使用flask做网页的excel成绩分析
使用到的技术:pyecharts flask
首先 pip install flask 和下载pip install pyecharts==0.5.5
项目结构:
代码:
- from flask import Flask,render_template
app = Flask(__name__)
@app.route('/')
def hello_world():
return render_template('test.html')
@app.route('/avg',methods=['GET','POST'])
def avg_score():
return render_template("不同年份总体平均成绩情况.html")
@app.route('/sex')
def sex_score():
return render_template("不同性别学生成绩情况柱形图-折线图.html")
@app.route('/many')
def many_score():
return render_template("一个页面渲染多张图表.html")
@app.route('/bing')
def bing_score():
return render_template("饼图.html")- if __name__ == '__main__':
app.run(debug=True)
- # 导入xlrd模块
import xlrd
from pyecharts import *
page = Page() # 实例化page类,一个页面顺序熏染读个图表
#设置文件名和路径
fname = '课程成绩.xlsx'
# 打开文件
filename = xlrd.open_workbook(fname)
sheets=filename.nsheets#获得sheet的个数
sheet_list = filename.sheet_names()#sheet名字
list_x=[]
years=["2016","2017","2018"]#年份
for i in range(len(sheet_list)):
listx=[]#存放班级
dirx={}#存放班级人数
listy=[]#存放分数
diry={}#统计存放班级的分数
sheet=filename.sheets()[i]#获得当前的sheet
nrows=sheet.nrows#获得当前的sheet的行数
diravg={}#存放平均分
for j in range(1,nrows):
row_datas = sheet.row_values(j)#获得当前行的所有信息
listx.append(row_datas[0])
listy.append(row_datas[4])
for k in range(len(listx)):
if listx[k] not in dirx:
dirx[listx[k]]=1
if "".join(listy[k].split())!='缺考':
diry[listx[k]]=int(listy[k])
else:
diry[listx[k]]=0
else:
dirx[listx[k]]=dirx[listx[k]]+1
if "".join(listy[k].split())!='缺考':
diry[listx[k]]=int(listy[k])+diry[listx[k]]
for d in dirx:
if d not in diravg:
diravg[d]="%.1f"%(diry.get(d)/dirx.get(d))
keys=list(diravg.keys())
values=list(diravg.values())
bar=Bar(years[i]+"成绩分析")
bar.add(years[i],keys,values)
page.add(bar)
page.render("../templates/一个页面渲染多张图表.html")
截图:

- # 导入xlrd模块
import xlrd
from pyecharts import Bar
#设置文件名和路径
fname = '课程成绩.xlsx'
# 打开文件
filename = xlrd.open_workbook(fname)
sheets=filename.nsheets#获得sheet的个数
sheet_list = filename.sheet_names()#sheet名字
avg=[]
for i in range(len(sheet_list)):#获取sheet个数
sheet=filename.sheets()[i]#获取当前的sheet
nrows=sheet.nrows#获取行数
sumscore=0#总分
count=0#学生的个数
for j in range(1,nrows):
row_datas = sheet.row_values(j)#获得当前行的所有信息
if "".join(row_datas[4].split())!='缺考':
count=count+1
sumscore+=int(row_datas[4])
avg.append("%.1f"%(sumscore/count))#存放保留一位小数的成绩
#print(avg)
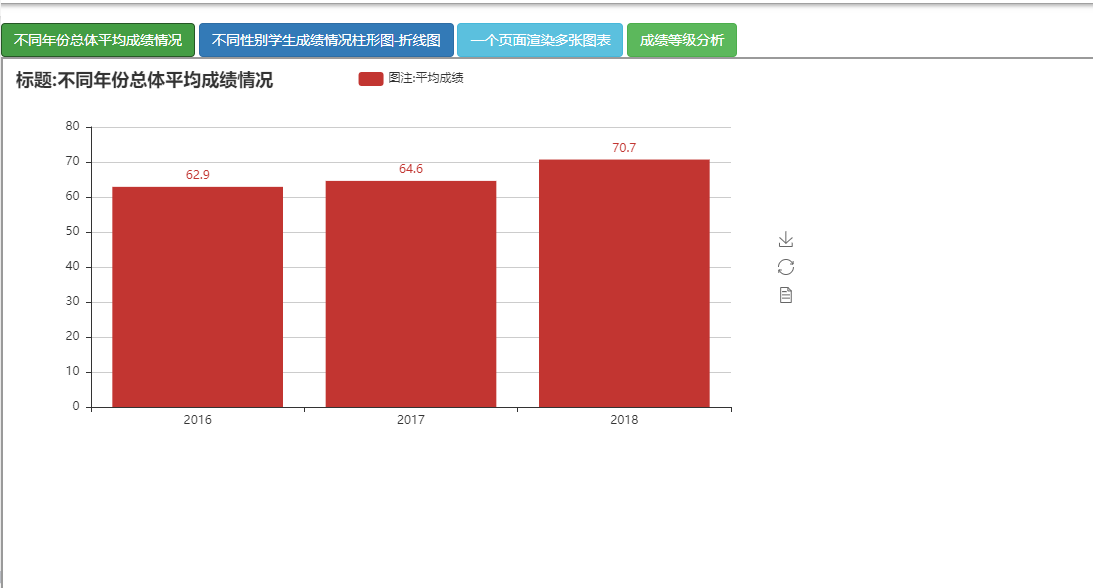
years=['2016','2017','2018']#设计x坐标
bar=Bar("标题:不同年份总体平均成绩情况")#设置标题
#画图
bar.add("图注:平均成绩",years,avg, is_label_show=True)
bar.render("../templates/不同年份总体平均成绩情况.html")
- import xlrd
from pyecharts import *
#设置文件名和路径
fname = '课程成绩.xlsx'
# 打开文件
filename = xlrd.open_workbook(fname)
page = Page() # 实例化page类,一个页面顺序熏染读个图表
sheets=filename.nsheets#获得sheet的个数
sheet_list = filename.sheet_names()#sheet名字
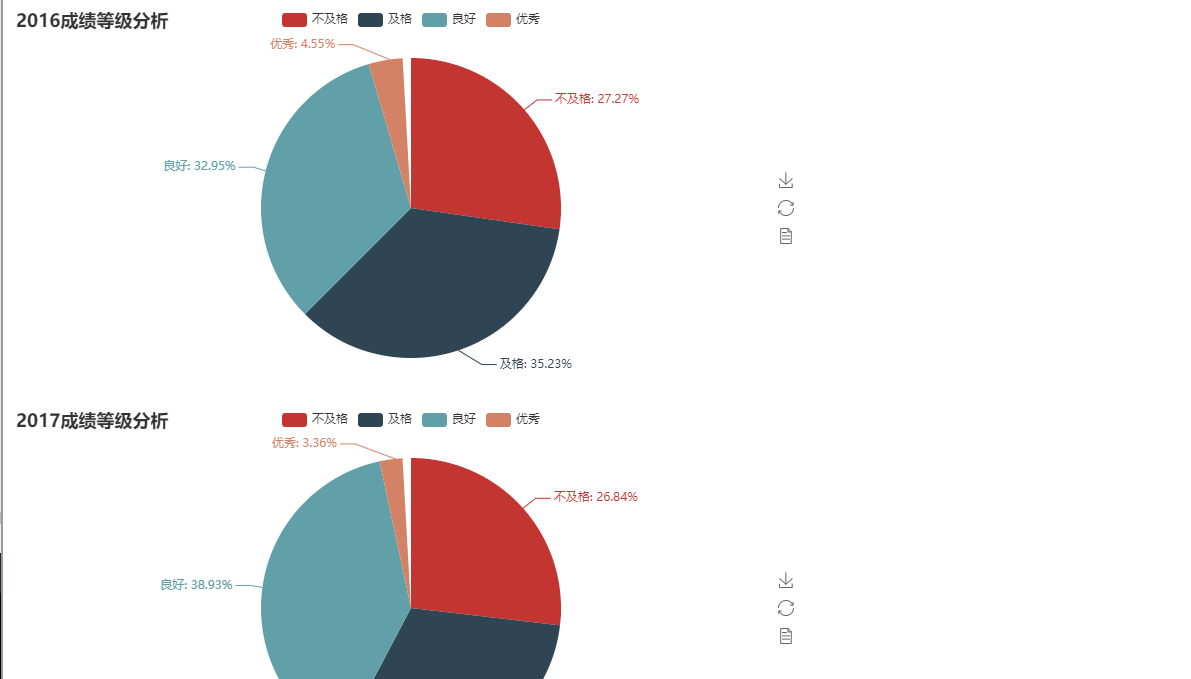
dirk={"不及格":0,"及格":0,'良好':0,'优秀':0}
years=["2016","2017","2018"]#年份
for i in range(len(sheet_list)):
sheet=filename.sheets()[i]#获取当前的sheet
nrows=sheet.nrows#获取行数
sumscore=0#总分
for j in range(1,nrows):
row_datas = sheet.row_values(j)#获得当前行的所有信息
if "".join(row_datas[4].split())!='缺考':
if int(row_datas[4])<60:
dirk["不及格"]=dirk.get("不及格")+1
elif 60<=int(row_datas[4])<70 :
dirk["及格"]=dirk.get("及格")+1
elif 70<=int(row_datas[4])<90 :
dirk["良好"]=dirk.get("良好")+1
else:
dirk["优秀"]=dirk.get("优秀")+1
pie = Pie(years[i]+"成绩等级分析")
listname=list(dirk.keys())
# print(listname)
attr = []
for i in listname:
attr.append(i)
values=[dirk.get("不及格"),dirk.get("及格"),dirk.get("良好"),dirk.get("优秀")]
pie.add("", attr, values, is_label_show=True)
page.add(pie)- page.render("../templates/饼图.html")
- #
# attr = ["衬衫", "羊毛衫", "雪纺衫", "裤子", "高跟鞋", "袜子"]
# v1 = [11, 12, 13, 10, 10, 10]
# pie = Pie("饼图示例")
# pie.add("", attr, v1, is_label_show=True)
# pie.render('pie.html')
使用flask做网页的excel成绩分析的更多相关文章
- 通过excel表格分析学生成绩
题目要求: 分析文件’课程成绩.xlsx’,至少要完成内容:分析1)每年不同班级平均成绩情况.2)不同年份总体平均成绩情况.3)不同性别学生成绩情况,并分别用合适的图表展示出三个内容的分析结果. 废话 ...
- 网页细分图结果分析(Web Page Diagnostics)
Discuz开源论坛网页细分图结果分析(Web Page Diagnostics) 续LR实战之Discuz开源论坛项目,之前一直是创建虚拟用户脚本(Virtual User Generator)和场 ...
- LR实战之Discuz开源论坛——网页细分图结果分析(Web Page Diagnostics)
续LR实战之Discuz开源论坛项目,之前一直是创建虚拟用户脚本(Virtual User Generator)和场景(Controller),现在,终于到了LoadRunner性能测试结果分析(An ...
- 用XAML做网页!!—终结篇
原文:用XAML做网页!!-终结篇 迄今为止的设计都很顺利,但这次就不得不接触我前面所说的非常糟糕的流文档了,但在此之前先来把标题弄好: <Border BorderBrush="#6 ...
- 基于flask的网页聊天室(四)
基于flask的网页聊天室(四) 前言 接前天的内容,今天完成了消息的处理 具体内容 上次使用了flask_login做用户登录,但是直接访问login_requare装饰的函数会报401错误,这里可 ...
- 基于flask的网页聊天室(三)
基于flask的网页聊天室(三) 前言 继续上一次的内容,今天完成了csrf防御的添加,用户头像的存储以及用户的登录状态 具体内容 首先是添加csrf的防御,为整个app添加防御: from flas ...
- flask使用tablib导出excel数据表
在网页中常常有导出数据的需求,尤其是一下管理类平台.在flask中要导出excel数据表,通常可以使用xlwt库,创建文件并逐行写入数据,但是使用起来总是感觉很麻烦.tablib库相对操作更加方便. ...
- 【学】CSS3基础实例1 - 用CSS3做网页中的小三角,以及transition的用法
自开了博客园已经有2周了吧,虽然转载了一些觉得比较有用的文章之外还没有开始写自己的一些学习记录,那就从今天开始. 目前看了妙味的不少视频,有css+html,js的基础和中级也都看完了,作业也都做了, ...
- 用做网页开发经历了三个阶段(附长篇讨论) good
用做网页开发经历了三个阶段:第一阶:傻干阶段使用Intraweb,傻瓜型,无需知道javascript,html,css,会pascal就可以了. 第二阶:困惑阶段使用Intraweb,有很多限制,比 ...
随机推荐
- BZOJ 5338: [TJOI2018]xor 可持久化trie+dfs序
强行把序列问题放树上,好无聊啊~ code: #include <bits/stdc++.h> #define N 200005 #define setIO(s) freopen(s&qu ...
- globing通配符
匹配标点符号 linux中只要不含有/的文件就可以生成,所以标点符号也是符合要求的 匹配空白 使用\对空白进行转义,这样就可以生成包含空格名称的文件 但是不推荐这样用,容易让别人在使用的时候造成误解 ...
- bootstrap轮播图组件
一.轮播图组件模板(官方文档) <div id="carousel-example-generic" class="carousel slide" dat ...
- canvas的基本使用
一.定义 canvas最早是由Apple引入Webkit的,<canvas>元素包含于HTML5中 HTML5的canvas元素使用JavaScript在网页上绘制图像,画布是一个矩形区域 ...
- JQuery/JS插件 日期插件
用于日期的计算,功能比较全,我常用的主要是日期的计算(多一天少一天,或者添加几个月等),日期格式化 网址:http://momentjs.cn/ 测试代码: <!DOCTYPE html> ...
- Dense Semantic Labeling with Atrous Spatial Pyramid Pooling and Decoder for High-Resolution Remote Sensing Imagery(高分辨率语义分割)
对 Potsdam and Vaihingen 公开数据集进行处理,得到了SOTA的结果,超越DeepLab_v3+,提出的网络结构如下:结合了ASPP和FCN,UNet
- 第12组 Beta冲刺(3/5)
Header 队名:To Be Done 组长博客 作业博客 团队项目进行情况 燃尽图(组内共享) 展示Git当日代码/文档签入记录(组内共享) 注: 由于GitHub的免费范围内对多人开发存在较多限 ...
- 2019 SDN第二次上机作业
2019 SDN第二次上机作业 1. 利用mininet创建如下拓扑,要求拓扑支持OpenFlow 1.3协议,主机名.交换机名以及端口对应正确,请给出拓扑Mininet执行结果,展示端口连接情况 创 ...
- 时针分针角度问题c语言解法
#include <stdio.h> //时针一小时走30度 double hour_per_hour_angle = 30.0; //先算出时针和分钟 一分钟内 分别走多少度数 //时针 ...
- AOP的定义和原理
一.本课目标 理解Spring AOP的原理 掌握Spring AOP的七个术语 二.面向切面编程(AOP) AOP的思想是,不去动原来的代码,而是基于原来代码产生代理对象,通过代理的方法,去包装原 ...