33、shuffle性能优化
一、shuffle性能优化
1、没有开启consolidation机制的性能低下的原理剖析
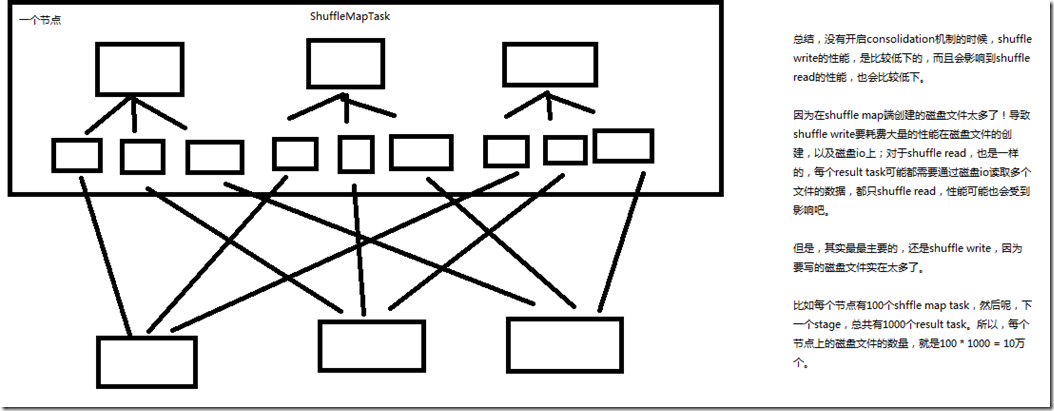
2、开启consolidation机制之后对磁盘io性能的提升的原理
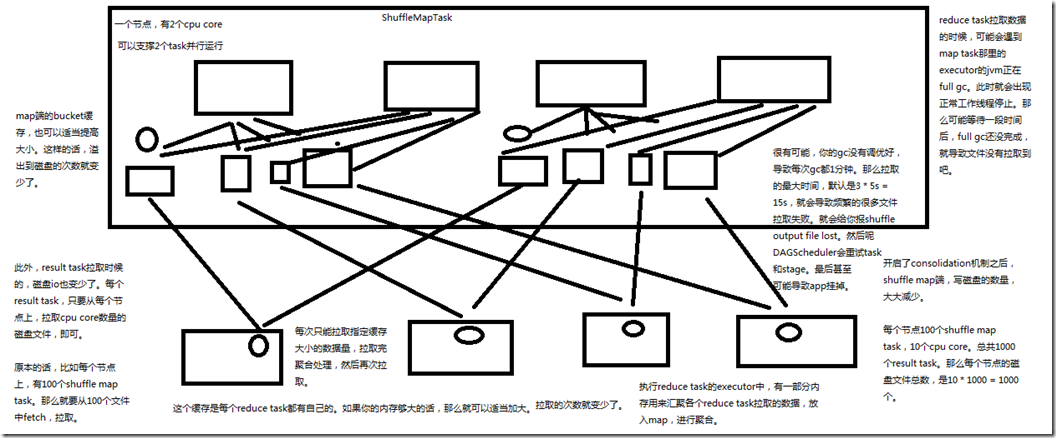
spark.shuffle.consolidateFiles:是否开启shuffle block file的合并,默认为false; 总结,开启了consolidation机制之后,shuffle map端,写磁盘的数量,大大减少; 比如节点100个shuffle map task ,10个cpu core,总共1000个result task,那么每个节点的磁盘文件总数,是10 * 1000 = 1万个; 此外,result task拉取的时候,磁盘io也变少了,每个result task,只要从每个节点上,拉取cpu core数量的磁盘文件即可; 比如,每个节点上,有100个shuffle map task,那么就要从100个文件中fetch,拉取,现在只需要从10个文件中fetch,拉取; map端的bucket缓存,也可以适当提高大小,这样,溢出到磁盘的次数就变少了; spark.shuffle.file.buffer:map task的写磁盘缓存,默认32k; 每次只能拉取指定缓存大小的数据量,拉取完聚合处理,然后再次拉取,这个缓存是每个reduce task都有自己的,如果内存够大的话,那么可以适当加大,
那么拉取的次数就变少了,spark.reducer.maxSizeInFlight:reduce task的拉取缓存,默认48m; 执行reduce task的executor中,有一部分内存用来汇聚各个reduce task 拉取的数据,放入map,进行聚合,spark.shuffle.memoryFraction:用于reduce端聚合的内存比例,
默认0.2,超过比例就会溢出到磁盘上; reduce task 拉取数据的时候,可能会遇到map task哪里的executor的jvm正在full gc,此时就会出现正常工作线程停止,那么可能等待一段时间后,full gc还没完成,
就导致文件没有拉取到,spark.shuffle.io.maxRetries:拉取失败的最大重试次数,默认3次; 很有可能,gc没有调优好,导致每次gc都1分钟,那么拉取的最大时间,默认是3 * 5 = 15s,就会导致频繁的很多文件拉取失败,就会给你报shuffle output file lost,
然后,DAGScheduler会重试task和stage,最后甚至可能导致Application挂掉,spark.shuffle.io.retryWait:拉取失败的重试间隔,默认5s;
3、调优参数总结
new SparkConf().set("spark.shuffle.consolidateFiles", "true")
spark.shuffle.consolidateFiles:是否开启shuffle block file的合并,默认为false
spark.reducer.maxSizeInFlight:reduce task的拉取缓存,默认48m
spark.shuffle.file.buffer:map task的写磁盘缓存,默认32k
spark.shuffle.io.maxRetries:拉取失败的最大重试次数,默认3次
spark.shuffle.io.retryWait:拉取失败的重试间隔,默认5s
spark.shuffle.memoryFraction:用于reduce端聚合的内存比例,默认0.2,超过比例就会溢出到磁盘上
33、shuffle性能优化的更多相关文章
- Spark记录-Spark性能优化(开发、资源、数据、shuffle)
开发调优篇 原则一:避免创建重复的RDD 通常来说,我们在开发一个Spark作业时,首先是基于某个数据源(比如Hive表或HDFS文件)创建一个初始的RDD:接着对这个RDD执行某个算子操作,然后得到 ...
- Spark性能优化(1)——序列化、内存、并行度、数据存储格式、Shuffle
序列化 背景: 在以下过程中,需要对数据进行序列化: shuffling data时需要通过网络传输数据 RDD序列化到磁盘时 性能优化点: Spark默认的序列化类型是Java序列化.Java序列化 ...
- Spark性能优化——和shuffle搏斗
Spark的性能分析和调优很有意思,今天再写一篇.主要话题是shuffle,当然也牵涉一些其他代码上的小把戏. 以前写过一篇文章,比较了几种不同场景的性能优化,包括portal的性能优化,web se ...
- Spark性能优化指南-高级篇(spark shuffle)
Spark性能优化指南-高级篇(spark shuffle) 非常好的讲解
- 《Spark大数据处理:技术、应用与性能优化 》
基本信息 作者: 高彦杰 丛书名:大数据技术丛书 出版社:机械工业出版社 ISBN:9787111483861 上架时间:2014-11-5 出版日期:2014 年11月 开本:16开 页码:255 ...
- 《Spark大数据处理:技术、应用与性能优化》【PDF】 下载
内容简介 <Spark大数据处理:技术.应用与性能优化>根据最新技术版本,系统.全面.详细讲解Spark的各项功能使用.原理机制.技术细节.应用方法.性能优化,以及BDAS生态系统的相关技 ...
- 《Spark大数据处理:技术、应用与性能优化》【PDF】
内容简介 <Spark大数据处理:技术.应用与性能优化>根据最新技术版本,系统.全面.详细讲解Spark的各项功能使用.原理机制.技术细节.应用方法.性能优化,以及BDAS生态系统的相关技 ...
- 【大数据】Spark性能优化和故障处理
第一章 Spark 性能调优 1.1 常规性能调优 1.1.1 常规性能调优一:最优资源配置 Spark性能调优的第一步,就是为任务分配更多的资源,在一定范围内,增加资源的分配与性能的提升是成正比的, ...
- spark 性能优化 数据倾斜 故障排除
版本:V2.0 第一章 Spark 性能调优 1.1 常规性能调优 1.1.1 常规性能调优一:最优资源配置 Spark性能调优的第一步,就是为任务分配更多的资源,在一定范围 ...
随机推荐
- Unity3D 跨平台原理
Unity3D的跨平台原理核心在于对指令集CIL(通用中间语言)的应用. 机理 首先需要知道,Unity中的Mono是基于 通用语言架构(Common Language Infrastructure, ...
- Bean进行操作的相关工具方法
Bean进行操作的相关工具方法 /** * <html> * <body> * <P> Copyright 1994 JsonInternational</p ...
- 广州CBC2019
CBC2019-day1 25 August 2019 on 学术前沿huyujia 8月24日上午,CBC2019正式开幕.主持人首先对大会情况以及与会嘉宾做了简要介绍:紧接着,校领导.大会主席以及 ...
- CSS 各种形状
制作圆形: 要使用CSS来制作一个圆形,我们需要一个div,被给它设置一个ID <div id="circle"></div> 圆形在设置CSS时要设置宽 ...
- BUAA OO 2019 第四单元作业总结
目录 第四单元总结 总 UML UML 类图 UML 时序图 UML 状态图 架构设计 第十三次作业 第十四次作业 课程总结 历次作业总结 架构设计 面向对象方法理解 测试方法理解与实践 改进建议 尽 ...
- UCOSIII事件标志组
两种同步机制 "或"同步 "与"同步 使能 #define OS_CFG_FLAG_EN 1u /* Enable (1) or Disable (0) cod ...
- UCOSIII软件定时器
API函数 //创建 void OSTmrCreate (OS_TMR *p_tmr, CPU_CHAR *p_name, OS_TICK dly, OS_TICK period, OS_OPT op ...
- Linux多IP配置
# ifconfig eth0:1 172.168.1.222
- 笔谈OpenGL ES(二)
昨晚回家也看了OpenGL ES 2.0 iOS教程的第一篇,对于其中涉及的一些基本知识罗列下,虽然自己做iOS开发一年多了,但是对于一些细节没有注意,真正的把自己当成“应用”工程师了 ,不仅要会用, ...
- Python sorted 函数用法
1.背景 在python中,通常需要使用排序函数.而对字典针对一个键值进行排序会经常使用到.记录sorted 函数的键值排序用法. 2.代码 data 一个list,list 中的元素由字典组成 ...