PostgreSQL 锁机制浅析
锁机制在 PostgreSQL 里非常重要 (对于其他现代的 RDBMS 也是如此)。对于数据库应用程序开发者(特别是那些涉及到高并发代码的程序员),需要对锁非常熟悉。对于某些问题,锁需要被重点关注与检查。大部分情况,这些问题跟死锁或者数据不一致有关系,基本上都是由于对 Postgres 的锁机制不太了解导致的。虽然锁机制在 Postgres 内部很重要,但是文档缺非常缺乏,有时甚至还是错误的,与文档所指出的结果不一致。我会告诉你精通 Postgres 的锁机制需要知道的一切,要知道对锁了解的越多,解决与锁相关的问题就会越快。
文档里都说了些什么?
Postgres 有 3 种锁机制:表级锁,行级锁和建议性锁。表级和行级的锁可以是显式的也可以是隐式的。建议性锁一般是显式的。显式的锁由显式的用户请求(通过特殊的查询)获取,隐式的锁是通过标准的 SQL 命令来获取。
除了表级和行级的锁,还有页级共享/排除锁,用于控制对共享缓存池里表页的访问。在一行数据被读取或者更新后,这些锁会立即被释放。应用程序开发者通常不需要关注页级的锁。
锁机制会不时的变动,所以我们这里只针对 Postgres 9.x 的版本。9.1 和 9.2 基本上是差不多的,9.3 和 9.4 跟它们有些区别,主要涉及行级锁。
表级锁
大多数的表级锁是由内置的 SQL 命令获得的,但他们也可以通过锁命令来明确获取。可使用的表级锁包括:
访问共享(ACCESS SHARE) - SELECT 命令可在查询中引用的表上获得该锁。一般规则是所有的查询中只有读表才获取此锁。
行共享(ROW SHARE) - SELECT FOR UPDATE 和 SELECT FOR SHARE 命令可在目标表上获得该锁(以及查询中所有引用的表的访问共享锁)。
行独占(ROW EXCLUSIVE) - UPDATE、INSERT 和 DELETE 命令在目标表上获得该锁(以及查询中所有引用的表的访问共享锁)。 一般规则是所有修改表的查询获得该锁。
共享更新独占(SHARE UPDATE EXCLUSIVE) - VACUUM(不含FULL),ANALYZE,CREATE INDEX CONCURRENTLY,和一些 ALTER TABLE 的命令获得该锁。
共享(SHARE) - CREATE INDEX 命令在查询中引用的表上获得该锁。
共享行独占(SHARE ROW EXCLUSIVE) - 不被任何命令隐式获取。
排他(EXCLUSIVE) - 这个锁模式在事务获得此锁时只允许读取操作并行。它不能由任何命令隐式获取。
访问独占(ACCESS EXCLUSIVE) - ALTER TABLE,DROP TABLE,TRUNCATE,REINDEX,CLUSTER 和 VACUUM FULL 命令在查询中引用的表上获得该锁。此锁模式是 LOCK 命令的默认模式。
重要的是要知道,所有这些锁都是表级锁,即使它们名称里有行(ROW)字。
每个锁模式的最重要的信息是与彼此冲突的模式列表。在同一时间同一个表中,2 个事务不能同时保持相冲突的锁模式。事务永远不会与自身发生冲突。 非冲突的锁可以支持多事务并发。同样重要的是要知道有的模式和自身冲突。一些锁模式在获得后会持续到事务结束。但如果锁是在建立一个保存点后获得,保存点回滚后锁会被立刻释放。 下面的表格展示了哪些模式是互相冲突的:
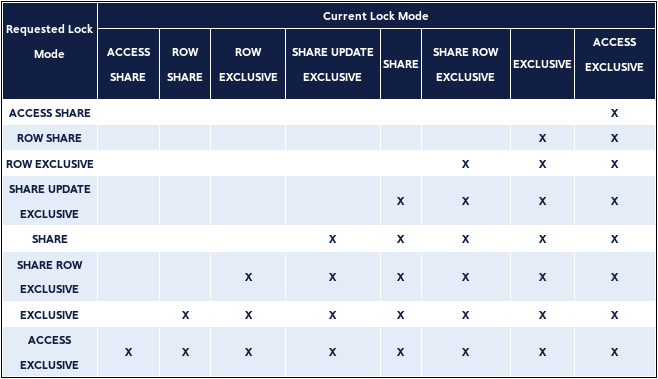
行级锁
在 Postgres 9.1 和 9.2 有两种行级锁模式,但在 Postgres 9.3 和 9.4 有四种行级锁模式。
Postgres 不会记住修改的行在内存中的任何信息,所以一次锁定的行的数目没有限制。然而,锁定一行可能会导致磁盘写入,例如,SELECT FOR UPDATE 修改选定的行并标记它们锁定,所以会导致磁盘写入。
Postgres 9.1 和 9.2 中的行级锁
在这两种版本中,只有 2 种行级锁:排他或共享锁。当行更新或删除时,会自动获得排他行级锁。行级锁不阻止数据查询,它们只阻止同一行写入。 排他行级锁可由 SELECT FOR UPDATE 命令明确获得,即使行没有实际更改。
共享行级锁可由 SELECT FOR SHARE 命令获得。一个共享锁并不阻止其他事务获取同样的共享锁。然而,当任何其他事务持有共享锁时,事务的更新、删除或排他锁都不被允许。
Postgres 9.3 和 9.4 中的行级锁
在 Postgres 9.3 和 9.4 中有四种类型的行级锁:
更新(FOR UPDATE) - 这种模式导致 SELECT 读取的行的更新被锁定。这可以防止它们被其他事务锁定,修改或删除。即尝试 UPDATE、DELETE、SELECT FOR UPDATE、SELECT FOR NO KEY UPDATE、SELECT FOR SHARE 或 SELECT FOR KEY SHARE 的其他事务将被阻塞。删除一行,更新一些列也可以获得到此种锁模式(目前的列集是指那些具有唯一索引,并且可被用作外键 - 但将来这可能会改变)。
无键更新(FOR NO KEY UPDATE) - 这种模式与 FOR UPDATE 相似,但是更弱 - 它不会阻塞SELECT FOR KEY SHARE 锁模式。它通过不获取更新锁的 UPDATE 命令获得。
共享(FOR SHARE) - 这种模式与无键更新锁类似,除了它可以获取共享锁(非排他)。一个共享锁阻止其他事务在这些行上进行 UPDATE,DELETE,SELECT FOR UPDATE 或 SELECT FOR NO KEY UPDATE 操作,但并不阻止它们进行 SELECT FOR SHARE 或 SELECT FOR KEY SHARE。
键共享(FOR KEY SHARE)- 行为类似于共享,但该锁是较弱的:阻止了 SELECT FOR UPDATE,但不阻止 SELECT FOR NO KEY UPDATE。一个键共享锁阻止其他事务进行 DELETE 或任何更改该键值的 UPDATE,但不妨碍任何其他 UPDATE、SELECT FOR NO KEY UPDATE、SELECT FOR SHARE 或者SELECT FOR KEY SHARE。
行级锁冲突:
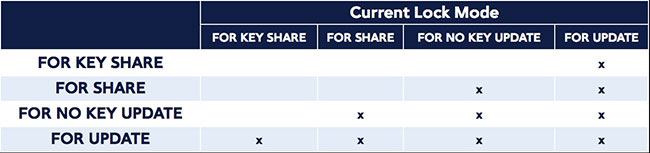
页级锁
除了表级别和行级别的锁以外,页面级别的共享/排他锁被用来控制对共享缓冲池中表页面的读/写。 这些锁在行被抓取或者更新后马上被释放。应用开发者通常不需要关心页级锁,我们在这里提到它们只是为了完整。
劝告锁
Postgres提供创建具有应用定义的锁的方法,这些被称为劝告锁(advisory locks),因为系统并不支持其使用,其取决于应用对锁的正确使用。
Postgres中有两种途径可以获得一个劝告锁:会话层级或事务层级。一旦在会话层级获得劝告锁,会一直保持到被显式释放或会话结束。不同于标准的锁请求,会话层级的劝告锁请求并不遵守事务语义:事务被回滚后锁也会随着回滚保持着,同样地即使调用锁的事务之后失败了,解锁请求仍然是有效的。一个锁可以被拥有它的进程多次获取;对于每个完成的锁请求,在锁被真正释放前一定要有一个对应的解锁请求。
另一方面,事务层级的锁请求表现得更像普通的锁请求:它们在事务结束时会自动释放,并且没有显式的解锁操作。对于短暂地使用劝告锁,这种特性通常比会话层级更方便。可以想见,会话层级与事务层级请求同一个劝告锁标识符会互相阻塞。如果一个会话已经有了一个劝告锁,它再请求时总会成功的,即使其他会话在等待此锁;不论保持现有的锁和新的请求是会话层级还是事务层级,都是这样。文档中可以找到操作劝告锁的完整函数列表。
这里有几个获取事务层级劝告锁的例子(pg_locks是系统视图,文章之后会说明。它存有事务保持的表级锁和劝告锁的信息):
启动第一个psql会话,开始一个事务并获取一个劝告锁:
-- Transaction 1
BEGIN;
SELECT pg_advisory_xact_lock(1);
-- Some work here
现在启动第二个psql会话并在同一个劝告锁上执行一个新的事务:
-- Transaction 2
BEGIN;
SELECT pg_advisory_xact_lock(1);
-- This transaction is now blocked
在第三个psql会话里我们可以看下这个锁现在的情况:
SELECT * FROM pg_locks;-- Only relevant parts of output
locktype | database | relation | page | tuple | virtualxid | transactionid | classid | objid | objsubid | virtualtransaction | pid | mode | granted |fastpath---------------+----------+----------+------+-------+------------+---------------+---------+-------+----------+--------------------+-------+---------------------+---------+----------
advisory | 16393 | | | | | | 0 | 1 | 1 | 4/36 | 1360 | ExclusiveLock | f | f
advisory | 16393 | | | | | | 0 | 1 | 1 | 3/186 | 14340 | ExclusiveLock | t | f
-- Transaction 1
COMMIT;
-- This transaction now released lock, so Transaction 2 can continue
我们同样可以调用获取锁的非阻塞方法,这些方法会尝试去获取锁,并返回true(如果成功了)或者false(如果无法获取锁)。
-- Transaction 1
BEGIN;
SELECT pg_advisory_xact_lock(1);
-- Some work here
-- Transaction 2
BEGIN;
SELECT pg_try_advisory_xact_lock(1) INTO vLockAcquired;
IF vLockAcquired THEN
-- Some work
ELSE
-- Lock not acquired
END IF;
-- Transaction 1
COMMIT;
监控锁
所有活动事务持有的监控锁的基本配置即为系统视图 pg_locks。这个视图为每个可加锁的对象、已请求的锁模式和相关事务包含一行记录。非常重要的一点是,pg_locks 持有内存中被跟踪的锁的信息,所以它不显示行级锁!(译注:据查以前的文档,有关行级锁的信息是存在磁盘上,而非内存)这个视图显示表级锁和劝告锁。如果一个事务在等待一个行级锁,它通常在视图中显示为在等待该行级锁的当前所有者的固定事务 ID。这使得调试行级锁更为困难。事实上,在任何地方你都看不到行级锁,直到有人阻塞了持有此锁的事务(然后你在 pg_locks 表里可以看到一个被上锁的元组)。pg_locks 是可读性欠佳的视图(不是很人性化),所以我们来让显示锁定信息的视图更好接受些:
-- View with readable locks info and filtered out locks on system tables
CREATE VIEW active_locks AS
SELECT clock_timestamp(), pg_class.relname, pg_locks.locktype, pg_locks.database,
pg_locks.relation, pg_locks.page, pg_locks.tuple, pg_locks.virtualtransaction,
pg_locks.pid, pg_locks.mode, pg_locks.granted
FROM pg_locks JOIN pg_class ON pg_locks.relation = pg_class.oid
WHERE relname !~ '^pg_' and relname <> 'active_locks';
-- Now when we want to see locks just type
SELECT * FROM active_locks;
--查看会话session
select pg_backend_pid(); --查看会话持有的锁
select * from pg_locks where pid=3797; --1,查看数据库 select pg_database.datname, pg_database_size(pg_database.datname) AS size from pg_database; //查询所有数据库,及其所占空间大小 --2. 查询存在锁的数据表 select a.locktype,a.database,a.pid,a.mode,a.relation,b.relname -- ,sa.*
from pg_locks a
join pg_class b on a.relation = b.oid
inner join pg_stat_activity sa on a.pid=sa.procpid --3.查询某个表内,状态为lock的锁及关联的查询语句 select a.locktype,a.database,a.pid,a.mode,a.relation,b.relname -- ,sa.*
from pg_locks a
join pg_class b on a.relation = b.oid
inner join pg_stat_activity sa on a.pid=sa.procpid
where a.database=382790774 and sa.waiting_reason='lock'
order by sa.query_start
--4.查看数据库表大小 select pg_database_size('playboy');
--查看会话被谁阻塞
select pg_blocking_pids(3386);
死锁
显式锁定的使用可能会增加死锁的可能性,死锁是指两个(或多个)事务相互持有对方想要的锁。
例如,如果事务 1 在表 A 上获得一个排他锁,同时试图获取一个在表 B 上的排他锁, 而事务 2 已经持有表 B 的排他锁,同时却正在请求表 A 上的一个排他锁,那么两个事务就都不能进行下去。PostgreSQL能够自动检测到死锁情况 并且会通过中断其中一个事务从而允许其它事务完成来解决这个问题(具体哪个事务会被中 断是很难预测的,而且也不应该依靠这样的预测)。
要注意死锁也可能会作为行级锁的结果而发生(并且因此,它们即使在没有使用显式锁定的情况下也会发生)。考虑如下情况,两个并发事务在修改一个表。第一个事务执行:
UPDATE accounts SET balance = balance + 100.00 WHERE acctnum = 11111;
这样就在指定帐号的行上获得了一个行级锁。然后,第二个事务执行:
UPDATE accounts SET balance = balance + 100.00 WHERE acctnum = 22222;
UPDATE accounts SET balance = balance - 100.00 WHERE acctnum = 11111;
第一个UPDATE语句成功地在指定行上获得了一个行级锁,因此它成功更新了该行。 但是第
二个UPDATE语句发现它试图更新的行已经被锁住了,因此它等待持有该锁的事务结束。事
务二现在就在等待事务一结束,然后再继续执行。现在,事务一执行:
UPDATE accounts SET balance = balance - 100.00 WHERE acctnum = 22222;
事务一试图在指定行上获得一个行级锁,但是它得不到:事务二已经持有了这样的锁。所以
它要等待事务二完成。因此,事务一被事务二阻塞,而事务二也被事务一阻塞:一个死锁。
PostgreSQL将检测这样的情况并中断其中一个事务。
防止死锁的最好方法通常是保证所有使用一个数据库的应用都以一致的顺序在多个对象上获得锁。在上面的例子里,如果两个事务以同样的顺序更新那些行,那么就不会发生死锁。 我们也应该保证一个事务中在一个对象上获得的第一个锁是该对象需要的最严格的锁模式。如果我们无法提前验证这些,那么可以通过重试因死锁而中断的事务来即时处理死锁。
只要没有检测到死锁情况,寻求一个表级或行级锁的事务将无限等待冲突锁被释放。这意味着一个应用长时间保持事务开启不是什么好事(例如等待用户输入)。
咨询锁
- PostgreSQL提供了一种方法创建由应用定义其含义的锁。这种锁被称为咨询锁,因为系统并不强迫其使用 — 而是由应用来保证其正确的使用。咨询锁可用于 MVCC 模型不适用的锁定策略。例如,咨询锁的一种常用用法是模拟所谓“平面文件”数据管理系统典型的悲观锁策略。虽然一个存储在表中的标志可以被用于相同目的,但咨询锁更快、可以避免表膨胀并且会由服务器在会话结束时自动清理。
- 有两种方法在PostgreSQL中获取一个咨询锁:在会话级别或在事务级别。一旦在会话级别获得了咨询锁,它将被保持直到被显式释放或会话结束。不同于标准锁请求,会话级咨询锁请求不尊重事务语义:在一个后来被回滚的事务中得到的锁在回滚后仍然被保持,并且同样即使调用它的事务后来失败一个解锁也是有效的。一个锁在它所属的进程中可以被获取多次;对于每一个完成的锁请求必须有一个相应的解锁请求,直至锁被真正释放。在另一方面,事务级锁请求的行为更像普通锁请求:在事务结束时会自动释放它们,并且没有显式的解锁操作。这种行为通常比会话级别的行为更方便,因为它使用一个咨询锁的时间更短。对于同一咨询锁标识符的会话级别和事务级别的锁请求按照期望将彼此阻塞。如果一个会话已经持有了一个给定的咨询锁,由它发出的附加请求将总是成功,即使有其他会话在等待该锁;不管现有的锁和新请求是处在会话级别还是事务级别,这种说法都是真的。
- 和所有PostgreSQL中的锁一样,当前被任何会话所持有的咨询锁的完整列表可以在pg_locks系统视图中找到
- 咨询锁和普通锁都被存储在一个共享内存池中,它的尺寸由max_locks_per_transaction和max_connections配置变量定义。 必须当心不要耗尽这些内存,否则服务器将不能再授予任何锁。这对服务器可以授予的咨询锁数量设置了一个上限,根据服务器的配置不同,这个限制通常是数万到数十万。
- 在使用咨询锁方法的特定情况下,特别是查询中涉及显式排序和LIMIT子句时,由于 SQL 表达式被计算的顺序,必须小心控制锁的获取。例如:
SELECT pg_advisory_lock(id) FROM foo WHERE id = 12345; -- ok
SELECT pg_advisory_lock(id) FROM foo WHERE id > 12345 LIMIT 100; -- danger!
SELECT pg_advisory_lock(q.id) FROM
(
SELECT id FROM foo WHERE id > 12345 LIMIT 100
) q; -- ok
在上述查询中,第二种形式是危险的,因为不能保证在锁定函数被执行之前应用LIMIT。这
可能导致获得某些应用不期望的锁,并因此在会话结束之前无法释放。 从应用的角度来看,
这样的锁将被挂起,虽然它们仍然在pg_locks中可见。
PostgreSQL 锁机制浅析的更多相关文章
- InnoDB的锁机制浅析(五)—死锁场景(Insert死锁)
可能的死锁场景 文章总共分为五个部分: InnoDB的锁机制浅析(一)-基本概念/兼容矩阵 InnoDB的锁机制浅析(二)-探索InnoDB中的锁(Record锁/Gap锁/Next-key锁/插入意 ...
- InnoDB的锁机制浅析(四)—不同SQL的加锁状况
不同SQL的加锁状况 文章总共分为五个部分: InnoDB的锁机制浅析(一)-基本概念/兼容矩阵 InnoDB的锁机制浅析(二)-探索InnoDB中的锁(Record锁/Gap锁/Next-key锁/ ...
- InnoDB的锁机制浅析(三)—幻读
文章总共分为五个部分: InnoDB的锁机制浅析(一)-基本概念/兼容矩阵 InnoDB的锁机制浅析(二)-探索InnoDB中的锁(Record锁/Gap锁/Next-key锁/插入意向锁) Inno ...
- InnoDB的锁机制浅析(二)—探索InnoDB中的锁(Record锁/Gap锁/Next-key锁/插入意向锁)
Record锁/Gap锁/Next-key锁/插入意向锁 文章总共分为五个部分: InnoDB的锁机制浅析(一)-基本概念/兼容矩阵 InnoDB的锁机制浅析(二)-探索InnoDB中的锁(Recor ...
- InnoDB的锁机制浅析(一)—基本概念/兼容矩阵
InnoDB锁的基本概念 文章总共分为五个部分: InnoDB的锁机制浅析(一)-基本概念/兼容矩阵 InnoDB的锁机制浅析(二)-探索InnoDB中的锁(Record锁/Gap锁/Next-key ...
- InnoDB的锁机制浅析(All in One)
目录 InnoDB的锁机制浅析 1. 前言 2. 锁基本概念 2.1 共享锁和排它锁 2.2 意向锁-Intention Locks 2.3 锁的兼容性 3. InnoDB中的锁 3.1 准备工作 3 ...
- MySQL锁机制浅析
MySQL使用了3种锁机制 行级锁,开销大,加锁慢,会出现死锁,发生锁冲突的概率最高,并发度也最高 表级锁,开销小,加锁快,不会出现死锁,发生锁冲突的概率最低,并发度最低 页级锁,开销和加锁时间界于表 ...
- 数据库并发事务控制四:postgresql数据库的锁机制二:表锁 <转>
在博文<数据库并发事务控制四:postgresql数据库的锁机制 > http://blog.csdn.net/beiigang/article/details/43302947 中后面提 ...
- 浅析SQLite的锁机制和WAL技术
锁机制 SQLite基于锁来实现并发控制.SQLite的锁是粗粒度的,并不拥有PostgreSQL那样细粒度的行锁,这也使得SQLite较为轻量级.当一个连接要写数据库时,所有其它的连接都被锁住,直到 ...
随机推荐
- SQL——IN操作符
一.IN操作符基本用法 IN操作符用于在WHERE字句中规定多个值. 语法格式如下: SELECT 列名1,列名2... FROM 表名 WHERE 列名 IN(值1,值2...); 示例studen ...
- python基础 — 参数组合
参数组合 >>>def f1(a, b, c=0, *args, **kw): ... print('a =', a, 'b =', b, 'c =', c, 'args =', a ...
- 关于base64的一个小细节
Base64出现\r\n的问题 前段时间遇到这么一个小问题: 后台接口返回一个图片的base64串,同事拿着这个字符串,找了一个在线图片和Base64字符串互转的工具网站,想将字符串转成图片,死活转不 ...
- 使用eslint检查代码质量
1.安装 全局安装 npm install eslint -g 局部安装 npm install eslint --save 2.初始化一个配置文件 eslint --init 执行后根据项目需要回答 ...
- 分享大麦UWP版本开发历程-02.内容“高度/宽度”不同的列表展示
一个成型的产品,肯定是经过了产品经理出的UE,美工设计的UI,最终到我们手里Coding,这里面最少3个人,最多就不知道会有多少人参与了.每个人脑子想的都是不一样的,我就不粘贴那个“XX眼中的XX”那 ...
- Django admin 修改密码
Django admin 修改密码 问题:Django的admin 用户忘记密码或修改密码,在auth_user表中password字段是加密的,所以需要以下方法进行修改. 方法一: python m ...
- CRM-Q模糊查询
Q查询-模糊查询 示例一 q=Q() # 实例化一个Q的对象q,我们可以给它加条件 q.children.append(("name","xxx")) # 添加 ...
- Zabbix-报警之微信(Wechat alert)告警
1.前言 Zabbix告警发送是监控系统的重要功能之一.Zabbix可以通过多种方式把告警信息发送到指定人,常用的有邮件,短信报警方式,但是越来越多的企业开始使用zabbix结合微信作为主要的告警方式 ...
- c# Stack 类
- Linux kernel buffer ring
参考:What are the concepts of “kernel ring buffer”, “user level”, “log level”? Ring Buffer 原始问题 个人补充:r ...