storm杂记+性能调优
1、默认情况下:
1个supervisor节点启动4个worker进程。
每一个topology默认占用一个worker进程。
每个worker会启动executor。
每个executor默认启动一个task。
2、并行度
什么是并行度?在 Storm 的设定里,并行度大体分为3个方面:
- 一个 topology 指定多少个 worker 进程并行运行;
- 一个 worker 进程指定多少个 executor 线程并行运行;
- 一个 executor 线程指定多少个 task 并行运行。
一般来说,并行度设置越高,topology 运行的效率就越高,但是也不能一股脑地给出一个很高的值,还得考虑给每个 worker 分配的内存的大小,还得平衡系统的硬件资源,以避免浪费。
Storm 集群可以运行一个或多个 topology,而每个 topology 包含一个或多个 worker 进程,每个 worer 进程可派生一个或多个 executor 线程,而每个 executor 线程则派生一个或多个 task,task 是实际的数据处理单元,也是 Storm 概念里最小的工作单元, spout 或 bolt 的实例便是由 task 承载。
3、ACK/Fail
上文说到,Storm 保证了数据不会丢失,ack/fail 机制便是实现此机制的法宝。Storm 在内部构建了一个 tuple tree 来表示每一个 tuple 的流向,当一个 tuple 被 spout 发射给下游 bolt 时,默认会带上一个 messageId,可以由代码指定但默认是自动生成的,当下游的 bolt 成功处理 tuple 后,会通过 acker 进程通知 spout 调用 ack 方法,当处理超时或处理失败,则会调用 fail 方法。当 fail 方法被调用,消息可能被重发,具体取决于重发策略的配置,和所使用的 spout。
对于一个消息,Storm 提出了『完全处理』的概念。即一个消息是否被完全处理,取决于这个消息是否被 tuple tree 里的每一个 bolt 完全处理,当 tuple tree 中的所有 bolt 都完全处理了这条消息后,才会通知 acker 进程并调用该消息的原始发射 spout 的 ack 方法,否则会调用 fail 方法。
ack/fail 只能由创建该 tuple 的 task 所承载的 spout 触发
默认情况下,Storm 会在每个 worker 进程里面启动1个 acker 线程,以为 spout/bolt 提供 ack/fail 服务,该线程通常不太耗费资源,因此也无须配置过多,大多数情况下1个就足够了。
4、work通信
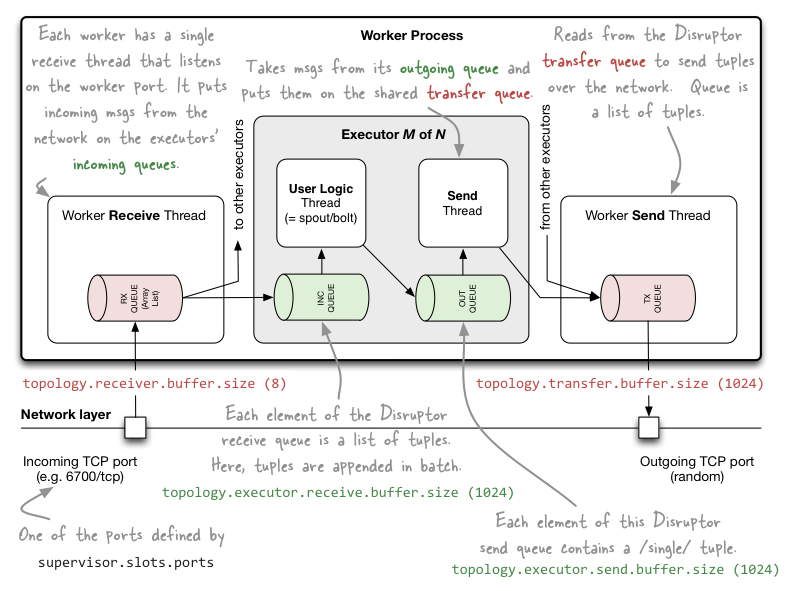
一个 worker 进程装配了如下几个元件:
- 一个 receive 线程,该线程维护了一个 ArrayList,负责接收其他 worker 的 sent 线程发送过来的数据,并将数据存储到 ArrayList 中。数据首先存入 receive 线程的一个缓冲区,可通过 topology.receiver.buffer.size (此项配置在 Storm 1.0 版本以后被删除了)来配置该缓冲区存储消息的最大数量,默认为8(个数,并且得是2的倍数),然后才被推送到 ArrayList 中。receive 线程接收数据,是通过监听 TCP的端口,该端口有 storm 配置文件中 supervisor.slots.prots 来配置,比如 6700;
- 一个 sent 线程,该线程维护了一个消息队列,负责将队里中的消息发送给其他 worker 的 receive 线程。同样具有缓冲区,可通过 topology.transfer.buffer.size 来配置缓冲区存储消息的最大数量,默认为1024(个数,并且得是2的倍数)。当消息达到此阈值时,便会被发送到 receive 线程中。sent 线程发送数据,是通过一个随机分配的TCP端口来进行的。
- 一个或多个 executor 线程。executor 内部同样拥有一个 receive buffer 和一个 sent buffer,其中 receive buffer 接收来自 receive 线程的的数据,sent buffer 向 sent 线程发送数据;而 task 线程则介于 receive buffer 和 sent buffer 之间。receive buffer 的大小可通过 Conf.TOPOLOGY_EXECUTOR_RECEIVE_BUFFER_SIZE 参数配置,sent buffer 的大小可通过 Config.TOPOLOGY_EXECUTOR_SEND_BUFFER_SIZE 配置,两个参数默认都是 1024(个数,并且得是2的倍数)。
5、性能调优
合理的配置并行度
有几个手段可以配置 topology 的并行度:
- conf.setNumWorkers() 配置 worker 的数量
- builder.setBolt("NAME", new Bolt(), 并行度) 设置 executor 数量
- spout/bolt.setNumTask() 设置 spout/bolt 的 task 数量
那么问题是:
- setNumWorkers 应该取多少?取决于哪些因素?
- kafkaSpout 的并行度应该取多少?取决于哪些因素?
- FilterBolt 的并行度应该取多少?取决于哪些因素?
- AlertBolt 的并行度应该取多少?取决于哪些因素?
- FilterBolt 用 shuffleGrouping 是最好的吗?
- AlertBolt 用 fieldsGrouping 是最好的吗?
回答如下:
第一个问题:关于 worker 的并行度:worker 可以分配到不同的 supervisor 节点,这也是 Storm 实现多节点并行计算的主要配置手段。据此, workers 的数量,可以说是越多越好,但也不能造成浪费,而且也要看硬件资源是否足够。所以主要考虑集群各节点的内存情况:默认情况下,一个 worker 分配 768M 的内存,外加 64M 给 logwriter 进程;因此一个 worker 会耗费 832M 内存;题设的集群有3个节点,每个节点4G内存,除去 linux 系统、kafka、zookeeper 等的消耗,保守估计仅有2G内存可用来运行 topology,由此可知,当集群只有一个 topology 在运行的情况下,最多可以配置6个 worker。
另外,我们还可以调节 worker 的内存空间。这取决于流过 topology 的数据量的大小以及各 bolt 单元的业务代码的执行时间。如果数据量特别大,代码执行时间较长,那么可以考虑增加单个 worker 的工作内存。有一点需要注意的是,一个 worker 下的所有 executor 和 task 都是共享这个 worker 的内存的,也就是假如一个 worker 分配了 768M 内存,3个 executor,6个 task,那么这个 3 executor 和 6 task 其实是共用这 768M 内存的,但是好处是可以充分利用多核 CPU 的运算性能。
总结起来,worker 的数量,取值因素有:
- 节点数量,及其内存容量
- 数据量的大小和代码执行时间
机器的CPU、带宽、磁盘性能等也会对 Storm 性能有影响,但是这些外在因素一般不影响 worker 数量的决策。
需要注意的是,Storm 在默认情况下,每个 supervisor 节点只允许最多4个 worker(slot)进程运行;如果所配置的 worker 数量超过这个限制,则需要在 storm 配置文件中修改。
第二个问题:关于 FilterBolt 的并行度:如果 spout 读取的是 kafka 的数据,那么正常情况下,设置为 topic 的分区数量即可。计算 kafkaSpout 的最佳取值,有一个最简单的办法,就是在 Storm UI里面,点开 topology 的首页,在 Spouts (All time) 下,查看以下几个参数的值:
- Emitted 已发射出去的tuple数
- Transferred 已转移到下一个bolt的tuple数
- Complete latency (ms) 每个tuple在tuple tree中完全处理所花费的平均时间
- Acked 成功处理的tuple数
- Failed 处理失败或超时的tuple数

怎么看这几个参数呢?有几个技巧:
- 正常情况下 Failed 值为0,如果不为0,考虑增加该 spout 的并行度。这是最重要的一个判断依据;
- 正常情况下,Emitted、Transferred和Acked这三个值应该是相等或大致相等的,如果相差太远,要么该 spout 负载太重,要么下游负载过重,需要调节该 spout 的并行度,或下游 bolt 的并行度;
- Complete latency (ms) 时间,如果很长,十秒以上就已经算很长的了。当然具体时间取决于代码逻辑,bolt 的结构,机器的性能等。
kafka 只能保证同一分区下消息的顺序性,当 spout 配置了多个 executor 的时候,不同分区的消息会均匀的分发到不同的 executor 上消费,那么消息的整体顺序性就难以保证了,除非将 spout 并行度设为 1
第三个问题:关于 FilterBolt 的并行度:其取值也有一个简单办法,就是在 Storm UI里面,点开 topology 的首页,在 Bolts (All time) 下,查看以下几个参数的值:
- Capacity (last 10m) 取值越小越好,当接近1的时候,说明负载很严重,需要增加并行度,正常是在 0.0x 到 0.1 0.2 左右
- Process latency (ms) 单个 tuple 的平均处理时间,越小越好,正常也是 0.0x 级别;如果很大,可以考虑增加并行度,但主要以 Capacity 为准

一般情况下,按照该 bolt 的代码时间复杂度,设置一个 spout 并行度的 1-3倍即可。
第四个问题:AlertBolt 的并行度同 FilterBolt。
第五个问题:shuffleGrouping 会将 tuple 均匀地随机分发给下游 bolt,一般情况下用它就是最好的了。
总之,要找出并行度的最佳取值,主要结合 Storm UI 来做决策。
优化配置参数:
- /** tuple发送失败重试策略,一般情况下不需要调整 */
- spoutConfig.retryInitialDelayMs = 0;
- spoutConfig.retryDelayMultiplier = 1.0;
- spoutConfig.retryDelayMaxMs = 60 * 1000;
- /** 此参数比较重要,可适当调大一点 */
- /** 通常情况下 spout 的发射速度会快于下游的 bolt 的消费速度,当下游的 bolt 还有 TOPOLOGY_MAX_SPOUT_PENDING 个 tuple 没有消费完时,spout 会停下来等待,该配置作用于 spout 的每个 task。 */
- conf.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 10000)
- /** 调整分配给每个 worker 的内存,关于内存的调节,上文已有描述 */
- conf.put(Config.WORKER_HEAP_MEMORY_MB, 768);
- conf.put(Config.TOPOLOGY_WORKER_MAX_HEAP_SIZE_MB, 768);
- /** 调整 worker 间通信相关的缓冲参数,以下是一种推荐的配置 */
- conf.put(Config.TOPOLOGY_RECEIVER_BUFFER_SIZE, 8); // 1.0 以上已移除
- conf.put(Config.TOPOLOGY_TRANSFER_BUFFER_SIZE, 32);
- conf.put(Config.TOPOLOGY_EXECUTOR_RECEIVE_BUFFER_SIZE, 16384);
- conf.put(Config.TOPOLOGY_EXECUTOR_SEND_BUFFER_SIZE, 16384);
6、rebalance
可以直接采用 rebalance 命令(也可以在 Storm UI上操作)重新配置 topology 的并行度:
storm rebalance TOPOLOGY-NAME -n 5 -e SPOUT/BOLT1-NAME=3 -e SPOUT/BOLT2-NAME=10
7、GC参数优化:
可以对每个worker的java内存参数进行调整,配置在conf/storm.yaml文件中,
可以通过在Strom的配置文件storm.yaml中设置worker的启动参数:
worker.childopts: "-Xmx2048m"
该参数会在启动时传递给JVM,然后就可以在worker中使用2048m内存了。
一个比较简单的启用CMS的GC配置可以为:

也可以在worker.childopts的参数中加入打印GC的日志进行GC性能的优化。
-XX:+PrintGCDetails -Xloggc:d:\gc.log
8、其他建议
1、优先使用localOrShuffleGrouping
2、注意fieldsGrouping 的数据均衡性
3、KafkaBolt批量提交
4、使用组件的并行度代替线程池
5、kryo序列化
storm杂记+性能调优的更多相关文章
- Spark性能调优之资源分配
Spark性能调优之资源分配 性能优化王道就是给更多资源!机器更多了,CPU更多了,内存更多了,性能和速度上的提升,是显而易见的.基本上,在一定范围之内,增加资源与性能的提升,是成正比的:写完了 ...
- JVM性能调优监控工具专题一:JVM自带性能调优工具(jps,jstack,jmap,jhat,jstat,hprof)
性能分析工具jstatjmapjhatjstack 前提概要: JDK本身提供了很多方便的JVM性能调优监控工具,除了集成式的VisualVM和jConsole外,还有jps.jsta ...
- Kafka性能调优 - Kafka优化的方法
今天,我们将讨论Kafka Performance Tuning.在本文“Kafka性能调优”中,我们将描述在设置集群配置时需要注意的配置.此外,我们将讨论Tuning Kafka Producers ...
- web前端性能调优
最近2个月一直在做手机端和电视端开发,开发的过程遇到过各种坑.弄到快元旦了,终于把上线了.2个月干下来满满的的辛苦,没有那么忙了自己准备把前端的性能调优总结以下,以方便以后自己再次使用到的时候得于得心 ...
- [网站性能2]Asp.net平台下网站性能调优的实战方案
文章来源:http://www.cnblogs.com/dingjie08/archive/2009/11/10/1599929.html 前言 最近帮朋友运营的平台进行了性能调优,效果还不错, ...
- Asp.net平台下网站性能调优的实战方案(转)
转载地址:http://www.cnblogs.com/chenkai/archive/2009/11/07/1597795.html 前言 最近帮朋友运营的平台进行了性能调优,效果还不错,所以写出来 ...
- 第0/24周 SQL Server 性能调优培训引言
大家好,这是我在博客园写的第一篇博文,之所以要开这个博客,是我对MS SQL技术学习的一个兴趣记录. 作为计算机专业毕业的人,自己对技术的掌握总是觉得很肤浅,博而不专,到现在我才发现自己的兴趣所在,于 ...
- sqlserver性能调优第一步
相信不少的朋友,无论是做开发.架构的,还是DBA等,都经常听说“调优”这个词.说起“调优”,可能会让很多技术人员心头激情澎湃,也可能会让很多人感觉苦恼,不知道如何入手.当然,也有很多人对此不屑一顾,因 ...
- JavaScript:内存泄露、性能调优
1.在进行JS内存泄露检查之前,先要了解JS的内存管理: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Memory_Manageme ...
随机推荐
- Postgresql中无则插入的使用方法INSERT INTO WHERE NOT EXISTS
一.问题 Postgresql中无则插入的使用方法INSERT INTO WHERE NOT EXISTS,用法请参考样例. 二.解决方案 (1)PostgresSQL INSERT INTO tes ...
- VMware 12 下载+专业版永久序列号
VMware 12 下载 VMware 12 下载(百度网盘) 链接:https://pan.baidu.com/s/1VvRmjf1yZ2zprQUzuVKRkA 密码:dvpr VMwar ...
- vue-cli随机生成port源码
const portfinder = require('portfinder'): const port = await portfinder.getPortPromise(): 两行代码 端口搜索范 ...
- Mysql-修改用户连接数据库IP地址和用户名
将用户连接数据库(5.7.14-7)的IP地址从 10.10.5.16 修改为 10.11.4.197 Mysql> rename user 'username'@'10.10.5.16' ...
- youtube-dll工具使用,很好用!!
最近喜欢上youtube-dll这个插件,下载东西真的很好用,墙裂推荐,github地址如下 https://github.com/ytdl-org/youtube-dl 安装 1.Linux 1.1 ...
- mds0: Many clients (191) failing to respond to cache pressure
目录 背景 后续的努力 临时的解决办法 cephfs时我们产品依赖的主要分布式操作系统,但似乎很不给面子,压力测试的时候经常出问题. 背景 集群环境出现的问题: mds0: Many clients ...
- 04、rpm+yum+tar解压
Linux 下安装软件: 1.rpm 软件包的安装 一般安装都用 rpm -ivh 包路径及名字 如:rpm -ivh /soft/RealPlayer11GOLD.rpm --安装/soft下 ...
- sftp常用命令
help 查看sftp支持哪些命令 ls 查看当前目录下文件 cd 指定目录 lcd 更改和/或打印本地工作目录 pwd 查看当前目录 lpwd 打印本地工作目录 get xxx.txt 下载xxx ...
- 大数据技术原理与应用:【第二讲】大数据处理架构Hadoop
2.1 Hadoop概论 创始人:Doug Cutting 1.简介: 开源免费; 操作简单,极大降低使用的复杂性; Hadoop是Java开发的; 在Hadoop上开发应用支持多种编程语言.不限于J ...
- 为 Jupyter Notebook指定虚拟环境的 Python 解释器
说明:本机系统为 win10 64 位, base 是集成于 Anaconda3 的 64 位的python,以下是创建虚拟环境 py366-32,安装 3.6.6 版的 32 为python,把 3 ...