linux驱动开发学习一:创建一个字符设备
首先是内核初始化函数。代码如下。主要是三个步骤。1 生成设备号。 2 注册设备号。3 创建设备。
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/init.h>
#include <linux/cdev.h>
#include <linux/slab.h>
#include <linux/uaccess.h> #define GLOBALMEM_SIZE 0X1000
#define MEM_CLEAR 0X1
#define GLOBALMEM_MAJOR 230 static int globalmem_major= GLOBALMEM_MAJOR;
module_param(globalmem_major,int,S_IRUGO); struct globalmem_dev{
struct cdev cdev;
unsigned char mem[GLOBALMEM_SIZE];
}; static int __init globalmem_init(void)
{
int ret;
dev_t devno=MKDEV(globalmem_major,0); (1)
if(globalmem_major)
ret=register_chrdev_region(devno,1,"globalmem_tmp"); (2)
else{
ret=alloc_chrdev_region(&devno,0,1,"globalmem_tmp");
globalmem_major=MAJOR(devno);
}
if(ret < 0)
return ret;
globalmem_devp=kzalloc(sizeof(struct globalmem_dev),GFP_KERNEL);
if(!globalmem_devp){
ret=-EFAULT;
goto fail_malloc;
} globalmem_setup_dev(globalmem_dev,0); (3)
return 0;
fail_malloc:
unregister_chrdev_region(devno,1);
return ret;
}
(1) 生成设备号
我们要注册一个设备,首先要生成这个设备的设备号。这里先分配一块大小为4KB的内存空间。同时将该值赋值给globalmem_major用于生成设备号
Linux的设备管理是和文件系统紧密结合的,各种设备都以文件的形式存放在/dev目录下,称为设备文件。应用程序可以打开、关闭和读写这些设备文件,完成对设备的操作,就像操作普通的数据文件一样。为了管理这些设备,系统为设备编了号,每个设备号又分为主设备号和次设备号。主设备号用来区分不同种类的设备,而次设备号用来区分同一类型的多个设备
如下在dev下的设备,中,都是以b开头的。证明都是block设备。然后主设备号都是7,0,1,10都是次设备号
nb-test:/dev$ ls -al
brw-rw---- 1 root disk 7, 0 10月 24 16:36 loop0
brw-rw---- 1 root disk 7, 1 10月 24 16:36 loop1
brw-rw---- 1 root disk 7, 10 10月 24 16:36 loop10
和设备号相关的代码如下,
#define MINORBITS 20
#define MINORMASK ((1U << MINORBITS) - 1)
#define MAJOR(dev) ((unsigned int) ((dev) >> MINORBITS))
#define MINOR(dev) ((unsigned int) ((dev) & MINORMASK))
#define MKDEV(ma,mi) (((ma) << MINORBITS) | (mi))
设备号是个32bit,高12bit是主设备号,低20bit是次设备号。MAJOR宏将设备号向右移动20位得到主设备号,MINOR将设备号的高12位清0。MKDEV将主设备号ma左移20位,然后与次设备号mi相与得到设备号。
(2) 注册设备号
设备号生成,接下来的任务就是将设备号注册到系统中去。由于我们是创建有一个字符型的设备,因此调用函数register_chrdev_region。
函数的原型:int register_chrdev_region(dev_t from, unsigned count, const char *name)
from是设备号,count是设备个数,name是设备名。实际上在里面调用的是
__register_chrdev_region 函数。这里面主要步骤包含几个
>1 申请一个设备结构体内存
cd = kzalloc(sizeof(struct char_device_struct), GFP_KERNEL);
>2在chrdevs中找到cd的插入位置,在chrdevs中是以升序排列的。
for (cp = &chrdevs[i]; *cp; cp = &(*cp)->next)
if ((*cp)->major > major ||
((*cp)->major == major &&
(((*cp)->baseminor >= baseminor) ||
((*cp)->baseminor + (*cp)->minorct > baseminor))))
break;
chrdevs是一个结构体指针数组,里面存储的的都是每个结构体的指针。这里为什么要用到结构体指针数组,下面会介绍
static struct char_device_struct {
struct char_device_struct *next;
unsigned int major;
unsigned int baseminor;
int minorct;
char name[64];
struct cdev *cdev; /* will die */
} *chrdevs[CHRDEV_MAJOR_HASH_SIZE];
>3 找到位置后,将cd插入到cp中去。这一段插入充分利用了指针的性质,在对于一个单链表的插入来说非常的巧妙。
cd->next = *cp;
*cp = cd;
cd和cp的类型申明如下。
struct char_device_struct *cd, **cp;
cd是char_device_struct的指针。cp是char_device_struct 指针的指针。在前面寻找插入位置的时候。循环控制方式如下,也就是说cp指向的是上一个节点的next指针的地址。
for (cp = &chrdevs[i]; *cp; cp = &(*cp)->next)
cd->next=*cp这个好理解,就是将cd的下一个节点指向*cp。那么*cp=cd相对比较抽象,这个的意思将cp地址存储的内容修改为cd。而cp地址指向的是上一个节点的next指针地址,将整个*cp赋值为cd,也就是将上一个节点的next指针地址所存储的值变为cd。这样就实现了将cd插入到了链表中去
用段代码来验证下:
struct linklist
{
int num;
struct linklist *next;
};
int main(int argc, char **argv)
{
int i;
struct linklist head;
struct linklist_tmp *s;
head.num = 0;
head.next = NULL;
struct linklist *tmp = NULL;
struct linklist **ttmp = NULL; len = sizeof(a)/sizeof(int);
for (i = 1; i < 6; i += 2)
{
tmp = (struct linklist *)malloc(sizeof(struct linklist));
tmp->num = i;
tmp->next = head.next;
head.next = tmp;
}
ttmp = &(head.next);
while (*ttmp)
{
printf("%d, %016x, %016x, %016x\n", (*ttmp)->num, ttmp, *ttmp, (*ttmp)->next);
ttmp = &((*ttmp)->next);
} printf("============================\n");
struct linklist addnode = { .num = 2,.next = NULL };
ttmp = &(head.next);
while (*ttmp)
{
if ((*ttmp)->num < addnode.num)
{
break;
}
ttmp = &((*ttmp)->next);
}
addnode.next = *ttmp;
*ttmp = &addnode;
ttmp = &(head.next);
while (*ttmp)
{
printf("%d, %016x, %016x, %016x,%016x\n", (*ttmp)->num, ttmp, *ttmp, (*ttmp)->next,&((*ttmp)->next));
ttmp = &((*ttmp)->next);
} return 0;
}
执行结果如下:
可以看到节点值为2 指针的指针就是以前节点值为1的地址。而节点值为1 指针的指针则被挪到了另外一个位置。
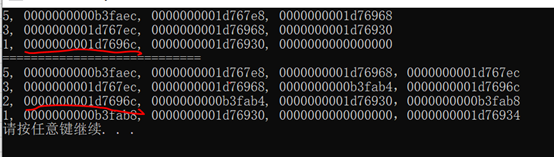
用下面这个图来表示更直观,*cp = cd; 也就意味着地址为1d7696c存储的值变为0b3fab4,而地址0b3fab4存储的节点就是插入的节点2。而0b3fab4指向节点1的地址也就是1d76930。而1d76930的地址则变为另外一个。

通过这种二级指针的方式实现了单链表的插入。这种方法避免了传统的删除或插入链表节点需要记录链表prev节点。同样的也可以用这种方式进行删除节点
void remove_if(node ** head, remove_fn rm)
{
for (node** curr = head; *curr; )
{
node * entry = *curr;
if (rm(entry))
{
*curr = entry->next;
free(entry);
}
else
curr = &entry->next;
}
}
(3) Cdev的初始化和添加。
>1 首先是cdev的初始化。其中最重要的工作就是注册设备的操作函数。设备的注册函数实现如下。
static int globalmem_open(struct inode *inode,struct file *filp)
{
filp->private_data=globalmem_devp;
return 0;
} static int globalmem_release(struct inode *inode,struct file *filp)
{
return 0;
} static long globalmem_ioctl(struct file *filp,unsigned int cmd,unsigned long arg)
{
struct globalmem_dev *dev=filp->private_data;
switch(cmd)
{
case MEM_CLEAR:
memset(dev->mem,0,GLOBALMEM_SIZE);
printk(KERN_INFO "globalmem is set to zero\n");
default:
return -EINVAL;
}
return 0;
} static ssize_t globalmem_read(struct file *filp,char __user *buf,size_t size,loff_t *ppos)
{
unsigned long p=*ppos;
unsigned int count=size;
int ret=0;
struct globalmem_dev *dev=filp->private_data;
if(p > GLOBALMEM_SIZE)
return 0;
if(count > GLOBALMEM_SIZE-p)
count=GLOBALMEM_SIZE-p;
if(copy_to_user(buf,dev->mem+p,count)){
ret=-EFAULT;
}
else{
*ppos+=count;
ret=count;
}
printk(KERN_INFO “read %u bytes(s) from %lu\n”,count,p);
return ret;
} static ssize_t globalmem_write(struct file *filp,const char __user *buf,size_t size, loff_t *ppos)
{
unsigned long p=*ppos;
unsigned int count=size;
int ret=0;
struct globalmem_dev *dev=filp->private_data;
if(p > GLOBALMEM_SIZE)
return 0;
if(count > GLOBALMEM_SIZE-p)
count=GLOBALMEM_SIZE-p;
if(copy_from_user(dev->mem+p,buf,count))
ret=-EFAULT;
else{
*ppos+=count;
ret=count;
printk(KERN_INFO "written %u bytes(s) from %lu\n",count,p);
}
return ret;
} static loff_t globalmem_llseek(struct file *filp,loff_t offset,int orig)
{
loff_t ret=0;
switch(orig){
case 0:
if (offset <0)
ret=-EFAULT;
break;
if ((unsigned int)offset > GLOBALMEM_SIZE){
ret=-EFAULT;
break;
}
filp->f_pos=(unsigned int)offset;
ret=filp->f_pos;
break;
case 1:
if((filp->f_pos+offset) > GLOBALMEM_SIZE){
ret=-EFAULT;
break;
}
if((filp->f_pos+offset) < 0){
ret=-EFAULT;
break;
}
filp->f_pos+=offset;
ret=filp->f_pos;
break;
}
return ret;
}
globalmem_fops就是操作的函数指针结构体。
static const struct file_operations globalmem_fops={
.owner=THIS_MODULE,
.llseek=globalmem_llseek,
.read=globalmem_read,
.write=globalmem_write,
.unlocked_ioctl=globalmem_ioctl,
.open=globalmem_open,
.release=globalmem_release,
};
cdev_init的工作就是将这些操作函数赋给cdev->ops
void cdev_init(struct cdev *cdev, const struct file_operations *fops)
{
memset(cdev, 0, sizeof *cdev);
INIT_LIST_HEAD(&cdev->list);
kobject_init(&cdev->kobj, &ktype_cdev_default);
cdev->ops = fops;
}
这里还有一个kobject_init函数,是用来初始化kobj对象的。这个下面介绍
>2 添加cdev设备。这里首先介绍kobj_map结构体
struct kobj_map {
struct probe {
struct probe *next; 链表结构
dev_t dev; 设备号
unsigned long range; 设备号的范围
struct module *owner;
kobj_probe_t *get;
int (*lock)(dev_t, void *);
void *data; 指向struct cdev对象
} *probes[255];
struct mutex *lock;
};
结构体中有一个互斥锁lock,一个probes[255]数组,数组元素为struct probe的指针。
根据下面的函数作用来看,kobj_map结构体是用来管理设备号及其对应的设备的。
kobj_map函数就是将指定的设备号加入到该数组,kobj_lookup则查找该结构体,然后返回对应设备号的kobject对象,利用利用该kobject对象,我们可以得到包含它的对象如cdev。struct probe结构体中的get函数指针就是用来获得kobject对象的
因此cdev_add其实就是想kobj中添加设备的过程,具体实现是用kobj_map函数。
其中cdev_map是定义在char_dev.c中的一个静态变量。
static struct kobj_map *cdev_map;
int cdev_add(struct cdev *p, dev_t dev, unsigned count)
{
p->dev = dev;
p->count = count;
return kobj_map(cdev_map, dev, count, NULL, exact_match, exact_lock, p);
}
Kobj_map的代码如下
int kobj_map(struct kobj_map *domain, dev_t dev, unsigned long range,
struct module *module, kobj_probe_t *probe,
int (*lock)(dev_t, void *), void *data)
{
unsigned n = MAJOR(dev + range - 1) - MAJOR(dev) + 1;
unsigned index = MAJOR(dev);
unsigned i;
struct probe *p; if (n > 255)
n = 255; p = kmalloc(sizeof(struct probe) * n, GFP_KERNEL); if (p == NULL)
return -ENOMEM; for (i = 0; i < n; i++, p++) {
p->owner = module;
p->get = probe;
p->lock = lock;
p->dev = dev;
p->range = range;
p->data = data;
}
mutex_lock(domain->lock);
for (i = 0, p -= n; i < n; i++, p++, index++) {
struct probe **s = &domain->probes[index % 255];
while (*s && (*s)->range < range)
s = &(*s)->next;
p->next = *s;
*s = p;
}
mutex_unlock(domain->lock);
return 0;
}
至此设备的初始化,注册,插入功能都已全部完成,下面来试下功能。Makefile文件如下
#Makefile文件注意:假如前面的.c文件起名为first.c,那么这里的Makefile文件中的.o文
#件就要起名为first.o 只有root用户才能加载和卸载模块
obj-m:=global_test.o #产生global_test模块的目标文件
#目标文件 文件 要与模块名字相同
CURRENT_PATH:=$(shell pwd) #模块所在的当前路径
LINUX_KERNEL:=$(shell uname -r) #linux内核代码的当前版本
LINUX_KERNEL_PATH:=/usr/src/linux-headers-$(LINUX_KERNEL)
CONFIG_MODULE_SIG=n
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
clean:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) clean #清理模块
插入模块:sudo insmod global_test.ko。 此时在/proc/devices下能看到多出了主设备号为230的globalmem_tmp字符设备驱动

接下来创建节点,执行命令sudo mknod -m 766 /dev/globalmem_tmp c 230 0。 显示创建成功
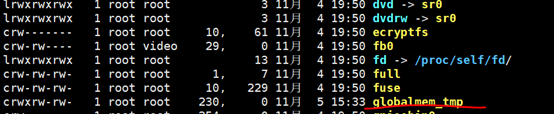
cat /dev/globalmem_tmp 读取设备数据。可以看到能正常的读出数据
test:~/linux_prj/globalman$ cat /dev/globalmem_tmp
hello world
linux驱动开发学习一:创建一个字符设备的更多相关文章
- Linux驱动开发学习的一些必要步骤
1. 学会写简单的makefile 2. 编一应用程序,可以用makefile跑起来 3. 学会写驱动的makefile 4. 写一简单char驱动,makefile编译通过,可以insmod, ...
- Linux驱动实践:你知道【字符设备驱动程序】的两种写法吗?
作 者:道哥,10+年嵌入式开发老兵,专注于:C/C++.嵌入式.Linux. 关注下方公众号,回复[书籍],获取 Linux.嵌入式领域经典书籍:回复[PDF],获取所有原创文章( PDF 格式). ...
- Linux驱动开发学习笔记(1):LINUX驱动版本的hello world
1.关于目录 /lib/modules/2.6.9-42.ELsmp/build/ 这个是内核源码所在的目录 一般使用这样的命令进入这个目录:cd /lib/modules/$(una ...
- 在dev目录创建一个字符设备驱动的流程
1.struct file_operations 字符设备文件接口 1: static int mpu_open(struct inode *inode, struct file *file) 2: ...
- linux驱动开发学习二:创建一个阻塞型的字符设备
在Linux 驱动程序中,可以使用等待队列来实现阻塞进程的唤醒.等待队列的头部定义如下,是一个双向列表. struct list_head { struct list_head *next, *pre ...
- (57)Linux驱动开发之三Linux字符设备驱动
1.一般情况下,对每一种设备驱动都会定义一个软件模块,这个工程模块包含.h和.c文件,前者定义该设备驱动的数据结构并声明外部函数,后者进行设备驱动的具体实现. 2.典型的无操作系统下的逻辑开发程序是: ...
- Linux内核(17) - 高效学习Linux驱动开发
这本<Linux内核修炼之道>已经开卖(网上的链接为: 卓越.当当.china-pub ),虽然是严肃文学,但为了保证流畅性,大部分文字我还都是斟词灼句,反复的念几遍才写上去的,尽量考虑到 ...
- Hasen的linux设备驱动开发学习之旅--时钟
/** * Author:hasen * 參考 :<linux设备驱动开发具体解释> * 简单介绍:android小菜鸟的linux * 设备驱动开发学习之旅 * 主题:时钟 * Date ...
- Linux驱动开发2——字符设备驱动
1.申请设备号 #include <linux/fs.h> int register_chrdev_region(dev_t first, unsigned int count, char ...
随机推荐
- DT添加七牛云对象存储插件功能
七牛云对象存储 1.注意客户购买的空间的存储区域,区域不同对应的上传域名不同 destoon 七牛云上传文件 用下面源码替换include/ftp.class.php 文件代码 &l ...
- luogu2900:Land Acquisition(斜率优化)
题意:有N块地,每块地给出的宽和高,然后可以分批买,每次买的代价是所选择的地种最宽*最高. 问怎么买,使得代价和最小. 思路:显然,先去掉被包括的情况,即如果一个地的宽和高斗比另外一个小,那么久可以删 ...
- TestAbstract
public class TestAbstract { public static void main(String[] args) { System.out.println("Hello ...
- NSData、数据结构与数据转换
数据结构公式:Data_Structure=(D,R): 只要数据元素与数据(组织关系)能够保持:同一个数据(结构)可以在各种存贮形式间进行转换. 字节流或字符串是所有转化的中间节点(中转站).相当于 ...
- NYOJ104-最大和-(前缀和)
题意:给一个矩阵,每个元素有正有负,求最大矩阵和. 解题: (1)对原矩阵a用前缀和处理,处理变成矩阵sum,sum[i][j]表示从左上角为a[1][1]到右下角a[i][j]的全部元素和. 矩阵必 ...
- HDU 6583 Typewriter(后缀自动机)
Typewrite \[ Time Limit: 1500 ms\quad Memory Limit: 262144 kB \] 题意 给出一个字符串 \(s\),现在你需要构造出这个字符串,你每次可 ...
- Reincarnation HDU - 4622 (后缀自动机)
Reincarnation \[ Time Limit: 3000 ms\quad Memory Limit: 65536 kB \] 题意 给出一个字符串 \(S\),然后给出 \(m\) 次查询, ...
- [CF787D] legacy
题目 Rick和他的同事们研究出了一种新的有关放射的公式,于是许多坏人就在追赶他们.所以Rick希望在被坏人抓住之前把遗产给Morty. 在他们的宇宙里总共有n颗行星,每颗行星有它自己的编号(编号为1 ...
- [AGC007E] Shik and Travel
题目 给定一棵n节点的 以1为根的 满二叉树 (每个非叶子节点恰好有两个儿子)n−1 条边. 第ii条边连接 i+1号点 和 ai, 经过代价为vi设这棵树有m个叶子节点定义一次合法的旅行为:(1) ...
- 安装单机es
1.安装JDK(1.8)2.上传解压Elasticsearch-5.4.33.创建一个普通用户,然后将对于的目录修改为普通用户的所属用户和所属组4.修改配置文件config/elasticsearch ...