[基础]斯坦福cs231n课程视频笔记(二) 神经网络的介绍
Introduction to Neural Networks
BP
梯度反向传播BackPropagation,是神经网络中的重要算法,主要思想是:
计算网络的输出与期望输出之间的误差
将误差从网络的输出层回传,沿着网络逐层传递,传递的是损失值相对当前层里参数的梯度
当每一层都接收到该层的参数梯度时,沿着梯度方向更新参数
用更新后的网络参数来计算新的输出,再重新计算误差,误差梯度回传,循环上述过程直到参数收敛
结合计算图来理解:
computation graph 计算图
任何函数都可以拆成计算图的形式
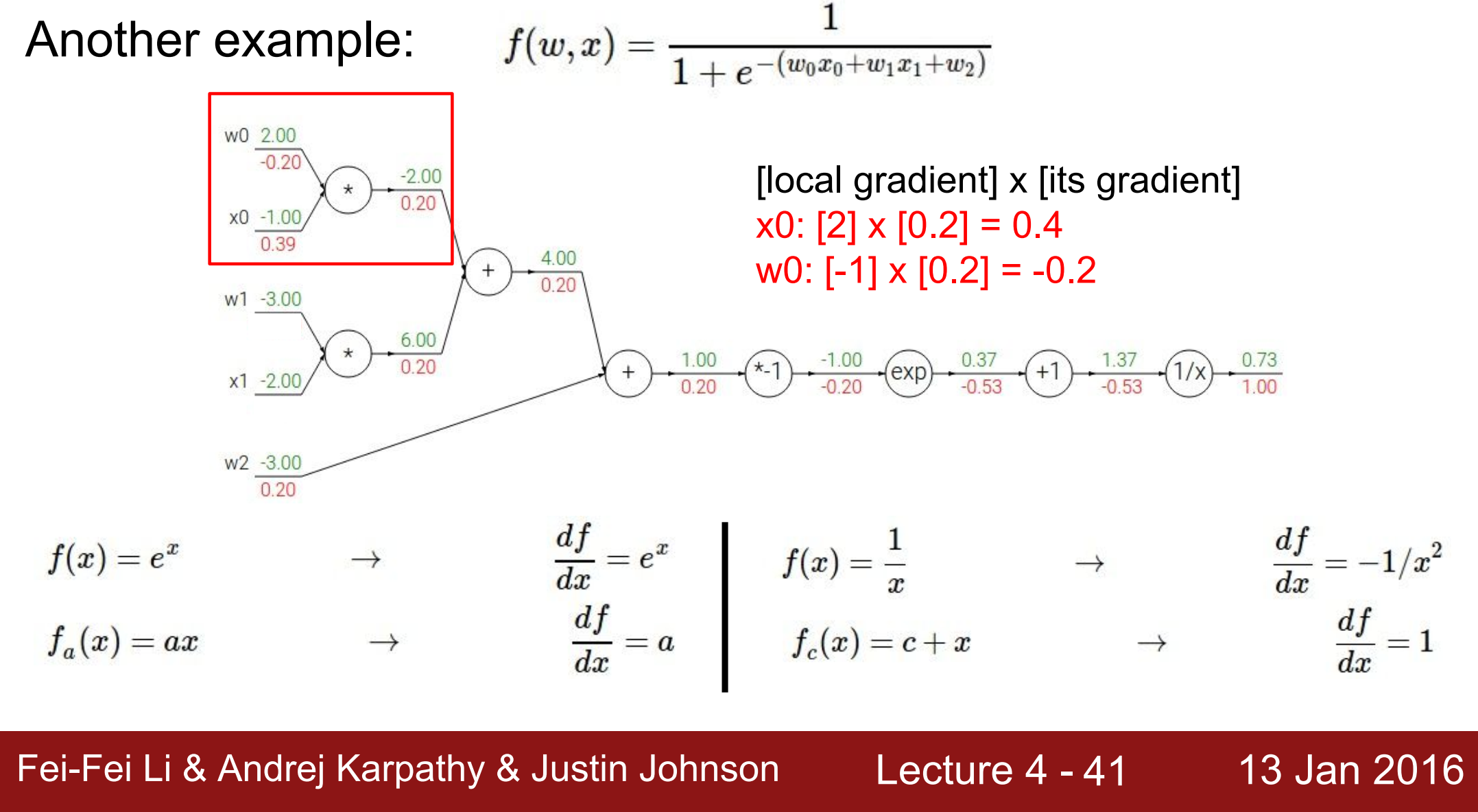
绿色的部分,是每个计算节点的输入值和输出值,即forward pass
红色的部分,是网络最终输出对于每个节点的梯度= local gradient * 前一个节点的梯度,即backward pass
- 最终输出的节点
\[\frac{\partial f}{\partial f} = 1 \] - 对前一个节点的梯度:记 $f = \frac{1}{z} $ (z为中间变量的名称),
\[ \frac{\partial f}{\partial z} = \frac{\partial f}{\partial f} * \frac{\partial f}{\partial z} = 1 * \frac{-1}{1.37^2} =-0.53 \] - 对倒数第二个节点的梯度:记 $z = h+1 $,
\[ \frac{\partial f}{\partial h} = \frac{\partial f}{\partial z} * \frac{\partial z}{\partial h} = -0.53*1 =-0.53 \] - 对倒数第三个节点的梯度:记 \(h = e^m\) ,
\[ \frac{\partial f}{\partial m} = \frac{\partial f}{\partial h} * \frac{\partial h}{\partial m} = -0.53*e^{-1} =-0.20 \]
将一维推广到多维,现在假设W是 2 * 2,x是 2 维向量

【注意】
在全连接网络Fully Connected Network中,做反向传播时,误差对偏置bias的求导,需要对所有样本求和,这是因为loss就是对所有样本求和的结果,简单推理如下:
\[
shape \ of\ x:(N,D),\ shape\ of\ w:(D,), \ shape \ of \ b:(D,) \\
loss = \sum_{i=1}^N L_i \ , loss \ is \ a \ constant \\
d\ scores = \frac{d\ loss}{d\ scores} \ , shape \ is\ (N,D) \\
scores = wx + b \\
d\ b_j = \frac{d\ loss_j}{d\ b_j} = \frac{d\ loss}{d\ scores} * \frac{d\ scores}{d\ b} =\sum_i^N d\ scores_{ij} \\
<=> d\ b_j = \frac{d\ scores_{1j}+d\ scores_{2j}+...}{d\ b_j} \\ (d\ loss_j = \sum_i^N L_{ij} )
\]
Nerual Network
neural network are a class of functions where we have simpler functions that are stacked on top of each other with non-linear functions in-between.. and we stacked them in a hierarchical way in order to make up a more complex non-linear function
可以看做是线性函数的叠加,同时线性函数层之间还夹杂着非线性层,来使网络具有非线性
- 如果单纯全是线性层的话,网络的代表能力会比较差 即难以表示复杂的变化:想象一下 多个线性函数的叠加在一起得到的也是线性函数 而线性函数的表达能力比较差 比如二维坐标系x-y下的线性函数只是一条直线,当特征产生一些变化 输出必须随之变化
网络中不同线性函数层是在提取不同层次的特征,网络中较低的层提取低层的语义特征,越高层提取到的特征越抽象。比如:
- 网络有两层线性函数层,对于输入图像,第一层的特征(or templates)有专门检测左侧人脸的滤波器,和检测右侧人脸的滤波器;而第二层特征是对第一层提取出来的特征做weighted sum 可以理解为第二层的特征有专门检测人脸的滤波器
- 如果输入图像是左侧人脸,那么经过第一层特征提取之后,检测左侧人脸滤波器得到的结果(score)比检测右侧人脸滤波器得到的结果高,然后输入到第二层,经过第二层的特征提取之后,在检测人脸的滤波器得到的结果(score)比在检测车的滤波器得到的结果高,第二层的输出即为网络的输出。
- 如果输入图像是正面人脸,那么经过第一层,左侧人脸滤波器得到的结果可能大致等于右侧人脸滤波器的结果,而经过第二层之后,得到的输出仍然也是人脸的可能性高于车辆。
Convolutional Neural Network
参见之前的博文
[基础]斯坦福cs231n课程视频笔记(二) 神经网络的介绍的更多相关文章
- [基础]斯坦福cs231n课程视频笔记(三) 训练神经网络
目录 training Neural Network Activation function sigmoid ReLU Preprocessing Batch Normalization 权重初始化 ...
- [基础]斯坦福cs231n课程视频笔记(一) 图片分类之使用线性分类器
线性分类器的基本模型: f = Wx Loss Function and Optimization 1. LossFunction 衡量在当前的模型(参数矩阵W)的效果好坏 Multiclass SV ...
- 转:深度学习斯坦福cs231n 课程笔记
http://blog.csdn.net/dinosoft/article/details/51813615 前言 对于深度学习,新手我推荐先看UFLDL,不做assignment的话,一两个晚上就可 ...
- 神经网络系列学习笔记(二)——神经网络之DNN学习笔记
一.单层感知机(perceptron) 拥有输入层.输出层和一个隐含层.输入的特征向量通过隐含层变换到达输出层,在输出层得到分类结果: 缺点:无法模拟稍复杂一些的函数(例如简单的异或计算). 解决办法 ...
- Linux入门视频笔记二(Shell)
一.Shell脚本编程基础 1.简单地理解是脚本就是一堆的Linux命令或其他命令,把他们写到一起,打包成一个文件就是脚本,Shell脚本一般以.sh后缀结尾 2.sh text.sh:运行text. ...
- javass 视频笔记二 (关键字,标示符,常量变量,运算符和if-else)
1,java的关键字和标识符2,java的基本数据类型3,变量和常量4,java的运算符5,if-else if - else表达式1,java的关键字和标识符 1.1,所有关键字都要小写 ...
- 《分布式Java应用之基础与实践》读书笔记二
远程调用方式就是尽可能地使系统间的通信和系统内一样,让使用者感觉调用远程同调用本地一样,但其实没没有办法做到完全透明,例如由于远程调用带来的网络问题.超时问题.序列化/反序列化问题.调式复杂的问题等. ...
- 斯坦福机器学习课程 Exercise 习题二
Exercise 2: Linear Regression 话说LaTex用起来好爽 Matlab代码 迭代并且画出拟合曲线 Linear regression 公式如下 hθ(x)=θTx=∑i=0 ...
- CS231n课程笔记翻译9:卷积神经网络笔记
译者注:本文翻译自斯坦福CS231n课程笔记ConvNet notes,由课程教师Andrej Karpathy授权进行翻译.本篇教程由杜客和猴子翻译完成,堃堃和李艺颖进行校对修改. 原文如下 内容列 ...
随机推荐
- MASK-RCNN(1)
MASK-RCNN是一个多用途的网络,可以用来做目标检测,实例分割或者人体姿态识别.主要结构如下. 简单的说,就是首先用Faster-RCNN获得ROI,再进行ROI Align,然后输出ROI的分类 ...
- mysql清空带外键的表
set FOREIGN_KEY_CHECKS =0;TRUNCATE memo;TRUNCATE customer;set FOREIGN_KEY_CHECKS =1;
- vue-router 之 keep-alive路由缓存处理include+exclude
keep-alive 简介 keep-alive 是 Vue 内置的一个组件,可以使被包含的组件保留状态,或避免重新渲染. 用法也很简单: <keep-alive> <compone ...
- 二,java框架学习
二,java框架学习 实体类的编写规则 实体类里面的属性是私有的 私有属性使用公开的set,get,方法操作 要求实体类有属性作为唯一值(一般使用id值) 实体类属性建议不使用基本数据类型,使用基本数 ...
- C++ 模板特化、偏特化测试程序
#include <iostream> // 偏特化的模板不会自己添加构造函数 ctor 和 析构函数 dtor #if 1 // P1 template <typename T1, ...
- 判断101-200之间有多少个素数,并输出所有素数,方法:用一个数分别去除2到sqrt(这个数),如果能被整除, 则表明此数不是素数,反之是素数。
<?php$sum=0;for($i=101;$i<=200;$i++){ for($j=2;$j<=sqrt($i);$j++) { if($i%$j==0 ...
- NOIP模拟赛 迷路
题目描述 Description \(FYH\) 在 \(ns\) 星系迷路了,情急之下,他找到了你.现在,解救 \(FYH\) 的重任就落在了你的肩上了. \(ns\) 星系有 \(n\) 颗星球, ...
- 前端/h5/React D3.js实现根据数据动态更新图形/类似进度实时变化效果
最近接到一个需求,在满足规则下,实现类似这种展示效果,其实就是用图形反映数据(NK,一种干扰值) 运行后,它其实是不断在动的,每格都可能显示灰色或者彩色 这里一共是10个格子,每格代表一个范围边界,说 ...
- 关于XSS攻击
1.XSS XSS(Cross Site Scripting)攻击全称跨站脚本攻击,为了不与CSS(Cascading Style Sheets)混淆,故将跨站脚本攻击缩写为XSS,XSS是一种经常出 ...
- @Resource和@Autowire用谁?
我选了@Resource 1.当注入的属性是接口 1.1在接口只有一个实现类的时候,@Resource和@Autowire 在功能上是没有区别的 1.2如果接口有多个实现类,在写法上,@Autowir ...