Mycat分布式数据库架构解决方案--Mycat实现数据库分表
echo编辑整理,欢迎转载,转载请声明文章来源。欢迎添加echo微信(微信号:t2421499075)交流学习。 百战不败,依不自称常胜,百败不颓,依能奋力前行。——这才是真正的堪称强大!!!
准备工作:
- 请先在服务器上面安装Mycat,安装教程:https://blog.csdn.net/xlecho/article/details/102755484
- 了解一下他的核心配置文件:Server.xml详解、schema.xml详解、rule.xml详解
- 准备三台服务器,都需要安装mysql
- 搭建一主两从的MySQL读写分离环境:Mycat分布式数据库架构解决方案--搭建MySQL读写分离环境--一主多从
- 下载一份Mycat的原码(在服务器上面编写不方便,本地更改好,替换服务器配置文件更方便)Mycat下载
如果前面的准备工作都做好了,并且有配置Mycat实现读写分离,就能很快的上手Mycat实现数据库分库分表。Mycat实现读写分离请参考:https://blog.csdn.net/xlecho/article/details/102897050
由于我们的Mycat实现读写分离配置好了登录用户名和密码,所以配置Mycat实现数据库分库分表的工作就不在需要去配置server.mxl了,但是我们使用分表规则的时候,要涉及两个新的配置文件
- rule.xml
- autopartition-long.txt
配置schema
实现数据库分库分表它和读写分离最大的不同就是dataHost该标签的配置,读写分离,只需要一个dataHost即可。但是dataHost如果只配置一个,就没有办法实现多库读写。我们要实现分表,当然要考虑每一个库对应的表都需要能够读写。所以我们在配置table的时候,对应的每一个库,就需要对应到每一个可以写的库。同时和读写分离不同的是,我们既然要分库分表就需要分表的规则,这里新增了分表规则auto-sharding-long
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="userDB" checkSQLschema="true" sqlMaxLimit="100">
<table name="user" dataNode="dn1,dn2,dn3" primaryKey="id" rule="auto-sharding-long"/>
</schema>
<dataNode name="dn1" dataHost="testNode1" database="test"/>
<dataNode name="dn2" dataHost="testNode2" database="test"/>
<dataNode name="dn3" dataHost="testNode3" database="test"/>
<dataHost name="testNode1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="-1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.222.132:3306" user="root" password="123456" />
</dataHost>
<dataHost name="testNode2" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="-1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM2" url="192.168.222.133:3306" user="root" password="123456" />
</dataHost>
<dataHost name="testNode3" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="-1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM3" url="192.168.222.134:3306" user="root" password="123456" />
</dataHost>
</mycat:schema>
配置rule.xml
我们在schema中配置了auto-sharding-long的规则就需要在rule.xml中配置对应的规则。(Mycat原始的rule配置文件中就已经有了我们需要配置的规则,所以我们这里不需要改动,但是auto-sharding-long对应的autopartition-long.txt文档,由于演示需要,我们更改一下)
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="rule1">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="rule2">
<rule>
<columns>user_id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<tableRule name="crc32slot">
<rule>
<columns>id</columns>
<algorithm>crc32slot</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<tableRule name="latest-month-calldate">
<rule>
<columns>calldate</columns>
<algorithm>latestMonth</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-rang-mod">
<rule>
<columns>id</columns>
<algorithm>rang-mod</algorithm>
</rule>
</tableRule>
<tableRule name="jch">
<rule>
<columns>id</columns>
<algorithm>jump-consistent-hash</algorithm>
</rule>
</tableRule>
<function name="murmur" class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 -->
<!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索
引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不>会输出任何东西 -->
</function>
<function name="crc32slot" class="io.mycat.route.function.PartitionByCRC32PreSlot">
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
</function>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function>
<function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
<function name="latestMonth" class="io.mycat.route.function.LatestMonthPartion">
<property name="splitOneDay">24</property>
</function>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2015-01-01</property>
</function>
<function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod">
<property name="mapFile">partition-range-mod.txt</property>
</function>
<function name="jump-consistent-hash" class="io.mycat.route.function.PartitionByJumpConsistentHash">
<property name="totalBuckets">3</property>
</function>
</mycat:rule>
配置autopartition-long.txt
该配置文件的原本配置是M为单位,这样的数据太大,测试的时候,计算麻烦,我们更改配置如下:
0-2000=0 # 代表id的大小在0-2000中间就是用dn1服务器
2000-4000=1 # 代表id的大小在2000-4000中间就是用dn2服务器
4000-8000=2 # 代表id的大小在4000-8000中间就是用dn3服务器
我们有三个节点,相当于一个有一个服务器集合,每台服务器都是根据下标来对应的,都是从0开始计数,0就代表我们的dn1
测试:
插入三条数据,根据我们配置的规则进行插入
INSERT INTO `user`(`id`, `user_name`, `pass_word`) VALUES (1000, 'a', '123456');
INSERT INTO `user`(`id`, `user_name`, `pass_word`) VALUES (3000, 'b', '123456');
INSERT INTO `user`(`id`, `user_name`, `pass_word`) VALUES (6000, 'c', '123456');
插入完成之后,我们连接Mycat查看数据,如下图:
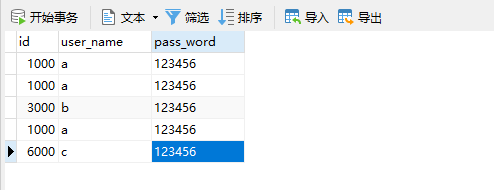
这里我们有3条1000的数据原因是因为我们id等于1000,所以插入到dn1服务里面,但是dn1是我们对应的MySQL主从复制的主服务器132,所以,插入该服务器之后,另外两台从服务器133/134都会直接将数据复制过去。
验证
服务器dn1,应该id=1000的三台服务器都有,id=3000在我们的133从服务器上,id=6000在我们134服务器上
- 主服务器132

- 从服务器133
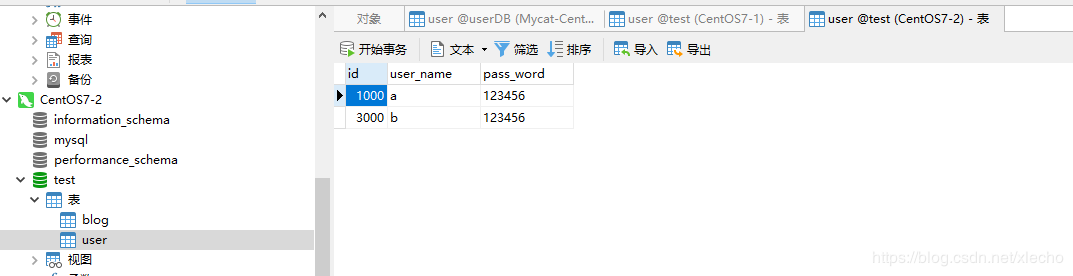
- 从服务器134

做一个有底线的博客主
Mycat分布式数据库架构解决方案--Mycat实现数据库分表的更多相关文章
- Mycat分布式数据库架构解决方案--Mycat实现读写分离
echo编辑整理,欢迎转载,转载请声明文章来源.欢迎添加echo微信(微信号:t2421499075)交流学习. 百战不败,依不自称常胜,百败不颓,依能奋力前行.--这才是真正的堪称强大!!! 安装完 ...
- Mycat分布式数据库架构解决方案--Mycat的介绍
echo编辑整理,欢迎转载,转载请声明文章来源.欢迎添加echo微信(微信号:t2421499075)交流学习. 百战不败,依不自称常胜,百败不颓,依能奋力前行.--这才是真正的堪称强大!!! 如果我 ...
- Mycat分布式数据库架构解决方案--schema.xml详解
echo编辑整理,欢迎转载,转载请声明文章来源.欢迎添加echo微信(微信号:t2421499075)交流学习. 百战不败,依不自称常胜,百败不颓,依能奋力前行.--这才是真正的堪称强大!!! 该文件 ...
- Mycat分布式数据库架构解决方案--rule.xml详解
echo编辑整理,欢迎转载,转载请声明文章来源.欢迎添加echo微信(微信号:t2421499075)交流学习. 百战不败,依不自称常胜,百败不颓,依能奋力前行.--这才是真正的堪称强大!!! 该文件 ...
- Mycat分布式数据库架构解决方案--Server.xml详解
echo编辑整理,欢迎转载,转载请声明文章来源.欢迎添加echo微信(微信号:t2421499075)交流学习. 百战不败,依不自称常胜,百败不颓,依能奋力前行.--这才是真正的堪称强大!!! 该文件 ...
- Mycat安装并实现mysql读写分离,分库分表
Mycat安装并实现mysql读写分离,分库分表 一.安装Mycat 1.1 创建文件夹 1.2 下载 二.mycat具体配置 2.1 server.xml 2.2 schema.xml 2.3 se ...
- Mycat读写分离、主从切换、分库分表的操作记录
系统开发中,数据库是非常重要的一个点.除了程序的本身的优化,如:SQL语句优化.代码优化,数据库的处理本身优化也是非常重要的.主从.热备.分表分库等都是系统发展迟早会遇到的技术问题问题.Mycat是一 ...
- Mycat分布式数据库架构解决方案--Linux安装运行Mycat
echo编辑整理,欢迎转载,转载请声明文章来源.欢迎添加echo微信(微信号:t2421499075)交流学习. 百战不败,依不自称常胜,百败不颓,依能奋力前行.--这才是真正的堪称强大!!! Myc ...
- Mycat分布式数据库架构解决方案--配置defaultAccount属性报错解决方案
echo编辑整理,欢迎转载,转载请声明文章来源.欢迎添加echo微信(微信号:t2421499075)交流学习. 百战不败,依不自称常胜,百败不颓,依能奋力前行.--这才是真正的堪称强大!!! 该文章 ...
随机推荐
- ubuntu 18.04 设置静态ip方法
1. 前言 本教程将会演示如何设置Ubuntu16.04 Server版和Ubuntu18.04 Server版系统的静态固定IP地址. 2. 确认你要修改的网卡号 先确认你要修改的网卡号,假设你的服 ...
- java Atomic compareAndSet部分原理分析
以AtomicLong的compareAndSet方法举例.先说结论:如果CPU支持,则基于CPU指令(CMPXCHG8)实现:否则使用ObjectLocker锁实现. 分析过程如下: 该方法在jdk ...
- 修改JDK安装路径的作用
JDK的默认安装路径是Program Files文件夹,而Program Files的两个英文单词间有空格, 而当JDK的安装路径里包含空格时,在设置CLASSPATH时,可能会引发莫名奇妙的错误, ...
- Spring Cloud微服务安全实战_3-4_API安全机制之认证
认证:登录和认证是 两个概念,比如你两周.一个月,可能只登录了一次,但认证却是每次访问都要经过的步骤. 对于图中的认证不成功,也要继续处理,这个我觉得得看业务,比如管理系统,不登录就不让你访问,但对 ...
- vue中使用过的全局API
Vue.directive()---------全局自定义指令 Vue.filter()----------全局过滤器 Vue.$set()----------为响应式对象添加一个响应式属性 Vue. ...
- async和await对promise异步方案的改进,以及使用注意事项
async.await相比原生promise的有优势: 1.更加简洁,await一个promise即可,那么会自动返回这个promise的resolve值,无需在then函数的回调中手动取值,彻底解决 ...
- Sql Server怎样设置sa用户登录
首先,我门打开数据库管理工具,用windows方式登录,windows只能本机登录,这样远程的客户端就登录不了,我们目前就是为了开启sa登录,使远程客户端也能访问数据库,看下图,windows方式登录 ...
- SpringBoot系列教程web篇Servlet 注册的四种姿势
原文: 191122-SpringBoot系列教程web篇Servlet 注册的四种姿势 前面介绍了 java web 三要素中 filter 的使用指南与常见的易错事项,接下来我们来看一下 Serv ...
- jquery swipper插件的一些弊端
jquery swipper插件的一些弊端touch触摸机制是swipper的 阻止click冒泡.拖动Swiper时阻止click事件.下面这个方法或许可以解决触摸机制的问题 <pre> ...
- Faker伪数据生成
版本信息:Faker==3.0.0factory-boy==2.12.0 provider: # encoding=utf-8 import randomfrom faker.providers im ...