MySQL实战45讲学习笔记:第一讲
一、MySQL逻架构图
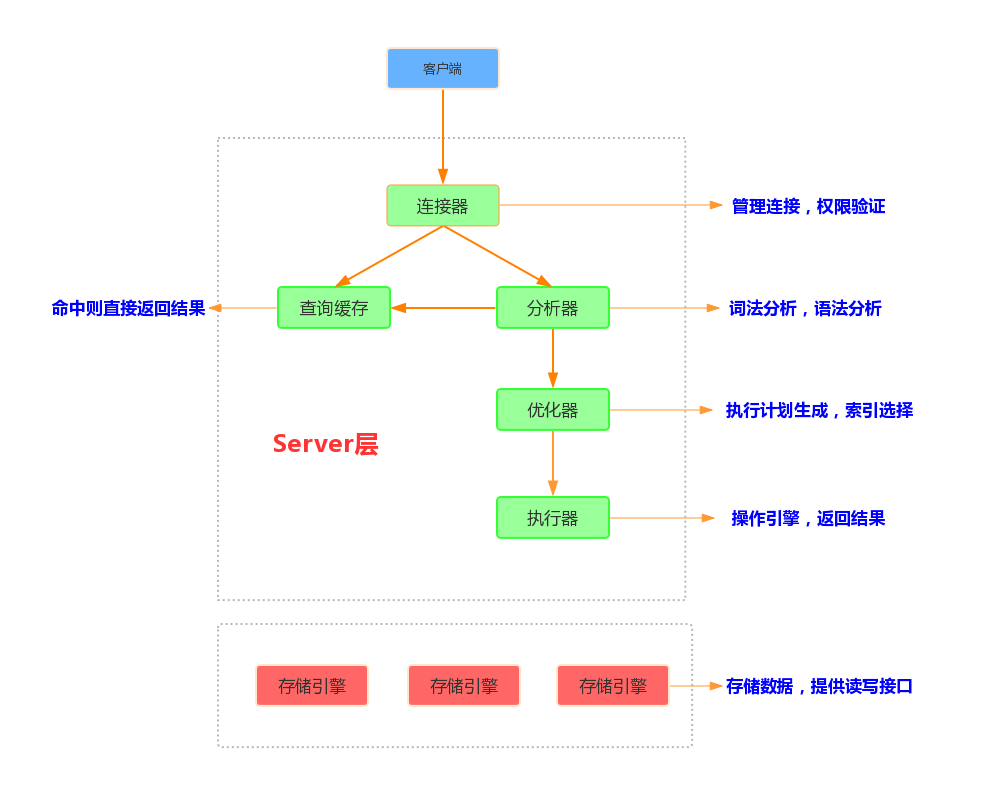
二、连接器工作原理刨析
1、连接器工作原理图
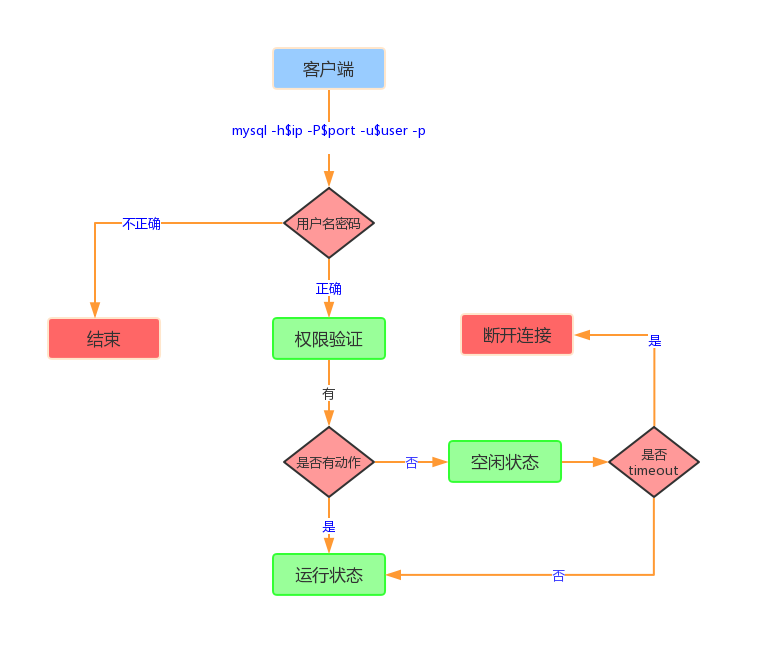
2、原理图说明
1、连接命令
mysql -h$ip -P$port -u$user -p
2、查询链接状态

3、长连接端连接
1、什么是长链接?
数据库里面,长连接是连接成功后,如果客户端持续有请求,则一直使用同一个链接。
2、什么是短连接?
短连接则是指每次执行完很少的几次查询就断开连接,下次查询重新建立一个
3、尽量使用长链接
建立连接的过程通常是比较复杂的,所以我建议你在使用中尽量减少建立的动作,也就是使用长连接
三、使用长链接困惑及解决方案
1、为什么MySQL占用内存涨得特别快
但是全部是用长连接后,你可能会发现,有些时候MySQL占用内存涨得特别快,
这是因为MySQL在执行过程中临时使用的内存管理在连接对象里面的,这些资源会在连接断开的时候才释放,
所以如果长链接积累下来,可能导致内存占用大,被系统强行杀掉,从现象看就是MySQL异常重启了
2、如何解决MySQL占用内存涨得特别快
1、定期断开长链接,使用一段时间,或者程序里面判断执行过一个占用内存的大查询后,断开连接,之后要查询再连接
2、如果你用的是MySQL5.7或更新版本,可以在每次执行一个比较大的操作后,通过执行
mysql_reset_connection
来重新初始化连接资源,这个过程不需要重连或重新做权限验证,但是会将连接回复到刚刚创建完时的状态
四、查询缓存
1、工作流程刨析图解
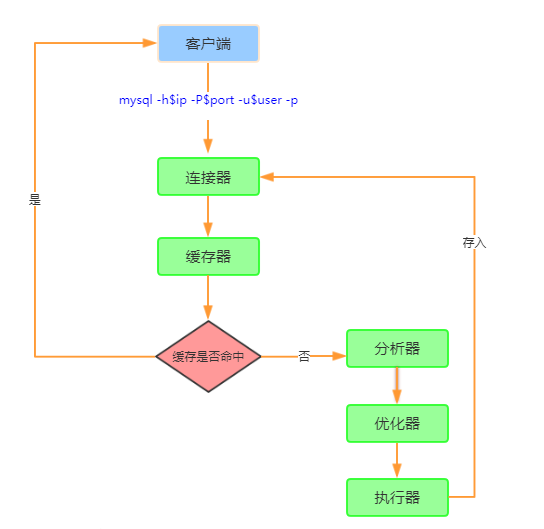
- MySQL拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句,如果有,就直接返回给客户端
- 如果语句不在查询缓存中,就会继续后面的执行阶段。
- 执行完成后,执行结果会被存入查询缓存中,
- 如果查询命中缓存MySQL不需要执行后面的复杂操作,就可以直接返回结果,这个效率会很高
2、为什么大多数情况下比建议使用查询缓存?
1、查询缓存的失效非常频繁,只要有一个表更新,这个表上所有的查询缓存都被清空
2、对于更新压力大的数据库来说,查询缓存的命中率会非常低,
3、除非你的业务就是有一张静态表,很长时间才会更新一次(比如一个系统配置表)
1、默认语句不实用查询缓存
MySQL提供的按需使用的方式
query_cache_type 设置成 DEMAND
2、确定需要查询缓存的语句
mysql> select SQL_CACHE * from T where ID=10;
MySQL 8.0 版本直接将查询缓存的整块功能删掉了,也就是说 8.0 开始彻底没有这个功能了。
五、分析器
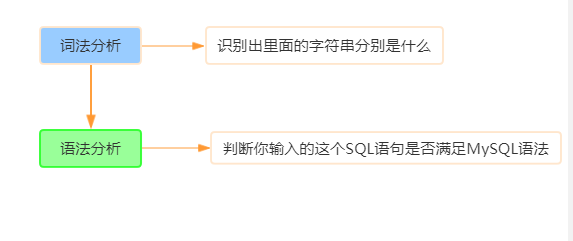
如果你的语句不对,就会收到“You have an error in your SQL syntax”的错误提醒,
比如下面这个语句select 少打了开头的字母“s”
mysql> elect * from t where ID=1;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to
your MySQL server version for the right syntax to use near 'elect * from t where ID=1' at line 1
一般语法错误会提示第一个出现错误的位置,所以你要关注的是紧接"use naar"的内容
六、优化器
1、优化器的作用
1、在表里面有多个索引的时候,决定使用哪个索引
2、多表关联(ioin)的时候,决定各个表的链接顺序
2、举例说明
mysql> select * from t1 join t2 using(ID) where t1.c=10 and t2.d=20;
既可以先从表 t1 里面取出 c=10 的记录的 ID 值,再根据 ID 值关联到表 t2,再判断 t2 里面 d 的值是否等于20
也可以先从表 t2 里面取出 d=20 的记录的 ID 值,再根据 ID 值关联到 t1,再判断 t1 里面 c 的值是否等于10
这两种执行方法的逻辑结果时一样的,但是执行的效率会有不同,而优化器的作用就是决定选择哪一个方案
七、执行器
1、工作原理
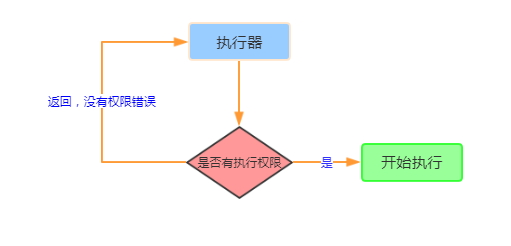
2、举例说明
1、没有索引的执行流程
1、调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是1,如果不是则跳过,如果是则将这行存在结果集中
2、调用引擎接口取"下一行",重复相同的判断逻辑,直到取到这个表的最后一行
3、执行器将上述遍布过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
2、有索引的执行流程
第一调用的是"取满足条件的第一行"这个接口,
之后循环取"满足条件的下一行"
引擎扫描行数跟rows_examined并不是完全相同的
八、思考题
1、题目
如果表 T 中没有字段 k,而你执行了这个语句 select* from T where k=1, 那肯定是会报“不存在这个列”的错误:
“Unknown column ‘k’ iin ‘where clause’”。
你觉得这个错误是在我们上面提到的哪个阶段报出来的呢?
2、答案
作者回复: “不是执行器”这一点,你分析得很好
MySQL实战45讲学习笔记:第一讲的更多相关文章
- mybatis学习笔记第一讲
第一步:先配置mybatis配置 <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE confi ...
- 初探 Elasticsearch,学习笔记第一讲
1. ES 基础 1.1 ES定义 ES=elaticsearch简写, Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储.检索数据:本身扩展 ...
- Python学习笔记第一讲
1.pycharm快捷键 撤销与反撤销:Ctrl + z,Ctrl + Shift + z 缩进.不缩进:Tab.Shift + tab 运行:Shift + F10 取消注释,行注释:Ctrl + ...
- 深挖计算机基础:MySQL实战45讲学习笔记
参考极客时间专栏<MySQL实战45讲>学习笔记 一.基础篇(8讲) MySQL实战45讲学习笔记:第一讲 MySQL实战45讲学习笔记:第二讲 MySQL实战45讲学习笔记:第三讲 My ...
- MySQL实战45讲学习笔记:第三十九讲
一.本节概况 MySQL实战45讲学习笔记:自增主键为什么不是连续的?(第39讲) 在第 4 篇文章中,我们提到过自增主键,由于自增主键可以让主键索引尽量地保持递增顺序插入,避免了页分裂,因此索引更紧 ...
- 《MySQL实战45讲》学习笔记1——MySQL的基础架构
在<极客时间>订阅了<MySQL实战45讲>专栏,总觉得看完和没看一样
- 极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间
极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间 笔记体会: 方案一,事务相 ...
- Mysql实战45讲 05讲深入浅出索引(下)极客时间 读书笔记
极客时间 Mysql实战45讲 04讲深入浅出索引(下)极客时间 笔记体会: 回表:回到主键索引树搜索的过程,称为回表覆盖索引:某索引已经覆盖了查询需求,称为覆盖索引,例如:select ID fro ...
- Mysql实战45讲 04讲深入浅出索引(上)读书笔记 极客时间
极客时间 Mysql实战45讲 04讲深入浅出索引 极客时间(上)读书笔记 笔记体悟 1.索引的作用:提高数据查询效率2.常见索引模型:哈希表.有序数组.搜索树3.哈希表:键 - 值(key - v ...
- 《MySQL实战45讲》(1-7)笔记
<MySQL实战45讲>笔记 目录 <MySQL实战45讲>笔记 第一节: 基础架构:一条SQL查询语句是如何执行的? 连接器 查询缓存 分析器 优化器 执行器 第二节:日志系 ...
随机推荐
- LeetCode 733: 图像渲染 flood-fill
题目: 有一幅以二维整数数组表示的图画,每一个整数表示该图画的像素值大小,数值在 0 到 65535 之间. An image is represented by a 2-D array of int ...
- PHP 中的关于 trait 的简单
什么是 trait 看看 PHP 官网的介绍. 自 PHP 5.4.0 起,PHP 实现了一种代码复用的方法,称为 trait. Trait 是为类似 PHP 的单继承语言而准备的一种代码复用机制.T ...
- ThinkPHP 3.2 自定义基类 Model
ThinkPHP 提供了一个 Model 类,供其他的 Model 进行继承.Model 类中是 MVC 中的模型类,它是调用 持久层 的上层类.感觉这么描述问题很多,但是有什么办法呢?但是,这个 M ...
- Jsp自学1
jsp学习之初,我是用记事本(EditPlus)来进行编辑的,那么写好的jsp文件如何执行看到效果呢?不像html文件可以直接用浏览器打开,jsp文件需要先进行编译器的编译才能执行,而Tomcat就可 ...
- css不常用的4个选择器-个人向
①:element1.element2(给同时满足有element1和element2 2个类名的元素添加样式) <!DOCTYPE html> <html> <head ...
- Java 使用Navicat连接MySQL出现2059错误
今天使用navicat链接mysql的时候报了2059的错误,找了很久才找到解决方法,这里记录一下.出现2059这个错误的原因是在mysql8之前的版本中加密规则为mysql_native_passw ...
- MySQL出现Waiting for table metadata lock的原因以及解决方法(转)
MySQL在进行alter table等DDL操作时,有时会出现Waiting for table metadata lock的等待场景.而且,一旦alter table TableA的操作停滞在Wa ...
- Winforn中设置ZedGraph多条Y轴时曲线刻度不均匀问题解决
场景 Winform中实现ZedGraph的多条Y轴(附源码下载): https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/1001322 ...
- 【转】测试开发工程师必备软硬能力&高级测试开发工程师需要具备什么能力?
对于测试的基本知识,可以查看软件测试相关书籍 对于在公司成为一位优秀的测试开发工程师,我觉得下面这篇文章涉及到的是我们需要的,稍微进行改动https://blog.csdn.net/sinat_210 ...
- Java学习——单元测试JUnit
Java学习——单元测试JUnit 摘要:本文主要介绍了什么是单元测试以及怎么进行单元测试. 部分内容来自以下博客: https://www.cnblogs.com/wxisme/p/4779193. ...