elasticsearch 分片的创建 集群重启分片运作
Here are some great slides from our Core Elasticsearch: Operations course that help explain the concept. We'd recommend that you take the full course to understand this even better, but I'll provide an overview from our training here:
Shard allocation is the process of allocating shards to nodes. This can happen during initial recovery, replica allocation, rebalancing, or when nodes are added or removed. Most of the time, you don't need to think about it, this work is done by Elasticsearch in the background. If you've ever found yourself curious about these particulars, this blog will explore shard allocation in several different scenarios.
This is our 4 node cluster, it's what we'll use for the examples within our content:
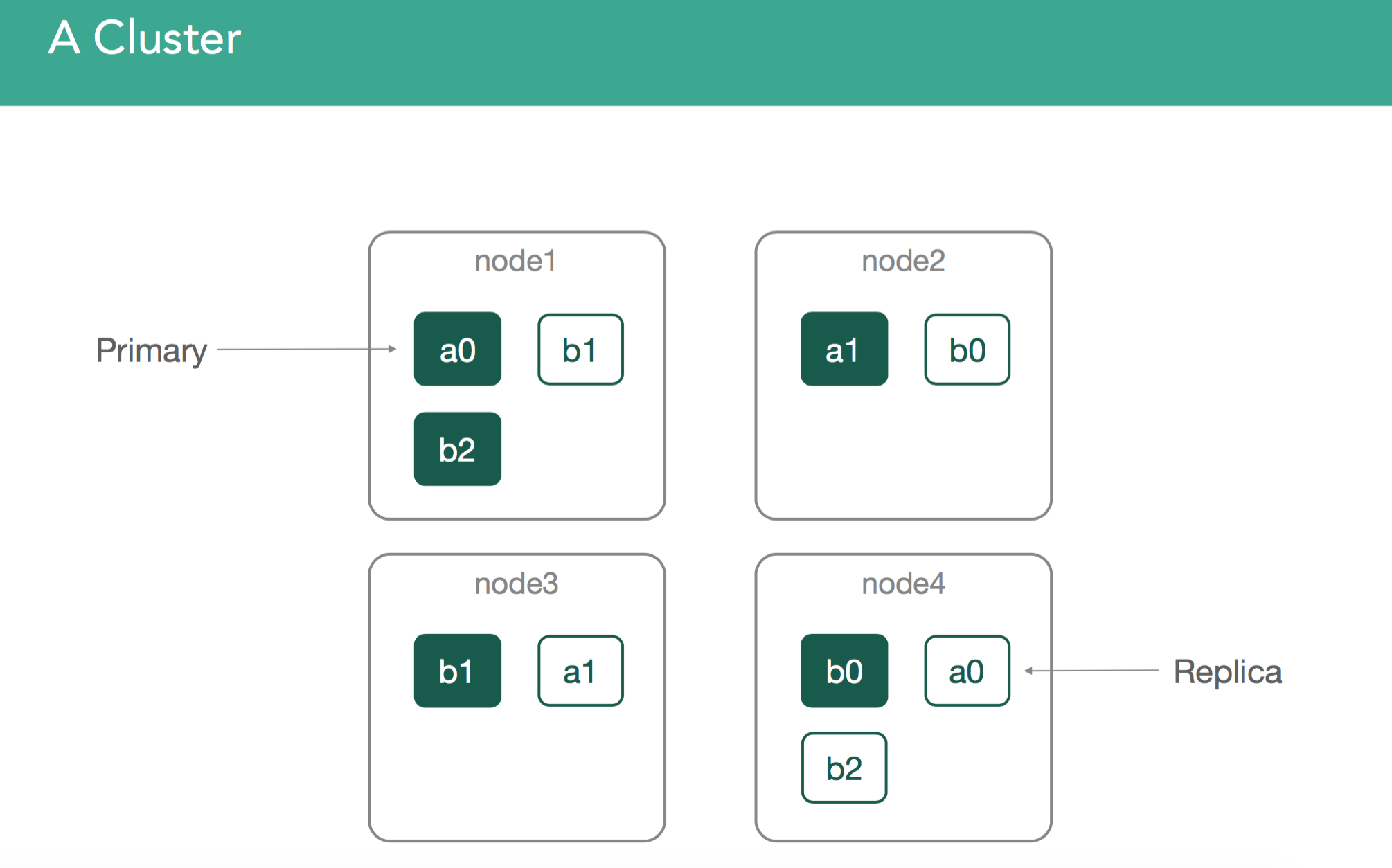
We'll cover several different scenarios.
Scenario 1. Index creation
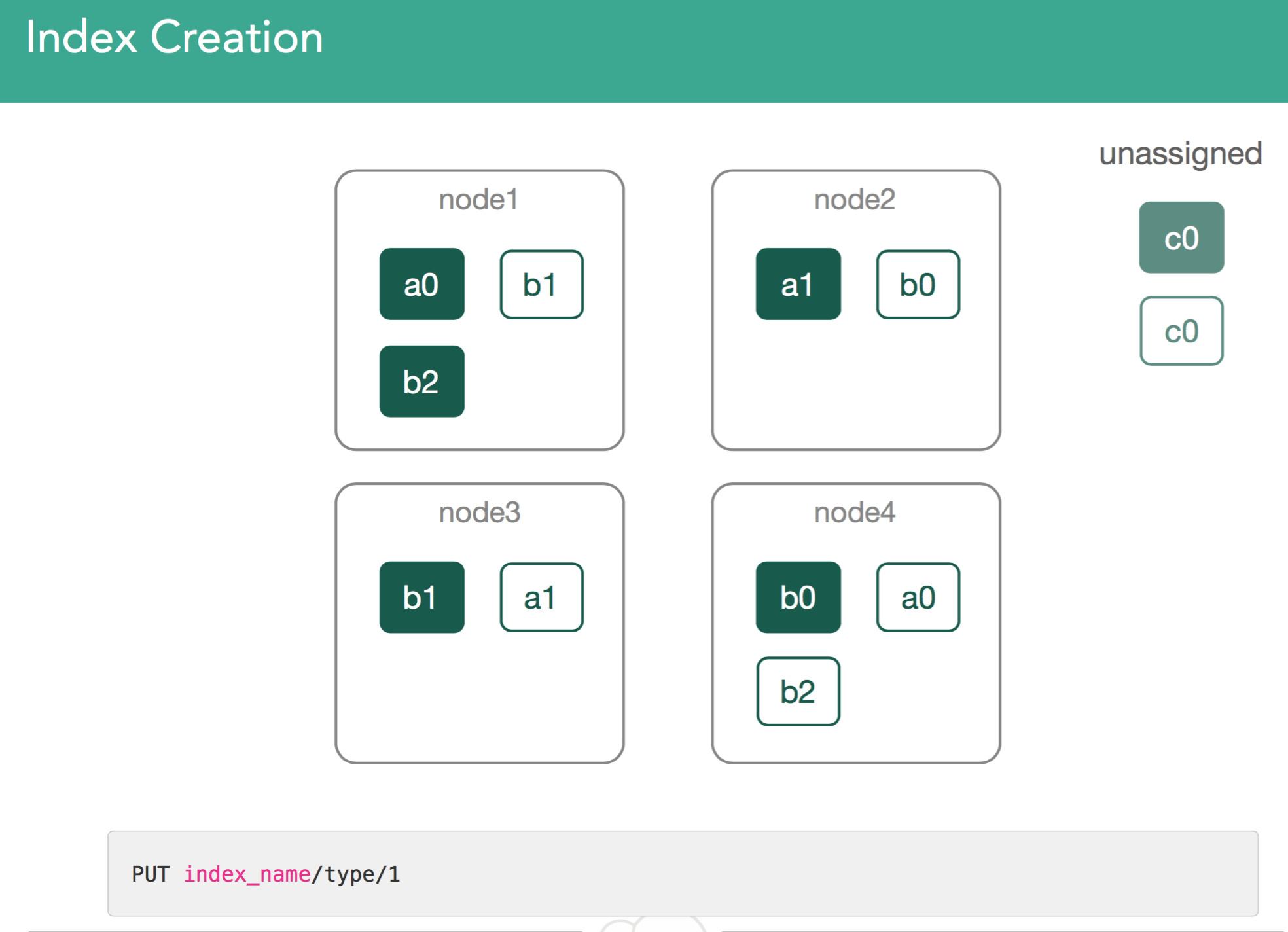
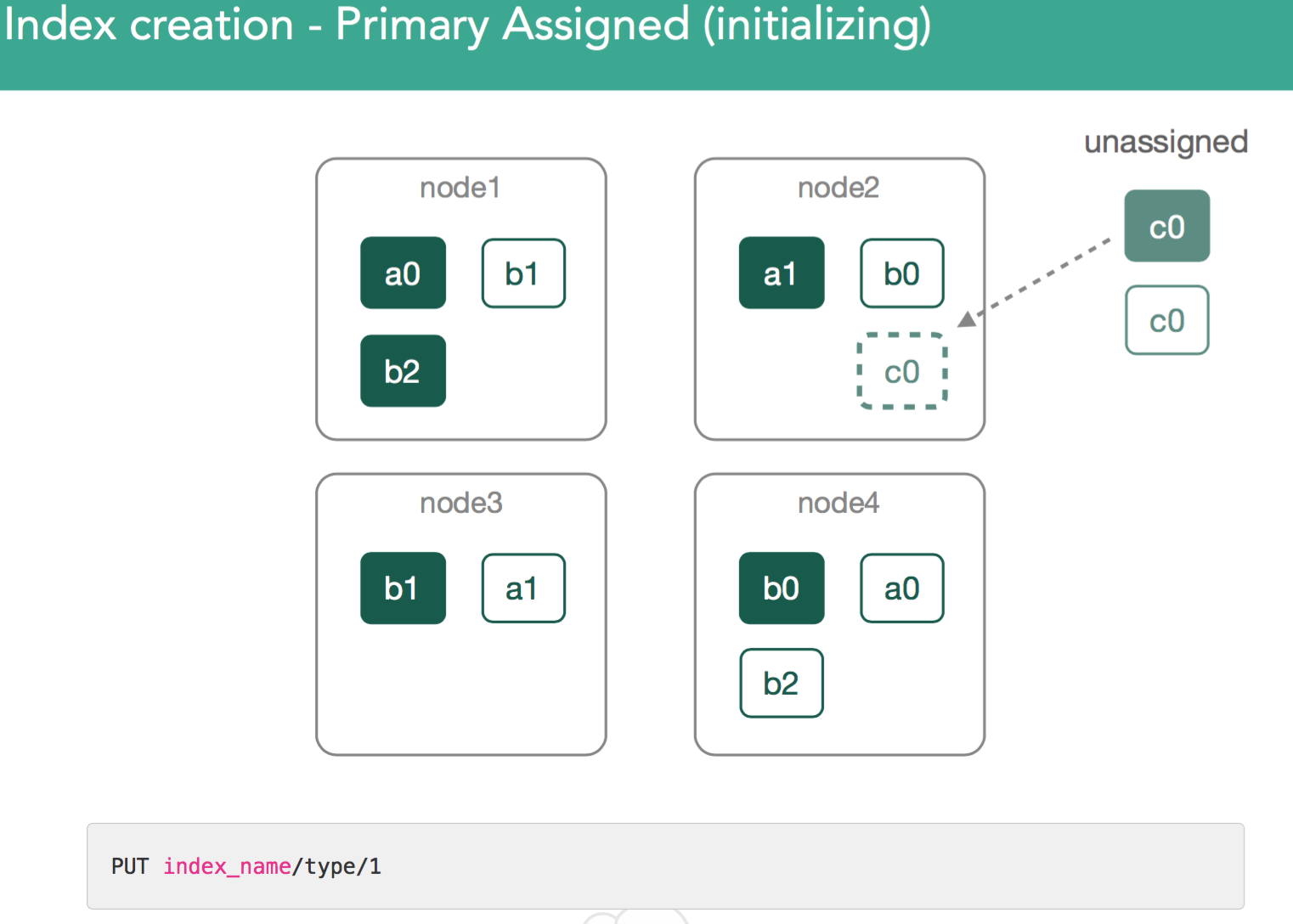
This is the most simple use case. We've created an index, c, and for it we've got to assign new shards. This will be done by indexing the first document into a new index c, with a command like you see in the grey box, using the Console(formerly Sense) plugin from within Kibana.
For index c, we're creating one primary shard, and one replica. The master needs to create index c, and assign 2 shards for c0, a primary and a replica. The way that the cluster will balance the cluster is by:
- By looking at the average number of shards that each node in the cluster contains and then trying to get that number to be as close to the same as possible
- By evaluating on a per index level in the cluster, and trying to rebalance shards across those indices.
There are certain restrictions on this process, and those restrictions are imposed by allocation deciders. They evaluate every decision the cluster tries to make and make a yes/no decision. They run on the master. You can think of it like the master proposing changes, and the deciders tell the master if there are any blocks that prevent the master's proposition.
The cleanest example of this is that you cannot put a primary and a replica on the same node.
There are other examples as well:

1. Allocation Filtering on Hot/Warm setups. This allows you to only put shards on nodes with certain attributes and will either accept or reject decisions made by the cluster made via this logic. This is an example of a User-driven decision controlling this configuration.
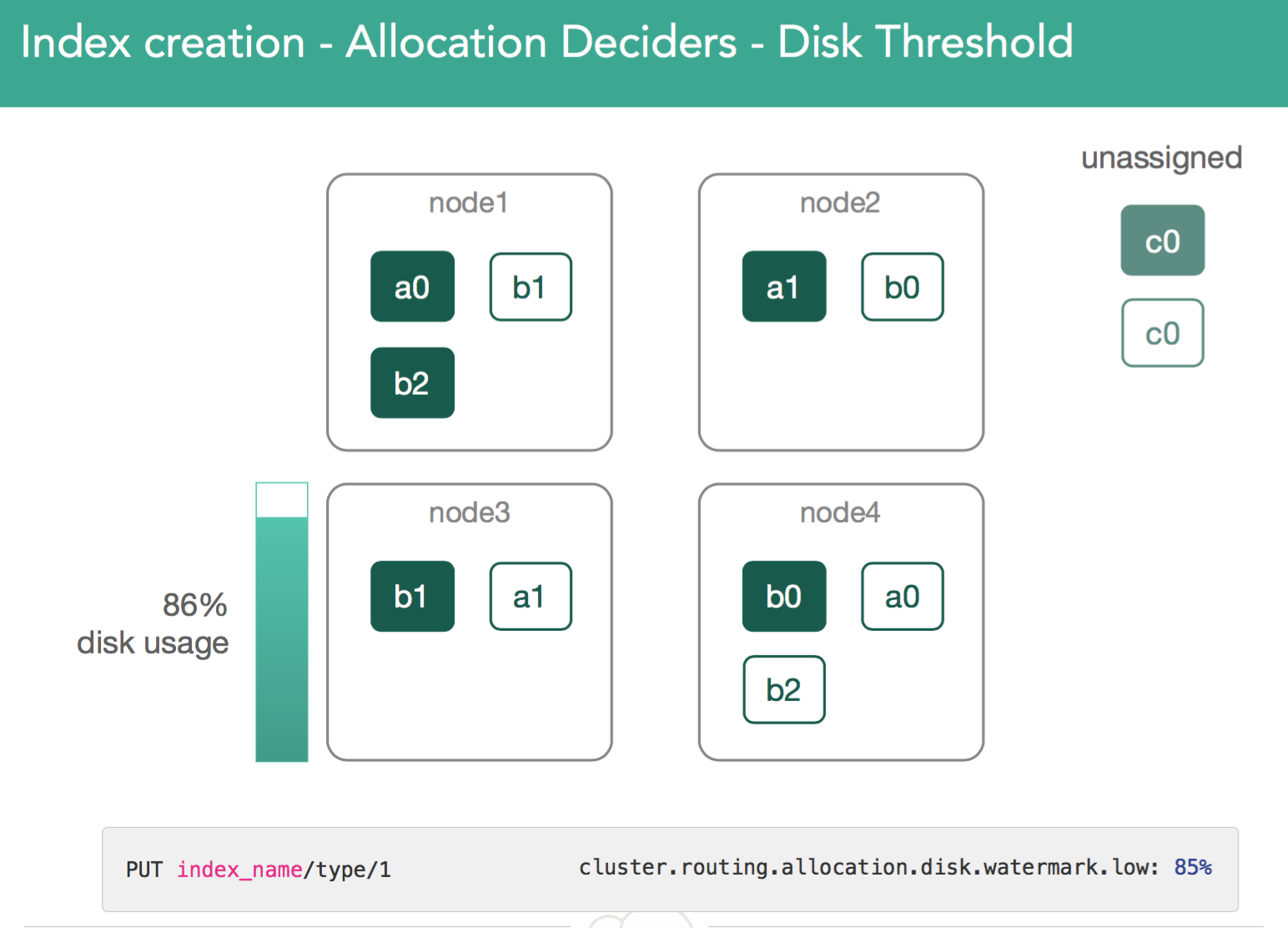
2. Disk usage allocator. The Master monitors disk usage on cluster and looks at high/low watermark. (see "Time to move a shard" below).
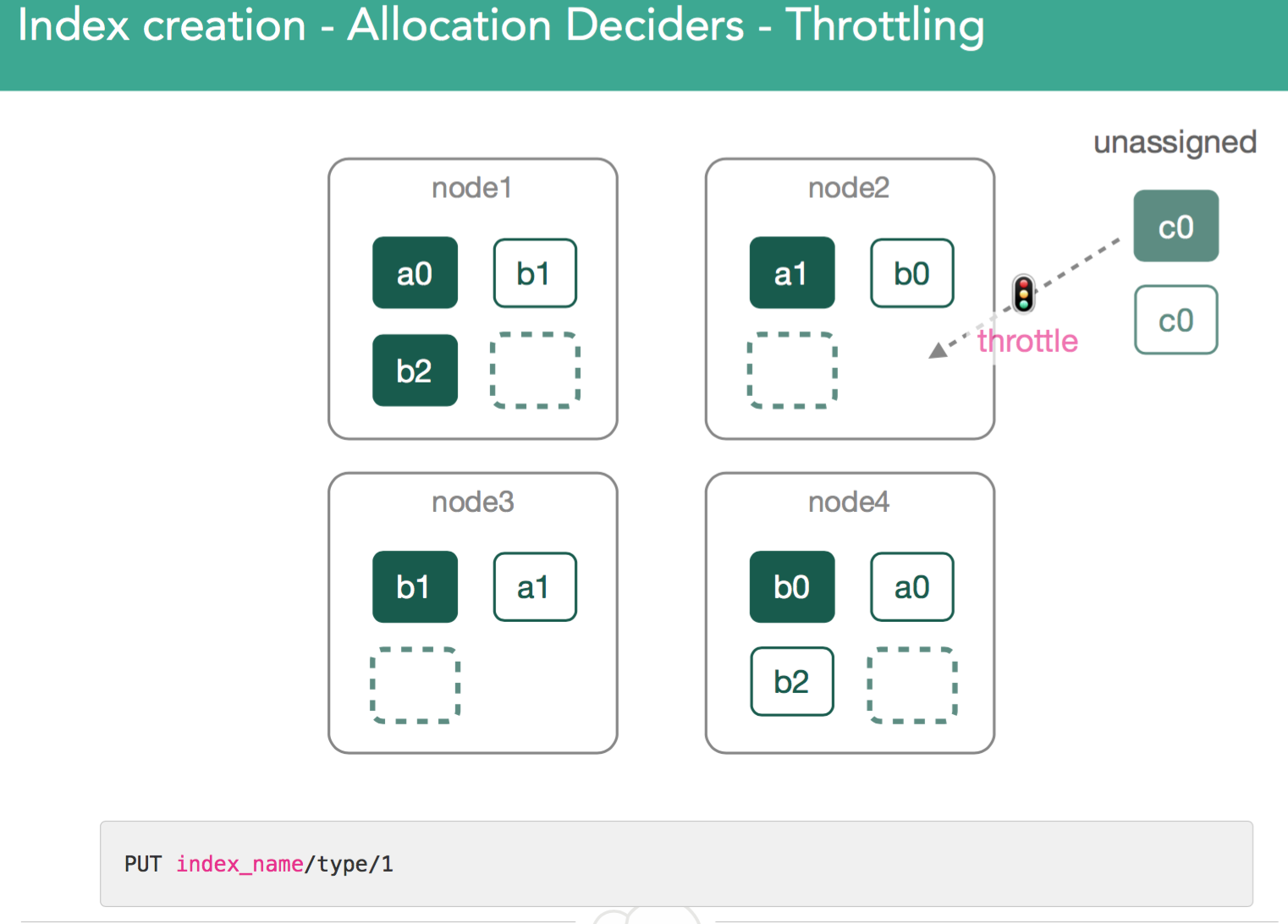
3. Throttles, which mean that in principle we can assign a shard to the node, but there are too many ongoing recoveries. To protect the node and allow recovery, the allocation decider can tell the cluster to wait and retry to assign the shard to the same node in the next iteration.
Shard initialization.
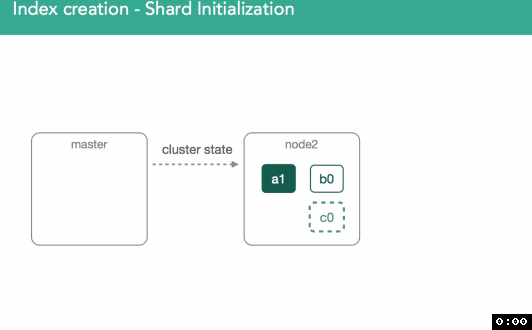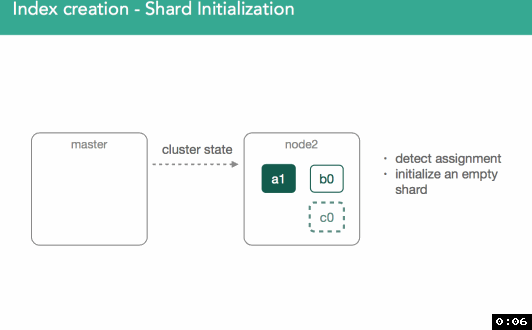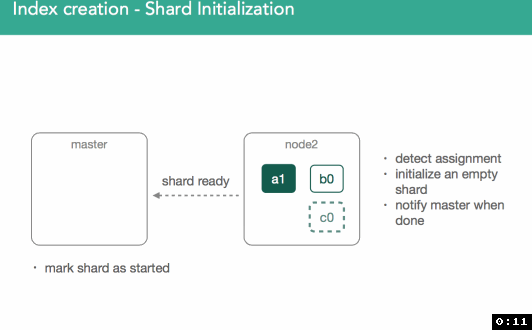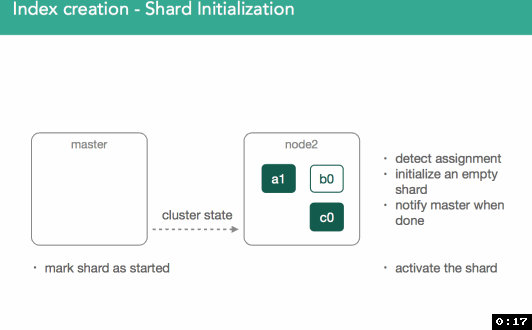
Once we've made a decision about where the primary shard belongs, it'll get marked as "initializing" and decision will be broadcast to cluster via a modified cluster state which is made available to all nodes within the cluster.
Once marked initializing, the node assigned will detect it was assigned the new shard. An empty lucene index will be created and once this is done the master will be alerted the shard is ready, master marks the shard as started, and sends out another modified cluster state. Once the node assigned the primary gets the updated cluster state it'll mark the shard as started. Because it's a primary, we'll now be allowed to index:
All of this communication, as you've seen, is done via modified cluster state. Once this cycle is complete, the master will perform a re-route and reevaluate shard assignment, potentially making decisions about what was throttled in the previous iteration.
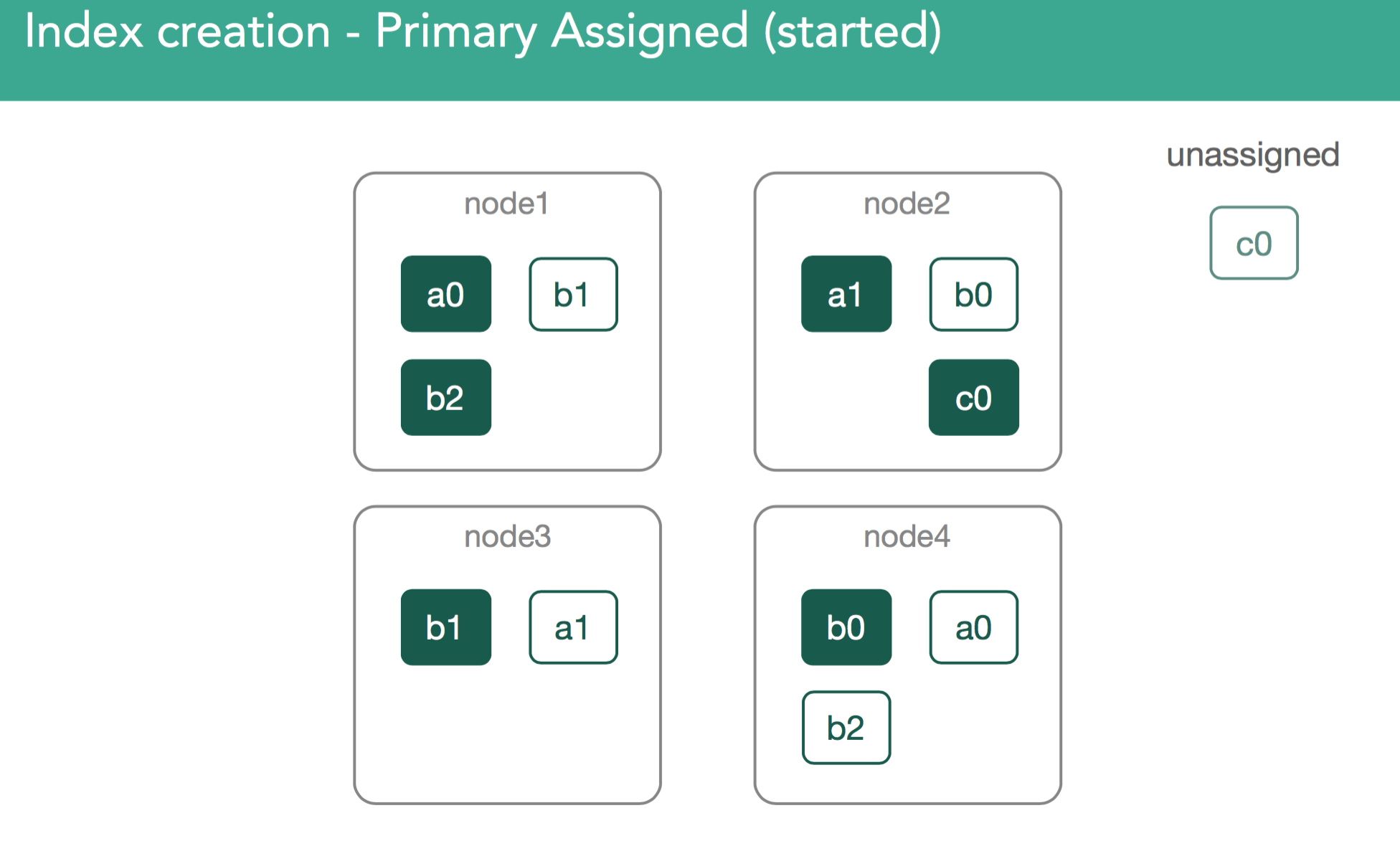
In our example, the master now must attempt to assign the leftover replica, c0. This is also decision of the allocation deciders, which prevent replicas from being assigned until the primary is marked as started on the node containing it.
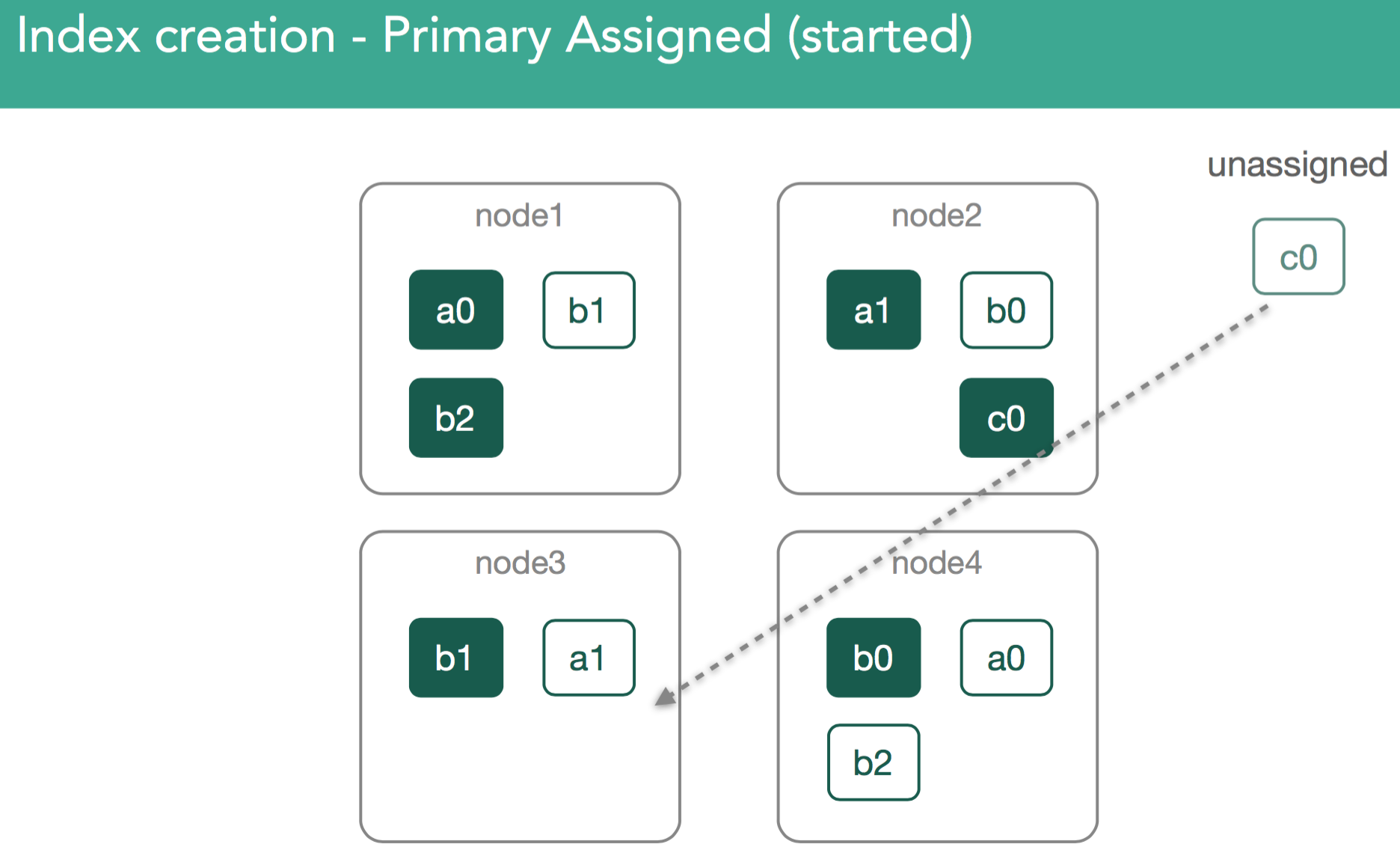
At this point, the re-balancing happens using the same process as describe above, with the goal of ensuring data balanced across the cluster, and in the case of this example we'll assign the c0 replica shard to node3 in the cluster in order to keep things balanced. This should leave us with 3 shards on each node in the cluster.
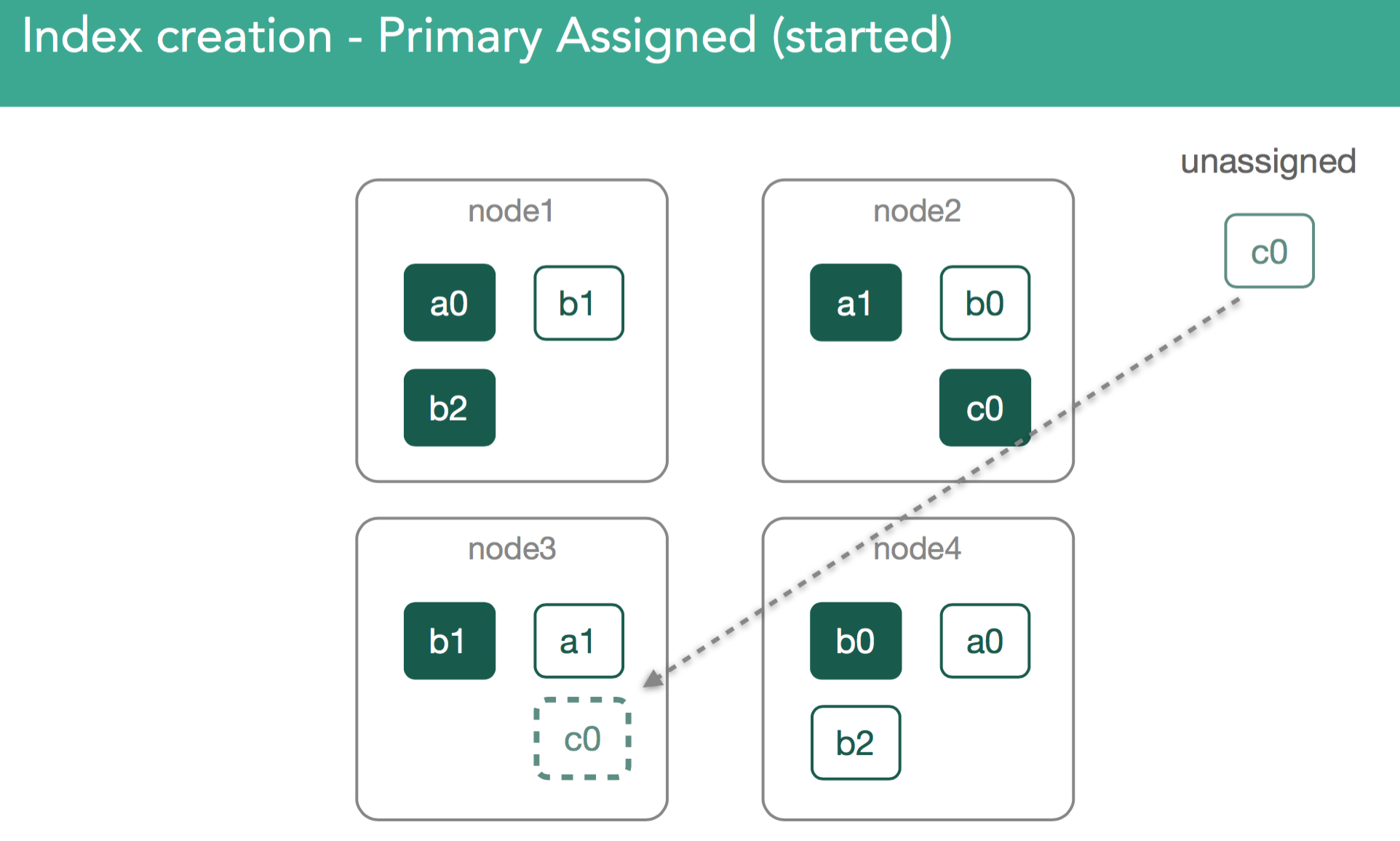
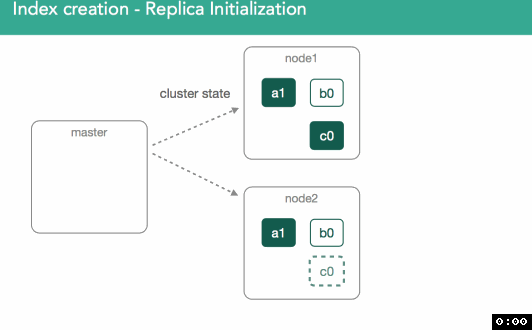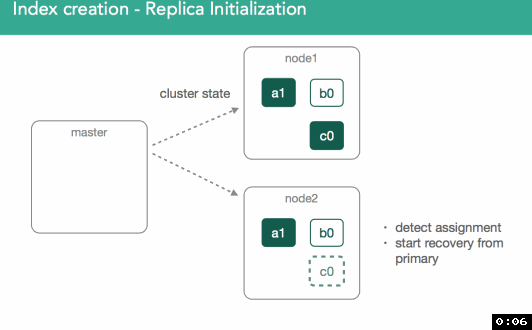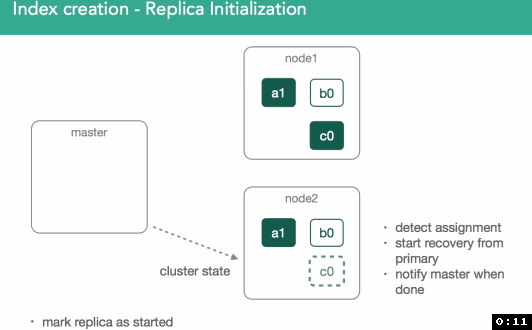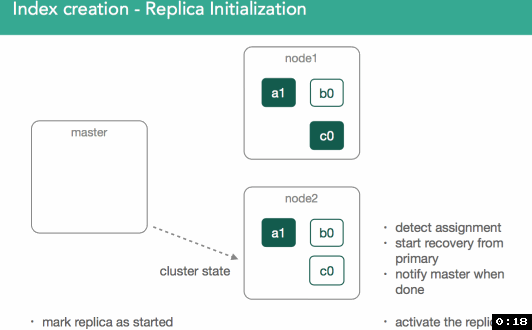
In our previous example, we just created an empty replica shard, which was a bit simpler than if we imagine we already have a started primary that already has data. With this in mind, we need to ensure the new replica has the same data as the primary.
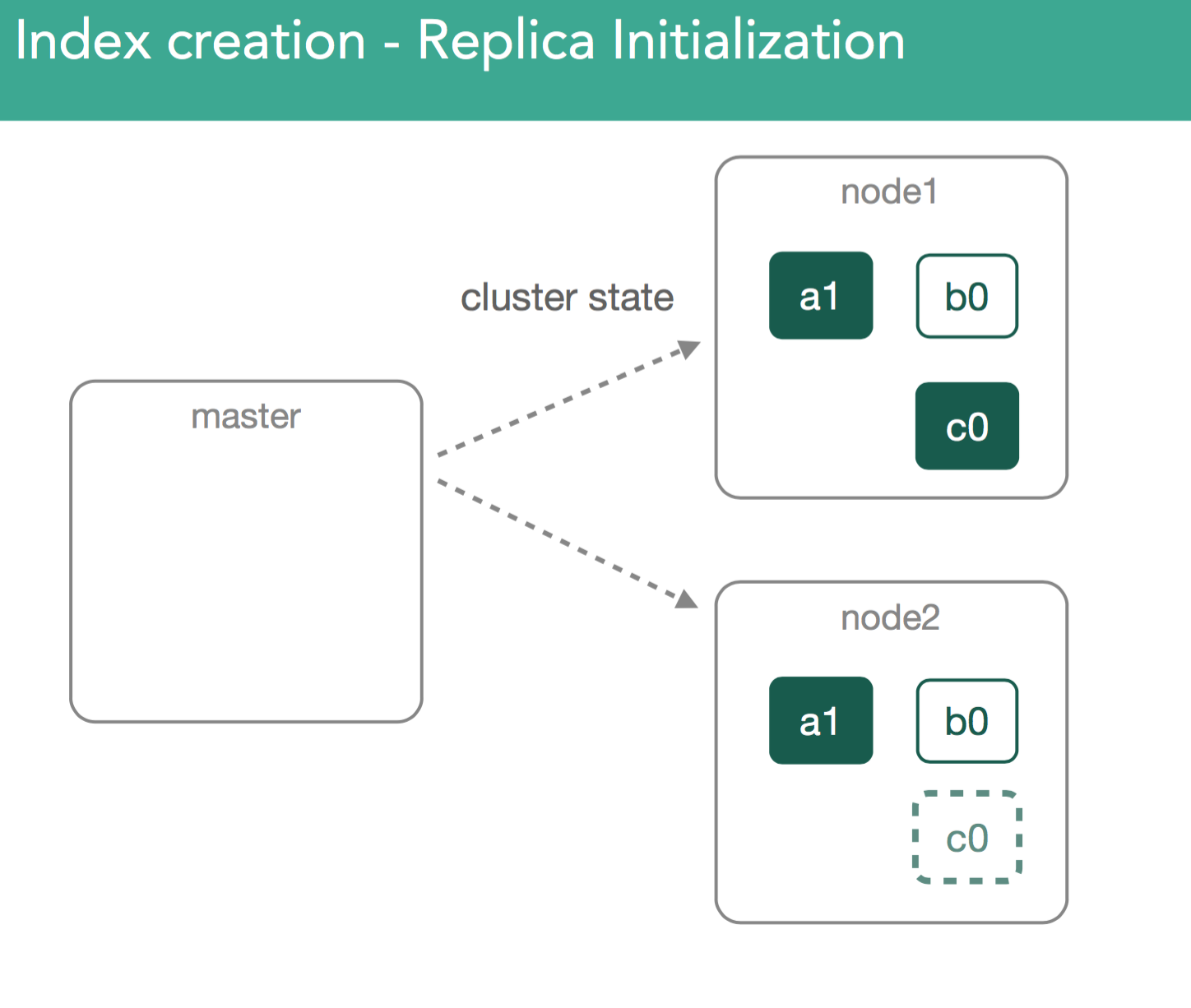
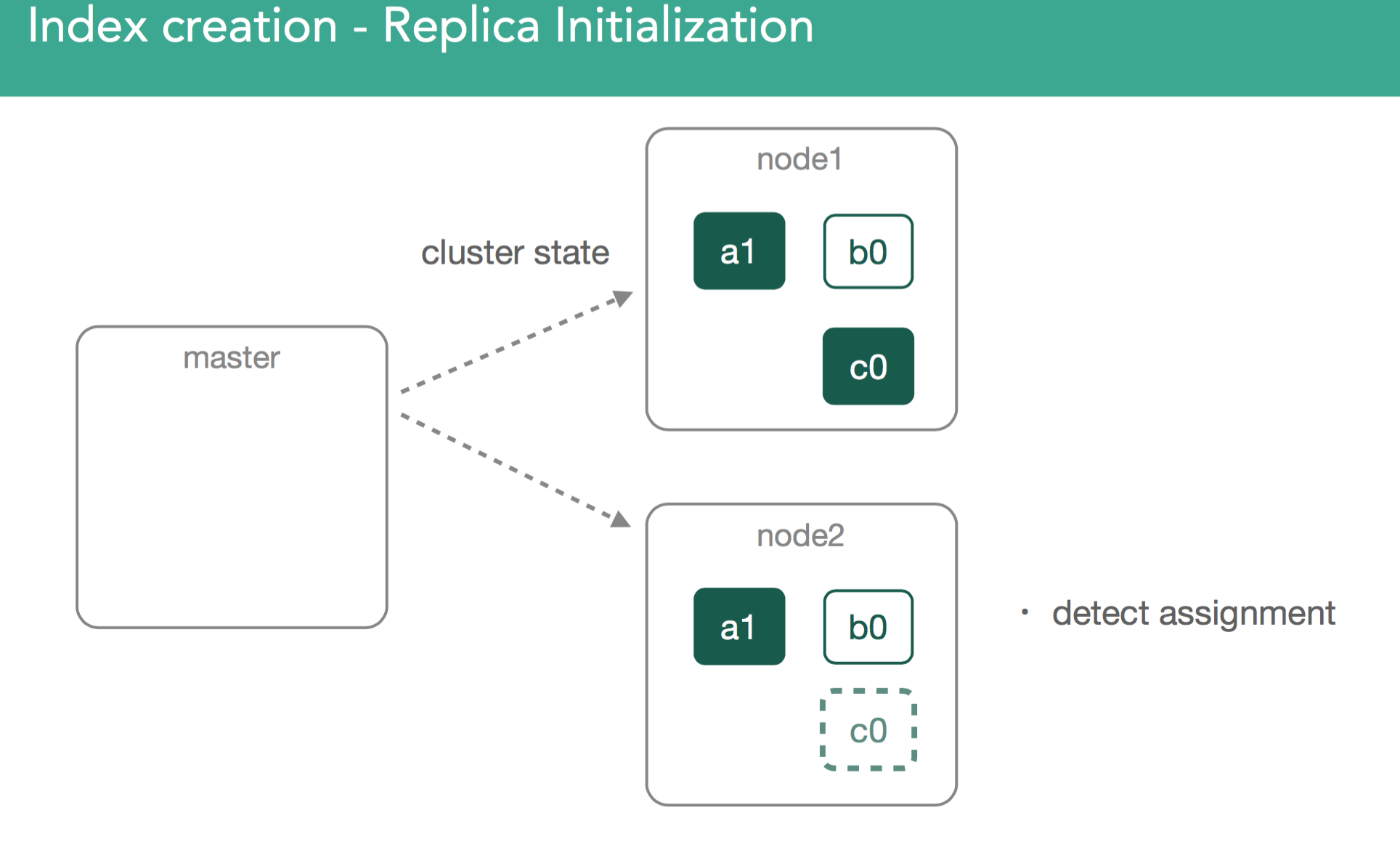
When replicas are assigned, it's important to understand we're going to copy any missing data from the primary back to the replica. After this, the master will again mark the replica as started and broadcast a new cluster state.
Scenario 2. Time to move a shard.
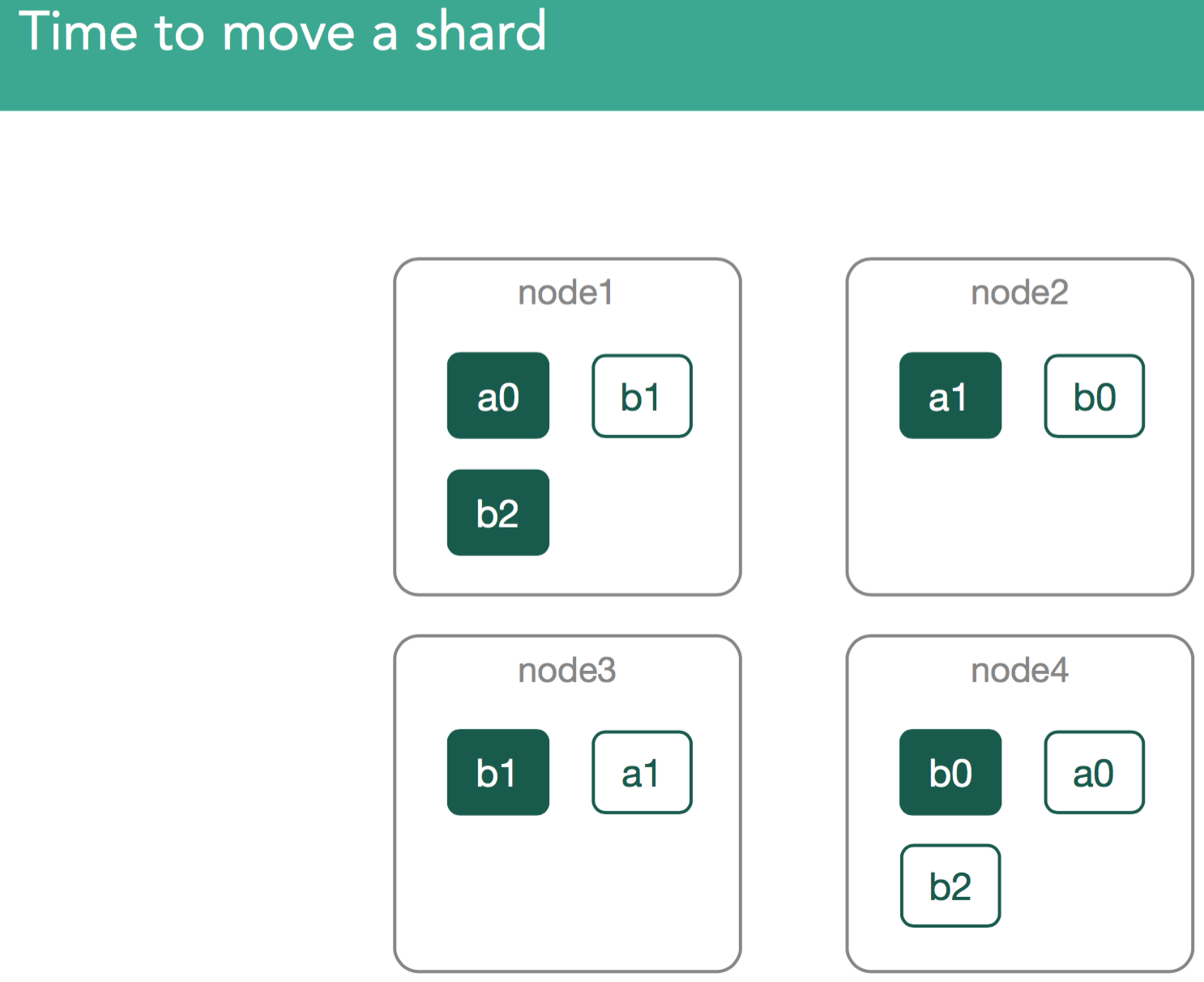
From time to time your cluster may need to move already existing shards within the cluster. This can happen for a number of reasons:

1. Explicit user configuration. A common example of this is a Hot/Warm configuration which moves data to slower disks as it ages:
2. User instructs elasticsearch to actually move a shard from one place to another for you with the cluster re-route command.
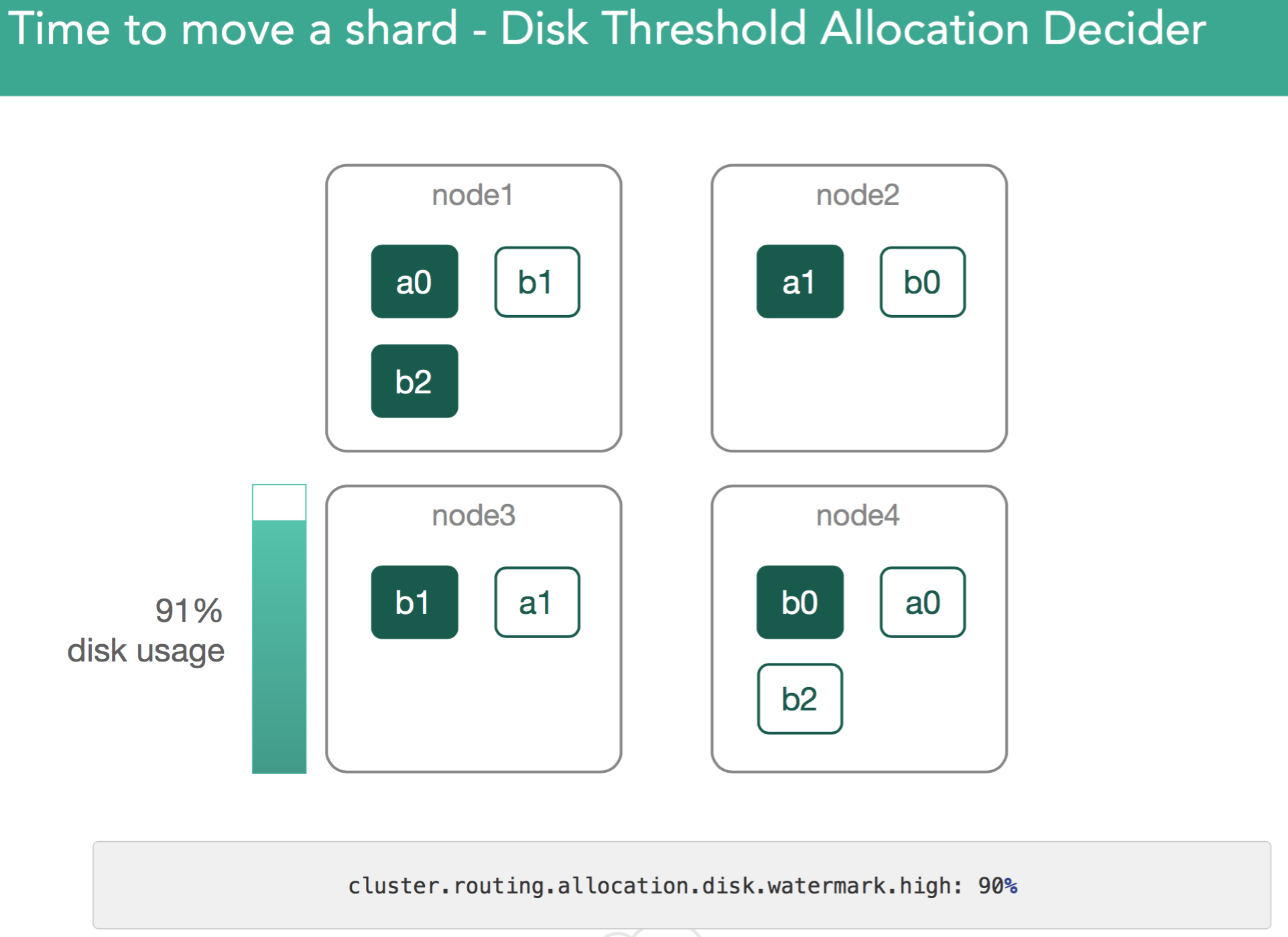
3. Allocation decider blocking on disk space because of exceeded thresholds for:
a. cluster.routing.allocation.disk.watermark.low
b. cluster.routing.allocation.disk.watermark.high
The low watermark prevents us from writing new shards when threshold is triggered. Likewise, the high watermark threshold the moves shards off the node until such time as disk space falls below the threshold.
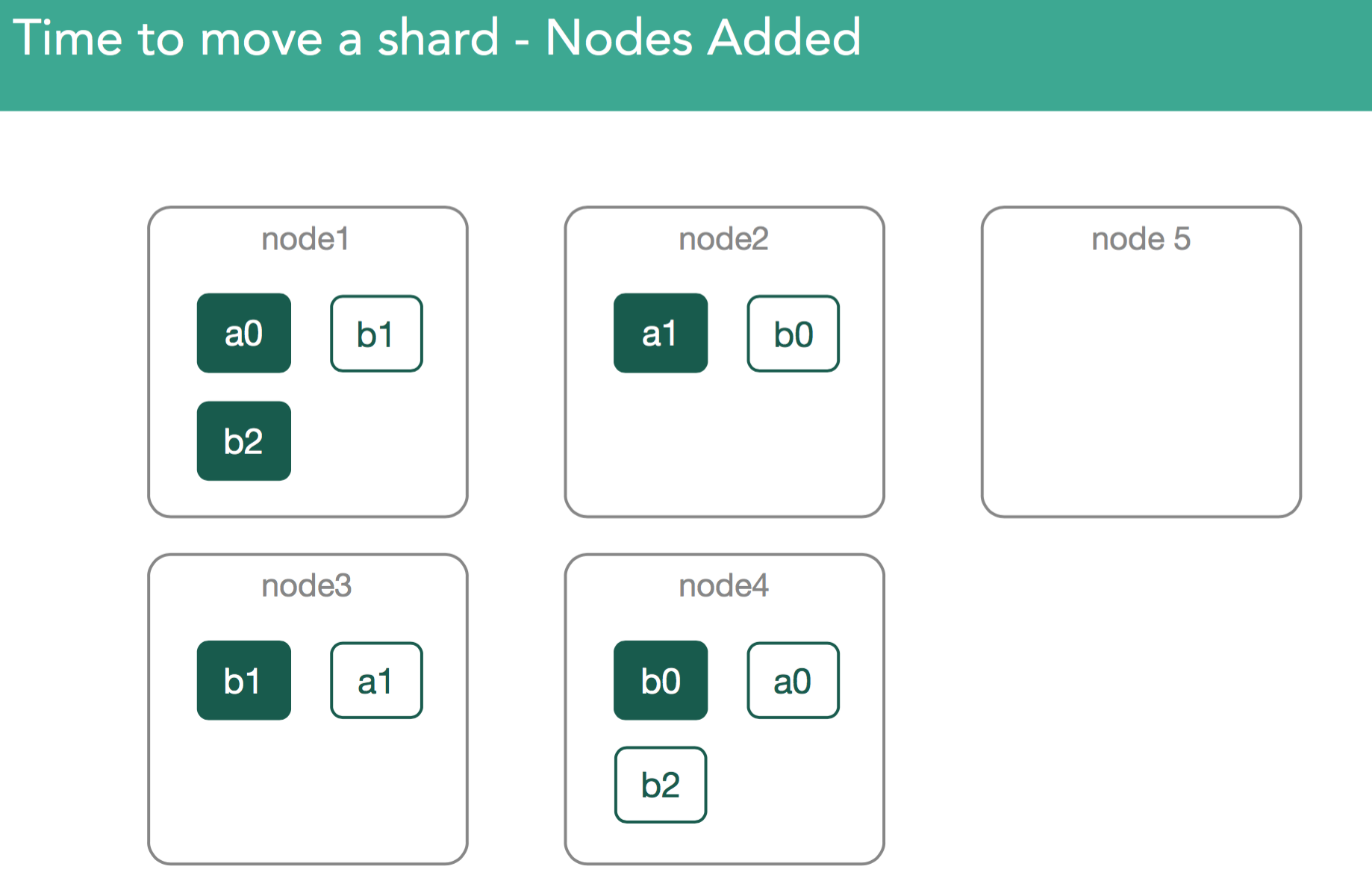
4. Nodes added to cluster. Maybe your cluster is at maximum capacity, so you've added a new node. Elasticsearch will attempt to rebalance the cluster.
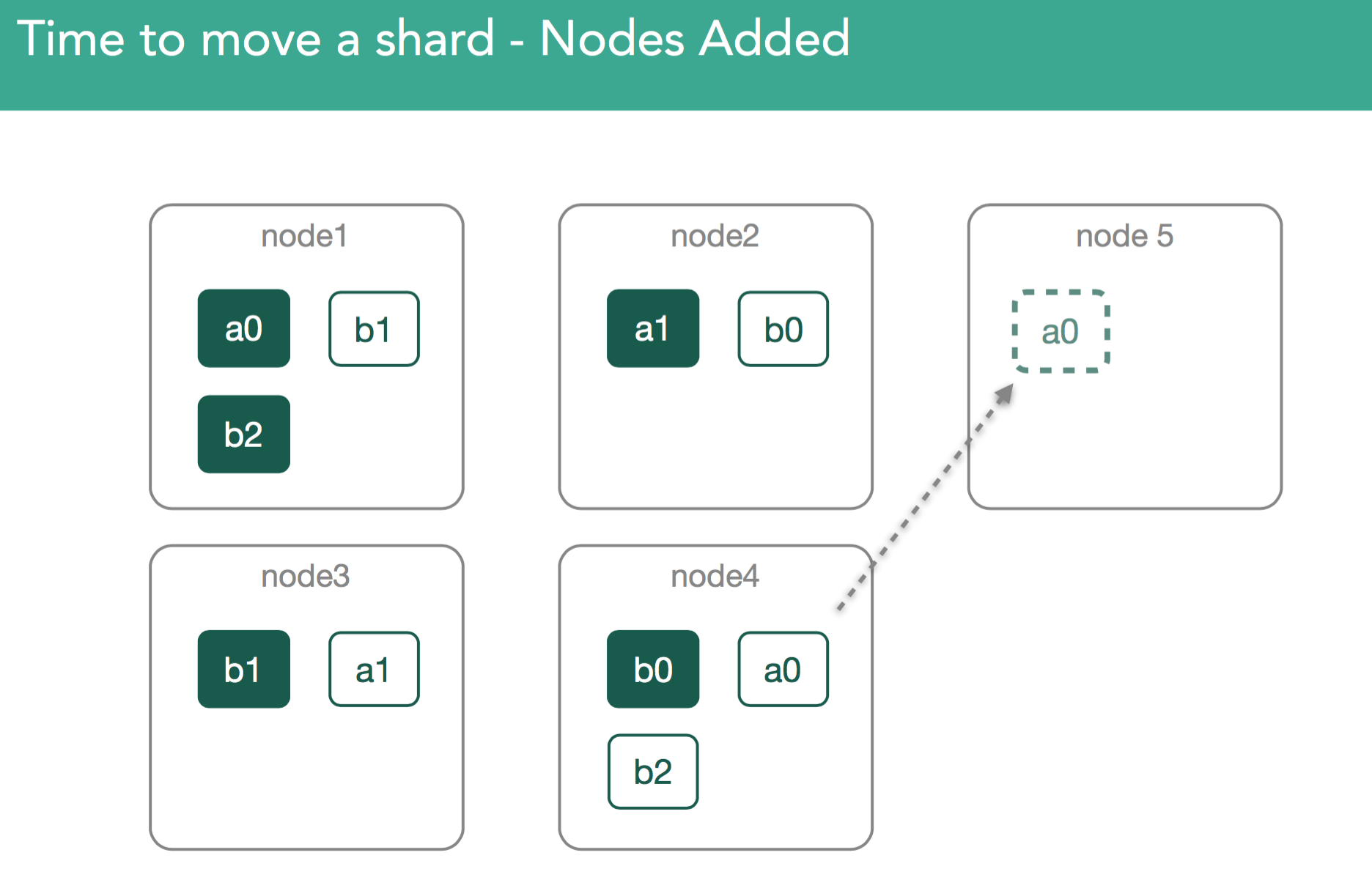
Since shards may contain many gigabytes of data, moving these across the cluster could potentially have significant impacts on performance. In order for this process to be transparent to users, this has to happen in the background. The idea is to, as much as possible, limit impacts on other aspects of elasticsearch performance. Toward that end, a throttle(indices.recovery.max_bytes_per_sec/cluster.routing.allocation.node_concurrent_recoveries) is introduced to ensure that we can continue to index into these shards.
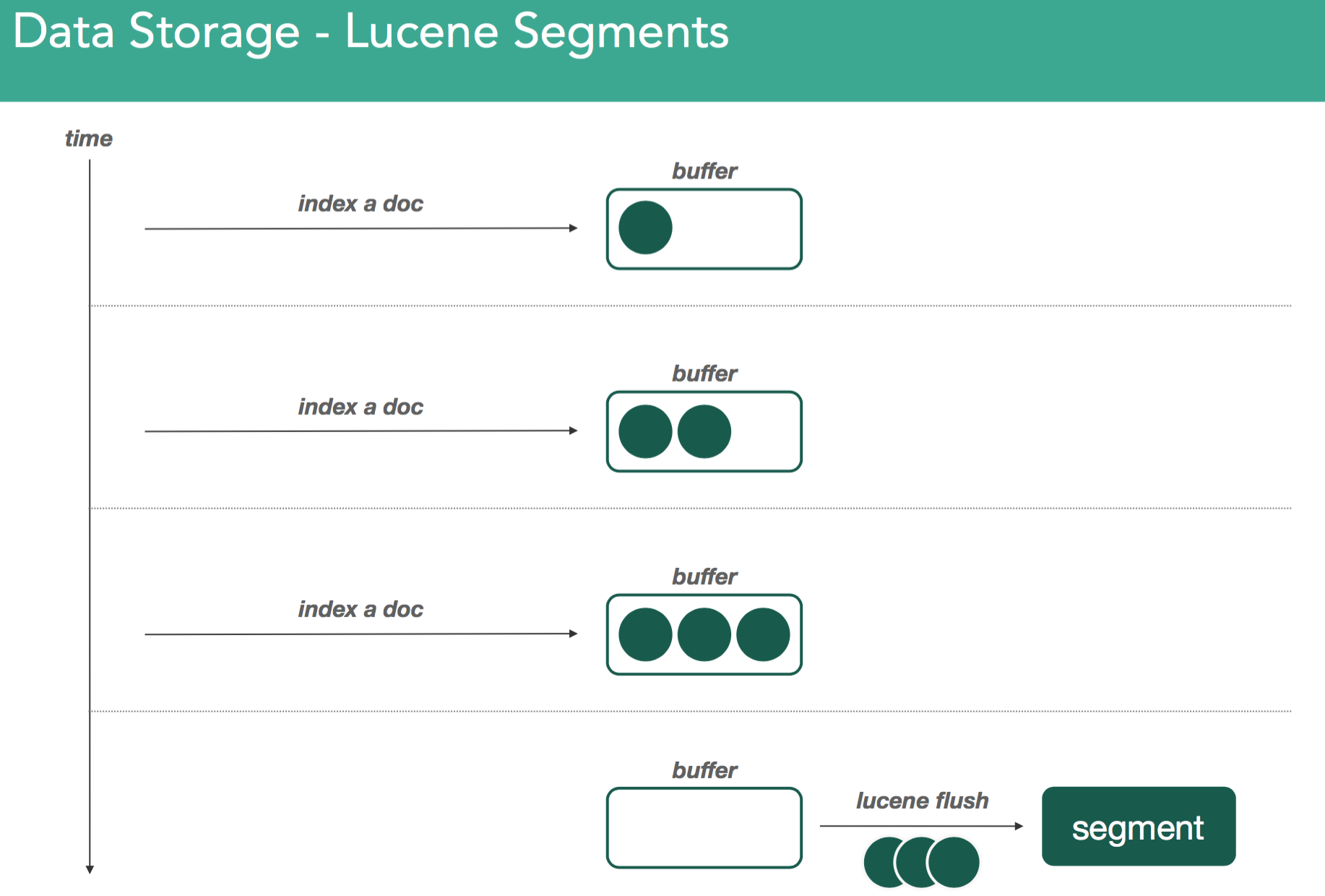
Remember, all elasticsearch data is stored through Lucene. Lucene contains a set of inverted indices in a set of files called segments. These inverted indices have a structure to tell you about where certain tokens/words appear within a set of documents. When indexing documents in Lucene, they're parked within an indexing buffer that sits in memory. There it sits until it a buffer becomes full, or in the case of elasticsearch, when something called a refresh is issued it forces all the data in the buffer into an inverted index called a segment.
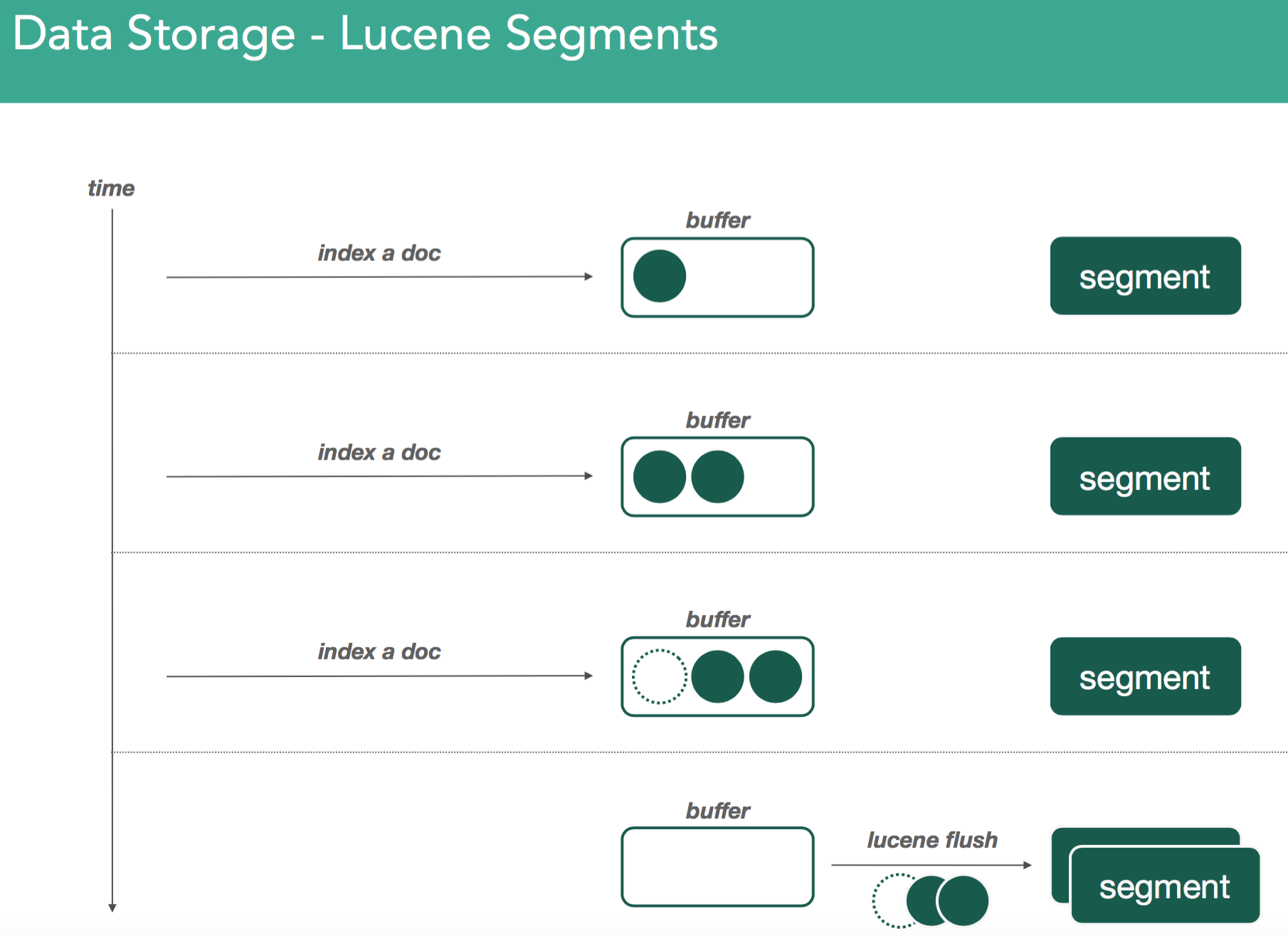
As we continue indexing, we create new segments in the same fashion. The thing about segments is they're immutable. Meaning, once you've written one, they don't ever change. If you issue a delete, or any change at all, it goes into a new segment where the same merging process happens again.
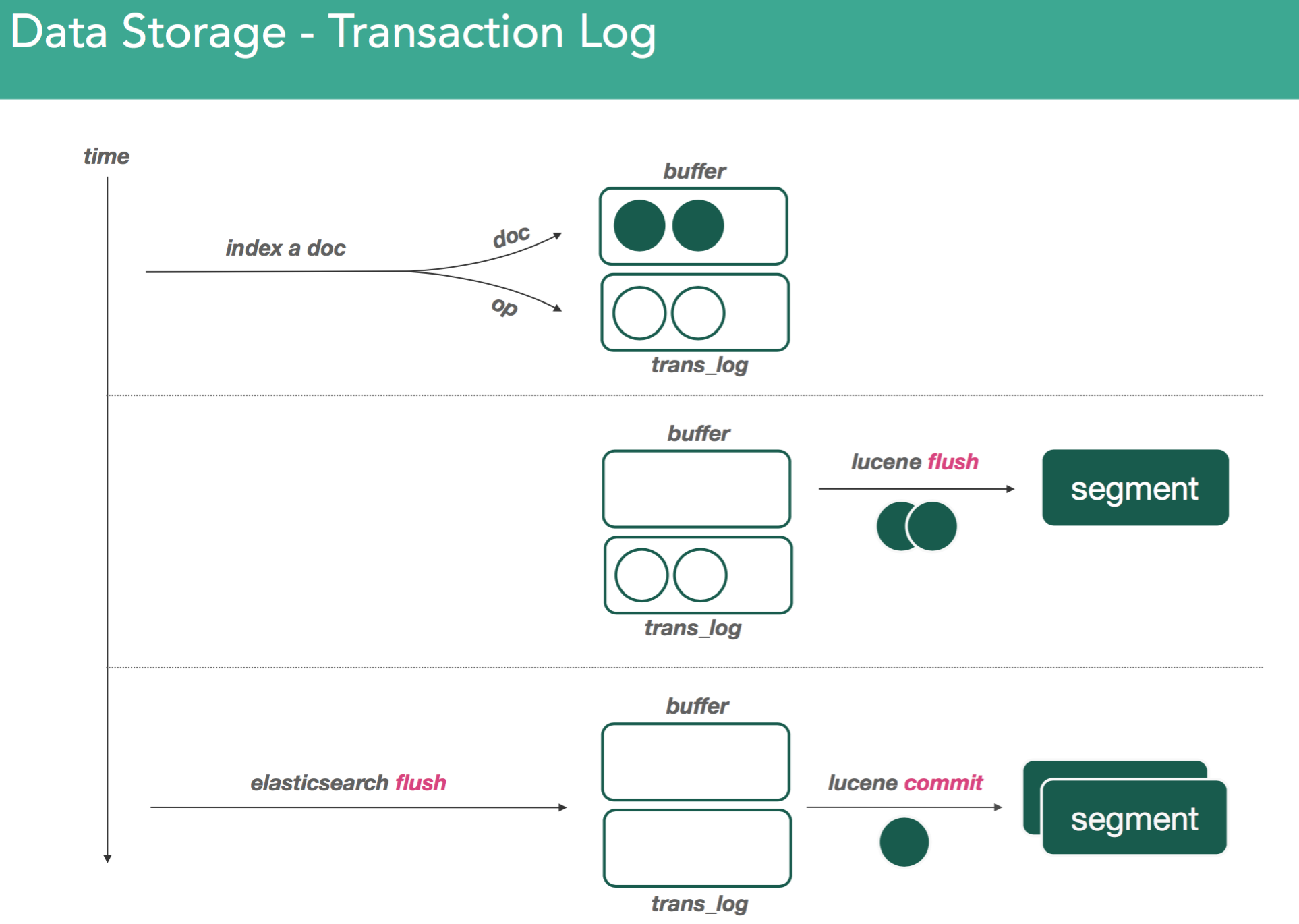
Since data is stored in memory, theoretically data could be lost before it's committed into a segment file. To mitigate this, elasticsearch makes use of a transaction log. Whenever a document is indexed into lucene, it's also written to the transaction log.
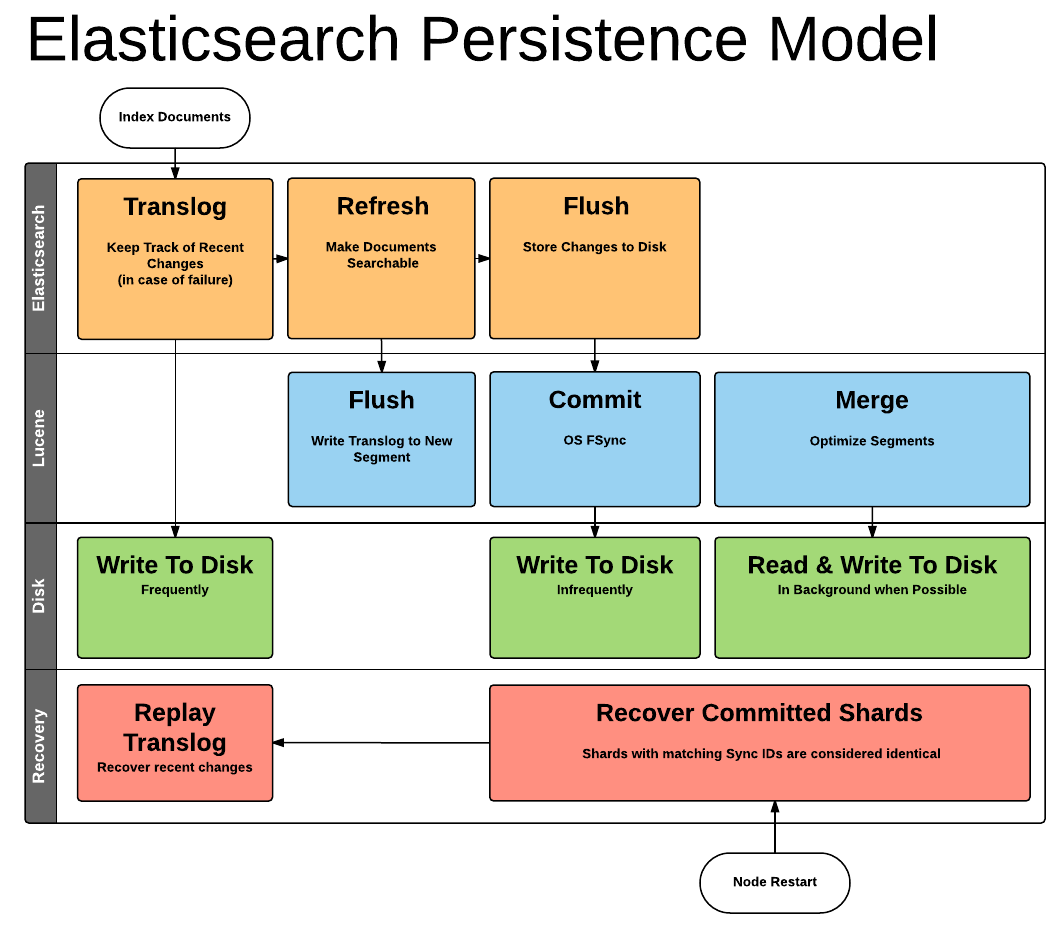
The transaction log is written sequentially, with the last request at the end of the file. The transaction logs allow us to recover documents which may not have made it into lucene.
It's possible for us make a segment without fsyncing, allowing the filesystem to keep in memory or pending flushes to disk. This is done for performance reasons, and because of this the transaction log needs to be cleaned. This is done with an elasticsearch flush.
On issuing elasticsearch flush, lucene commit, which does 2 things:
- Take everything in buffer and commit it to disk in new segment
- Goes through all segment files and asks the file system cache to persist to disk using fsync.
This allows us to flush the transaction log and guarantees we have all the data. For relocation, if we capture a given set of segments and keep them around we have a point in time consistent and immutable snapshot of our data.
In our example, when the cluster wants to move a0 from node4 to node5, first the master does it by marking shard a0 as relocating from node4 to node5. Node5 interprets this as an initializing shard copy on itself. An important thing to note around this behavior is that while rebalancing is happening it may appear a replica is being moved from node4 to node5, when relocating data it will always be copied from the primary shard(node1).

In the example below, we have an empty node5 and a node with the primary, node1. Keep in mind the two data storage mechanisms we mentioned previously, the transaction log and the lucene segments. We're illustrating Node5 responding to a request from the master to initialize a shard after reading an updated cluster state. Node5 goes to node1 and ask to start a recovery process. Node1 will then validate it knows about the request that node5 is making. Once a request is found, elasticsearch will pin the transaction log to prevent it from being deleted and take a snapshot in lucene, ensuring that we capture all the data within the shard. Once we do this, we can start sending segments over to the target file. This all happens in the background, so you can still index into the primary shards during this process. Once that happens, we'll replay the transaction log to ensure whatever wasn't in the segments is now captured.
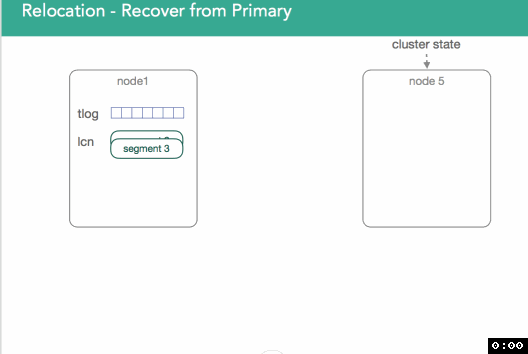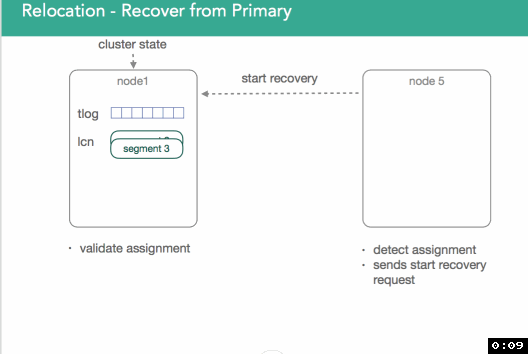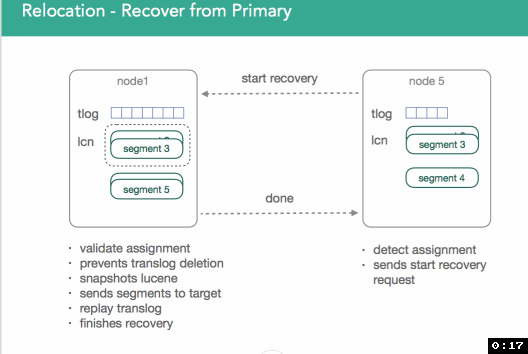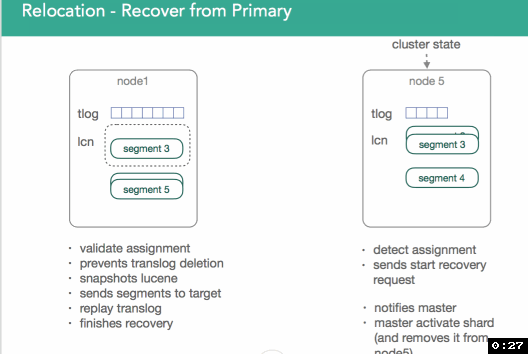
Now the question comes up, when do we stop? People can still index into primary shard, which means that the transaction log grows. In 1.x, we locked the trans log and from that point on all incoming requests are blocked until we finish replaying the transaction log.
In 2.x/5.x, we're better. As soon as we start relocation, primary will start to send all indexing operations to the new primary(node5). Since we know when we did the lucene snapshot, and when the shard was initialized, we know what exactly to replay from the transaction log.
Once recovery is done, the target nodes sends notification that the shard is ready to it's master. Master processes request, copies remaining primary data, and activates shard. It can then be removed from the source and the process repeats until rebalancing is completed.
Scenario 3. Full Cluster Restart
The next scenario we'll look at is a full cluster restart. This is a scenario in which we're not dealing with active segments, but finding data locally on each node.
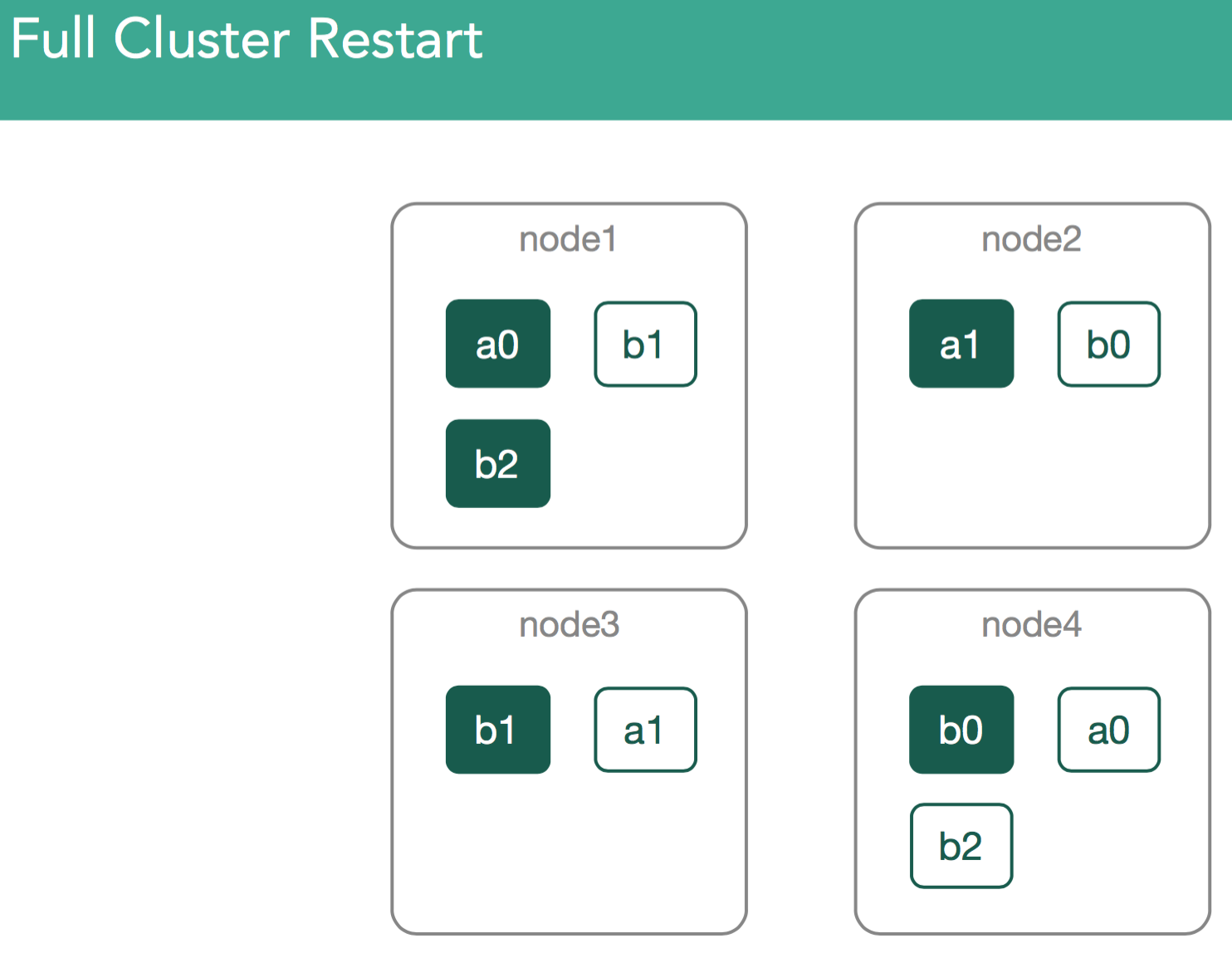
This covers things like Maintenance cycles, upgrades, anything related to planned maintenance.

Here our Master is elected, then a cluster state is created or restored from disk. Now we have a list of shard that need to be assigned. Unlike newly indexed data, these shards can't be assigned anywhere as they've previously been assigned. That means we'll have to go find the data and make sure we open the lucene indices we've previously created.
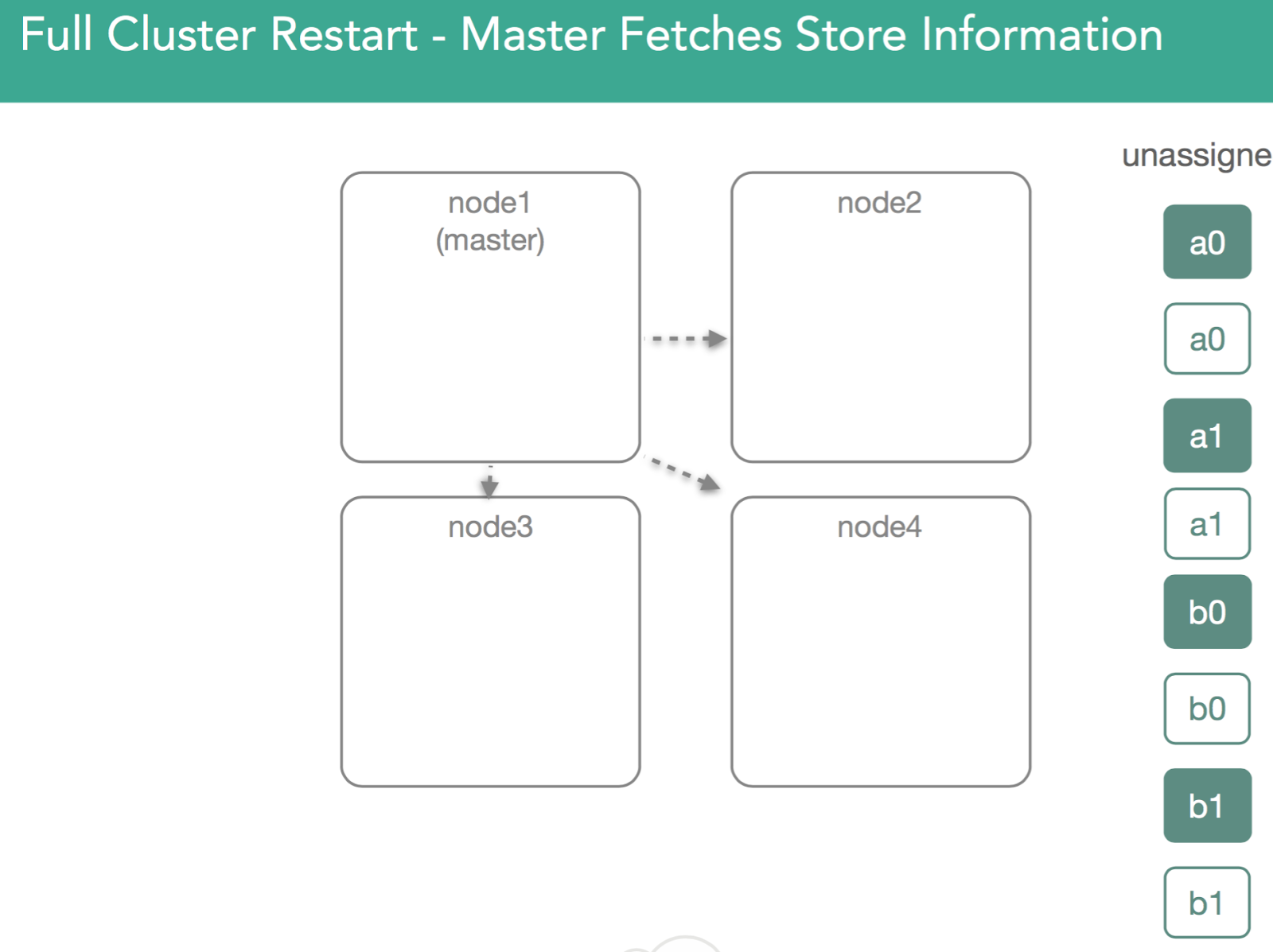
To do this, the master reaches out to the nodes to assign a primary and asks for a list of everything on disk. That means we physically open the segments and then respond to the master with a confirmation of a shard copy. At that point the master will decide who gets the primary. In 5.x, we introduced preferences for previous primaries(optimization).
Below, we can see that shard a0 on node1 had previously acted as primary, but potential exists for any valid copy to become primary. In this case, node4's shard is marked as initializing, but what's different is this time we know we're supposed to use existing data and can look at our nodes lucene indices to validate they're valid and can be opened. The Master is notified that the shard is ready, shard is assigned, and the master adds that assignment to the cluster state.
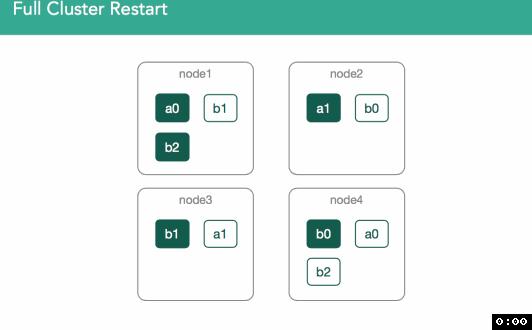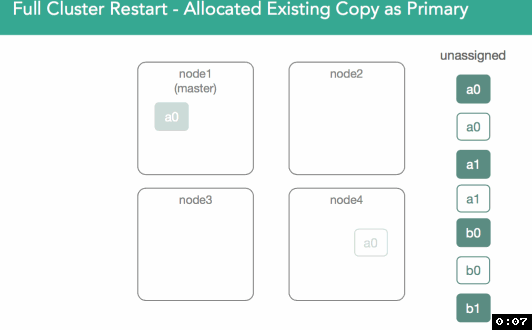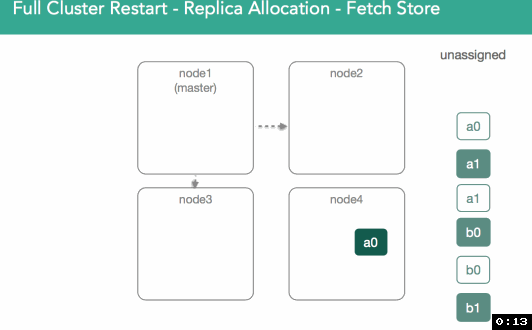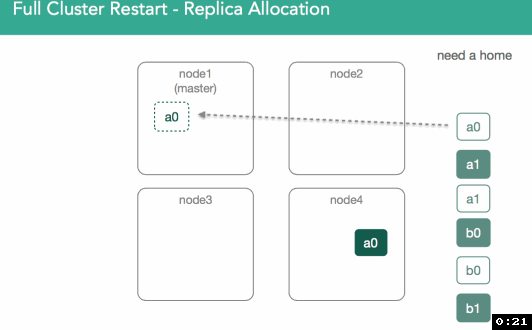
In order to validate the data is the same on both shards, we go to a process similar to relocation except that because all copies of the shard are restored from disk, they may already match and no shards would need to be transferred.This process is described in more detail here.
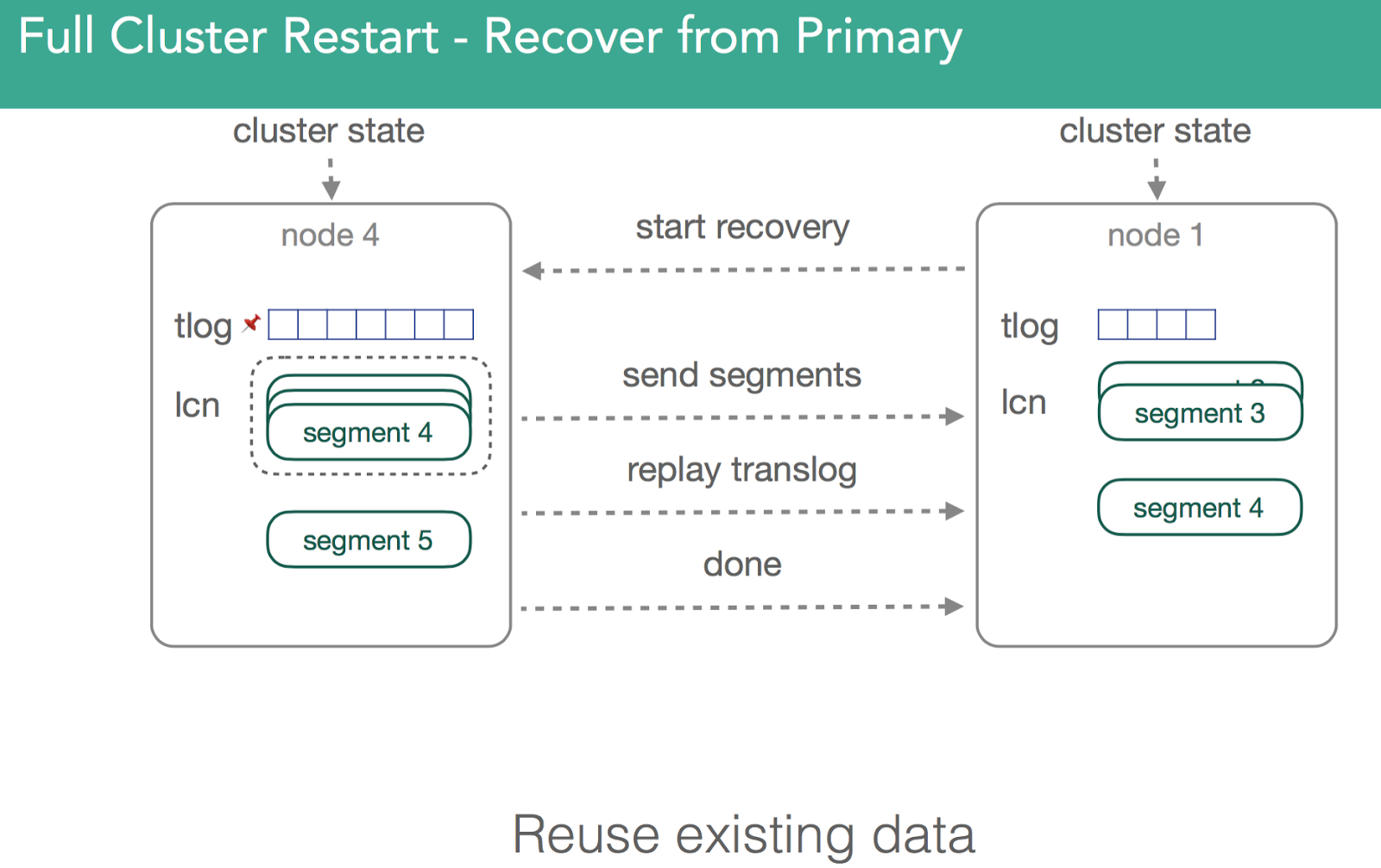
Because segments are independent lucene indices, after heavy indexing there is a strong likelihood they're going to be different on disk vs the same segments on other nodes. Some of them will use more resources than others, some of them will have nosy neighbors.
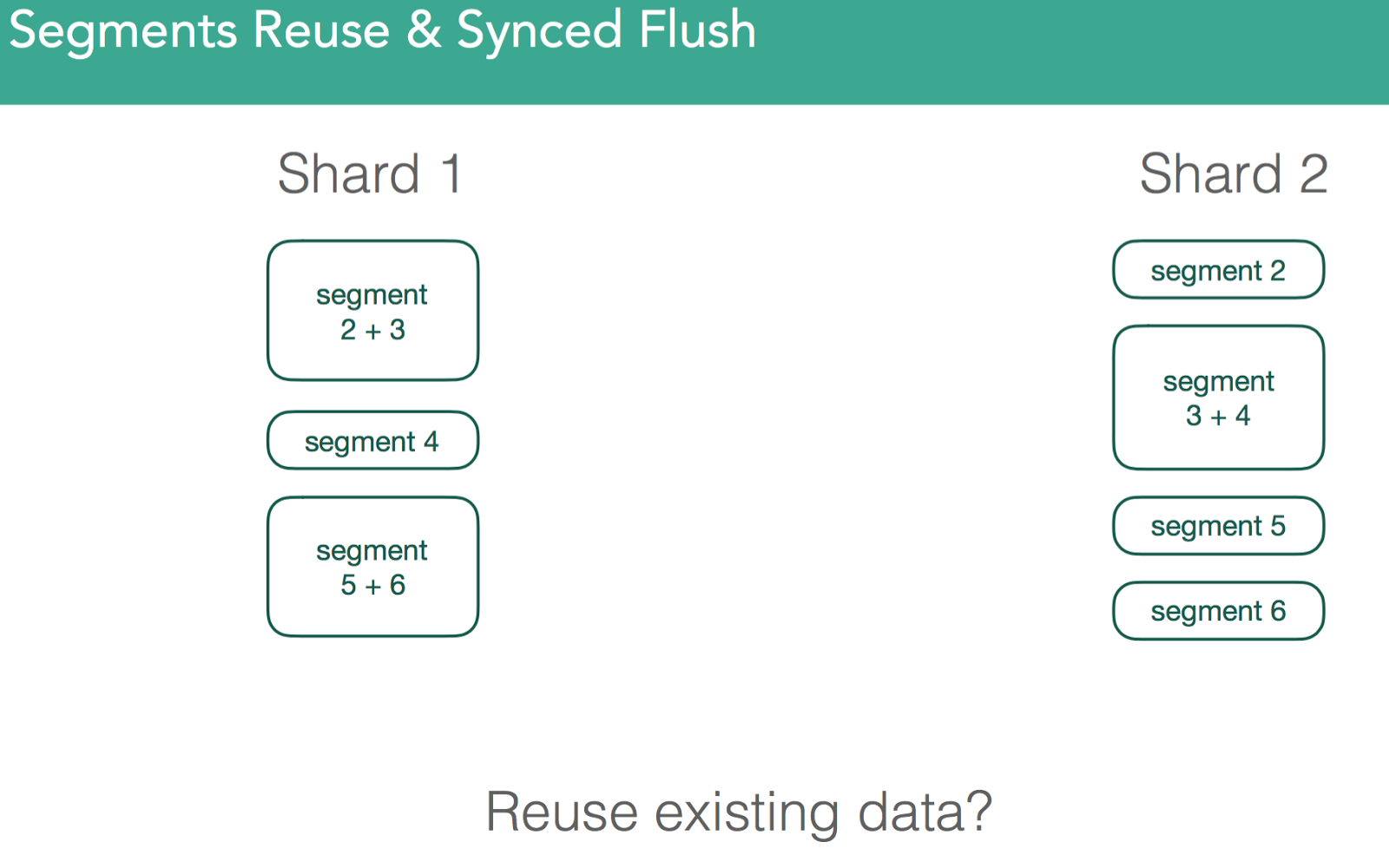
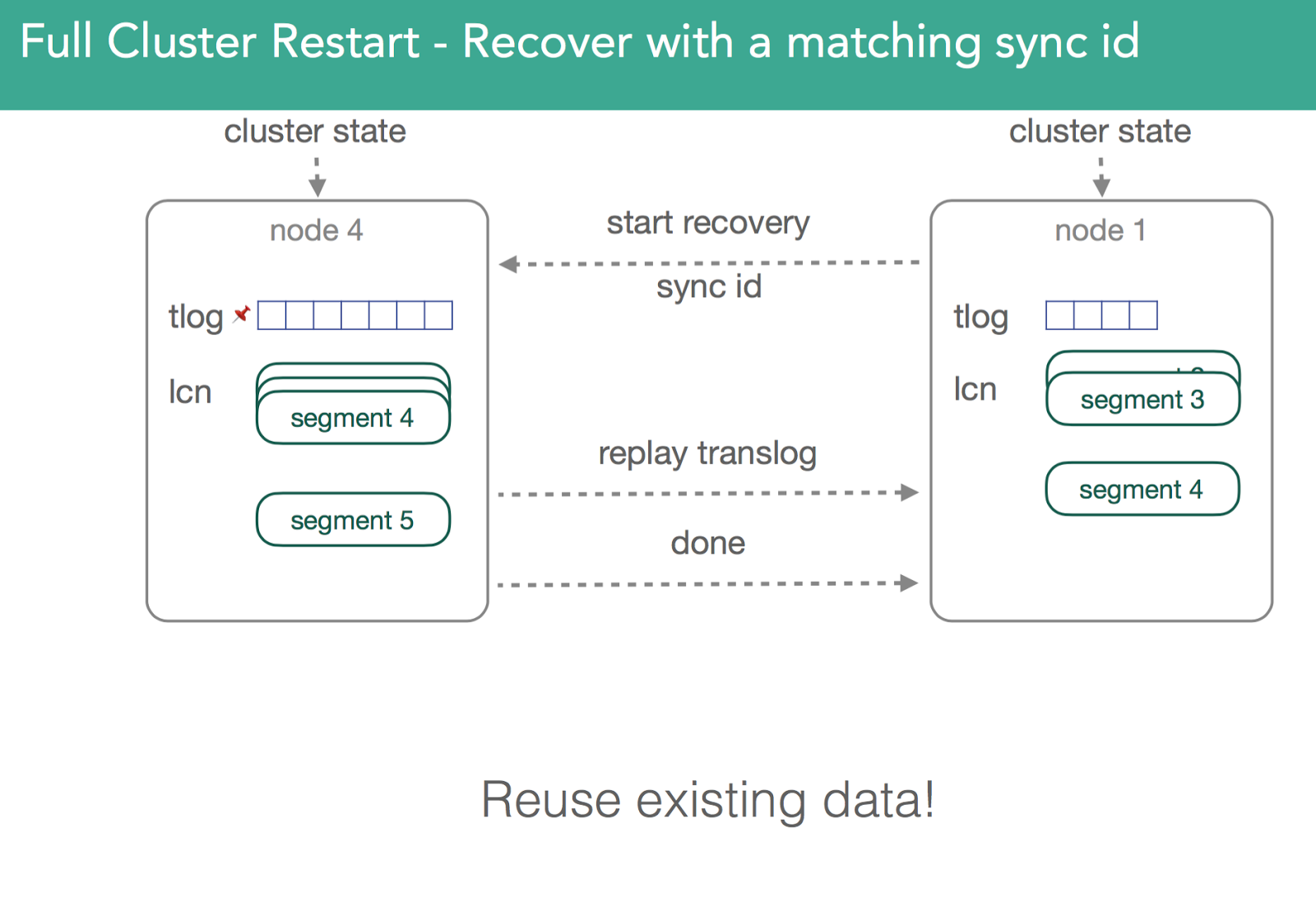
Prior to 1.6, all segments had to be copied over. Because of this, recoveries prior to 1.6 were slow. We have to sync primary and replica, but can't use any local data. To deal with this we added sync_flush and sync_id. It's a way of taking a moment when no indexing is occurring, capture the information with a unique identifier, guaranteeing the data is identical between copies of the same shard. So when we go to recovery, we send the sync_id to act as a marker, and if it matches it won't copy the file over and will reuse old copies. Because segments in lucene are immutable, this can only be done for inactive shards. NOTE: below the image shows the same shard on separate nodes, the copy numbers are what change.

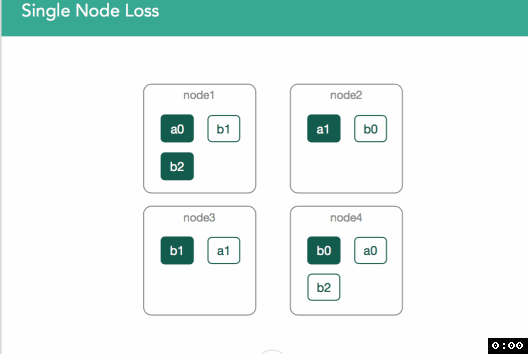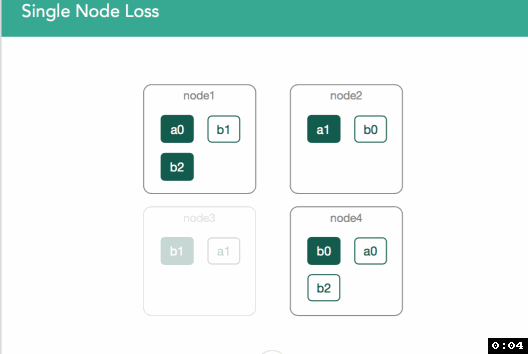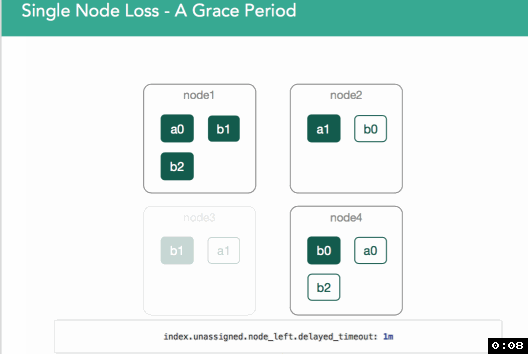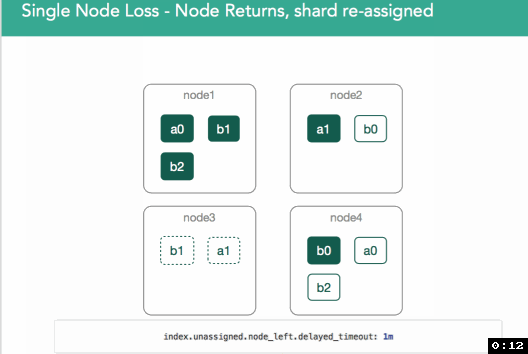
Scenario 4. Single node Loss on node3.
In the figure below, node3 is removed from the cluster, and with it, the primary copy of shard b1. The first, immediate step is that the master will promote the single replica of b1, currently on node1, to be the new primary. The health of that index, as well of the cluster, is now yellow, because there is a shard which doesn't have all of the shard copies allocated (as indicated by the user in the index definition). Hence, the master should attempt to allocate a new replica copy of that shard to one of the other remaining nodes. If node3 left because of a temporary network disruption (or a long pause of the JVM due to garbage collection), and there is no additional indexing of the shard before the disruption passes and the node returns to the cluster, replication of the shard to another node during its absence will have been a wasteful use of resources.
In v1.6, a per-index setting was introduced (index.unassigned.node_left.delayed_timeout, defaults to 1m) to address this issue. When node3 leaves, re-allocation of the shard will be delayed for this period. If node3 returns before this, the shard copies will be compared, and if the primary hasn't changed in the interim, the copy on node3 will be designated as the replica. If it has changed, the shard will be re-replicated to node3.
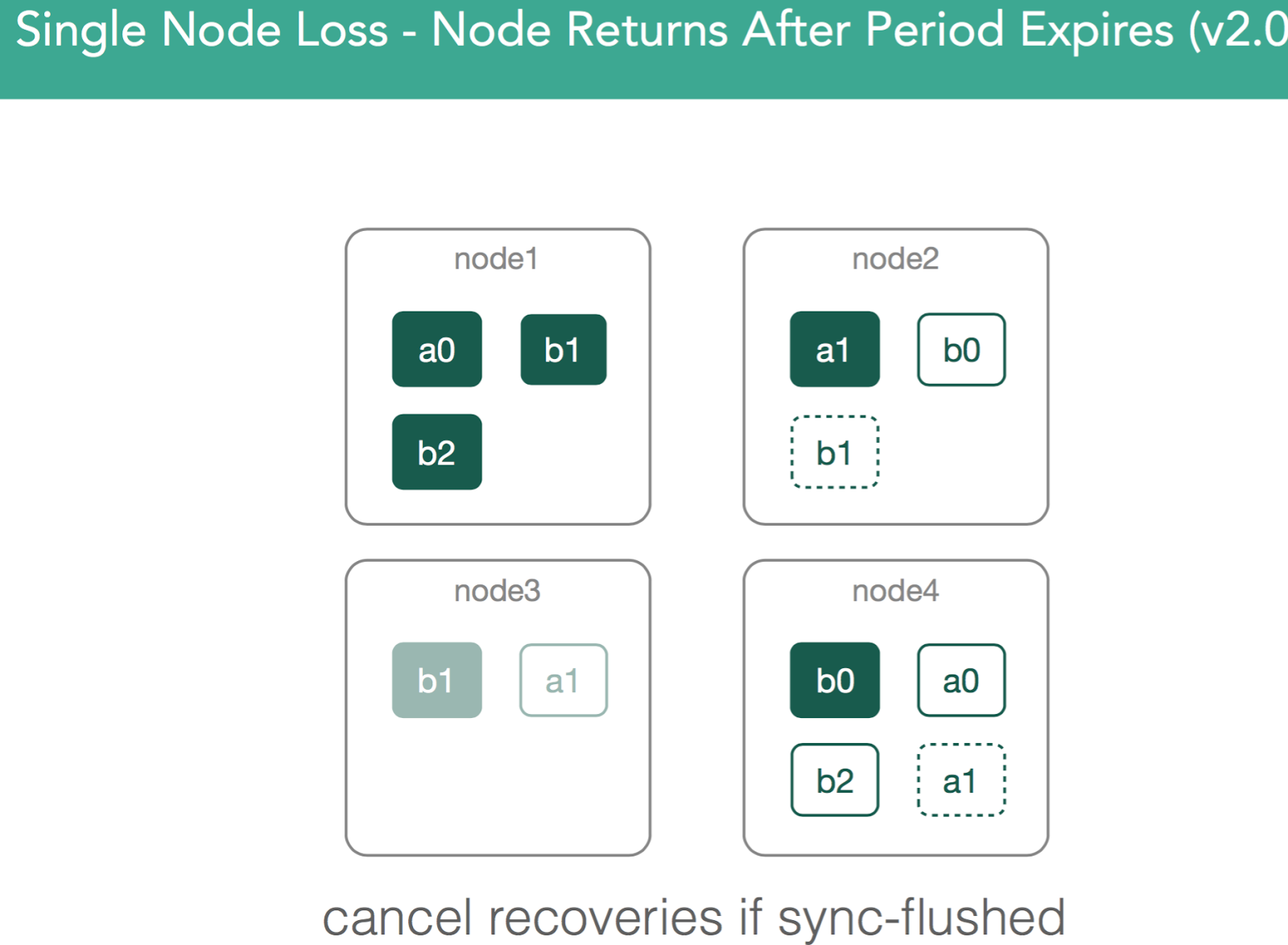
In v2.0, an improvement was added so that, if node3 returns after the delayed_timeout, for any shards on node3 that still match the primary copy(based on the sync_id marker), any replications that have been initiated will be stopped, and the copy on node3 will be designated the replica.


elasticsearch 分片的创建 集群重启分片运作的更多相关文章
- Elasticsearch(ES)集群的搭建
1. 概述 Elasticsearch(ES)集群支持分片和副本,能够很容易的实现负载均衡.扩容.容灾.高可用. 今天我们就来聊一下,Elasticsearch(ES)集群是如何搭建的. 2. 场景介 ...
- 实例展示elasticsearch集群生态,分片以及水平扩展.
elasticsearch用于构建高可用和可扩展的系统.扩展的方式可以是购买更好的服务器(纵向扩展)或者购买更多的服务器(横向扩展),Elasticsearch能从更强大的硬件中获得更好的性能,但是纵 ...
- mongodb3.6集群搭建:分片+副本集
mongodb是最常用的noSql数据库,在数据库排名中已经上升到了前五.这篇文章介绍如何搭建高可用的mongodb(分片+副本)集群. 在搭建集群之前,需要首先了解几个概念:路由,分片.副本集.配置 ...
- redis集群与分片(2)-Redis Cluster集群的搭建与实践
Redis Cluster集群 一.redis-cluster设计 Redis集群搭建的方式有多种,例如使用zookeeper等,但从redis 3.0之后版本支持redis-cluster集群,Re ...
- Mongodb集群与分片 1
分片集群 Mongodb中数据分片叫做chunk,它是一个Collection中的一个连续的数据记录,但是它有一个大小限制,不可以超过200M,如果超出产生新的分片. 下面是一个简单的分片集群 ...
- mongodb3.6集群搭建:分片集群认证
上篇集群已经创建,现在加入认证. 1. 生成密钥文件每个服务器上创建路径: mkdir -p /var/lib/mongo/auth 生成64字节的密钥文件openssl rand -base64 6 ...
- MongoDB集群搭建-分片
MongoDB集群搭建-分片 一.场景: 1,机器的磁盘不够用了.使用分片解决磁盘空间的问题. 2,单个mongod已经不能满足写数据的性能要求.通过分片让写压力分散到各个分片上面,使用分片服务器自身 ...
- redis(6)--redis集群之分片机制(redis-cluster)
Redis-Cluster 即使是使用哨兵,此时的Redis集群的每个数据库依然存有集群中的所有数据,从而导致集群的总数据存储量受限于可用存储内存最小的节点,形成了木桶效应.而因为Redis是基于内存 ...
- redis集群与分片(1)-redis服务器集群、客户端分片
下面是来自知乎大神的一段说明,个人觉得非常清晰,就收藏了. 为什么集群? 通常,为了提高网站响应速度,总是把热点数据保存在内存中而不是直接从后端数据库中读取.Redis是一个很好的Cache工具.大型 ...
随机推荐
- 「福利」Java Swing 编写的可视化算法工程,包含树、图和排序
之前在整理<学习排序算法,结合这个方法太容易理解了>这篇文章时,发现了一个用 Java Swing 编写的可视化算法工程,真心不错!包含了常用数据结构和算法的动态演示,先来张图感受下: 可 ...
- 解决plsql中文显示问号(???)问题
最近新买的电脑,配置好数据库连接后,plsql查看数据与插入中文数据都显示问号(???),同事的都正常显示,查看了很多资料,有的说是数据库字符集的原因让修改数据库的字符集,但是我的数据库都是远程连接正 ...
- moodle3.7中文语言包
Moodle官方有中文语言包,但是还有没有翻译的,为了提高用户体验,可以将部分未翻译的应用在Moodle网站管理中自己修改. 具体步骤: 先确定需要修改的关键字,也就是网站中没有翻译成中文的文字 在c ...
- vue chunk-elementUI.3d5a4739.js 过大,网页打开慢开启gzip压缩
如下 upstream sems { server weight= fail_timeout=; } server { listen ; server_name www.serve.com; loca ...
- python高级编程——网络编程(二)
UDP 概念和介绍 UDP --- 用户数据报协议,是一个无连接的简单的面向数据报的运输层协议. UDP不提供可靠性,它只是把应用程序传给IP层的数据报发送出去,但是并 不能保证它们能到达目的地. U ...
- 解决Eclipe安装不上android的ADT的办法
Eclipse,https://dl-ssl.google.com/android/eclipse/安装不上去,ADT在线安装装不了,用离线包又出问题时会不会疯掉. 显然,国内网络和谐掉了google ...
- Gin-Go学习笔记一:Hello World
Hello World 1> Gin是一个golang的微框架,封装比较优雅,API友好.具有快速灵活,容错方便等特点.Gin自身的net/http足够简单,性能也非常不错. 2> ...
- Nginx实现防盗链的方式
一.ngx_http_referer_module(阻挡来源非法的域名请求),配置如下: location ~.*\. (gif|jpg|png|flv|swf|rar|zip)$ { valid_r ...
- Jira未授权SSRF漏洞复现(CVE-2019-8451)
0x00 漏洞背景 Jira的/plugins/servlet/gadgets/makeRequest资源存在SSRF漏洞,原因在于JiraWhitelist这个类的逻辑缺陷,成功利用此漏洞的远程攻击 ...
- JavaScript正则表达式进阶指南
摘要:正则表达式是程序员的必备技能,想不想多学几招呢? 本文用JavaScript的exec方法来测试正则表达式. 例如,正则表达式**/F.*g/会匹配"以F开头,以g结尾的字符串&quo ...