查全率(Recall),查准率(Precision),灵敏性(Sensitivity),特异性(Specificity),F1,PR曲线,ROC,AUC的应用场景
之前介绍了这么多分类模型的性能评价指标(《分类模型的性能评价指标(Classification Model Performance Evaluation Metric)》),那么到底应该选择哪些指标来评估自己的模型呢?答案是应根据应用场景进行选择。
查全率(Recall):recall是相对真实的情况而言的:假设测试集里面有100个正类,如果模型预测出其中40个是正类,那模型的recall就是40%。查全率也称为召回率,等价于灵敏性(Sensitivity)和真正率(True Positive Rate,TPR)。

查全率的应用场景:需要尽可能地把所需的类别检测出来,而不在乎结果是否准确。比如对于地震的预测,我们希望每次地震都能被预测出来,这个时候可以牺牲precision。假如一共发生了10次地震,我们情愿发出1000次警报,这样能把这10次地震都涵盖进去(此时recall是100%,precision是1%),也不要发出100次警报,其中有8次地震给预测到了,但漏了2次(此时recall是80%,precision是8%)。
查准率(Precision):precision是相对模型的预测结果而言的:假设模型一共预测出了100个正类,其中80个是正确的,那么precision就是80%。
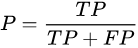
查准率的应用场景:需要尽可能地把所需的类别检测准确,而不在乎这些类别是否都被检测出来。比如对于罪犯的预测,我们希望预测结果是非常准确的,即使有时候放过了一些真正的罪犯,也不能错怪一个好人。
F1:F1 score是对查准率和查全率取平均,但是这里不是取算数平均,而是取调和平均。为什么?因为调和平均值更接近较小值,这样查准率或查全率中哪个值较小,调和平均值就更接近这个值,这样的测量指标更严格。
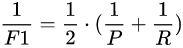
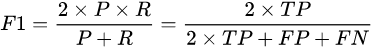 或
或 
F1的应用场景:在precision和recall两者要求同样高的情况下,可以用F1来衡量。
查全率和查准率是最常用的两个分类指标,除此之外人们还会用到以下一些指标:
(注:查全率在医学上经常被称为真阳性率(True Positive Rate,TPR),也就是正确检测出疾病的比例。)
假阳性率(False Positive Rate,FPR):在所有实际为负类的样本中,预测错误的比例,在医学上又称误诊率(没有病的人被检测出有病),等于 1 - 特异性(Specificity)。
FPR= FP / (FP + TN)
假阴性率(False Negative Rate,FNR):在所有实际为正类的样本中,预测错误的比例,在医学上又称漏诊率(有病的人没有被检测出来),等于 1 - 灵敏性(Sensitivity)。
FNR = FN /(TP + FN)
与recall和precision相互矛盾不同,TPR和FPR呈正相关关系,也就是说TPR增大,FPR也会变大。我们希望TPR能够越大越好(为1),FPR越小越好(为0),但这通常是不可能发生的。
在现实中,人们往往对查全率和查准率都有要求,但是会根据应用场景偏向某一边。比如做疾病检测,我们希望尽可能地把疾病检测出来,但同时也不想检测结果的准确率太低,因为这样会造成恐慌和不必要的医疗支出(偏向recall)。又比如对于垃圾邮件检测(Spam Detection),我们希望检测出的垃圾邮件肯定是垃圾邮件,而不希望把正常邮件邮件归为垃圾邮件,因为这样有可能会给客户造成很大的损失,但是相对地,如果我们经常把垃圾邮件归为正常邮件,虽然不会造成很大损失,但是会影响用户体验(偏向precision)。再比如如果是做搜索,搜出来的网页都和关键词相关才是好的搜索引擎,在这种情况下,我们希望precision高一些(偏向precision)。这时就要用到PR曲线。
PR曲线:x轴为查全率,y轴为查准率。
PR曲线的应用场景:需要根据需求找到对应的precision和recall值。如果偏向precison,那就是在保证recall的情况下提升precision;如果偏向recall,那就是在保证precision的情况下提升recall。比如对于欺诈检测(Fraud Detection),如果要求预测出的潜在欺诈人群尽可能准确,那么就要提高precision;而如果要尽可能多地预测出潜在的欺诈人群,那么就是要提高recall。一般来说,提高二分类模型的分类阈值就能提高precision,降低分类阈值就能提高 recall,这时便可观察PR 曲线,根据自己的需要,找到最优的分类阈值(threshold)。
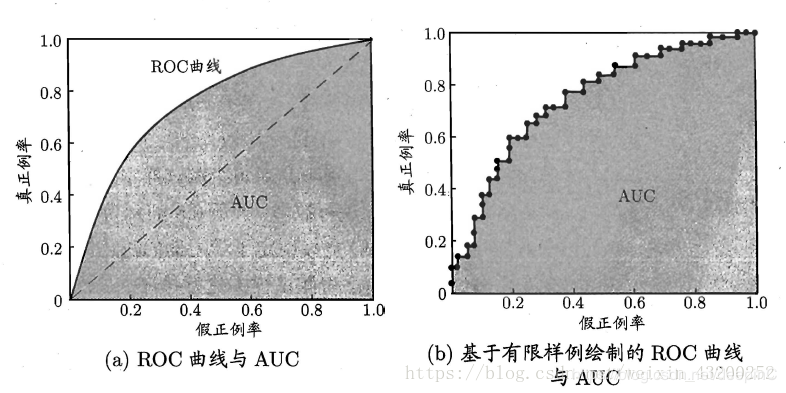
一般来说,模型的ROC-AUC值越大,模型的分类效果越好。不过如果两个模型AUC值差不多,并不代表这两个模型的效果相同。下面两幅图中两条ROC曲线相交于一点,AUC值几乎一样:当需要高Sensitivity时,模型A(细线)比B好;当需要高Speciticity时,模型B(粗线)比A好。

总结一下PR曲线和ROC曲线&AUC的区别:
1. 在正负样本差距不大的情况下,ROC曲线和PR曲线的趋势是差不多的,但是当正负样本相差悬殊的时候(通常负样本比正样本多很多),两者就截然不同了,在ROC曲线上的效果依然看似很好,但是在PR曲线上就效果一般了。这就说明对于类别不平衡问题,ROC曲线的表现会比较稳定(不会受不均衡数据的影响),但如果我们希望看出模型在正类上的表现效果,还是用PR曲线更好,因为此时ROC曲线通常会给出一个过于乐观的效果估计。
2. ROC曲线由于兼顾正例与负例,适用于评估分类器的整体性能(通常是计算AUC,表示模型的排序性能);PR曲线则完全聚焦于正例,因此如果我们主要关心的是正例,那么用PR曲线比较好。
3. ROC曲线不会随着类别分布的改变而改变。然而,这一特性在一定程度上也是其缺点。因此需要根据不用的场景进行选择:比如对于欺诈检测,每个月正例和负例的比例可能都不相同,这时候如果只想看一下分类器的整体性能是否稳定,则用ROC曲线比较合适,因为类别分布的改变可能使得PR曲线发生变化,这种时候难以进行模型性能的比较;反之,如果想测试不同的类别分布对分类器性能的影响,则用PR曲线比较合适。
总的来说,我们应该根据具体的应用场景,在相应的曲线上找到最优的点,得到相对应的precision,recall,f1 score等指标,然后去调整模型的分类阈值,从而得到一个符合具体应用的模型。
附:
如何画PR曲线?
根据每个测试样本属于正样本的概率值从大到小排序,依次将这些概率值作为分类阈值,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。每次选取一个不同的threshold,我们就可以得到一组recall和precision,即PR曲线上的一点。取n组不同的分类阈值,就可以得到n个点,连接起来就成为一条曲线。threshold取值越多,PR曲线越平滑。
如何画ROC曲线?
根据每个测试样本属于正样本的概率值从大到小排序,依次将这些概率值作为分类阈值,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。取n组不同的分类阈值,就可以得到n个点,连接起来就成为一条曲线。threshold取值越多,ROC曲线越平滑。
如何计算AUC值?
假定ROC曲线是由坐标为 的点按序连接而形成,则AUC可估算为:

查全率(Recall),查准率(Precision),灵敏性(Sensitivity),特异性(Specificity),F1,PR曲线,ROC,AUC的应用场景的更多相关文章
- 敏感性、特异性、假阳性、假阴性(sensitivity and specificity)
医学.机器学习等等,在统计结果时时长会用到这两个指标来说明数据的特性. 定义 敏感性:在金标准判断有病(阳性)人群中,检测出阳性的几率.真阳性.(检测出确实有病的能力) 特异性:在金标准判断无病(阴性 ...
- 混淆矩阵、准确率、精确率/查准率、召回率/查全率、F1值、ROC曲线的AUC值
准确率.精确率(查准率).召回率(查全率).F1值.ROC曲线的AUC值,都可以作为评价一个机器学习模型好坏的指标(evaluation metrics),而这些评价指标直接或间接都与混淆矩阵有关,前 ...
- Precision/Recall、ROC/AUC、AP/MAP等概念区分
1. Precision和Recall Precision,准确率/查准率.Recall,召回率/查全率.这两个指标分别以两个角度衡量分类系统的准确率. 例如,有一个池塘,里面共有1000条鱼,含10 ...
- ROC曲线、AUC、Precision、Recall、F-measure理解及Python实现
本文首先从整体上介绍ROC曲线.AUC.Precision.Recall以及F-measure,然后介绍上述这些评价指标的有趣特性,最后给出ROC曲线的一个Python实现示例. 一.ROC曲线.AU ...
- 机器学习常见的几种评价指标:精确率(Precision)、召回率(Recall)、F值(F-measure)、ROC曲线、AUC、准确率(Accuracy)
原文链接:https://blog.csdn.net/weixin_42518879/article/details/83959319 主要内容:机器学习中常见的几种评价指标,它们各自的含义和计算(注 ...
- Mean Average Precision(mAP),Precision,Recall,Accuracy,F1_score,PR曲线、ROC曲线,AUC值,决定系数R^2 的含义与计算
背景 之前在研究Object Detection的时候,只是知道Precision这个指标,但是mAP(mean Average Precision)具体是如何计算的,暂时还不知道.最近做OD的任 ...
- 【计算机视觉】目标检测中的指标衡量Recall与Precision
[计算机视觉]目标检测中的指标衡量Recall与Precision 标签(空格分隔): [图像处理] 说明:目标检测性能指标Recall与Precision的理解. Recall与Precision ...
- PR曲线,ROC曲线,AUC指标等,Accuracy vs Precision
作为机器学习重要的评价指标,标题中的三个内容,在下面读书笔记里面都有讲: http://www.cnblogs.com/charlesblc/p/6188562.html 但是讲的不细,不太懂.今天又 ...
- sensitivity and specificity(敏感性和特异性)
医学.机器学习等等,在统计结果时时长会用到这两个指标来说明数据的特性.
随机推荐
- VMware学习笔记之在虚拟机中使用Ghost系统盘安装xp黑屏卡在光标闪无法进入系统
使用ghost安装后,无法进入系统,卡在光标闪动,请参考如下: https://www.cnblogs.com/mq0036/p/3588058.html https://wenku.baidu.co ...
- Macvlan 和 IPvlan
介绍 macvlan 本身是 linxu kernel 模块,其功能是允许在同一个物理网卡上配置多个 MAC 地址,即多个 interface,每个 interface 可以配置自己的 IP.macv ...
- mysql-数据库查询语句汇总
目录 数据库查询语句 ***** 添加数据补充: 所有的select 关键字 where 条件 distinct 去除重复记录 指定字段 取别名 group by having order limit ...
- 自学Python编程的第三天----------来自苦逼的转行人
2019-09-14 11:09:50 学Python的第三天和写博客的第三天 本来第三天的内容前天就应该发的,但是因为有点难度,用了两天的时间去学习,按道也是昨天发, 因为中秋导致今天早上发,第三天 ...
- sense chrome扩展工具安装问题
下载一个chrome的插件,只能在国内下了.有个什么插件网 .下载完之后是 .crx 格式的.直接拖到 chrome的扩展工具里,显示,插件有问题.无语 参考了一个网上的教程. 1.先将扩展名 .c ...
- That IP address can't be assigned to.的问题
That IP address can't be assigned to. 烦恼了很久,现在知道了,解决的办法如下 首先确定端口号是不是开放,阿里云的直接在控制台修改 其次 看看 你的地址是不是输入错 ...
- js正则表达式(七)
一.正则表达式对象的创建方法一:使用构造函数的形式: var pattern = new RegExp('正则表达式','修饰符'); var pattern = new RegExp('hello' ...
- react学习记录(二)
JSX 在render中return标签的部分可以插入字符串,数字,数组 class Welcome extends React.Component { render(){ return ( < ...
- 前端构建工具 Gulp 压缩合并JS/CSS 并添加版本号、ES6转ES5
Gulp 基于 Node.js 的前端构建工具,可以实现前端代码的编译(sass.less).压缩合并(JS.CSS).测试:图片的压缩:已经添加 JS 和 CSS 版本号,防止浏览器缓存. 1. 安 ...
- 《我是一只IT小小鸟》读书笔记——第七周
我是一只IT小小鸟,每一个程序员都是从这样的阶段成长起来的,问题是是否能一开始就找到正确的路径,少走弯路.本书收集了许多年轻程序员从大学开始到就业的成长之路,十分有指导价值也很让人深思. 切忌急功近利 ...