MySQL实战45讲学习笔记:第十八讲
一、引子
在 MySQL 中,有很多看上去逻辑相同,但性能却差异巨大的 SQL 语句。对这些语句使用不当的话,就会不经意间导致整个数据库的压力变大。
我今天挑选了三个这样的案例和你分享。希望再遇到相似的问题时,你可以做到举一反三、快速解决问题。
二、案例一:条件字段函数操作
假设你现在维护了一个交易系统,其中交易记录表 tradelog 包含交易流水号(tradeid)、交易员 id(operator)、交易时间(t_modified)等字段。为了便于描
述,我们先忽略其他字段。这个表的建表语句如下:
mysql> CREATE TABLE `tradelog` (
`id` int(11) NOT NULL,
`tradeid` varchar(32) DEFAULT NULL,
`operator` int(11) DEFAULT NULL,
`t_modified` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `tradeid` (`tradeid`),
KEY `t_modified` (`t_modified`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
假设,现在已经记录了从 2016 年初到 2018 年底的所有数据,运营部门有一个需求是,要统计发生在所有年份中 7 月份的交易记录总数。这个逻辑看上去并不复杂,你的 SQL
语句可能会这么写:
mysql> select count(*) from tradelog where month(t_modified)=7;
由于 t_modified 字段上有索引,于是你就很放心地在生产库中执行了这条语句,但却发现执行了特别久,才返回了结果。
1、如果对字段做了函数计算,就用不上索引了,这是 MySQL 的规定。
如果你问 DBA 同事为什么会出现这样的情况,他大概会告诉你:如果对字段做了函数计算,就用不上索引了,这是 MySQL 的规定。
2、为什么条件是 wheret_modified='2018-7-1’的时候可以用上索引,而改成 where month(t_modified)=7的时候就不行了?
现在你已经学过了 InnoDB 的索引结构了,可以再追问一句为什么?为什么条件是 wheret_modified='2018-7-1’的时候可以用上索引,而改成 where month(t_modified)=7
的时候就不行了?
下面是这个 t_modified 索引的示意图。方框上面的数字就是 month() 函数对应的值。
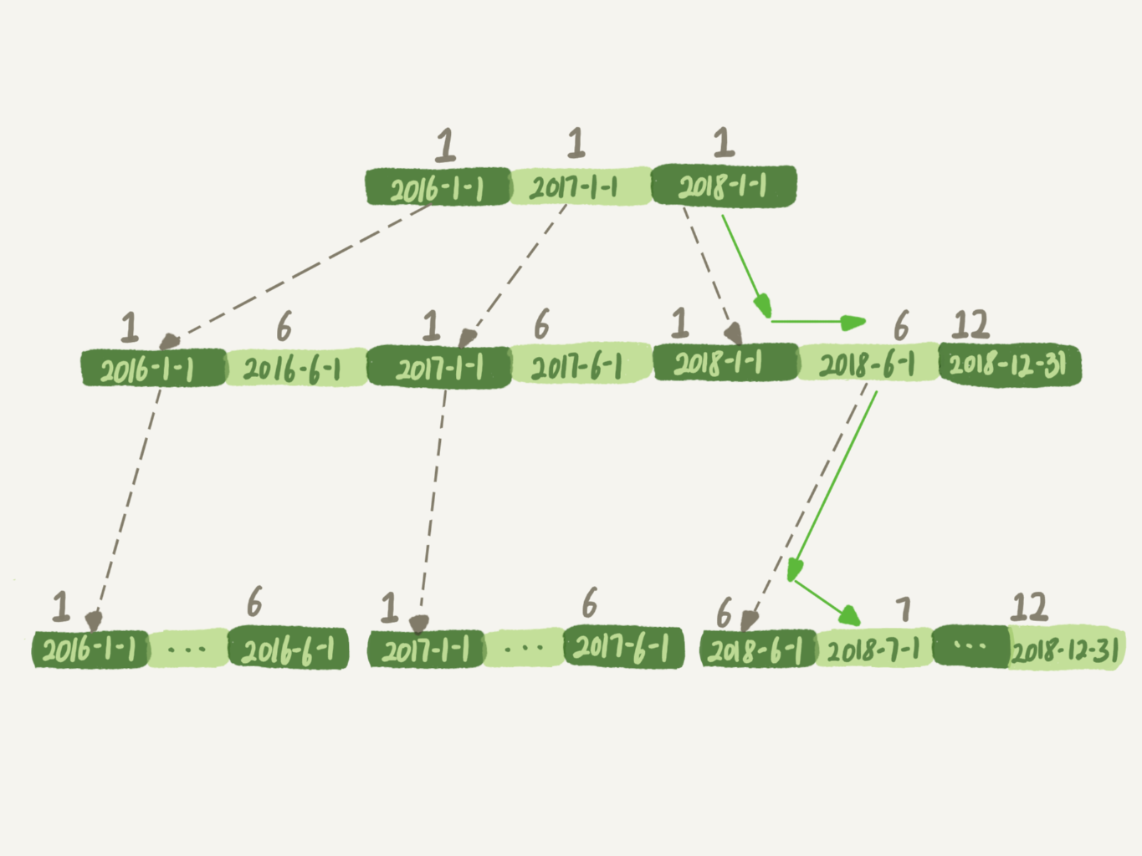
图 1 t_modified 索引示意图
如果你的 SQL 语句条件用的是 where t_modified='2018-7-1’的话,引擎就会按照上面绿色箭头的路线,快速定位到 t_modified='2018-7-1’需要的结果。
实际上,B+ 树提供的这个快速定位能力,来源于同一层兄弟节点的有序性。
但是,如果计算 month() 函数的话,你会看到传入 7 的时候,在树的第一层就不知道该怎么办了。
也就是说,对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。
3、优化器并不是要放弃使用这个索引。
需要注意的是,优化器并不是要放弃使用这个索引。
在这个例子里,放弃了树搜索功能,优化器可以选择遍历主键索引,也可以选择遍历索引
t_modified,优化器对比索引大小后发现,索引 t_modified 更小,遍历这个索引比遍历
主键索引来得更快。因此最终还是会选择索引 t_modified。
接下来,我们使用 explain 命令,查看一下这条 SQL 语句的执行结果。

图 2 explain 结果
key="t_modified"表示的是,使用了 t_modified 这个索引;我在测试表数据中插入了10 万行数据,rows=100335,说明这条语句扫描了整个索引的所有值;Extra 字段的
Using index,表示的是使用了覆盖索引。
也就是说,由于在 t_modified 字段加了 month() 函数操作,导致了全索引扫描。为了能够用上索引的快速定位能力,我们就要把 SQL 语句改成基于字段本身的范围查询。按照下
面这个写法,优化器就能按照我们预期的,用上 t_modified 索引的快速定位能力了。
mysql> select count(*) from tradelog where
-> (t_modified >= '2016-7-1' and t_modified<'2016-8-1') or
-> (t_modified >= '2017-7-1' and t_modified<'2017-8-1') or
-> (t_modified >= '2018-7-1' and t_modified<'2018-8-1');
当然,如果你的系统上线时间更早,或者后面又插入了之后年份的数据的话,你就需要再把其他年份补齐。
到这里我给你说明了,由于加了 month() 函数操作,MySQL 无法再使用索引快速定位功能,而只能使用全索引扫描。
不过优化器在个问题上确实有“偷懒”行为,即使是对于不改变有序性的函数,也不会考虑使用索引。比如,对于 select * from tradelog where id + 1 = 10000 这个 SQL 语
句,这个加 1 操作并不会改变有序性,但是 MySQL 优化器还是不能用 id 索引快速定位到 9999 这一行。所以,需要你在写 SQL 语句的时候,手动改写成 where id = 10000 -1
才可以。
三、案例二:隐式类型转换
接下来我再跟你说一说,另一个经常让程序员掉坑里的例子。
我们一起看一下这条 SQL 语句:
mysql> select * from tradelog where tradeid=110717;
1、数据类型转换的规则是什么?
交易编号 tradeid 这个字段上,本来就有索引,但是 explain 的结果却显示,这条语句需要走全表扫描。你可能也发现了,tradeid 的字段类型是 varchar(32),而输入的参数却是
整型,所以需要做类型转换。
那么,现在这里就有两个问题:
- 1. 数据类型转换的规则是什么?
- 2. 为什么有数据类型转换,就需要走全索引扫描?
先来看第一个问题,你可能会说,数据库里面类型这么多,这种数据类型转换规则更多,我记不住,应该怎么办呢?
这里有一个简单的方法,看 select “10” > 9 的结果:
1. 如果规则是“将字符串转成数字”,那么就是做数字比较,结果应该是 1;
2. 如果规则是“将数字转成字符串”,那么就是做字符串比较,结果应该是 0。

验证结果如图 3 所示。
实际测试代码如下:
mysql> mysql> select "10" > 9;
+----------+
| "10" > 9 |
+----------+
| 1 |
+----------+
1 row in set (0.00 sec)
图 3 MySQL 中字符串和数字转换的效果示意图
从图中可知,select “10” > 9 返回的是 1,所以你就能确认 MySQL 里的转换规则了:在 MySQL 中,字符串和数字做比较的话,是将字符串转换成数字。
2、为什么有数据类型转换,就需要走全索引扫描?
这时,你再看这个全表扫描的语句:
mysql> select * from tradelog where tradeid=110717;
实际测试代码与截图如下:
mysql> explain select * from tradelog where tradeid=110717;
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | tradelog | NULL | ALL | tradeid | NULL | NULL | NULL | 3 | 33.33 | Using where |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 3 warnings (0.00 sec)
就知道对于优化器来说,这个语句相当于:
mysql> select * from tradelog where CAST(tradid AS signed int) = 110717;
也就是说,这条语句触发了我们上面说到的规则:对索引字段做函数操作,优化器会放弃走树搜索功能。
现在,我留给你一个小问题,id 的类型是 int,如果执行下面这个语句,是否会导致全表扫描呢?
select * from tradelog where id="83126";
你可以先自己分析一下,再到数据库里面去验证确认。接下来,我们再来看一个稍微复杂点的例子。
四、案例三:隐式字符编码转换
假设系统里还有另外一个表 trade_detail,用于记录交易的操作细节。为了便于量化分析和复现,我往交易日志表 tradelog 和交易详情表 trade_detail 这两个表里插入一些数据。
mysql> CREATE TABLE `trade_detail` (
`id` int(11) NOT NULL,
`tradeid` varchar(32) DEFAULT NULL,
`trade_step` int(11) DEFAULT NULL, /* 操作步骤 */
`step_info` varchar(32) DEFAULT NULL, /* 步骤信息 */
PRIMARY KEY (`id`),
KEY `tradeid` (`tradeid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into tradelog values(1, 'aaaaaaaa', 1000, now());
insert into tradelog values(2, 'aaaaaaab', 1000, now());
insert into tradelog values(3, 'aaaaaaac', 1000, now()); insert into trade_detail values(1, 'aaaaaaaa', 1, 'add');
insert into trade_detail values(2, 'aaaaaaaa', 2, 'update');
insert into trade_detail values(3, 'aaaaaaaa', 3, 'commit');
insert into trade_detail values(4, 'aaaaaaab', 1, 'add');
insert into trade_detail values(5, 'aaaaaaab', 2, 'update');
insert into trade_detail values(6, 'aaaaaaab', 3, 'update again');
insert into trade_detail values(7, 'aaaaaaab', 4, 'commit');
insert into trade_detail values(8, 'aaaaaaac', 1, 'add');
insert into trade_detail values(9, 'aaaaaaac', 2, 'update');
insert into trade_detail values(10, 'aaaaaaac', 3, 'update again');
insert into trade_detail values(11, 'aaaaaaac', 4, 'commit')
这时候,如果要查询 id=2 的交易的所有操作步骤信息,SQL 语句可以这么写:
mysql> select d.* from tradelog l, trade_detail d where d.tradeid=l.tradeid and l.id=2; /* 语句 Q1*/

图 4 语句 Q1 的 explain 结果
实际测试代码如下:
mysql> explain select d.* from tradelog l, trade_detail d where d.tradeid=l.tradeid and l.id=2;
+----+-------------+-------+------------+-------+-----------------+---------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+-----------------+---------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | l | NULL | const | PRIMARY,tradeid | PRIMARY | 4 | const | 1 | 100.00 | NULL |
| 1 | SIMPLE | d | NULL | ALL | NULL | NULL | NULL | NULL | 11 | 100.00 | Using where |
+----+-------------+-------+------------+-------+-----------------+---------+---------+-------+------+----------+-------------+
2 rows in set, 1 warning (0.01 sec)
我们一起来看下这个结果:
- 1. 第一行显示优化器会先在交易记录表 tradelog 上查到 id=2 的行,这个步骤用上了主键索引,rows=1 表示只扫描一行;
- 2. 第二行 key=NULL,表示没有用上交易详情表 trade_detail 上的 tradeid 索引,进行了全表扫描。
在这个执行计划里,是从 tradelog 表中取 tradeid 字段,再去 trade_detail 表里查询匹配字段。因此,我们把 tradelog 称为驱动表,把 trade_detail 称为被驱动表,把 tradeid
称为关联字段。
1、语句 Q1 的执行过程
接下来,我们看下这个 explain 结果表示的执行流程:
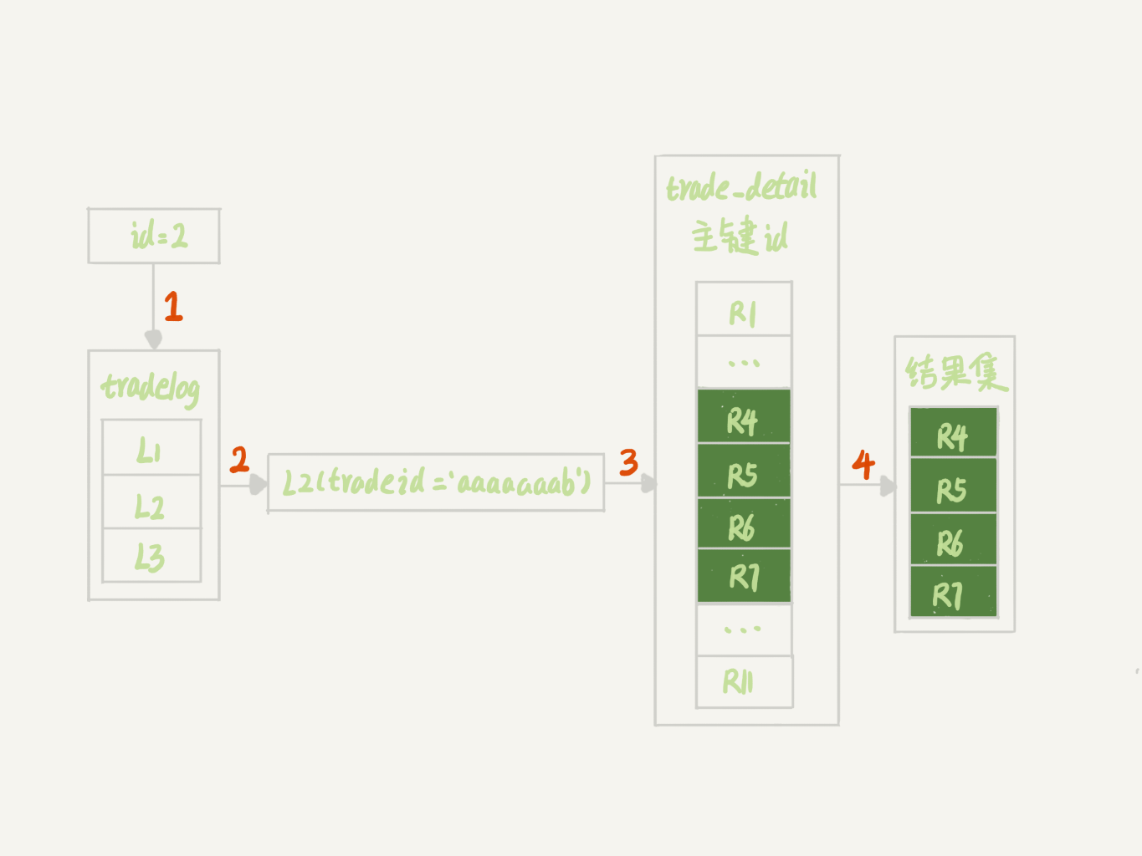
图 5 语句 Q1 的执行过程
第 1 步,是根据 id 在 tradelog 表里找到 L2 这一行;
第 2 步,是从 L2 中取出 tradeid 字段的值;
第 3 步:是根据 tradeid 值到 trade_detail 表中查找条件匹配的行。explain 的结果里面第二行的 key=NULL 表示的就是,这个过程是通过遍历主键索引的方式,一个一个地判断 tradeid 的值是否匹配。
进行到这里,你会发现第 3 步不符合我们的预期。因为表 trade_detail 里 tradeid 字段上是有索引的,我们本来是希望通过使用 tradeid 索引能够快速定位到等值的行。但,这里并没有。
2、两个表的字符集不同所以做表连接查询的时候用不上关联字段的索引
如果你去问 DBA 同学,他们可能会告诉你,因为这两个表的字符集不同,一个是 utf8,一个是 utf8mb4,所以做表连接查询的时候用不上关联字段的索引。这个回答,也是通常
你搜索这个问题时会得到的答案。
但是你应该再追问一下,为什么字符集不同就用不上索引呢?
我们说问题是出在执行步骤的第 3 步,如果单独把这一步改成 SQL 语句的话,那就是:
mysql> select * from trade_detail where tradeid=$L2.tradeid.value;
其中,$L2.tradeid.value 的字符集是 utf8mb4。
参照前面的两个例子,你肯定就想到了,字符集 utf8mb4 是 utf8 的超集,所以当这两个类型的字符串在做比较的时候,MySQL 内部的操作是,先把 utf8 字符串转成 utf8mb4
字符集,再做比较。
这个设定很好理解,utf8mb4 是 utf8 的超集。类似地,在程序设计语言里面,做自动类型转换的时候,为了避免数据在转换过程中由于截断导致数据
错误,也都是“按数据长度增加的方向”进行转换的。
因此, 在执行上面这个语句的时候,需要将被驱动数据表里的字段一个个地转换成utf8mb4,再跟 L2 做比较。
也就是说,实际上这个语句等同于下面这个写法:
select * from trade_detail where CONVERT(traideid USING utf8mb4)=$L2.tradeid.value;
CONVERT() 函数,在这里的意思是把输入的字符串转成 utf8mb4 字符集。这就再次触发了我们上面说到的原则:对索引字段做函数操作,优化器会放弃走树搜索功能。
到这里,你终于明确了,字符集不同只是条件之一,连接过程中要求在被驱动表的索引字段上加函数操作,是直接导致对被驱动表做全表扫描的原因。
3、连接过程中要求在被驱动表的索引字段上加函数操作
作为对比验证,我给你提另外一个需求,“查找 trade_detail 表里 id=4 的操作,对应的操作者是谁”,再来看下这个语句和它的执行计划。
mysql>select l.operator from tradelog l , trade_detail d where d.tradeid=l.tradeid and d.id=4;

图 6 explain 结果
实际测试代码如下:
mysql> explain select l.operator from tradelog l , trade_detail d where d.tradeid=l.tradeid and d.id=4;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | d | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
| 1 | SIMPLE | l | NULL | ref | tradeid | tradeid | 131 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
2 rows in set, 1 warning (0.00 sec)
这个语句里 trade_detail 表成了驱动表,但是 explain 结果的第二行显示,这次的查询操作用上了被驱动表 tradelog 里的索引 (tradeid),扫描行数是 1。
这也是两个 tradeid 字段的 join 操作,为什么这次能用上被驱动表的 tradeid 索引呢?我们来分析一下。
假设驱动表 trade_detail 里 id=4 的行记为 R4,那么在连接的时候(图 5 的第 3 步),
被驱动表 tradelog 上执行的就是类似这样的 SQL 语句:
select operator from tradelog where traideid =$R4.tradeid.value;
这时候 $R4.tradeid.value 的字符集是 utf8, 按照字符集转换规则,要转成 utf8mb4,所以这个过程就被改写成:
select operator from tradelog where traideid =CONVERT($R4.tradeid.value USING utf8mb4);
你看,这里的 CONVERT 函数是加在输入参数上的,这样就可以用上被驱动表的 traideid索引。
理解了原理以后,就可以用来指导操作了。如果要优化语句
select d.* from tradelog l, trade_detail d where d.tradeid=l.tradeid and l.id=2;
的执行过程,有两种做法:
比较常见的优化方法是,把 trade_detail 表上的 tradeid 字段的字符集也改成utf8mb4,这样就没有字符集转换的问题了。
alter table trade_detail modify tradeid varchar(32) CHARACTER SET utf8mb4 default null;
如果能够修改字段的字符集的话,是最好不过了。但如果数据量比较大, 或者业务上暂时不能做这个 DDL 的话,那就只能采用修改 SQL 语句的方法了。
mysql> select d.* from tradelog l , trade_detail d where d.tradeid=CONVERT(l.tradeid USING utf8) and l.id=2;

图 7 SQL 语句优化后的 explain 结果
实际测试代码如下:
mysql> explain select d.* from tradelog l , trade_detail d where d.tradeid=CONVERT(l.tradeid USING utf8) and l.id=2;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | l | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
| 1 | SIMPLE | d | NULL | ref | tradeid | tradeid | 99 | const | 4 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
2 rows in set, 1 warning (0.01 sec)
这里,我主动把 l.tradeid 转成 utf8,就避免了被驱动表上的字符编码转换,从 explain结果可以看到,这次索引走对了。
五、小结
今天我给你举了三个例子,其实是在说同一件事儿,即:对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。
第二个例子是隐式类型转换,第三个例子是隐式字符编码转换,它们都跟第一个例子一样,因为要求在索引字段上做函数操作而导致了全索引扫描。
MySQL 的优化器确实有“偷懒”的嫌疑,即使简单地把 where id+1=1000 改写成where id=1000-1 就能够用上索引快速查找,也不会主动做这个语句重写。
因此,每次你的业务代码升级时,把可能出现的、新的 SQL 语句 explain 一下,是一个很好的习惯。
最后,又到了思考题时间。
今天我留给你的课后问题是,你遇到过别的、类似今天我们提到的性能问题吗?你认为原因是什么,又是怎么解决的呢?
你可以把你经历和分析写在留言区里,我会在下一篇文章的末尾选取有趣的评论跟大家一起分享和分析。感谢你的收听,也欢迎你把这篇文章分享给更多的朋友一起阅读。
六、上期问题时间
我在上篇文章的最后,留给你的问题是:我们文章中最后的一个方案是,通过三次 limitY,1 来得到需要的数据,你觉得有没有进一步的优化方法。
这里我给出一种方法,取 Y1、Y2 和 Y3 里面最大的一个数,记为 M,最小的一个数记为
N,然后执行下面这条 SQL 语句:
mysql> select * from t limit N, M-N+1;
再加上取整个表总行数的 C 行,这个方案的扫描行数总共只需要 C+M+1 行。
当然也可以先取回 id 值,在应用中确定了三个 id 值以后,再执行三次 where id=X 的语句也是可以的。@倪大人 同学在评论区就提到了这个方法。
七、经典留言
1、冠超
非常感谢老师分享的内容,实打实地学到了。这里提个建议,希望老师能介绍一下设计表的时候要怎么考虑这方面的知识哈
MySQL实战45讲学习笔记:第十八讲的更多相关文章
- MySQL实战45讲学习笔记:第八讲
一.今日内容概要 我在第 3 篇文章和你讲事务隔离级别的时候提到过,如果是可重复读隔离级别,事务 T 启动的时候会创建一个视图 read-view,之后事务 T 执行期间,即使有其他事务修改了数据,事 ...
- Java框架spring 学习笔记(十八):事务管理(xml配置文件管理)
在Java框架spring 学习笔记(十八):事务操作中,有一个问题: package cn.service; import cn.dao.OrderDao; public class OrderSe ...
- Android学习笔记(十八)——再谈升级数据库
//此系列博文是<第一行Android代码>的学习笔记,如有错漏,欢迎指正! 之前我们为了保证数据库中的表是最新的,只是简单地在 onUpgrade()方法中删除掉了当前所有的表,然后强制 ...
- Dynamic CRM 2013学习笔记(十八)根据主表状态用JS控制子表自定义按钮
有时要根据主表的审批状态来控制子表上的按钮要不要显示,比如我们有一个需求审批通过后就不能再上传文件了. 首先打开Visual Ribbon Editor, 如下图,我们可以利用Enable Rules ...
- MySQL实战45讲学习笔记:第二十一讲
一.引子 在上一篇文章中,我和你介绍了间隙锁和 next-key lock 的概念,但是并没有说明加锁规则.间隙锁的概念理解起来确实有点儿难,尤其在配合上行锁以后,很容易在判断是否会出现锁等待的问题上 ...
- MySQL实战45讲学习笔记:第六讲
一.今日内容概要 今天我要跟你聊聊 MySQL 的锁.数据库锁设计的初衷是处理并发问题.作为多用户共享的资源,当出现并发访问的时候,数据库需要合理地控制资源的访问规则.而锁就是用来实现这些访问规则的重 ...
- MySQL实战45讲学习笔记:第十一讲
一.如何在邮箱这样的字段上建立合理的索引 现在,几乎所有的系统都支持邮箱登录,如何在邮箱这样的字段上建立合理的索引,是我们今天要讨论的问题. 假设,你现在维护一个支持邮箱登录的系统,用户表是这么定义的 ...
- MySQL实战45讲学习笔记:第十七讲
一 .引子 我在上一篇文章,为你讲解完 order by 语句的几种执行模式后,就想到了之前一个做英语学习 App 的朋友碰到过的一个性能问题.今天这篇文章,我就从这个性能问题说起,和你说说 MySQ ...
- MySQL实战45讲学习笔记:第二十七讲
一.一主多从的切换正确性 在前面的第24.25和26篇文章中,我和你介绍了 MySQL 主备复制的基础结构,但这些都是一主一备的结构. 大多数的互联网应用场景都是读多写少,因此你负责的业务,在发展过程 ...
- MySQL实战45讲学习笔记:第七讲
一.上节回顾今日计划 在上一篇文章中,我跟你介绍了 MySQL 的全局锁和表级锁,今天我们就来讲讲 MySQL的行锁. MySQL 的行锁是在引擎层由各个引擎自己实现的.但并不是所有的引擎都支持行锁, ...
随机推荐
- Luogu P3577 [POI2014]TUR-Tourism
Luogu P3577 [POI2014]TUR-Tourism 题目链接 题目大意:给出一张\(n\)个点,\(m\)条边的无向图,保证任意两点之间没有点数超过\(10\)的简单路径.选择第\(i\ ...
- 造轮子ArrayList
这篇博客实现一个简单的ArrayList集合.博客里的代码首先根据自己的想法实现,在走不动的情况下会去参考JDK源代码.所以阅读本文,不要抱着跟JDK源码对比的心态.于我个人而言,国庆期间,纯属娱乐. ...
- Docker学习(六)-Kubernetes - Spring Boot 应用
接上一篇 https://www.cnblogs.com/woxpp/p/11872155.html 新建 k8s-demo.yaml apiVersion: apps/v1beta2 kind: D ...
- 【UOJ#22】【UR #1】外星人(动态规划)
[UOJ#22][UR #1]外星人(动态规划) 题面 UOJ 题解 一道简单题? 不难发现只有按照从大往小排序的顺序选择的才有意义,否则先选择一个小数再去模一个大数是没有意义的. 设\(f[i][j ...
- 基于Spark的电影推荐系统(推荐系统~1)
第四部分-推荐系统-项目介绍 行业背景: 快速:Apache Spark以内存计算为核心 通用 :一站式解决各个问题,ADHOC SQL查询,流计算,数据挖掘,图计算 完整的生态圈 只要掌握Spark ...
- C#使用splitContainer控件制作收缩展开面板
C#使用splitContainer控件制作收缩展开面板 原创 2011年07月19日 17:18:02 标签: c# / object / 扩展 / 测试 15690 最近对Squi ...
- convert datatable to List<T>
public class DataConvert { public static List<T> ConvertDataTable<T>(DataTable dt) { Lis ...
- Java学习——注解
Java学习——注解 摘要:本文主要介绍了Java开发常用的注解,以及如何自定义注解. 部分内容来自以下博客: https://www.cnblogs.com/Qian123/p/5256084.ht ...
- Python基础17
写出来的代码,若有部分不想运行,可注释掉. 看跑出来的结果,再加进来调试.
- ActiveMQ反序列化(CVE-2015-5254) && ActiveMQ任意文件写入 (CVE-2016-3088)
ActiveMQ 反序列化漏洞(CVE-2015-5254) 漏洞详情 ActiveMQ启动后,将监听61616和8161两个端口,其中消息在61616这个端口进行传递,使用ActiveMQ这个中间件 ...