【电商日志项目之五】数据分析-MR方式
环境
hadoop-2.6.5
hbase-0.98.12.1-hadoop2
新增用户指标分析
(1)用户分析模块
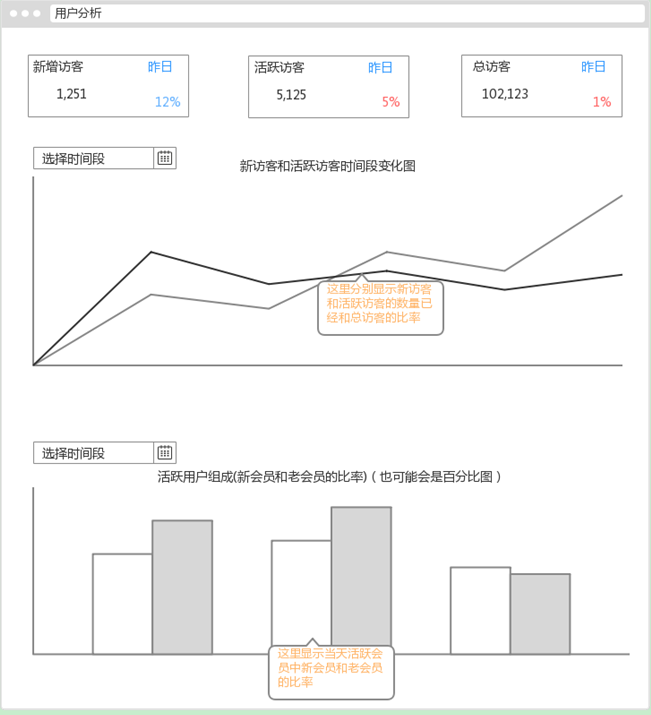
(2)浏览器分析模块
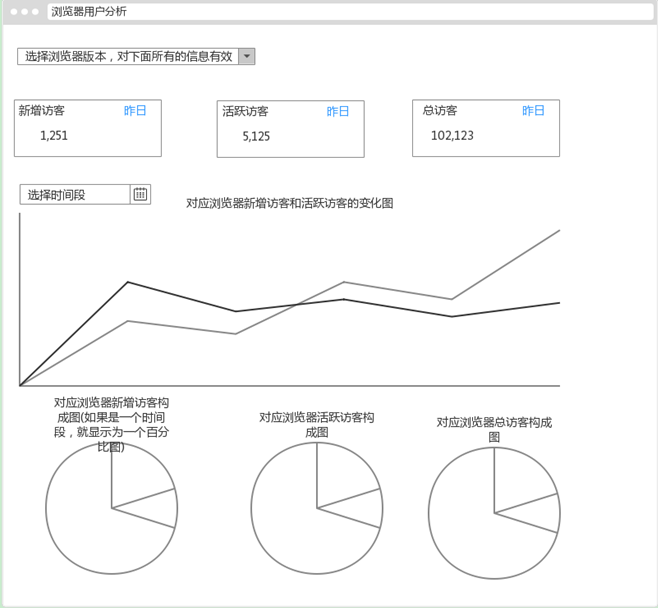
根据分析效果图,找出分析的维度:
用户分析是指某个时间段内的数量变化,浏览器用户分析自然就是某个浏览器在某个时间段内的数量变化,那么根据现有条件确定统计分类的种类,举例说明:
用户基本信息模块:新增用户(时间)
浏览器分析模块:新增用户(时间,浏览器信息)
2018-08-10 www.bjsxt.com zhangsan firefox-48
2018-08-10 www.bjsxt.com lisi firefox-53
MR
map:
2018-08-10 zhangsan
2018-08-10,firefox-48 zhangsan
2018-08-10,firefox-all zhangsan
2018-08-10 lisi
2018-08-10,firefox-53 lisi
2018-08-10,firefix-all lisi
reduce:
2018-08-10 zhangsan 2
2018-08-10 lisi
2018-08-10,firefox-48 zhangsan 1
2018-08-10,firefox-53 lisi 1
2018-08-10,firefix-all lisi 2
2018-08-10,firefox-all zhangsan
模块当做其中一个条件
时间,用户基本信息模块
时间,浏览器,浏览器分析模块
2018-08-10 www.bjsxt.com zhangsan firefox-48
2018-08-10 www.bjsxt.com lisi firefox-53
map
2018-08-10,user zhangsan
2018-08-10,firefox-48,browser zhangsan
2018-08-10,firefix-all,browser zhangsan
2018-08-10,user lisi
2018-08-10,firefox-53,browser lisi
2018-08-10,firefix-all,browser lisi
reduce
2018-08-10,user zhangsan 2
2018-08-10,user lisi
2018-08-10,firefox-48,browser zhangsan 1
2018-08-10,firefox-53,browser lisi 1
2018-08-10,firefix-all,browser zhangsan 2
2018-08-10,firefix-all,browser lisi
Runner:
package com.sxt.transformer.mr.nu; import java.sql.Connection;
import java.sql.Date;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.List;
import java.util.Map; import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.MultipleColumnPrefixFilter;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.log4j.Logger; import com.google.common.collect.Lists;
import com.sxt.common.DateEnum;
import com.sxt.common.EventLogConstants;
import com.sxt.common.EventLogConstants.EventEnum;
import com.sxt.common.GlobalConstants;
import com.sxt.transformer.model.dim.StatsUserDimension;
import com.sxt.transformer.model.dim.base.DateDimension;
import com.sxt.transformer.model.value.map.TimeOutputValue;
import com.sxt.transformer.model.value.reduce.MapWritableValue;
import com.sxt.transformer.mr.TransformerOutputFormat;
import com.sxt.util.JdbcManager;
import com.sxt.util.TimeUtil; /**
* 计算新增用户入口类
*
* @author root
*
*/
public class NewInstallUserRunner implements Tool
{
private static final Logger logger = Logger.getLogger(NewInstallUserRunner.class);
private Configuration conf = new Configuration(); /**
* 入口main方法
*
* @param args
*/
public static void main(String[] args)
{
try
{
ToolRunner.run(new Configuration(), new NewInstallUserRunner(), args);
}
catch (Exception e)
{
logger.error("运行计算新用户的job出现异常", e);
throw new RuntimeException(e);
}
} @Override
public void setConf(Configuration conf)
{
conf.addResource("output-collector.xml");
conf.addResource("query-mapping.xml");
conf.addResource("transformer-env.xml");
conf.set("fs.defaultFS", "hdfs://node101:8020");//HDFS
// conf.set("yarn.resourcemanager.hostname", "node3");
conf.set("hbase.zookeeper.quorum", "node104");//HBase
this.conf = HBaseConfiguration.create(conf);
} @Override
public Configuration getConf() {
return this.conf;
} @Override
public int run(String[] args) throws Exception
{
Configuration conf = this.getConf();
// 处理参数
this.processArgs(conf, args); Job job = Job.getInstance(conf, "new_install_user"); job.setJarByClass(NewInstallUserRunner.class);
// 本地运行
TableMapReduceUtil.initTableMapperJob(
initScans(job),
NewInstallUserMapper.class,
StatsUserDimension.class,
TimeOutputValue.class,
job,
false);
// 集群运行:本地提交和打包(jar)提交
// TableMapReduceUtil.initTableMapperJob(initScans(job), NewInstallUserMapper.class, StatsUserDimension.class, TimeOutputValue.class, job);
job.setReducerClass(NewInstallUserReducer.class);
job.setOutputKeyClass(StatsUserDimension.class);//维度作为key
job.setOutputValueClass(MapWritableValue.class);
// job.setInputFormatClass(KeyValueTextInputFormat.class);
job.setOutputFormatClass(TransformerOutputFormat.class);//自定义输出到mysql的outputformat类
if (job.waitForCompletion(true)) {
// 执行成功, 需要计算总用户
this.calculateTotalUsers(conf);
return 0;
}
else
{
return -1;
}
} /**
* 计算总用户
* 查询昨天和今天统计的数据 然后累加并记录最新数据
* @param conf
*/
private void calculateTotalUsers(Configuration conf) {
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null; try {
long date = TimeUtil.parseString2Long(conf.get(GlobalConstants.RUNNING_DATE_PARAMES));
// 获取今天的date dimension
DateDimension todayDimension = DateDimension.buildDate(date, DateEnum.DAY);
// 获取昨天的date dimension
DateDimension yesterdayDimension = DateDimension.buildDate(date - GlobalConstants.DAY_OF_MILLISECONDS, DateEnum.DAY);
int yesterdayDimensionId = -1;
int todayDimensionId = -1; // 1. 获取时间id
conn = JdbcManager.getConnection(conf, GlobalConstants.WAREHOUSE_OF_REPORT);
// 获取执行时间的昨天的
pstmt = conn.prepareStatement("SELECT `id` FROM `dimension_date` WHERE `year` = ? AND `season` = ? AND `month` = ? AND `week` = ? AND `day` = ? AND `type` = ? AND `calendar` = ?");
int i = 0;
pstmt.setInt(++i, yesterdayDimension.getYear());
pstmt.setInt(++i, yesterdayDimension.getSeason());
pstmt.setInt(++i, yesterdayDimension.getMonth());
pstmt.setInt(++i, yesterdayDimension.getWeek());
pstmt.setInt(++i, yesterdayDimension.getDay());
pstmt.setString(++i, yesterdayDimension.getType());
pstmt.setDate(++i, new Date(yesterdayDimension.getCalendar().getTime()));
rs = pstmt.executeQuery();
if (rs.next()) {
yesterdayDimensionId = rs.getInt(1);
} // 获取执行时间当天的id
pstmt = conn.prepareStatement("SELECT `id` FROM `dimension_date` WHERE `year` = ? AND `season` = ? AND `month` = ? AND `week` = ? AND `day` = ? AND `type` = ? AND `calendar` = ?");
i = 0;
pstmt.setInt(++i, todayDimension.getYear());
pstmt.setInt(++i, todayDimension.getSeason());
pstmt.setInt(++i, todayDimension.getMonth());
pstmt.setInt(++i, todayDimension.getWeek());
pstmt.setInt(++i, todayDimension.getDay());
pstmt.setString(++i, todayDimension.getType());
pstmt.setDate(++i, new Date(todayDimension.getCalendar().getTime()));
rs = pstmt.executeQuery();
if (rs.next()) {
todayDimensionId = rs.getInt(1);
} // 2.获取昨天的原始数据,存储格式为:platformid = totalusers
Map<String, Integer> oldValueMap = new HashMap<String, Integer>(); // 开始更新stats_user
if (yesterdayDimensionId > -1) {
pstmt = conn.prepareStatement("select `platform_dimension_id`,`total_install_users` from `stats_user` where `date_dimension_id`=?");
pstmt.setInt(1, yesterdayDimensionId);
rs = pstmt.executeQuery();
while (rs.next()) {
int platformId = rs.getInt("platform_dimension_id");
int totalUsers = rs.getInt("total_install_users");
oldValueMap.put("" + platformId, totalUsers);
}
} // 添加今天的总用户
pstmt = conn.prepareStatement("select `platform_dimension_id`,`new_install_users` from `stats_user` where `date_dimension_id`=?");
pstmt.setInt(1, todayDimensionId);
rs = pstmt.executeQuery();
while (rs.next()) {
int platformId = rs.getInt("platform_dimension_id");
int newUsers = rs.getInt("new_install_users");
if (oldValueMap.containsKey("" + platformId)) {
newUsers += oldValueMap.get("" + platformId);
}
oldValueMap.put("" + platformId, newUsers);
} // 更新操作
pstmt = conn.prepareStatement("INSERT INTO `stats_user`(`platform_dimension_id`,`date_dimension_id`,`total_install_users`) VALUES(?, ?, ?) ON DUPLICATE KEY UPDATE `total_install_users` = ?");
for (Map.Entry<String, Integer> entry : oldValueMap.entrySet()) {
pstmt.setInt(1, Integer.valueOf(entry.getKey()));
pstmt.setInt(2, todayDimensionId);
pstmt.setInt(3, entry.getValue());
pstmt.setInt(4, entry.getValue());
pstmt.execute();
} // 开始更新stats_device_browser
oldValueMap.clear();
if (yesterdayDimensionId > -1) {
pstmt = conn.prepareStatement("select `platform_dimension_id`,`browser_dimension_id`,`total_install_users` from `stats_device_browser` where `date_dimension_id`=?");
pstmt.setInt(1, yesterdayDimensionId);
rs = pstmt.executeQuery();
while (rs.next()) {
int platformId = rs.getInt("platform_dimension_id");
int browserId = rs.getInt("browser_dimension_id");
int totalUsers = rs.getInt("total_install_users");
oldValueMap.put(platformId + "_" + browserId, totalUsers);
}
} // 添加今天的总用户
pstmt = conn.prepareStatement("select `platform_dimension_id`,`browser_dimension_id`,`new_install_users` from `stats_device_browser` where `date_dimension_id`=?");
pstmt.setInt(1, todayDimensionId);
rs = pstmt.executeQuery();
while (rs.next()) {
int platformId = rs.getInt("platform_dimension_id");
int browserId = rs.getInt("browser_dimension_id");
int newUsers = rs.getInt("new_install_users");
String key = platformId + "_" + browserId;
if (oldValueMap.containsKey(key)) {
newUsers += oldValueMap.get(key);
}
oldValueMap.put(key, newUsers);
} // 更新操作
pstmt = conn.prepareStatement("INSERT INTO `stats_device_browser`(`platform_dimension_id`,`browser_dimension_id`,`date_dimension_id`,`total_install_users`) VALUES(?, ?, ?, ?) ON DUPLICATE KEY UPDATE `total_install_users` = ?");
for (Map.Entry<String, Integer> entry : oldValueMap.entrySet()) {
String[] key = entry.getKey().split("_");
pstmt.setInt(1, Integer.valueOf(key[0]));
pstmt.setInt(2, Integer.valueOf(key[1]));
pstmt.setInt(3, todayDimensionId);
pstmt.setInt(4, entry.getValue());
pstmt.setInt(5, entry.getValue());
pstmt.execute();
} }
catch (SQLException e)
{
e.printStackTrace();
}
} /**
* 处理参数
*
* @param conf
* @param args
*/
private void processArgs(Configuration conf, String[] args) {
String date = null;
for (int i = 0; i < args.length; i++) {
if ("-d".equals(args[i])) {
if (i + 1 < args.length) {
date = args[++i];
break;
}
}
} // 要求date格式为: yyyy-MM-dd
if (StringUtils.isBlank(date) || !TimeUtil.isValidateRunningDate(date)) {
// date是一个无效时间数据
date = TimeUtil.getYesterday(); // 默认时间是昨天
}
System.out.println("----------------------" + date);
conf.set(GlobalConstants.RUNNING_DATE_PARAMES, date);
} /**
* 初始化scan集合
*
* @param job
* @return
*/
private List<Scan> initScans(Job job) {
// 时间戳+....
Configuration conf = job.getConfiguration();
// 获取运行时间: yyyy-MM-dd
String date = conf.get(GlobalConstants.RUNNING_DATE_PARAMES);
long startDate = TimeUtil.parseString2Long(date);
long endDate = startDate + GlobalConstants.DAY_OF_MILLISECONDS; Scan scan = new Scan();
// 定义hbase扫描的开始rowkey和结束rowkey
scan.setStartRow(Bytes.toBytes("" + startDate));
scan.setStopRow(Bytes.toBytes("" + endDate)); FilterList filterList = new FilterList();
// 过滤数据,只分析launch事件
filterList.addFilter(new SingleColumnValueFilter(
Bytes.toBytes(EventLogConstants.EVENT_LOGS_FAMILY_NAME),
Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_EVENT_NAME),
CompareOp.EQUAL,
Bytes.toBytes(EventEnum.LAUNCH.alias)));
// 定义mapper中需要获取的列名
String[] columns = new String[] {
EventLogConstants.LOG_COLUMN_NAME_EVENT_NAME,
EventLogConstants.LOG_COLUMN_NAME_UUID,
EventLogConstants.LOG_COLUMN_NAME_SERVER_TIME,
EventLogConstants.LOG_COLUMN_NAME_PLATFORM,
EventLogConstants.LOG_COLUMN_NAME_BROWSER_NAME,
EventLogConstants.LOG_COLUMN_NAME_BROWSER_VERSION };
// scan.addColumn(family, qualifier)
filterList.addFilter(this.getColumnFilter(columns)); scan.setAttribute(Scan.SCAN_ATTRIBUTES_TABLE_NAME,
Bytes.toBytes(EventLogConstants.HBASE_NAME_EVENT_LOGS));
scan.setFilter(filterList);
return Lists.newArrayList(scan);
} /**
* 获取这个列名过滤的column
*
* @param columns
* @return
*/
private Filter getColumnFilter(String[] columns) {
int length = columns.length;
byte[][] filter = new byte[length][];
for (int i = 0; i < length; i++) {
filter[i] = Bytes.toBytes(columns[i]);
}
return new MultipleColumnPrefixFilter(filter);
}
}
Mapper:
package com.sxt.transformer.mr.nu; import java.io.IOException;
import java.util.List; import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.log4j.Logger; import com.sxt.common.DateEnum;
import com.sxt.common.EventLogConstants;
import com.sxt.common.KpiType;
import com.sxt.transformer.model.dim.StatsCommonDimension;
import com.sxt.transformer.model.dim.StatsUserDimension;
import com.sxt.transformer.model.dim.base.BrowserDimension;
import com.sxt.transformer.model.dim.base.DateDimension;
import com.sxt.transformer.model.dim.base.KpiDimension;
import com.sxt.transformer.model.dim.base.PlatformDimension;
import com.sxt.transformer.model.value.map.TimeOutputValue; /**
* 自定义的计算新用户的mapper类
*
* @author root
*
*/
public class NewInstallUserMapper extends TableMapper<StatsUserDimension, TimeOutputValue> {
//每个分析条件(由各个维度组成的)作为key,uuid作为value private static final Logger logger = Logger.getLogger(NewInstallUserMapper.class); private StatsUserDimension statsUserDimension = new StatsUserDimension();
private TimeOutputValue timeOutputValue = new TimeOutputValue(); private byte[] family = Bytes.toBytes(EventLogConstants.EVENT_LOGS_FAMILY_NAME); //代表用户分析模块的统计
private KpiDimension newInstallUserKpi = new KpiDimension(KpiType.NEW_INSTALL_USER.name);
//浏览器分析模块的统计
private KpiDimension newInstallUserOfBrowserKpi = new KpiDimension(KpiType.BROWSER_NEW_INSTALL_USER.name); /**
* map 读取hbase中的数据,输入数据为:hbase表中每一行。
* 输出key类型:StatsUserDimension
* value类型:TimeOutputValue
*/
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException
{
String uuid = Bytes.toString(value.getValue(family, Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_UUID)));
String serverTime = Bytes.toString(value.getValue(family, Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_SERVER_TIME)));
String platform = Bytes.toString(value.getValue(family, Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_PLATFORM))); System.out.println(uuid + "-" + serverTime + "-" + platform); if (StringUtils.isBlank(uuid) || StringUtils.isBlank(serverTime) || StringUtils.isBlank(platform)) {
logger.warn("uuid&servertime&platform不能为空");
return;
} long longOfTime = Long.valueOf(serverTime.trim());
timeOutputValue.setId(uuid); // 设置id为uuid
timeOutputValue.setTime(longOfTime); // 设置时间为服务器时间 // 设置date维度
DateDimension dateDimension = DateDimension.buildDate(longOfTime, DateEnum.DAY);
StatsCommonDimension statsCommonDimension = this.statsUserDimension.getStatsCommon();
statsCommonDimension.setDate(dateDimension); List<PlatformDimension> platformDimensions = PlatformDimension.buildList(platform); // browser相关的数据
String browserName = Bytes.toString(value.getValue(family, Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_BROWSER_NAME)));
String browserVersion = Bytes.toString(value.getValue(family, Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_BROWSER_VERSION)));
List<BrowserDimension> browserDimensions = BrowserDimension.buildList(browserName, browserVersion); //空浏览器维度,不考虑浏览器维度
BrowserDimension defaultBrowser = new BrowserDimension("", "");
for (PlatformDimension pf : platformDimensions) {
//用户分析
statsUserDimension.setBrowser(defaultBrowser);
statsCommonDimension.setKpi(newInstallUserKpi);
statsCommonDimension.setPlatform(pf);
context.write(statsUserDimension, timeOutputValue);
//浏览器用户分析
for (BrowserDimension br : browserDimensions) {
statsCommonDimension.setKpi(newInstallUserOfBrowserKpi);
statsUserDimension.setBrowser(br);
context.write(statsUserDimension, timeOutputValue);
}
}
}
}
Reducer:
package com.sxt.transformer.mr.nu; import java.io.IOException;
import java.util.HashSet;
import java.util.Set; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.MapWritable;
import org.apache.hadoop.mapreduce.Reducer; import com.sxt.common.KpiType;
import com.sxt.transformer.model.dim.StatsUserDimension;
import com.sxt.transformer.model.value.map.TimeOutputValue;
import com.sxt.transformer.model.value.reduce.MapWritableValue; /**
* 计算new isntall user的reduce类
*
* @author root
*
*/
public class NewInstallUserReducer extends Reducer<StatsUserDimension, TimeOutputValue, StatsUserDimension, MapWritableValue> {
private MapWritableValue outputValue = new MapWritableValue();
private Set<String> unique = new HashSet<String>(); @Override
protected void reduce(StatsUserDimension key, Iterable<TimeOutputValue> values, Context context) throws IOException, InterruptedException {
this.unique.clear(); // 开始计算uuid的个数
for (TimeOutputValue value : values) {
this.unique.add(value.getId());//uid,用户ID
} MapWritable map = new MapWritable();//相当于java中HashMap
map.put(new IntWritable(-1), new IntWritable(this.unique.size()));
outputValue.setValue(map); // 设置kpi名称-模块名 告诉数据库插入哪张表中
String kpiName = key.getStatsCommon().getKpi().getKpiName();
if (KpiType.NEW_INSTALL_USER.name.equals(kpiName)) {
// 计算stats_user表中的新增用户
outputValue.setKpi(KpiType.NEW_INSTALL_USER);
} else if (KpiType.BROWSER_NEW_INSTALL_USER.name.equals(kpiName)) {
// 计算stats_device_browser表中的新增用户
outputValue.setKpi(KpiType.BROWSER_NEW_INSTALL_USER);
}
context.write(key, outputValue);
}
}
统计维度StatsUserDimension:
package com.sxt.transformer.mr.nu; import java.sql.Connection;
import java.sql.Date;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.List;
import java.util.Map; import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.MultipleColumnPrefixFilter;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.log4j.Logger; import com.google.common.collect.Lists;
import com.sxt.common.DateEnum;
import com.sxt.common.EventLogConstants;
import com.sxt.common.EventLogConstants.EventEnum;
import com.sxt.common.GlobalConstants;
import com.sxt.transformer.model.dim.StatsUserDimension;
import com.sxt.transformer.model.dim.base.DateDimension;
import com.sxt.transformer.model.value.map.TimeOutputValue;
import com.sxt.transformer.model.value.reduce.MapWritableValue;
import com.sxt.transformer.mr.TransformerOutputFormat;
import com.sxt.util.JdbcManager;
import com.sxt.util.TimeUtil; /**
* 计算新增用户入口类
*
* @author root
*
*/
public class NewInstallUserRunner implements Tool
{
private static final Logger logger = Logger.getLogger(NewInstallUserRunner.class);
private Configuration conf = new Configuration(); /**
* 入口main方法
*
* @param args
*/
public static void main(String[] args)
{
try
{
ToolRunner.run(new Configuration(), new NewInstallUserRunner(), args);
}
catch (Exception e)
{
logger.error("运行计算新用户的job出现异常", e);
throw new RuntimeException(e);
}
} @Override
public void setConf(Configuration conf)
{
conf.addResource("output-collector.xml");
conf.addResource("query-mapping.xml");
conf.addResource("transformer-env.xml");
conf.set("fs.defaultFS", "hdfs://node101:8020");//HDFS
// conf.set("yarn.resourcemanager.hostname", "node3");
conf.set("hbase.zookeeper.quorum", "node104");//HBase
this.conf = HBaseConfiguration.create(conf);
} @Override
public Configuration getConf() {
return this.conf;
} @Override
public int run(String[] args) throws Exception
{
Configuration conf = this.getConf();
// 处理参数
this.processArgs(conf, args); Job job = Job.getInstance(conf, "new_install_user"); job.setJarByClass(NewInstallUserRunner.class);
// 本地运行
TableMapReduceUtil.initTableMapperJob(
initScans(job),
NewInstallUserMapper.class,
StatsUserDimension.class,
TimeOutputValue.class,
job,
false);
// 集群运行:本地提交和打包(jar)提交
// TableMapReduceUtil.initTableMapperJob(initScans(job), NewInstallUserMapper.class, StatsUserDimension.class, TimeOutputValue.class, job);
job.setReducerClass(NewInstallUserReducer.class);
job.setOutputKeyClass(StatsUserDimension.class);//维度作为key
job.setOutputValueClass(MapWritableValue.class);
// job.setInputFormatClass(KeyValueTextInputFormat.class);
job.setOutputFormatClass(TransformerOutputFormat.class);//自定义输出到mysql的outputformat类
if (job.waitForCompletion(true)) {
// 执行成功, 需要计算总用户
this.calculateTotalUsers(conf);
return 0;
}
else
{
return -1;
}
} /**
* 计算总用户
* 查询昨天和今天统计的数据 然后累加并记录最新数据
* @param conf
*/
private void calculateTotalUsers(Configuration conf) {
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null; try {
long date = TimeUtil.parseString2Long(conf.get(GlobalConstants.RUNNING_DATE_PARAMES));
// 获取今天的date dimension
DateDimension todayDimension = DateDimension.buildDate(date, DateEnum.DAY);
// 获取昨天的date dimension
DateDimension yesterdayDimension = DateDimension.buildDate(date - GlobalConstants.DAY_OF_MILLISECONDS, DateEnum.DAY);
int yesterdayDimensionId = -1;
int todayDimensionId = -1; // 1. 获取时间id
conn = JdbcManager.getConnection(conf, GlobalConstants.WAREHOUSE_OF_REPORT);
// 获取执行时间的昨天的
pstmt = conn.prepareStatement("SELECT `id` FROM `dimension_date` WHERE `year` = ? AND `season` = ? AND `month` = ? AND `week` = ? AND `day` = ? AND `type` = ? AND `calendar` = ?");
int i = 0;
pstmt.setInt(++i, yesterdayDimension.getYear());
pstmt.setInt(++i, yesterdayDimension.getSeason());
pstmt.setInt(++i, yesterdayDimension.getMonth());
pstmt.setInt(++i, yesterdayDimension.getWeek());
pstmt.setInt(++i, yesterdayDimension.getDay());
pstmt.setString(++i, yesterdayDimension.getType());
pstmt.setDate(++i, new Date(yesterdayDimension.getCalendar().getTime()));
rs = pstmt.executeQuery();
if (rs.next()) {
yesterdayDimensionId = rs.getInt(1);
} // 获取执行时间当天的id
pstmt = conn.prepareStatement("SELECT `id` FROM `dimension_date` WHERE `year` = ? AND `season` = ? AND `month` = ? AND `week` = ? AND `day` = ? AND `type` = ? AND `calendar` = ?");
i = 0;
pstmt.setInt(++i, todayDimension.getYear());
pstmt.setInt(++i, todayDimension.getSeason());
pstmt.setInt(++i, todayDimension.getMonth());
pstmt.setInt(++i, todayDimension.getWeek());
pstmt.setInt(++i, todayDimension.getDay());
pstmt.setString(++i, todayDimension.getType());
pstmt.setDate(++i, new Date(todayDimension.getCalendar().getTime()));
rs = pstmt.executeQuery();
if (rs.next()) {
todayDimensionId = rs.getInt(1);
} // 2.获取昨天的原始数据,存储格式为:platformid = totalusers
Map<String, Integer> oldValueMap = new HashMap<String, Integer>(); // 开始更新stats_user
if (yesterdayDimensionId > -1) {
pstmt = conn.prepareStatement("select `platform_dimension_id`,`total_install_users` from `stats_user` where `date_dimension_id`=?");
pstmt.setInt(1, yesterdayDimensionId);
rs = pstmt.executeQuery();
while (rs.next()) {
int platformId = rs.getInt("platform_dimension_id");
int totalUsers = rs.getInt("total_install_users");
oldValueMap.put("" + platformId, totalUsers);
}
} // 添加今天的总用户
pstmt = conn.prepareStatement("select `platform_dimension_id`,`new_install_users` from `stats_user` where `date_dimension_id`=?");
pstmt.setInt(1, todayDimensionId);
rs = pstmt.executeQuery();
while (rs.next()) {
int platformId = rs.getInt("platform_dimension_id");
int newUsers = rs.getInt("new_install_users");
if (oldValueMap.containsKey("" + platformId)) {
newUsers += oldValueMap.get("" + platformId);
}
oldValueMap.put("" + platformId, newUsers);
} // 更新操作
pstmt = conn.prepareStatement("INSERT INTO `stats_user`(`platform_dimension_id`,`date_dimension_id`,`total_install_users`) VALUES(?, ?, ?) ON DUPLICATE KEY UPDATE `total_install_users` = ?");
for (Map.Entry<String, Integer> entry : oldValueMap.entrySet()) {
pstmt.setInt(1, Integer.valueOf(entry.getKey()));
pstmt.setInt(2, todayDimensionId);
pstmt.setInt(3, entry.getValue());
pstmt.setInt(4, entry.getValue());
pstmt.execute();
} // 开始更新stats_device_browser
oldValueMap.clear();
if (yesterdayDimensionId > -1) {
pstmt = conn.prepareStatement("select `platform_dimension_id`,`browser_dimension_id`,`total_install_users` from `stats_device_browser` where `date_dimension_id`=?");
pstmt.setInt(1, yesterdayDimensionId);
rs = pstmt.executeQuery();
while (rs.next()) {
int platformId = rs.getInt("platform_dimension_id");
int browserId = rs.getInt("browser_dimension_id");
int totalUsers = rs.getInt("total_install_users");
oldValueMap.put(platformId + "_" + browserId, totalUsers);
}
} // 添加今天的总用户
pstmt = conn.prepareStatement("select `platform_dimension_id`,`browser_dimension_id`,`new_install_users` from `stats_device_browser` where `date_dimension_id`=?");
pstmt.setInt(1, todayDimensionId);
rs = pstmt.executeQuery();
while (rs.next()) {
int platformId = rs.getInt("platform_dimension_id");
int browserId = rs.getInt("browser_dimension_id");
int newUsers = rs.getInt("new_install_users");
String key = platformId + "_" + browserId;
if (oldValueMap.containsKey(key)) {
newUsers += oldValueMap.get(key);
}
oldValueMap.put(key, newUsers);
} // 更新操作
pstmt = conn.prepareStatement("INSERT INTO `stats_device_browser`(`platform_dimension_id`,`browser_dimension_id`,`date_dimension_id`,`total_install_users`) VALUES(?, ?, ?, ?) ON DUPLICATE KEY UPDATE `total_install_users` = ?");
for (Map.Entry<String, Integer> entry : oldValueMap.entrySet()) {
String[] key = entry.getKey().split("_");
pstmt.setInt(1, Integer.valueOf(key[0]));
pstmt.setInt(2, Integer.valueOf(key[1]));
pstmt.setInt(3, todayDimensionId);
pstmt.setInt(4, entry.getValue());
pstmt.setInt(5, entry.getValue());
pstmt.execute();
} }
catch (SQLException e)
{
e.printStackTrace();
}
} /**
* 处理参数
*
* @param conf
* @param args
*/
private void processArgs(Configuration conf, String[] args) {
String date = null;
for (int i = 0; i < args.length; i++) {
if ("-d".equals(args[i])) {
if (i + 1 < args.length) {
date = args[++i];
break;
}
}
} // 要求date格式为: yyyy-MM-dd
if (StringUtils.isBlank(date) || !TimeUtil.isValidateRunningDate(date)) {
// date是一个无效时间数据
date = TimeUtil.getYesterday(); // 默认时间是昨天
}
System.out.println("----------------------" + date);
conf.set(GlobalConstants.RUNNING_DATE_PARAMES, date);
} /**
* 初始化scan集合
*
* @param job
* @return
*/
private List<Scan> initScans(Job job) {
// 时间戳+....
Configuration conf = job.getConfiguration();
// 获取运行时间: yyyy-MM-dd
String date = conf.get(GlobalConstants.RUNNING_DATE_PARAMES);
long startDate = TimeUtil.parseString2Long(date);
long endDate = startDate + GlobalConstants.DAY_OF_MILLISECONDS; Scan scan = new Scan();
// 定义hbase扫描的开始rowkey和结束rowkey
scan.setStartRow(Bytes.toBytes("" + startDate));
scan.setStopRow(Bytes.toBytes("" + endDate)); FilterList filterList = new FilterList();
// 过滤数据,只分析launch事件
filterList.addFilter(new SingleColumnValueFilter(
Bytes.toBytes(EventLogConstants.EVENT_LOGS_FAMILY_NAME),
Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_EVENT_NAME),
CompareOp.EQUAL,
Bytes.toBytes(EventEnum.LAUNCH.alias)));
// 定义mapper中需要获取的列名
String[] columns = new String[] {
EventLogConstants.LOG_COLUMN_NAME_EVENT_NAME,
EventLogConstants.LOG_COLUMN_NAME_UUID,
EventLogConstants.LOG_COLUMN_NAME_SERVER_TIME,
EventLogConstants.LOG_COLUMN_NAME_PLATFORM,
EventLogConstants.LOG_COLUMN_NAME_BROWSER_NAME,
EventLogConstants.LOG_COLUMN_NAME_BROWSER_VERSION };
// scan.addColumn(family, qualifier)
filterList.addFilter(this.getColumnFilter(columns)); scan.setAttribute(Scan.SCAN_ATTRIBUTES_TABLE_NAME,
Bytes.toBytes(EventLogConstants.HBASE_NAME_EVENT_LOGS));
scan.setFilter(filterList);
return Lists.newArrayList(scan);
} /**
* 获取这个列名过滤的column
*
* @param columns
* @return
*/
private Filter getColumnFilter(String[] columns) {
int length = columns.length;
byte[][] filter = new byte[length][];
for (int i = 0; i < length; i++) {
filter[i] = Bytes.toBytes(columns[i]);
}
return new MultipleColumnPrefixFilter(filter);
}
}
输出到mysql的outputformat类:
package com.sxt.transformer.mr; import java.io.IOException;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.Map; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.OutputCommitter;
import org.apache.hadoop.mapreduce.OutputFormat;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.log4j.Logger; import com.sxt.common.GlobalConstants;
import com.sxt.common.KpiType;
import com.sxt.transformer.model.dim.base.BaseDimension;
import com.sxt.transformer.model.value.BaseStatsValueWritable;
import com.sxt.transformer.service.IDimensionConverter;
import com.sxt.transformer.service.impl.DimensionConverterImpl;
import com.sxt.util.JdbcManager; /**
* 自定义输出到mysql的outputformat类
* BaseDimension:reducer输出的key
* BaseStatsValueWritable:reducer输出的value
* @author root
*
*/
public class TransformerOutputFormat extends OutputFormat<BaseDimension, BaseStatsValueWritable> {
private static final Logger logger = Logger.getLogger(TransformerOutputFormat.class); /**
* 定义每条数据的输出格式,一条数据就是reducer任务每次执行write方法输出的数据。
*/
@Override
public RecordWriter<BaseDimension, BaseStatsValueWritable> getRecordWriter(TaskAttemptContext context) throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
Connection conn = null;
IDimensionConverter converter = new DimensionConverterImpl();
try {
conn = JdbcManager.getConnection(conf, GlobalConstants.WAREHOUSE_OF_REPORT);
conn.setAutoCommit(false);
} catch (SQLException e) {
logger.error("获取数据库连接失败", e);
throw new IOException("获取数据库连接失败", e);
}
return new TransformerRecordWriter(conn, conf, converter);
} @Override
public void checkOutputSpecs(JobContext context) throws IOException, InterruptedException {
// 检测输出空间,输出到mysql不用检测
} @Override
public OutputCommitter getOutputCommitter(TaskAttemptContext context) throws IOException, InterruptedException {
return new FileOutputCommitter(FileOutputFormat.getOutputPath(context), context);
} /**
* 自定义具体数据输出writer
*
* @author root
*
*/
public class TransformerRecordWriter extends RecordWriter<BaseDimension, BaseStatsValueWritable> {
private Connection conn = null;
private Configuration conf = null;
private IDimensionConverter converter = null;
private Map<KpiType, PreparedStatement> map = new HashMap<KpiType, PreparedStatement>();
private Map<KpiType, Integer> batch = new HashMap<KpiType, Integer>(); public TransformerRecordWriter(Connection conn, Configuration conf, IDimensionConverter converter) {
super();
this.conn = conn;
this.conf = conf;
this.converter = converter;
} @Override
/**
* 当reduce任务输出数据是,由计算框架自动调用。把reducer输出的数据写到mysql中
*/
public void write(BaseDimension key, BaseStatsValueWritable value) throws IOException, InterruptedException {
if (key == null || value == null) {
return;
} try {
KpiType kpi = value.getKpi();
PreparedStatement pstmt = null;//每一个pstmt对象对应一个sql语句
int count = 1;//sql语句的批处理,一次执行10
if (map.get(kpi) == null)
{
// 使用kpi进行区分,返回sql保存到config中
pstmt = this.conn.prepareStatement(conf.get(kpi.name));
map.put(kpi, pstmt);
}
else
{
pstmt = map.get(kpi);
count = batch.get(kpi);
count++;
}
batch.put(kpi, count); // 批量次数的存储 String collectorName = conf.get(GlobalConstants.OUTPUT_COLLECTOR_KEY_PREFIX + kpi.name);
Class<?> clazz = Class.forName(collectorName);
IOutputCollector collector = (IOutputCollector) clazz.newInstance();//把value插入到mysql的方法。由于kpi维度不一样。插入到不能表里面。
collector.collect(conf, key, value, pstmt, converter); if (count % Integer.valueOf(conf.get(GlobalConstants.JDBC_BATCH_NUMBER, GlobalConstants.DEFAULT_JDBC_BATCH_NUMBER)) == 0) {
pstmt.executeBatch();
conn.commit();
batch.put(kpi, 0); // 对应批量计算删除
}
}
catch (Throwable e)
{
logger.error("在writer中写数据出现异常", e);
throw new IOException(e);
}
} @Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
try {
for (Map.Entry<KpiType, PreparedStatement> entry : this.map.entrySet()) {
entry.getValue().executeBatch();
}
} catch (SQLException e) {
logger.error("执行executeUpdate方法异常", e);
throw new IOException(e);
} finally {
try {
if (conn != null) {
conn.commit(); // 进行connection的提交动作
}
} catch (Exception e) {
// nothing
} finally {
for (Map.Entry<KpiType, PreparedStatement> entry : this.map.entrySet()) {
try {
entry.getValue().close();
} catch (SQLException e) {
// nothing
}
}
if (conn != null)
try {
conn.close();
} catch (Exception e) {
// nothing
}
}
}
} }
}
项目代码参考:wjy.rar
【电商日志项目之五】数据分析-MR方式的更多相关文章
- 【电商日志项目之六】数据分析-Hive方式
环境 hadoop-2.6.5 hive-1.2.1 一.Hive和Hbase整合如果使用Hive进行分析,Hive要从Hbase取数据(当然可以直接将数据存到Hive),那么就需要将Hive和HBa ...
- 【电商日志项目之四】数据清洗-ETL
环境 hadoop-2.6.5 首先要知道为什么要做数据清洗?通过各个渠道收集到的数据并不能直接用于下一步的分析,所以需要对这些数据进行缺失值清洗.格式内容清洗.逻辑错误清洗.非需求数据清洗.关联性验 ...
- 01-Flutter移动电商实战-项目学习记录
一直想系统性的学习一下 Flutter,正好看到该课程<Flutter移动电商实战>的百度云资源,共 69 课时,由于怕自己坚持不下去(经常学着学着就不学了),故采用博客监督以记之. 1. ...
- Mall电商实战项目发布重大更新,全面支持SpringBoot 2.3.0
1. 前言 前面近一个月去写自己的mybatis框架了,对mybatis源码分析止步不前,此文继续前面的文章.开始分析mybatis一,二级缓存的实现. 附上自己的项目github地址:https:/ ...
- 电商网站项目Angular+Bootstrap+Node+Express+Mysql
1.登陆 2.注册 3.主页 4.购物车 5.管理中心 6.文件上传 代码: https://github.com/Carol0311/min_Shop.git 后期会持续进行功能更新以及开发阶段遇到 ...
- 16套java架构师,高并发,高可用,高性能,集群,大型分布式电商项目实战视频教程
16套Java架构师,集群,高可用,高可扩展,高性能,高并发,性能优化,设计模式,数据结构,虚拟机,微服务架构,日志分析,工作流,Jvm,Dubbo ,Spring boot,Spring cloud ...
- 微服务电商项目发布重大更新,打造Spring Cloud最佳实践!
Spring Cloud实战电商项目mall-swarm地址:转发+关注 私信我获取地址 系统架构图 系统架构图 项目组织结构 mall├── mall-common-- 工具类及通用代码模块├─ ...
- Cloudera Hadoop 4 实战课程(Hadoop 2.0、集群界面化管理、电商在线查询+日志离线分析)
课程大纲及内容简介: 每节课约35分钟,共不下40讲 第一章(11讲) ·分布式和传统单机模式 ·Hadoop背景和工作原理 ·Mapreduce工作原理剖析 ·第二代MR--YARN原理剖析 ·Cl ...
- C# 大型电商项目性能优化(一)
经过几个月的忙碌,我厂最近的电商平台项目终于上线,期间遇到的问题以及解决方案,也可以拿来和大家多做交流了. 我厂的项目大多采用C#.net,使用逐渐发展并流行起来的EF(Entity Framewor ...
随机推荐
- linux Crontab定时备份项目案例
首先先写好备份的脚本(拷贝的命令) #bash/bin cd /finance/tomcat8-finance/wtpwebapps tar -czf /finance/webapp_backup/* ...
- C#各版本
C#各版本 本系列文章主要整理并介绍 C# 各版本的新增功能. C# 8.0 C#8.0 于 2019年4月 随 .NET Framework 4.8 与 Visual Studio 2019 一同发 ...
- jpa之No property buyerOpenId found for type OrderMaster! Did you mean 'buyerOpenid'?
java.lang.IllegalStateException: Failed to load ApplicationContext at org.springframework.test.conte ...
- IntelliJ IDEA 2019.2破解
IntelliJ IDEA 2019.2破解 我是参考这个激活的,使用的激活码的方式,需要在百度云盘下载压缩包 https://zhile.io/2018/08/25/jetbrains-licens ...
- JQuery系列(4) - AJAX方法
jQuery对象上面还定义了Ajax方法($.ajax()),用来处理Ajax操作.调用该方法后,浏览器就会向服务器发出一个HTTP请求. $.ajax方法 $.ajax()的用法主要有两种. $.a ...
- How Open Source Became The Default Business Model For Software
https://www.forbes.com/sites/forbestechcouncil/2018/07/16/how-open-source-became-the-default-busines ...
- JS优化常用片断
防抖debounce装饰器 在事件被触发n秒后再执行回调,如果在这n秒内又被触发,则重新计时. function debounce(func, delay) { let isCooldown = fa ...
- learning svn diff --summarize
# svn diff --summarizeA armbian-custom-dc/test/4g-power.shA armbian-custom-dc/test/4g-reset.shM armb ...
- Android入门教程(四)
关注我,每天都有优质技术文章推送,工作,学习累了的时候放松一下自己. 本篇文章同步微信公众号 欢迎大家关注我的微信公众号:「醉翁猫咪」 学习Android要掌握Android程序结构,和通信技术,和如 ...
- HDU-5215 Cycle(边双/判奇偶环)
题目 HDU-5215 Cycle 网上那个啥dfs的垃圾做法随便弄组数据已经hack掉了 做法 纯奇环偶环通过dfs树上,染色判断(由于偶环可能有两个奇环,通过一点相交,dfs树上并不能判完) 两环 ...