Perl寻路A*算法实现
A*算法;A*(A-Star)算法是一种静态路网中求解最短路径最有效的直接搜索方法。估价值与实际值越接近,估价函数取得就越好。
公式表示为: f(n)=g(n)+h(n),其中 f(n) 是从初始点经由节点n到目标点的估价函数,g(n) 是在状态空间中从初始节点到n节点的实际代价,h(n) 是从n到目标节点最佳路径的估计代价。
保证找到最短路径(最优解的)条件,关键在于估价函数f(n)的选取:估价值h(n)<= n到目标节点的距离实际值,这种情况下,搜索的点数多,搜索范围大,效率低。但能得到最优解。并且如果h(n)=d(n),即距离估计h(n)等于最短距离,那么搜索将严格沿着最短路径进行, 此时的搜索效率是最高的。如果 估价值>实际值,搜索的点数少,搜索范围小,效率高,但不能保证得到最优解。
创建两个表,OPEN表保存所有已生成而未考察的节点,CLOSED表中记录已访问过的节点。算起点的估价值;将起点放入OPEN表;保存路径,即从终点开始,每个节点沿着父节点移动直至起点,这就是你的路径。
算法伪码:
while(OPEN!=NULL)
{
从OPEN表中取估价值f(n)最小的节点n;
if(n节点==目标节点)
break;
for(当前节点n的每个子节点X)
{
算X的估价值;
if(XinOPEN)
if(X的估价值小于OPEN表的估价值)
{
把n设置为X的父亲;
更新OPEN表中的估价值;//取最小路径的估价值
}
if(XinCLOSE)
continue;
if(Xnotinboth)
{
把n设置为X的父亲;
求X的估价值;
并将X插入OPEN表中;//还没有排序
}
}//endfor
将n节点插入CLOSE表中;
按照估价值将OPEN表中的节点排序;//实际上是比较OPEN表内节点f的大小,从最小路径的节点向下进行。
}//endwhile(OPEN!=NULL)
以上摘自百度百科,以下将用Perl语言实现:
1、建立路径数组,下标即是步数,并使用匿名哈希保存坐标点、开销、到目的地开销、实际开销、父节点等信息,数据结构如下:
path[step]={ coordinate=>[y,x],
cost=>0,
next_cost=>(y-end.y)+(x-end.x),
previous=>path[step-1],
actual_cost=>cost+next_cost }
2、另一个数组,下标即是坐标点,指向的匿名哈希存放OPEN、CLOSE、前一节点的状态,如: arr[y][x]->{point},方便回退时能直接获取到上一步的坐标点和状态,数据结构如下:
arr[y][x]={ flag=>0,
point=>arr[y-1][x-1] }
数据结构设计好后,根据上面的伪代码实现还是比较容易:
use strict;
use List::Util;
use constant {WIDTH=>,HEIGHT=>,DEBUG=>,};
my @uldr=( ,[-,],[,-],[,],[,], ); # 上、左、下、右
my @bg=();
for(my $y=;$y<HEIGHT;$y++){
for( my $x= ; $x<WIDTH ; $x++ ){
if( $y == || $y == HEIGHT- ||
$x == || $x == WIDTH- ){
$bg[$y][$x] = '*';
}
else{
$bg[$y][$x] = ' ';
}
}
} # 初始化迷宫 my @obstruction=( [,],[,],[,],[,],[,],[,],[,],[,],[,],[,],[,],[,], ); # 障碍物坐标
map{ $bg[ $obstruction[$_][] ][ $obstruction[$_][] ] = '#' } ..$#obstruction-1;
$bg[ $obstruction[][] ][ $obstruction[][] ] = '@'; @bg=( ['*','*','*','*','*','*','*','*','*','*','*','*',],
['*',' ',' ',' ','#',' ',' ',' ',' ',' ',' ','*',],
['*',' ','#',' ',' ',' ',' ',' ',' ',' ',' ','*',],
['*',' ','#',' ',' ',' ','#',' ',' ',' ',' ','*',],
['*',' ','#',' ',' ',' ','#','#','#','#','#','*',],
['*',' ',' ','#',' ',' ','#',' ',' ',' ',' ','*',],
['*',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ','*',],
['*','*','*','*','*','*','*','*','*','*','*','*',],
);
print @$_,"\n" foreach(@bg);
my @bg_ghost=(); # 0--未经过 1--已走 2--不可通过 print "-"x15,"\n";
sub caclulate_cost{
my ($sp,$ep)=@_;
return abs($sp->[] - $ep->[]) + abs($sp->[] - $ep->[]);
}
sub handle{
my @path=(); # 存放步数的数组
my $start=[ $obstruction[][] , $obstruction[][] ]; # 起点
$start=[,];
my $end=[ $obstruction[-][] , $obstruction[-][] ]; # 终点
$end=[,];
my ($step,$p_step,$p_gh)=(,'',''); # 步数、指向数组元素的指针、指向bg_ghost元素的指针 $path[$step]={ coordinate=>[$start->[],$start->[]],
cost=>,
next_cost=>&caclulate_cost( $start,$end ),
previous=>,
}; # 每一步保存坐标、预计开销、到目的地距离、父节点,起点开销为0
$path[$step]->{actual_cost}=$path[$step]->{cost} + $path[$step]->{next_cost}; # 实际开销
$bg_ghost[ $start->[] ][ $start->[] ]->{point}=''; # 起点的父节点为空
while(@path){
$p_step=pop(@path);
print " step:$step,p_step:$p_step\n" if DEBUG;
if( $p_step->{coordinate}->[] == $end->[] &&
$p_step->{coordinate}->[] == $end->[] ){ # 到达目的地
my @arr=('A'..'Z','a'..'z');
my @temp=();
while($p_step){
push @temp,$p_step->{coordinate};
$p_step=$p_step->{previous}; # 顺着父节点回溯,获取每个节点
}
@temp=reverse(@temp);
foreach(..$#temp){
$bg[ $temp[$_]->[] ][ $temp[$_]->[] ] = $arr[$_];
}
return ;
} # end if
$step++;
for(my $cnt=;$cnt<=;$cnt++){
my $y= $p_step->{coordinate}->[]+$uldr[$cnt][] ;
my $x= $p_step->{coordinate}->[]+$uldr[$cnt][] ;
print " ($p_step->{coordinate}->[0],$p_step->{coordinate}->[1])+($uldr[$cnt][0],$uldr[$cnt][1]),(y,x)=($y,$x)\n" if DEBUG;
if( $y < || $y > HEIGHT- || $x < || $x > WIDTH- || $bg[$y][$x] eq '#' ){
$bg_ghost[$y][$x]->{flag} = ; # 不可经过
}
if( ! $bg_ghost[$y][$x]->{flag} ){ # 未经过的
$bg_ghost[$y][$x]->{flag}=; # 设置已经过
$bg_ghost[$y][$x]->{point}=$p_step; # 保存前一节点状态
my $px={ coordinate=>[$y,$x],
cost=>$p_step->{cost}+,
next_cost=>&caclulate_cost( [$y,$x],$end ),
previous=>$p_step,
};
$px->{actual_cost}=$px->{cost} + $px->{next_cost};
push @path,$px;
}
else{
$p_gh=$bg_ghost[$y][$x]->{point};
print " p_gh:$p_gh\n" if DEBUG;
if($p_gh && $p_step->{cost}+ < $p_gh->{cost} ){ # 如果当前开销较小
print " $p_step->{cost},$p_gh->{cost}\n" if DEBUG;
$p_gh->{cost}=$p_step->{cost}+; #
$p_gh->{previous}=$p_step; # 将前一个节点设置为当前节点之父
$p_gh->{actual_cost}=$p_gh->{cost}+$p_gh->{next_cost}; # 更新前一节点开销
}
}
}
$bg_ghost[ $p_step->{coordinate}->[] ][ $p_step->{coordinate}->[] ]->{flag}=; # 设置已经过
@path=sort{$b->{actual_cost}<=>$a->{actual_cost}}@path; # 排序,开销最小的放在最后
}
return ;
}
&handle;
print @$_,"\n" foreach(@bg);
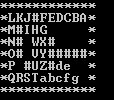
计算出来的最短路径:

比较一下深度优先算法:
Perl寻路A*算法实现的更多相关文章
- 游戏寻路A*算法
A*算法是一种启发式的BFS,目的就是找到到达目标位置的最短路径.启发式函数如下: f(x) = g(x) + h(x) g(x)是对出发点到达当前点距离的估约,h(x)是当前点到终点距离的估约.算法 ...
- A*寻路算法的探寻与改良(一)
A*寻路算法的探寻与改良(一) by:田宇轩 第一部分:这里我们主 ...
- PHP树生成迷宫及A*自己主动寻路算法
PHP树生成迷宫及A*自己主动寻路算法 迷宫算法是採用树的深度遍历原理.这样生成的迷宫相当的细,并且死胡同数量相对较少! 随意两点之间都存在唯一的一条通路. 至于A*寻路算法是最大众化的一全自己主动寻 ...
- 数据结构和算法总结(三):A* 寻路算法
前言 复习下寻路相关的东西,而且A star寻路在游戏开发中应用挺多的,故记录下. 正文 迪杰斯特拉算法 说起A*得先谈谈Dijkstra算法,它是在BFS基础上的一种带权值的两点最短寻路贪心算法. ...
- 基于Unity的A星寻路算法(绝对简单完整版本)
前言 在上一篇文章,介绍了网格地图的实现方式,基于该文章,我们来实现一个A星寻路的算法,最终实现的效果为: 项目源码已上传Github:AStarNavigate 在阅读本篇文章,如果你对于里面提到的 ...
- Unity实现A*寻路算法学习2.0
二叉树存储路径节点 1.0中虽然实现了寻路的算法,但是使用List<>来保存节点性能并不够强 寻路算法学习1.0在这里:https://www.cnblogs.com/AlphaIcaru ...
- 关于php Hash算法的一些整理总结
最近在公司内部的分享交流会上,有幸听到了鸟哥的关于php底层的一些算法的分享,虽然当时有些问题没有特别的明白,但是会后,查阅了各种各样的相关资料,对php的一些核心的hash算法有了进一步的理解和认识 ...
- 一步一步写算法(之 A*算法)
[ 声明:版权全部,欢迎转载,请勿用于商业用途. 联系信箱:feixiaoxing @163.com] 在前面的博客其中,事实上我们已经讨论过寻路的算法.只是,当时的演示样例图中,可选的路径是唯一的 ...
- JS - A*寻路
算法核心 A*估值算法 寻路估值算法有非常多:常用的有广度优先算法,深度优先算法,哈夫曼树等等,游戏中用的比较多的如:A*估值 算法描述 对起点与终点进行横纵坐标的运算 代码实现 start: 起点坐 ...
随机推荐
- Android数据存储原理分析
Android上常见的数据存储方式为: SharedPreferences是 Android 中比较常用的存储方法,本篇将从源码角度带大家分析一下Android中常用的轻量级数据存储工具SharedP ...
- Android ProGuard:代码混淆压缩
写这篇文章的目的 一直以来,在项目中需要进行代码混淆时每次都要去翻文档,很麻烦.也没有像写代码那样记得那么多.既然要查来查去,就不如自己捋一捋这个知识点了,被人写的终究还是别人的.所以自己去翻看了很多 ...
- [LeetCode] 62. 不同路径 ☆☆☆(动态规划)
动态规划该如何优化 描述 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” ). 机器人每次只能向下或者向右移动一步.机器人试图达到网格的右下角(在下图中标记为“Fi ...
- Linux正则表达式,grep总结,sed用法
原文: 1.sed 流编辑器,实现对文字的增删改替换查(过滤.取行),能同时处理多个文件多行的内容,可以不对原文件改动,把整个文件 输入到屏幕,可以把只匹配到模式的内容输入到屏幕上.还可以对原文件 ...
- props、state、forms
{}用来内嵌任何JS表达式JSX属性JS核心分为三大块:Es6.DOM.WindowBABEL编译器:可以在线编译html语法生成对应的react语法 **自定义组件第一个字母大写:用于区别普通的对象 ...
- 宁波市第二届CTF部分WP之msc1,msc2
msc1签到 这题没啥好说的,修改一下图片宽高,flag到手 msc2 一开始用十六进制编辑器打开,分析文件,暂时无果,卡了一小时(线下没网) 后面,看着这部分文件头眼熟,猜测是GIF头, 于是,在硬 ...
- DNS子域授权,区域传送
dig 命令 +recurse 递归查询 默认 +norecurse 不递归查询 dig +recurse -t A www.baidu.com @127.0.0.1 dig -t a ...
- DOCclever--自动化接口测试用例
1.登录---UI模式 2.登录--代码模式
- vetur 和 npm run lint 格式化不一致
vetur 的 template(html) 默认使用的格式化插件是 prettyhtml,虽然可以选 prettier,和 npm run lint 的格式化保持一致,但是有时候会影响到 scrip ...
- jmeter 压测工具安装及使用
linux下jmeter安装: 1. 下载JMeter官方网站下载最新版本: http://jmeter.apache.org/download_jmeter.cgi ,目前最新版是Apache JM ...