Generative Adversarial Networks overview(2)
Libo1575899134@outlook.com
Libo
(原创文章,转发请注明作者)
本文章会先从Gan的简单应用示例讲起,从三个方面问题以及解决思路覆盖25篇GAN论文,第二个大部分会进一步讲Gan的所有领域应用
-----------------------------------------------------------------------------------
上一篇说到最近有人关于encoder给出了更加直观的解释:
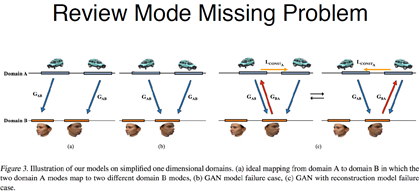
从另一个角度理解,传统的A是我们希望的map,两个domain的图像,都是向左的map到一起,都是向右的map到一起,如果用传统Gan去学,会导致b的情况,Mode Missing的问题
这样会导致生成这样的东西很模糊,有点像生成的平均一样,可以和之前很多Gan的模型生成的比较模糊联系到一起
第三个是简单把一个Gan加一个encoder的办法,细节不一样,但是概括了刚才说的三种方法,如果只加一个encoder的话,虽然能在一定程度上限制B领域的东西也能映射会A邻域,就会导致结果出现震荡,一会学到朝左的箭头,一会学到朝右的箭头,导致训练出来的结果只是一个偶然。
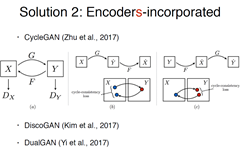
所以就有了后面三篇基本长得一样的,后面三篇基本长的一样,cycleGan 来自朱骏彦的作品,如果一个encoder学的是单向隐射,G:x->y 最好也要求F:Y->x,这个才能保证学到的东西是一一对应的
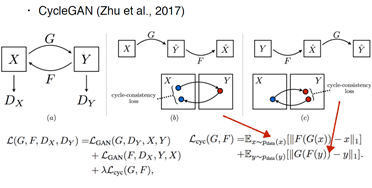
可以明显看到,Gan Loss函数包括了一个原始Gan+另一个方向的Gan+CycGan
两个encoder 两组Gan
下面是CycleGan的结果,把马变斑马,夏天变冬天,把画作变真实照片,风格迁移的任务,工作的突破是可以将整幅图的风格转换成莫奈的风格,而不是莫奈某幅画的风格
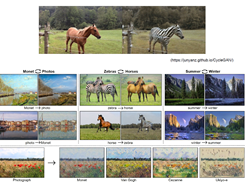

还可以转换成不同画家的作品的图片


下面是苹果变橘子,作者补充到,CycleGan只能应用到形状比较相似的物品上,马和斑马其实也是有细微的差异,苹果变成香蕉可能暂时不会work

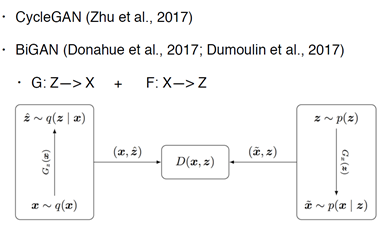
CycleGan也提到了一些Mode-missing的问题,下图对比了BiGan和CoGan的工作,这两篇工作也用到了两个encoder,并不是向那三篇说的只用了一个encoder,但是明显看到BiGan没学起来。

那么具体来看BiGan做了哪些事情,BiGan并不是直接学两个样本空间的映射,而是学一个样本空间和一个隐含空间的特征映射,Z代表的就是隐空间。和CycleGan 不太一样的地方,说明了隐空间学习有时候不如在样本空间直接学。
DiscoGan 解释ModeMissing 就会更有意思一些,a,代表的是原始的图像,b ,是Gan ,c ,是加了一个encoder的Gan, D,是加了两个encoder的双向Gan。
比较后面两幅图,为什么只加一个encoder对于Mode missing的问题也解决的不太好呢,C中绿色区域的三个点其实没有区出来,下面的区分情况也不太好,但是如多是DiscoGan 就可以把10个点,10个Mode,区分的非常好。不同的颜色和背景代表了判别器的输出大小,如果颜色的深浅很均匀的话(0.8-0.6)学的比较好。
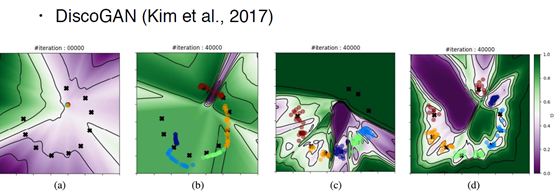
B是一个encoder的情况,C是用2个encoder的情况。A 是传统gan Mode-missing 最严重的情况,基本学出来都是一个方向的。

所以第二个Mode-Missing的第三类问题问题已经基本解决了,双向的encoder&noise input。就是即使不考虑JS散度,优化目标会导致Mode-Missing问题,刚才的一些方法就可以解决。

最后一个是比较火的Wasserstein Distance或者也叫WGan,翻译成中文推土机距离,可以看到下图γ属于联合分布,把生成数据分布和真实数据分布做一个联合分布,γ属于联合分布中的任意一种分布,对于这样的分布,取两个点的距离的整体的期望的下界。

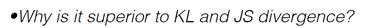
为什么比KL散度和JS散度好呢?为什么叫推土机距离,形象理解为把X变到Y需要推的土有多少

假设X和Y的分布分别如下图,需要费多大的力才能把X的形状的分布变成Y形状的分布,如果是一个离散的分布可以这么理解,假如有10个可能的样本,10种可能的取值,不同的概率是柱子的高度,如何可以变到右边,当然变的不是样本取值而只是概率值,是一个NP问题且并不是唯一的,有些解需要费的力比较大,类似汉诺塔,最优规划路径问题
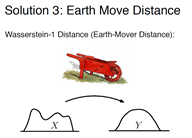

所以距离可以理解成:把生成分布变到真实分布所需要的最优距离的最小值,为什么比KL和JS散度好呢?在一种可以忽略不计的假设下,它是一个连续可分可微的度量,且最重要的是他直接解决了JS散度在两个分布不重合的时候,无意义这件事。即使两个分布远在天边 WD也可以衡量两者距离到底有多远,所以永远都可以提供一个有效的梯度,直接解决了梯度消失 ,不稳定的问题。


如果用JSD来做的话,两个分布就会有一些突变,但是如果Wasserstein的话就是渐变的

有了距离以后怎么具体变成Gan的目标函数呢?因为下届是不能直接计算的,于是用了一个KR对偶性的方法,做了转换,损失函数里的log被去掉了,下面再解释为什么没有了。

有了之后,并不是从刚才的直接等价过来的,条件是需要D的function是符合Lipschitz连续性的

解释下什么是Lipschitz连续性,对于一个连续函数或者实数的function,如果导函数的绝对值,在任意情况下都小于一个常数的话,那么就说这个函数是Lipschitz 连续的。要求函数导数的变化程度或者倾斜度角度不要太大

有了Lipschitz连续性之后就要把WD应用到Gan的损失函数中,需要满足D的函数符合这个连续性,所以原始的paper 就是把D的导数(weight)限制到一定的范围内,[-c,c] 如果超过这个范围就用weight clip的方法截断,就会出现个问题,选择C其实挺重要的,论文里也给了一些解决办法。

总之,WGan就可以改变gan中的目标函数,去掉log,应为原始的判别器是在判别一个二分类问题,fake or true ? 所以D的top layer 一般是一个sigmod layer,现在做了这个转变其实是在逼近Wasserstein的距离,逼近两个分布的距离,相当于变成一个回归问题,把最后的sigmod直接给去掉了

所以作者发现,如果用了WD之后,绿色和蓝色是原始Gan中的分布,发现梯度消失的很剧烈,D很快就变平了,就是没有梯度了,给它啥都判断的很对,也就没有啥变化了,用Wasserstein学出来发现梯度就会很平稳,形象证明了他们可以解决这个问题。
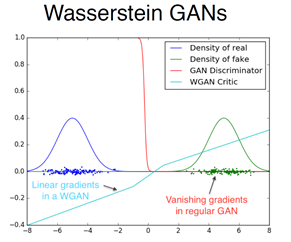
所以第二个困难点就解决了,第二个困难点在于如果用JS散度来衡量两个几乎不可能重叠的分布的时候,梯度没有办法得到有效信息,梯度消失的问题,就被Wgan解决掉了。

接下来介绍W-gan 的优点,和能做哪些事情,因为现在D输出的不是0或者1,输出的是一个真实值,说明了它逼近distance的程度,所以作者指出D的输出可以作为衡量trianing的进度,随着训练进行的越来越好,距离应该降低越来越少,蓝色曲线越来越低,图像质量越来越好
所以它做到了两件事,一个是终于有一个可靠的数值,来衡量生成样本的质量,因为生成样本的评价问题是个很难的问题,一直在用人工评价或者很多不靠谱的方法。相当于提出了副产品。
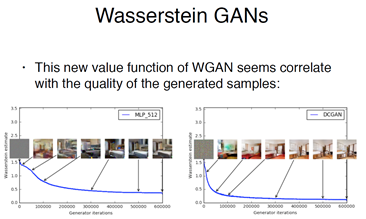
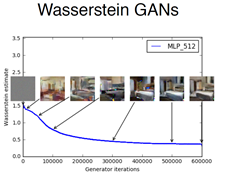
可以看到下图,变形度在慢慢降低,清晰度在慢慢提高,坏点再慢慢减少,上面是Wgan下面是DCgan,发现用Wgan的训练方法训练DCGan的结构,可以发现质量上面的清晰度和变形度更好一些。

在介绍DC-GAN是发现了他们还是用了BN,但是BN并不是所有情况下都好,有时候还会破坏训练,发现用DC去掉BN后train不出来因为增加了稳定性,但是W-GAN即使不用BN,依然能训练不错的结果。

有了DCGAN后大家不太用MLP了,因为MLP表现能差,表现在生成的样本不能逼近很复杂的图像,MLP学mnist还是不错的,三层就可以,但是如果SBA这种就不太好,用standard Gan学出来会更差,但是如果用W-GAN 的话,连MLP 也可以进行很好的学习了。

在最后一部分,有人发现,为了满足Lipschitz连续性的要求,直接简单粗暴的方式是weight clip,不仅仅有选择困难的问题,还会出现,如果C显得比较大,下面红色的先出现了梯度爆炸的问题,选的小时会出现梯度消失,越小消失的越厉害。
所以他们提出了一种Gradient Penalty(梯度惩罚)的方法,就会一直比较平稳。
对于weight clipping的情况下 甚至会学出两种极端的情况,判别器的weight不是-c就是c,导致学出来的D变得很简单。降低了学习能力。

下面做了一个展示, Weight clipping 会忽略掉高阶的动量,所以无法完成复杂的判别任务。

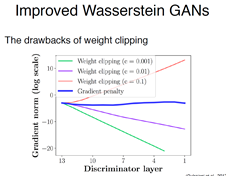
进一步分析,为什么会出现这个问题,用原始的W-gan 就跟gan一样会得到一个最优的D,会让判别器所有的梯度都在1左右,1就是指C,发现其实是跟norm有关的,所以就提出不要直接clip数,去控制norm,把现在的梯度和最优的值,之间差距有多少,用一个L2的loss,加到原始的W-gan的损失函数中。

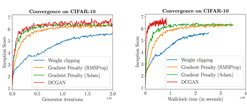
下图看到黄色跟绿色收敛的特别快,GP效果好,不加BN效果还是好。

建议
1 如果要做Gan相关任务传统的就不要再试了,试试最新的。
2 尝试noise input
3 分析特殊结构,例如:U-net 在encoder和decoder上面加了skip connection,其实是针对特定的pair的问题最有效的,需要让feature一一映射过去
4 不要总是尝试高斯的noise,尝试形状,大小等等
不同的noise直接影响了学出来的东西,不是说有情况下都一定要加显性noise,比如noise input 不需要Z的vetor,比如dropout 相当于已经加了noise。
下面的连接中总结了二十多种技巧,可以看一下。

----------------------------------------------------------
至此Gan相关的原理全部介绍完毕,大致从3个主要问题,以及对应的解决对二十多篇Gan模型进行整理,下一篇会整理行业所有领域对gan的应用程度
下一篇:Generative Adversarial Networks overview(3)
Generative Adversarial Networks overview(2)的更多相关文章
- Generative Adversarial Networks overview(1)
Libo1575899134@outlook.com Libo (原创文章,转发请注明作者) 本文章会先从Gan的简单应用示例讲起,从三个方面问题以及解决思路覆盖25篇GAN论文,第二个大部分会进一步 ...
- Generative Adversarial Networks overview(3)
Libo1575899134@outlook.com Libo (原创文章,转发请注明作者) 本文章主要介绍Gan的应用篇,3,主要介绍图像应用,4, 主要介绍文本以及医药化学其他领域应用 原理篇请看 ...
- Generative Adversarial Networks overview(4)
Libo1575899134@outlook.com Libo (原创文章,转发请注明作者) 本文章主要介绍Gan的应用篇,3,主要介绍图像应用,4, 主要介绍文本以及医药化学其他领域应用 原理篇请看 ...
- 生成对抗网络(Generative Adversarial Networks,GAN)初探
1. 从纳什均衡(Nash equilibrium)说起 我们先来看看纳什均衡的经济学定义: 所谓纳什均衡,指的是参与人的这样一种策略组合,在该策略组合上,任何参与人单独改变策略都不会得到好处.换句话 ...
- 生成对抗网络(Generative Adversarial Networks, GAN)
生成对抗网络(Generative Adversarial Networks, GAN)是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的学习方法之一. GAN 主要包括了两个部分,即 ...
- 论文解读(GAN)《Generative Adversarial Networks》
Paper Information Title:<Generative Adversarial Networks>Authors:Ian J. Goodfellow, Jean Pouge ...
- (转)Introductory guide to Generative Adversarial Networks (GANs) and their promise!
Introductory guide to Generative Adversarial Networks (GANs) and their promise! Introduction Neural ...
- 论文笔记之:Semi-Supervised Learning with Generative Adversarial Networks
Semi-Supervised Learning with Generative Adversarial Networks 引言:本文将产生式对抗网络(GAN)拓展到半监督学习,通过强制判别器来输出类 ...
- 《Self-Attention Generative Adversarial Networks》里的注意力计算
前天看了 criss-cross 里的注意力模型 仔细理解了 在: https://www.cnblogs.com/yjphhw/p/10750797.html 今天又看了一个注意力模型 < ...
随机推荐
- GTD时间管理
GTD就是Getting Things Done的缩写,翻译过来就是"把事情处理完",是一个管理时间的方法.GTD的核心理念概括就是必须记录下来要做的事,然后整理安排并使自己一一去 ...
- 第二节:EF Core的常规“增删改”及状态的变化
一. 整体说明 1. 本节用到的表 2. 状态说明补充 ①.Detached: 游离的状态,与数据库没有什么交涉,比如新new一个实体,状态就是Detached. ②.Added: 增加的状态. ③. ...
- 【性能优化】一文学会Java死锁和CPU100%问题的排查技巧
原文链接: 00 本文简介 作为一名搞技术的程序猿或者是攻城狮,想必你应该是对下面这两个问题有所了解,说不定你在实际的工作或者面试就有遇到过: 第一个问题:Java死锁如何排查和解决? 第二个问题:服 ...
- k8s Helm安装Prometheus Operator
Ubuntu 18 Kubernetes集群的安装和部署 以及Helm的安装完成了k8s的集群和helm的安装,今天我们来看看Prometheus的监控怎么搞.Prometheus Operator ...
- mysql数据库事务
事务: 一个或者一组sql语句组成一个执行的单元,这个单元要么全都执行,要么都不执行.也就是每个sql语句相互依赖.如果中间有一条出现错误则整个单元将回滚.(回滚就是刚刚的操作都撤销) 事务的属性: ...
- 上传文件时用form.submit提交的时候在低版本的IE中报拒绝访问的错误
上传文件的时候,在IE7下总是传不了,但FireFox,IE11和Chrome下则可以上传.发现是form.submit();时出错了(“拒绝访问”). html代码为: <label oncl ...
- centos从零开始安装elasticSearch
前言:elasticSearch作为一款优秀的分布式搜索工具,被广泛用在数据搜集和整理的业务中,知名的比如有github就是采用es来精准的搜索几千万行代码,百度也大量应用es做数据爬取分析,本篇博客 ...
- ASP.NET Core中返回 json 数据首字母大小写问题
ASP.NET Core中返回 json 数据首字母大小写问题 在asp.net core中使用ajax请求动态绑定数据时遇到该问题 后台返回数据字段首字母为定义的大写,返回的数据没有问题 但是在前台 ...
- 好用的随查工具Dash
1. 好用的随查工具Dash 1.1. mac版本推荐 推荐一个很好用的工具,名字就叫Dash,当然缺点就是只有英文版,中文版可能也有但更新肯定不如英文及时 可以自由下载各种文档,比如下面的这图,左侧 ...
- 13、vue如何解决跨域问题
开发环境:配置config文件夹中index.js文件: proxyTable: { '/api': { target: 'http://10.10.1.242:8245',//后端地址 // sec ...