kubernetes 配置网络插件 flannel
概述
在学习docker时知道docker有四种常用的网络模型
- bridge:桥接式网络
- joined:联盟式网络,共享使用另外一个容器的网络名称空间
- opened:容器直接共享使用宿主机的网络名称空间
- none:不使用任何网络名称空间
无论是哪一种网络方式都会导致如果我们跨节点之间的容器之间进行通信时必须要使用NAT机制来实现,任何pod在访问出去之前因为自己是私有网络中的地址,在离开本机时候必须要做源地址转换以确保能够拿着物理机的地址出去,而后每一个pod要想被别人所访问或者每一个容器在上下文当中它也访问不到我们还来做什么?从下图中可以看到,第一个节点上我们有container1,container1自己使用虚拟网卡(纯软件)的方式生成一个网络接口,它通常是一个v1th格式的网络接口,一半在容器上一半在宿主机上并关联到docker0桥上,所以他是一个私网地址,我们使用172.17.0.2这样的地址,很显然在这个地址出去访问其它物理机地址的时候物理机能收到请求没有问题因为它的网关有可能都已经通过打开核心转换要通过eth0即宿主机的网络发出来,但是对端主机收到以后响应给谁?是不是没法响应了,因为这是私网地址,而且是nat背后的私网地址,或者是位于某个服务器背后的私有地址,因此为了确保能够响应到我们任然能送回这个主机,我们需要在本地做原地址转换,同样的,如果container2希望被别人访问到我们需要在宿主机上的物理接口上做dnat将服务暴露出去,因此被别人访问时,假如有个物理机要访问docker2时就应该访问其宿主机上的eth0上的某一端口,再目标地址转换至container2的eth0的地址上来,所以如果我们刚好是container1和container2通信,那就是两级nat转换了,首先,对container1来讲,其报文离开本机的时候要做snat,然后这个报文接入物理网络发给container2的宿主机的时候我们还需要dnat一次然后到container2,container2响应的报文也是一样的逻辑。当前,dnat和snat都是都是自动实现的,不需要手动设置。这个过程是必不可少的
这样的话就会导致我们网络通信性能很差不说,并且container1其实一直不知道自己访问的是谁,他访问的是container2但实际上他的目标地址指向的是eth0的地址,并且container2一直不知道访问自己的是谁,因为他收到的请求是左侧eth0的,他实际上是被container1所访问

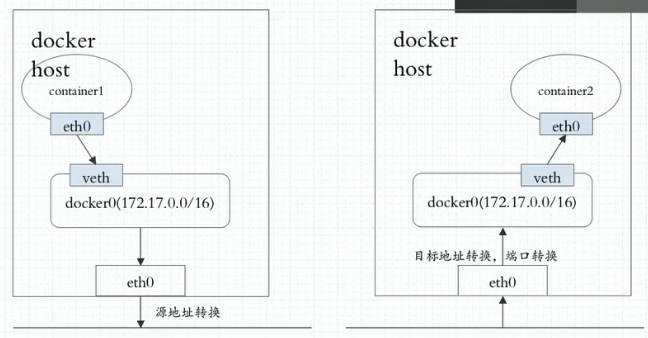
k8s之上的网络通讯模型
所以这种通信方式实在是让人觉得效率低而且很难去构建我们自己真正需要的网络通讯模型。因此k8s作为一个编排工具来讲他本身就必须需要让我们容器工作在多个节点之上,而且是pod的形式,各pod之间是需要进行通信的,而且在k8s之上要求我们pod之间通信大概存在以下情形
- 容器间通信:同一个Pod内的多个容器间的通信: lo
- pod间通信:pod间通信k8s要求他们之间的通信必须是所见即所得,即一个pod的IP到另一个pod的IP之间通信不经过任何NAT转换,要直达
- pod与service通信:即pod IP 与cluster IP之间直接通信,他们其实不在同一个网段,但是他们通过我们本地的IPVS或者iptables规则能实现通信,而且我们知道1.11上的kube-proxy也支持IPVS类型的service,只不过我们以前没有激活过。即pod IP与cluster IP通信是通过系统上已有的iptables或ipvs规则来实现的,这里特别提醒一下ipvs取代不了iptables,因为ipvs只能拿来做负载均衡,做nat转换这个功能就做不到
- service与集群外部客户端的通信;使用ingress 或nodeport或loadblance类型的service来实现
我们此前说过利用一个新的环境变量能够在部署的时候就能够实现IPVS后来发现这种方式不行,其实在我们使用kubeadm部署k8s集群时不需要这么做,最简单的办法就是直接改kube-proxy的配置文件。我们去往每一个节点都已经默认加载了ipvs内核模块,调度算法模块等等,还有连接追踪模块。我们来看一下kube-system名称空间的configmap,可以看到一个叫做kube-proxy,这里面定义了我们kube-proxy到底使用哪种模式在工作,将其中的mode定义为ipvs再重载一下即可
kubectl get configmap -n kube-system
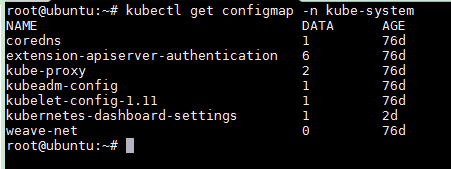
apiVersion: v1
data:
config.conf: |-
apiVersion: kubeproxy.config.k8s.io/v1alpha1
bindAddress: 0.0.0.0
clientConnection:
acceptContentTypes: ""
burst:
contentType: application/vnd.kubernetes.protobuf
kubeconfig: /var/lib/kube-proxy/kubeconfig.conf
qps:
clusterCIDR: 10.244.0.0/
configSyncPeriod: 15m0s
conntrack:
max: null
maxPerCore:
min:
tcpCloseWaitTimeout: 1h0m0s
tcpEstablishedTimeout: 24h0m0s
enableProfiling: false
healthzBindAddress: 0.0.0.0:
hostnameOverride: ""
iptables:
masqueradeAll: false
masqueradeBit:
minSyncPeriod: 0s
syncPeriod: 30s
ipvs:
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: ""
syncPeriod: 30s
kind: KubeProxyConfiguration
metricsBindAddress: 127.0.0.1:
mode: "" #将此处改为ipvs即可
nodePortAddresses: null
oomScoreAdj: -
portRange: ""
resourceContainer: /kube-proxy
udpIdleTimeout: 250ms
kubeconfig.conf: |-
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
server: https://192.168.10.10:6443
name: default
contexts:
- context:
cluster: default
namespace: default
user: default
name: default
current-context: default
users:
- name: default
user:
tokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
kind: ConfigMap
metadata:
creationTimestamp: --08T10::16Z
labels:
app: kube-proxy
name: kube-proxy
namespace: kube-system
resourceVersion: ""
selfLink: /api/v1/namespaces/kube-system/configmaps/kube-proxy
uid: 5c27af66--11e9-be24-000c29d142be
kubectl get configmap kube-proxy -n kube-system -o yaml
k8s最有意思的是他的网络实现不是自己来实现的,而是要靠网络插件。即CNI(容器网络接口)接口插件标准接入进来的其它插件来实现,即k8s自身并不提供网络解决方案,他允许去使用去托管第三方的任何解决方案,代为解决k8s中能解决这四种通信模型中需要执行通信或解决任何第三方程序都可以,这种解决方案是非常非常多的,有几十种,目前来讲比较流行的就是flannel,calico,以及二者拼凑起来的canel,事实上我们k8s自己也有据说性能比较好的插件比如kube-router等等,但无论是哪一种插件他们试图去解决这四种通信时所用到的解决方案无非就这么几种
1 虚拟网桥:brdige,用纯软件的方式实现一个虚拟网络,用一个虚拟网卡接入到我们网桥上去。这样就能保证每一个容器和每一个pod都能有一个专用的网络接口,从而实现每一主机组件有网络接口。每一对网卡一半留在pod之上一半留在宿主机之上并接入到网桥中。甚至能接入到真实的物理网桥上能顾实现物理桥接的方式
2 多路复用: MacVLAN,基于mac的方式去创建vlan,为每一个虚拟接口配置一个独有的mac地址,使得一个物理网卡能承载多个容器去使用。这样子他们就直接使用物理网卡并直接使用物理网卡中的MacVLAN机制进行跨节点之间进行通信了
3 硬件交换:使用支持单根IOV(SR-IOV)的方式,一个网卡支持直接在物理机虚拟出多个接口来,所以我们称为单根的网络连接方式,现在市面上的很多网卡都已经支持单根IOV的虚拟化了。它是创建虚拟设备的一种很高性能的方式,一个网卡能够虚拟出在硬件级多个网卡来。然后让每个容器使用一个网卡
相比来说性能肯定是硬件交换的方式效果更好,不过很多情况下我们用户期望去创建二层或三层的一些逻辑网络子网这就需要借助于叠加的网络协议来实现,所以会发现在多种解决方案中第一种叫使用虚拟网桥确实我们能够实现更为强大的控制能力的解决方案,但是这种控制确实实现的功能强大但多一点,他对网络传输来讲有额外的性能开销,毕竟他叫使用隧道网络,或者我们把它称之为叠加网络,要多封装IP守护或多封装mac守护,不过一般来讲我们使用这种叠加网络时控制平面目前而言还没有什么好的标准化,那么用起来彼此之间有可能不兼容,另外如果我们要使用VXLAN这种技术可能会引入更高的开销,这种方式给了用户更大的腾挪的空间
如果我们期望去使用这种所谓的CNI插件对整个k8s来讲非常简单,只需要在kubelete配置文件或在启动时直接通过一个目录路径去加载插件配置文件, /etc/cni/net.d/,因此我们只要把配置文件扔到这个目录中去他就可以被识别并加载为我们插件使用
ls /etc/cni/net.d/

{
"name": "cbr0",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
cat /etc/cni/net.d/10-flannel.conflist
任何其它网络插件部署上来也是如此,把配置文件扔到这个目录下从而被kubelete所加载,从而能够被kubelete作为必要时创建一个pod,这个pod应该有网络和网卡,那么它的网络和网卡怎么生成的呢?kubelet就调用这个目录下的由配置文件指定的网络插件,由网络插件代为实现地址分配,接口创建,网络创建等各种功能。这就是CNI,CNI是一个JSON格式的配置文件,另外他有必要有可能还会调IP地址管理一些二层的模块来实现一些更为强大的管理功能。
通常来讲CNI本身只是一种规范,CNI的插件是说我们的容器网络插件应该怎么定义,网络接口应该怎么定义等等,目前来讲我们CNI插件分为三类,了解即可。不同的网络插件在实现地址管理时可能略有不同,而flannel,calico,canel,kube-router等等都是解决方案,据统计,flannel目前来讲份额还是最大的。但是其有个缺陷,在k8s上网络插件不但要实现网络地址分配等功能,网络管理等功能,他还需要实现网络策略,可以去定义pod和pod之间能不能通信等等,大家知道我们在k8s上是存在网络名称空间的,但是这个名称空间他并不隔离Pod的访问,虽然隔离了用户的权限,比如我们定义说rolebinding以后我们一个用户只能管理这个名称空间的资源,但是,他却能够指挥着这个pod资源去访问另一个名称空间的pod资源,pod和pod之间在网络上都属于同一网段,他们彼此之间没有任何隔离特性,万一你的k8s集群有两个项目,彼此之间不认识,万一要互害的时候是没有隔离特性的。所以我们需要确保网络插件能够实现辅助设置pod和pod之间是否能够互相访问的网络策略,但是flannel是不支持网络策略的。calico虽然部署和配置比flannel麻烦很多,但是calico即支持地址分配又支持网络策略,因此其虽然复杂,但是却很受用户接受。还有一点就是calico在实现地址转发的方式中可以基于bgp的方式实现三层网络路由,因此在性能上据说比flannel要强一些。但是flannel也支持三种网络方式。默认是叠加的,我们使用host gw其实可能比我们想象的功能要强大的多
这是介绍的网络插件,我们经常使用时可以兼顾使用flannel的简单,借助于calico实现网络策略,也没必要直接部署canel,可以直接部署flannel做平时的网络管理功能若需要用到网络策略时再部署一个calico,只让其部署网络策略,搭配起来使用,而不用第三方专门合好的插件
配置和使用flannel
flannel默认情况下是用的vxlan的方式来作为后端网络传输机制的。正常情况下,两个节点之间怎么通信呢?如果基于宿主机之间桥接直接通信那么他们应该就可以直接借助于物理网卡实现报文交换,但现在是我们要做成一个叠加网络,使得两边主机之上应该各自有一个专门用于叠加报文封装的隧道,通常称之为flannel.0,flannel.1之类的接口,他们的ip很独特,为10.244.0.0等等,掩码也很独特,为32位,是用来封装隧道协议报文的,并且可以看到我们物理网卡mtu为1500,而他的mtu为1450要留出来一部分,因为我们要做叠加隧道封装的话会有额外的开销,他把额外的开销给留出来了,但这些开销不是没有,这些报文额外的空间不是不被占用,而是被占用了留给我们隧道使用而已
: lo: <LOOPBACK,UP,LOWER_UP> mtu qdisc noqueue state UNKNOWN qlen
link/loopback ::::: brd :::::
inet 127.0.0.1/ scope host lo
valid_lft forever preferred_lft forever
inet6 ::/ scope host
valid_lft forever preferred_lft forever
: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu qdisc pfifo_fast state UP qlen
link/ether :0c::d1::be brd ff:ff:ff:ff:ff:ff
inet 192.168.10.10/ brd 192.168.10.255 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fed1:42be/ scope link
valid_lft forever preferred_lft forever
: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu qdisc noqueue state DOWN
link/ether ::e1:e8:: brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/ brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
: flannel.: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu qdisc noqueue state UNKNOWN
link/ether d2:fb:::bf:7f brd ff:ff:ff:ff:ff:ff
inet 10.244.0.0/ scope global flannel.
valid_lft forever preferred_lft forever
inet6 fe80::d0fb:97ff:fe81:bf7f/ scope link
valid_lft forever preferred_lft forever
: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu qdisc noqueue state UP qlen
link/ether 0a::0a:f4:: brd ff:ff:ff:ff:ff:ff
inet 10.244.0.1/ scope global cni0
valid_lft forever preferred_lft forever
inet6 fe80::a0f8:5eff:fe8c:cf44/ scope link
valid_lft forever preferred_lft forever
: veth3ae34d47@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu qdisc noqueue master cni0 state UP
link/ether 0a:c6:2d:::d0 brd ff:ff:ff:ff:ff:ff link-netnsid
inet6 fe80::8c6:2dff:fe90:68d0/ scope link
valid_lft forever preferred_lft forever
: veth5a6b0c93@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu qdisc noqueue master cni0 state UP
link/ether ee::5d::9e:dd brd ff:ff:ff:ff:ff:ff link-netnsid
inet6 fe80::ec91:5dff:fe55:9edd/ scope link
valid_lft forever preferred_lft forever
ip addr
另外还有cni的接口,对应在flannel.1之上对应有一个10.244.0.1的接口,被当前主机作为这个隧道协议上在本地通信时使用的接口,但只有创建完pod以后有容器运行以后这个接口才会出现,默认情况下可能只有flannel.1这个接口存在
基于此我们可以简单理解一下,正常情况下我们的网络两个接口直接我们是假设期望他们能直接通信的,但是他两之间无法直接通信,要借助于我们的隧道接口进行通信,比如我们称为叫flannel,这也就意味着在他两个之间我们要构建一个额外添加了开报文传输的一个传输通道,使得他两之间的通信借助这个传输通道来实现,就好像他在直接通信一样,这个后端通信我们所使用的功能就是flannel接口,每一次在这个通讯之外再封装一个二层或三层或四层的直接报文,默认情况下我们用的是VXLAN机制,承载外层的隧道我们用的是VXLAN(扩展的虚拟局域网)协议,其在实现报文通信时他是一种类似于四层隧道一样的协议,也就意外着我们正常传输一个以太网帧的时候他就能在链路层直接进行传输,那怎么传呢?当一个帧发过来的时候,他要经过这个隧道接口再格外封装一层报文守护。第一,他要封装一个VXLAN守护。第二、VXLAN守护之外是UDP协议守护,他们用UDP进行传输。第三、UDP协议之外才是IP守护。第四、IP之外又有一个以太网守护。所以这几种守护完全都是额外开销。所以基于VXLAN可能性能上会有点低,但是好处就在于我们在这里可以独立管理一个网络,而且彼此之间和物理网络是不相干扰的
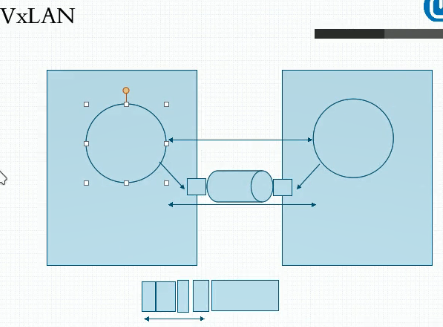
但是这只是我们对应的flannel网络的后端传输的第一种方式。所以flannel支持多种后端传输方式
1 VXLAN:如上所述
2 host-gw(Host Gateway):主机网关,一样的方式,我们有多个节点,每一个节点上都需要运行pod,因此对第一个节点和第二个节点上的pod大家各自有一个专有网段,但是我们把主机自己所在的这个网络接口当做是网关来使用,从而能给这些pod之间各自配一个ip地址并通过这个网关对外进行传递。我们在物理机上创建一个虚拟接口,然后我们每一个pod也有一个虚拟接口,这个虚拟接口在传输报文时不是通过隧道承载传递出去的,而是当其需要传输报文时一看目标主机不是本地的,他就应该把报文传给网关,即我们本地的专用虚拟接口,这个网关看到报文以后他会查我们本地的路由表,然后再经过物理网卡就发出去了,这个路由表中记录了到达哪个网络就跳到哪儿。假如主机一pod网络我们使用的是10.244.0.0/24,主机二pod网络使用的是10.244.1.0/24。所以假设我们主机一上的pod IP为10.244.0.2,主机二上的pod IP为10.244.1.2,当我们主机一pod发报文出去时发现对端主机是10.244.1.2,不在自己的网段内,然后就将报文送到网关,网关路由表记录了要到达10.244.1.0/24网络需要送给对端的物理网卡。所以这个报文他会通过本机的物理网卡直接传给主机二的物理网卡。主机二物理网卡一看这就是本机上的另外一个网卡(即这个虚拟接口),所以报文送给该接口,然后报文就到达了主机二了。通过这种方式就相当于是直接将节点当网关,不过这样的话主机的路由表会很大,假如是一个拥有三千节点的集群,大概至少要有三千个路由条目才行。这种比VXLAN方式性能好多了,因为几乎没有什么额外开销。但是其有一个缺陷就是要求各节点必须工作于同一个二层网络中。这样会使得同一个网段中主机非常多,万一发一个泛洪报文,因为彼此之间没有隔离所以每一个主机都有可能受到波及和影响。如果节点不在同一二层网络中就不能使用该模式。我们部署k8s集群所有主机没必要在同一网络中,我们有时候部署很大的k8s集群时中间是有路由器隔离的
但是我们又期望用这种高性能又期望各个节点又可以不在同一网段时要怎么办呢?其实他们还支持第二种方式,在VXLAN上也支持类似于host-gw这种模式,VXLAN还可以这样玩,如果说节点和节点之间通信时大家在同一个网络中,那么我们就直接使用host-gw的方式进行通信,因此我们不用隧道转发不用隧道承载,但是有些我们目标节点与当前节点,所谓当前pod所在的节点与目标pod所在的节点中间隔了路由设备的时候那么他就会自动转为VXLAN的方式使用叠加网络进行通信。这就是柔和了VXLAN和host-gw的一种解决方案。即VXLAN的Directrouting模式
UDP方式:即纯粹的UDP方式进行转发,这种方式比VXLAN性能更差,因为这是用普通的UDP报文转发的还不是用VXLAN专用的报文转发的。因此性能比前两种方式低很多很多,即前两种都不支持的情况下才使用。flannel刚刚被发明出来的时候linux内核尚且不支持VXLAN,linux内核没有VXLAN模块,而那时候host-gw又有很高的技术门槛,所以早期flannel就用的最差的方式UDP,因此大家产生了一种偏见认为flannel性能很差
flannel配置
接下来我们来改一改flannel用法,以及了解一下他的配置参数是怎么配置的,不过要注意的是我们要配置flannel的话,我们定义他使用VXLAN之类配置的话他的信息定义起来也是JSON格式的比较简单,我们要想使用VXLAN这种方式改为使用Directrouting,即能用直接路由就用不能用就用隧道进行转发的方式,这个时候我们需要自己定义flannel自己的configmap配置文件。大家可以发现flannel本身和k8s没有什么关系,他只是k8s的插件而已,都是第三方的,意思是说为了让k8s运行他事先都得存在才行。没有我们插件k8s没法跑起来,他要事先存在就很头疼。传统方式我们是将flannel部署在集群中
我们之前讲过部署k8s有两种传统方式,第一种方式为直接部署在节点上,使用systemctl来启动服务之类的,这种方式启动起来比较难。第二种方式为使用kubeadm把我们k8s自己的很多组件除了kubelete和docker以外都运行为pod,只不过他们作为k8s核心组件时都是运行为静态pod的,叫static pod。同样的逻辑,如果我们要把这些系统的组件部署为守护进程的话flannel一般也可以部署为系统的守护进程。因为他是被kubelet所调用的。因此但凡有kubelet的节点上都应该部署flannel,因为kubelet存在就应该运行pod,而pod就应该需要网络,而网络是kubelet调flannel或者其它网络插件来实现为网络做设置的
那么flannel自身是部署为系统级的守护进程还是部署在k8s之上的pod呢?两种方式都支持,只不过对第二种方式来讲我们必须把flannel配置为共享他所运行的节点的网络名称空间的pod,所以flannel自己的控制器如果作为pod来部署的话一定是一个demonset,一个节点上只运行一个pod副本,并且这个pod副本直接共享宿主机的网络名称空间,因为这样的pod才能设置宿主机的网络名称空间。 不然他就没法代为在pod中运行又能改宿主机的网络接口了。比如他创建一个cni,每一个pod启动时他要创建另外一段虚拟网卡,另外一半还要在虚拟机上,还能添加到某个桥上去,这个功能如果不能共享宿主机网络名称空间显然是做不到的,另外,如果我们把flannel托管运行在k8s之上作为pod运行的话他虽然是pod但相当于模拟运行了系统级的守护进程。而既然作为pod运行我们要配置它,配置pod应用我们可以使用configmap和secret,当我们使用kubeadm部署时我们的flannel自身也是托管运行在k8s上作为pod存在的
可以看到我们flannel是被配置为daemonset控制器的,因为我们集群中的节点数量为3因此运行了三个副本
kubectl get daemonset -n kube-system

我们配置flannel的时候用的是配置文件,可以看到默认使用的是VXLAN的形式。但是我们也可以使用VXLAN中的第二种形式叫Directrouting,我们去配置他的Backend时后面还有很多可以使用的配置参数
kubectl get configmap -n kube-system
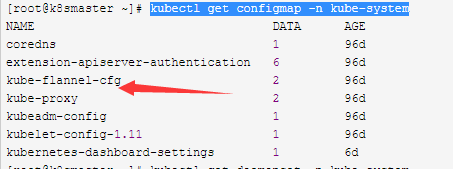
apiVersion: v1
data:
cni-conf.json: |
{
"name": "cbr0",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
kind: ConfigMap
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","data":{"cni-conf.json":"{\n \"name\": \"cbr0\",\n \"plugins\": [\n {\n \"type\": \"flannel\",\n \"delegate\": {\n \"hairpinMode\": true,\n
\"isDefaultGateway\": true\n }\n },\n {\n \"type\": \"portmap\",\n \"capabilities\": {\n \"portMappings\": true\n }\n }\n ]\n}\n","net-conf.json":"{\n \"Network\": \"10.244.0.0/16\",\n \"Backend\": {\n \"Type\": \"vxlan\"\n }\n}\n"},"kind":"ConfigMap","metadata":{"annotations":{},"labels":{"app":"flannel","tier":"node"},"name":"kube-flannel-cfg","namespace":"kube-system"}} creationTimestamp: --09T01::03Z
labels:
app: flannel
tier: node
name: kube-flannel-cfg
namespace: kube-system
resourceVersion: ""
selfLink: /api/v1/namespaces/kube-system/configmaps/kube-flannel-cfg
uid: 6378828a-71fa-11e9-be24-000c29d142be
kubectl get configmap kube-flannel-cfg -n kube-system -o yaml
flannel的配置参数:大体上来讲配置参数如下(上述json字符串中也可看到)
a、Network:flannel使用的CIDR格式的网络地址,用于为Pod配置网络功能。他通常会是全局的,他通常会是16位或8位掩码的,然后这个全局网络会划分成子网,每一个节点使用一个子网,比如他使用10.244.0.0/16,但是我们的节点1,节点2,节点3分别分一个子网,比如master:10.244.0.0/24。node01:10.244.1.0/24。...直到node255:10.244.255.0/24,不过这就意味着我们整个集群支持255个节点,想要更多的节点那就需要使用更大的网络,比如10.0.0.0/8,这样就能有10.0.0.0/24-10.255.255.0/24个节点。就可以有2的16次方,即65536个。因此我们一般不会用这么大的网段,比如我们可以使用16或12位掩码,最起码要留出来service使用的网络。比如service使用10.9.0.0/12,而pod使用10.10.0.0/12。
b、subnetLen:把Network切分子网供各节点使用时,使用多长的掩码进行切分,默认为24位。默认为什么是使用上述方式切子网呢?那是因为我们的子网默认使用24位掩码去切分子网。 留24位就意味着8位是可以当主机地址的,也就意味着将来在一个节点上可以同时运行两百多个Pod,如果我们运行不了那么多运行20个就够了那么我们的掩码可以再长一点,比如使用28位掩码,这样就能支持更多节点了。
c、SubnetMin:指明我们子网中的地址段中从最大最小是多少可以分给节点使用,默认就是从第一个开始,比如10/244.0.0/16中就是从10.244.0.0/24开始,10.244.255.0/24结束。但是我们可以限制,从10.244.10.0/24开始,前面10个不让其使用
d、SubnetMAx:同c中,指明最大可以以哪个网段结束,比如10.244.100.0/24,后面155个不让其使用。
e、Backend:指明各pod之间通信时使用什么样的方式来进行通信。有三种方式,vxlan,host-gw,udp。vxlan还有两种方式:默认的vxlan和Directrouting类型的VXLAN。
现在我们将默认的VXLAN配置为Directrouting类型的VXLAN
首先我们分别在两个节点上启动一个pod副本,用pod1 ping pod2并在node1 cni0接口进行抓包
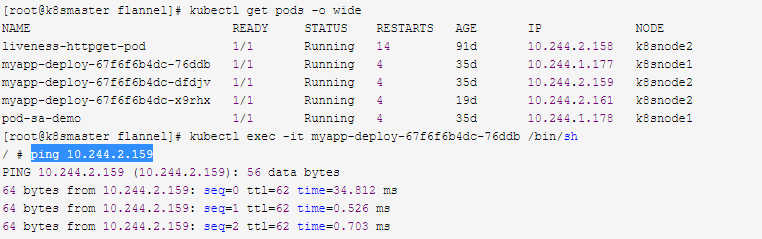
kubectl get pods -o wide

kubectl exec -it myapp-deploy-67f6f6b4dc-76ddb /bin/sh
ping 10.244.2.159

在node1 cni0 接口我们进行抓包
tcpdump -i cni0 -nn icmp
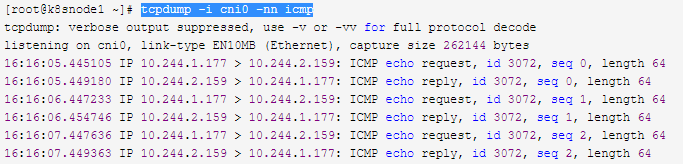
实际上这个报文被送达到flannel这个接口时他要先从cni0进来,从flannel.1出去,然后再借助于物理网卡发出去,到达flannel.1的时候就已经被封装为vxlan报文了,因此我们再来抓flannel.1接口的包
tcpdump -i flannel.1 -nn icmp
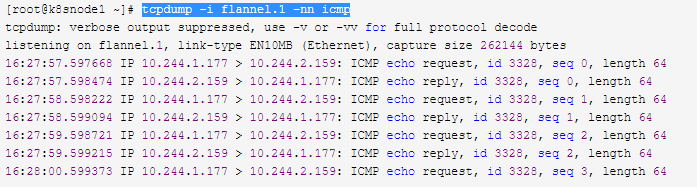
然后我们看我们node1物理网卡和node2之间通信的报文,可以看到有overlay的报文
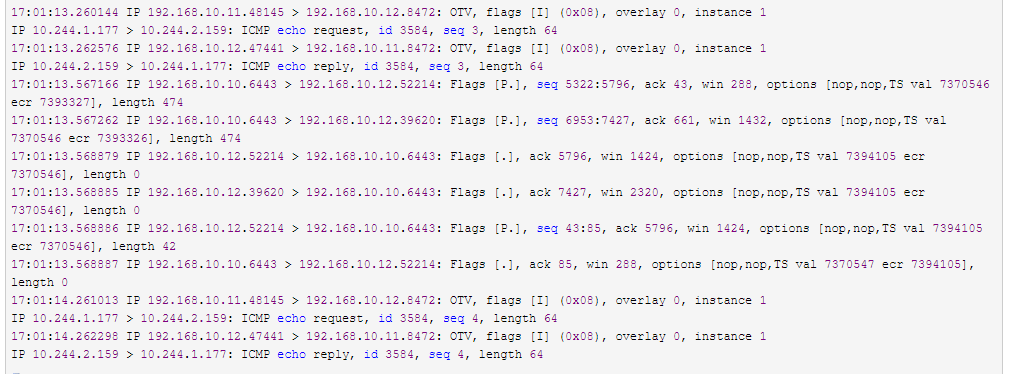
接下来我们把我们刚才用到的flannel的配置信息改成使用Directrouting的方式进行通信
- 我们首先定义一个json文件
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan",
"Directrouting": "true"
}
}
net-conf.jso
定义完成以后我们需要将它重新应用到集群中,怎么应用呢?这其实是我们configmap中的数据,所以我们需要把它定义成一个独立的configmap,或者是合并到flannel的kube-flannel-cfg 这个configmap中去,当然我们其实也可以直接使用kubectl edit的方式进行编辑,直接编辑配置中的net-conf.json的配置
apiVersion: v1
data:
cni-conf.json: |
{
"name": "cbr0",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
"Directrouting": true #此字段是添加字段 }
}
kind: ConfigMap
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","data":{"cni-conf.json":"{\n \"name\": \"cbr0\",\n \"plugins\": [\n {\n \"type\": \"flannel\",\n \"delegate\": {\n \"hairpinMode\": true,\n
\"isDefaultGateway\": true\n }\n },\n {\n \"type\": \"portmap\",\n \"capabilities\": {\n \"portMappings\": true\n }\n }\n ]\n}\n","net-conf.json":"{\n \"Network\": \"10.244.0.0/16\",\n \"Backend\": {\n \"Type\": \"vxlan\"\n }\n}\n"},"kind":"ConfigMap","metadata":{"annotations":{},"labels":{"app":"flannel","tier":"node"},"name":"kube-flannel-cfg","namespace":"kube-system"}} creationTimestamp: --09T01::03Z
labels:
app: flannel
tier: node
name: kube-flannel-cfg
namespace: kube-system
resourceVersion: ""
selfLink: /api/v1/namespaces/kube-system/configmaps/kube-flannel-cfg
uid: 6378828a-71fa-11e9-be24-000c29d142be
kubectl get configmap kube-flannel-cfg -n kube-system -o yaml
此时查看路由表没生效
ip route
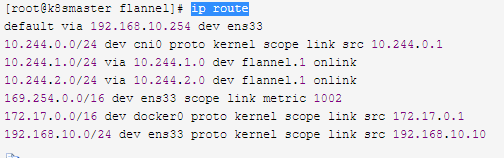
经验证直接edit是不会重载配置文件使生效的,因此我们必须重新部署flannel插件,注意,在生产环境中千万不要删掉然后重建,而需要在一开始部署集群的时候就要将flannel部署好
接下来我们开干,首先从flannel官网下载flannel配置文件并将文件中net-conf.json配置添加"Directrouting": true内容
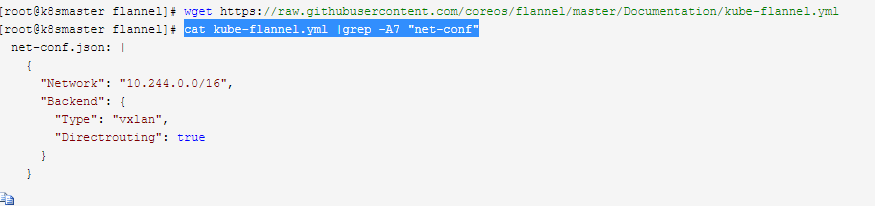
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
cat kube-flannel.yml |grep -A7 "net-conf"
然后我们先干掉flannel插件,注意我们干掉后我们所有的pod都运行不了了,因为没有网络插件因此我们系统节点是不就绪的
kubectl delete -f kube-flannel.yml
接下来我们重载我们修改好的flannel插件配置文件,然后查看路由表会发现我们pod之间通信直接会走物理网卡了
kubectl apply -f kube-flannel.yml
ip route

接下来我们开始验证,在node1中的pod ping node2中的pod,然后在node1的物理网卡上抓包
kubectl get pods -o wide
kubectl exec -it myapp-deploy-67f6f6b4dc-76ddb /bin/sh
ping 10.244.2.159
tcpdump -i ens33 -nn icmp

在物理接口上抓包可以看到并没有显示说二者是被overlay网络重载,和我们物理桥接是很想象的,所以我们flannel也能实现两个pod之间的桥接网络。这种通信性能肯定是很ok的,但是如果两个节点是跨网段的,他会自动降级为overlay
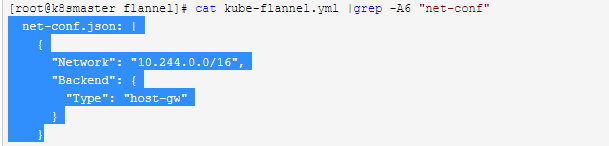
若我们将flannel的配置文件的net-conf.json中的Type内容改为host-gw时那它就是host-gw模式,host-gw是不支持Directrouting的,所以部署时将vxlan改为host-gw即可,不过host-gw各主机不能跨网段,跨网段是通信不了的
cat kube-flannel.yml |grep -A6 "net-conf"
kubernetes 配置网络插件 flannel的更多相关文章
- Kubernetes 学习18配置网络插件flannel
一.概述 1.我们在学习docker时知道docker有四种常用的网络模型 a.bridge:桥接式网络 b.joined:联盟式网络,共享使用另外一个容器的网络名称空间 b.opened:容器直接共 ...
- 3.kubernetes的CNI网络插件-Flannel
目录 1.1.K8S的CNI网络插件-Flannel 1.1.1.集群规划 1.1.2.下载软件.解压.软链接 1.1.3.最终目录结构 1.1.4.拷贝证书 1.1.5.创建配置 1.1.6.创建启 ...
- kubernetes进阶(二)核心网络插件Flannel
网络插件Flannel介绍:https://www.kubernetes.org.cn/3682.html 首先,flannel利用Kubernetes API或者etcd用于存储整个集群的网络配置, ...
- Kubernetes CNI网络插件
CNI 容器网络接口,就是在网络解决方案由网络插件提供,这些插件配置容器网络则通过CNI定义的接口来完成,也就是CNI定义的是容器运行环境与网络插件之间的接口规范.这个接口只关心容器的网络连接,在创建 ...
- 第十章 Kubernetes的CNI网络插件--flannel
1.简介 1.1前言 Kubernetes设计了网络模型,但却将它的实现讲给了网络插件,CNI网络插件最重要的功能就是实现Pod资源能够跨主机通信 常见的CNI网络插件如下: Flannel: Cac ...
- k8s之网络插件flannel及基于Calico的网络策略
1.k8s网络通信 a.容器间通信:同一个pod内的多个容器间的通信,通过lo即可实现; b.pod之间的通信:pod ip <---> pod ip,pod和pod之间不经过任何转换即可 ...
- k8s系列---网络插件flannel
跨节点通讯,需要通过NAT,即需要做源地址转换. k8s网络通信: 1) 容器间通信:同一个pod内的多个容器间的通信,通过lo即可实现: 2) pod之间的通信,pod ip <---> ...
- Kubernetes网络插件Flannel的三种工作模式
跨主机通信的一个解决方案是Flannel,由CoreOS推出,支持3种实现:UDP.VXLAN.host-gw 一.UDP模式(性能差) 核心就是通过TUN设备flannel0实现(TUN设备是工作在 ...
- Kubernetes(k8s)网络插件(CNI)的基准测试对比
Kubernetes是一个伟大的容器"乐队".但它不管理Pod-to-Pod通信的网络.这是容器网络接口(CNI)插件的使命,它是实现容器集群工具(Kubernetes,Mes ...
随机推荐
- electron---项目打包
创建一个应用目录:app,里面需要有必要的三个文件: index.html <!DOCTYPE html> <html> <head> <meta chars ...
- 泡泡一分钟:Tightly-Coupled Aided Inertial Navigation with Point and Plane Features
Tightly-Coupled Aided Inertial Navigation with Point and Plane Features 具有点和平面特征的紧密耦合辅助惯性导航 Yulin Ya ...
- 全基因组关联分析(GWAS)的计算原理
前言 关于全基因组关联分析(GWAS)原理的资料,网上有很多. 这也是我写了这么多GWAS的软件教程,却从来没有写过GWAS计算原理的原因. 恰巧之前微博上某位小可爱提问能否写一下GWAS的计算原理. ...
- 监听微信、支付宝等移动app及浏览器的返回、后退、上一页按钮的事件方法
在实际的应用中,我们常常需要实现在移动app和浏览器中点击返回.后退.上一页等按钮实现自己的关闭页面.调整到指定页面或执行一些其它操作的 需求,那在代码中怎样监听当点击微信.支付宝.百度糯米.百度钱包 ...
- [LeetCode] 358. Rearrange String k Distance Apart 按距离k间隔重排字符串
Given a non-empty string str and an integer k, rearrange the string such that the same characters ar ...
- 从一个案例窥探ORACLE的PASSWORD_VERSIONS
1.环境说明 ORACLE 客户端版本 11.2.0.1 ORACLE 服务端版本 12.2.0.1 2.异常现象 客户端(下文也称为Cp)访问服务端(Sp),报了一个错误: Figure 1 以错误 ...
- 12 Spring JdbcTemplate的使用
1.项目搭建 <1>数据库表account对应的账户实体类 package domain; import java.io.Serializable; /** * 账户实体类 */ publ ...
- 19 Maven---项目管理工具
1.Maven概念 Maven 的正确发音是[ˈmevən].Maven 在美国是一个口语化的词语,代表专家.内行的意思. 一个对 Maven 比较正式的定义是这么说的:Maven 是一个项目管理工 ...
- [HAOI2008]硬币购物-题解
传送门 解答 根据容斥原理 \[ \left|\bigcap_{i=1}^n \overline{S_i}\right| = |U| - \left|\bigcup_{i=1}^n S_i\right ...
- 【Centos】Centos7.5取消自动锁屏功能
目录 00. 目录 01. 问题描述 02. 问题分析 03. 解决办法 04. 附录 00. 目录 @ 参考博客:[Centos]Centos7.5取消自动锁屏功能 01. 问题描述 Centos7 ...