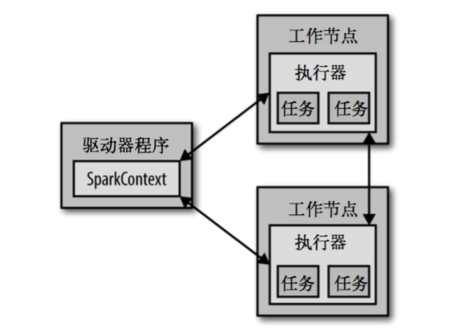
每个Spark应用都由一个驱动程序(driver program)来发起集群上的各种并行操作。驱动器程序包含应用的main函数,并且定义了集群上的分布式数据集,还对这些分布式数据集应用了相关操作
驱动器程序通过一个SparkContext对象来访问Spark。这个对象代表对计算集群的一个连接。shell启动时已经自动创建了一个SparkContext对象,是一个叫做sc的变量
驱动器程序一般要管理多个执行器(executor)节点
1. Spark基础解析的更多相关文章
- 【大数据】Spark基础解析
第1章 Spark概述 1.1 什么是Spark 1.2 Spark内置模块 Spark Core:实现了Spark的基本功能,包含任务调度.内存管理.错误恢复.与存储系统交互等模块.Spark Co ...
- 【大数据】Spark内核解析
1. Spark 内核概述 Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制.Spark任务调度机制.Spark内存管理机制.Spark核心功能的运行原理等,熟练掌握Spa ...
- 最全的spark基础知识解答
原文:http://www.36dsj.com/archives/61155 一. Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduc ...
- 【Spark 内核】 Spark 内核解析-下
Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制.Spark任务调度机制.Spark内存管理机制.Spark核心功能的运行原理等,熟练掌握Spark内核原理,能够帮助我们更 ...
- Spark内核解析
Spark内核概述 Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制.Spark任务调度机制.Spark内存管理机制.Spark核心功能的运行原理等,熟练掌握Spark内核 ...
- java基础解析系列(四)---LinkedHashMap的原理及LRU算法的实现
java基础解析系列(四)---LinkedHashMap的原理及LRU算法的实现 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析 ...
- java基础解析系列(五)---HashMap并发下的问题以及HashTable和CurrentHashMap的区别
java基础解析系列(五)---HashMap并发下的问题以及HashTable和CurrentHashMap的区别 目录 java基础解析系列(一)---String.StringBuffer.St ...
- java基础解析系列(六)---深入注解原理及使用
java基础解析系列(六)---注解原理及使用 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析系列(二)---Integer ja ...
- java基础解析系列(七)---ThreadLocal原理分析
java基础解析系列(七)---ThreadLocal原理分析 目录 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析系列(二)-- ...
随机推荐
- 【转】利用Python将多个PDF合并为一个
本脚本用来合并pdf文件,输出的pdf文件按输入的pdf文件名生成书签 使用示例如下: python pdfmerge.py -p "D:\pdf-files" -o " ...
- ArcPy python实例教程-条件平差-测量平差
ArcPy python实例教程-条件平差-测量平差 商务合作,科技咨询,版权转让:向日葵,135-4855__4328,xiexiaokui#qq.com 输入参数:条件方程的系数,观测值,常数项和 ...
- PHP实现执行定时任务
首先用命令检查服务是否在运行 systemctl status crond.service 如果服务器上没有装有crontab ,则可以执行 yum install vixie-cron yum in ...
- 干货满满!10分钟看懂Docker和K8S(转)
2010年,几个搞IT的年轻人,在美国旧金山成立了一家名叫“dotCloud”的公司. 这家公司主要提供基于PaaS的云计算技术服务.具体来说,是和LXC有关的容器技术. LXC,就是Linux容器虚 ...
- 算力和AI-ZILLIZ
特征向量检索加速.https://www.zilliz.com/ 公司介绍: MegaWise异构众核加速数据库 MegaWise是ZILLIZ独立自主研发的新一代异构众核加速数据库系统.MegaWi ...
- PHP获取远程文件的大小,通过ob_get_contents实现
function remote_filesize($uri,$user='',$pw='') { ob_start(); $ch = curl_init($uri); curl_setopt($ch, ...
- openresty开发系列30--openresty中使用http模块
OpenResty默认没有提供Http客户端,需要使用第三方提供的插件 我们可以从github上搜索相应的客户端,比如https://github.com/pintsized/lua-resty-ht ...
- consul_nginx_uprsync动态负载均衡
consul_nginx_uprsync动态负载均衡 环境准备: 原理描述: 将Nginx的负载均衡后端服务器配置信息写入consul的接口中,upsync插件通过读取consul的配置,然后持久化到 ...
- 005-guava 集合-集合工具类-java.util.Collections中未包含的集合工具[Maps,Lists,Sets],Iterables、Multisets、Multimaps、Tables
一.概述 工具类与特定集合接口的对应关系归纳如下: 集合接口 属于JDK还是Guava 对应的Guava工具类 Collection JDK Collections2:不要和java.util.Col ...
- pyenv、virtualenv、virtualenvwrapper三种python多版本介绍
今天有把此前接触过的三种python实现多版本环境用到的软件pyenv.virtualenv.virtualenvwrapper,了解了一番,现做如下总结: 一.pyenv: 是针对python多版本 ...