分布式缓存重建并发冲突和zookeeper分布式锁解决方案
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.5</version>
</dependency>
import java.util.concurrent.CountDownLatch; import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.ZooDefs.Ids;
import org.apache.zookeeper.ZooKeeper; public class ZooKeeperSession { private static CountDownLatch connectedSemaphore = new CountDownLatch(1); private ZooKeeper zookeeper; public ZooKeeperSession() {
// 去连接zookeeper server,创建会话的时候,是异步去进行的
// 所以要给一个监听器,说告诉我们什么时候才是真正完成了跟zk server的连接
try {
this.zookeeper = new ZooKeeper(
"192.168.31.187:2181,192.168.31.19:2181,192.168.31.227:2181",
50000,
new ZooKeeperWatcher());
// 给一个状态CONNECTING,连接中
System.out.println(zookeeper.getState()); try {
// CountDownLatch
// java多线程并发同步的一个工具类
// 会传递进去一些数字,比如说1,2 ,3 都可以
// 然后await(),如果数字不是0,那么久卡住,等待 // 其他的线程可以调用coutnDown(),减1
// 如果数字减到0,那么之前所有在await的线程,都会逃出阻塞的状态
// 继续向下运行 connectedSemaphore.await();
} catch(InterruptedException e) {
e.printStackTrace();
} System.out.println("ZooKeeper session established......");
} catch (Exception e) {
e.printStackTrace();
}
} /**
* 获取分布式锁
* @param productId
*/
public void acquireDistributedLock(Long productId) {
String path = "/product-lock-" + productId; try {
zookeeper.create(path, "".getBytes(),
Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
System.out.println("success to acquire lock for product[id=" + productId + "]");
} catch (Exception e) {
// 如果那个商品对应的锁的node,已经存在了,就是已经被别人加锁了,那么就这里就会报错
// NodeExistsException
int count = 0;
while(true) {
try {
Thread.sleep(20);
zookeeper.create(path, "".getBytes(),
Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
} catch (Exception e2) {
e2.printStackTrace();
count++;
continue;
}
System.out.println("success to acquire lock for product[id=" + productId + "] after " + count + " times try......");
break;
}
}
} /**
* 释放掉一个分布式锁
* @param productId
*/
public void releaseDistributedLock(Long productId) {
String path = "/product-lock-" + productId;
try {
zookeeper.delete(path, -1);
} catch (Exception e) {
e.printStackTrace();
}
} /**
* 建立zk session的watcher
* @author Administrator
*
*/
private class ZooKeeperWatcher implements Watcher { public void process(WatchedEvent event) {
System.out.println("Receive watched event: " + event.getState());
if(KeeperState.SyncConnected == event.getState()) {
connectedSemaphore.countDown();
}
} } /**
* 封装单例的静态内部类
* @author Administrator
*
*/
private static class Singleton { private static ZooKeeperSession instance; static {
instance = new ZooKeeperSession();
} public static ZooKeeperSession getInstance() {
return instance;
} } /**
* 获取单例
* @return
*/
public static ZooKeeperSession getInstance() {
return Singleton.getInstance();
} /**
* 初始化单例的便捷方法
*/
public static void init() {
getInstance();
} }
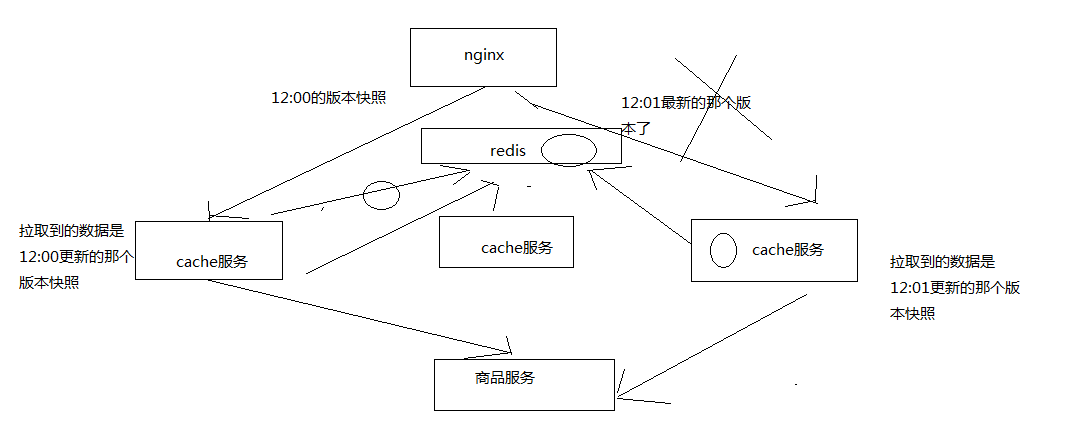
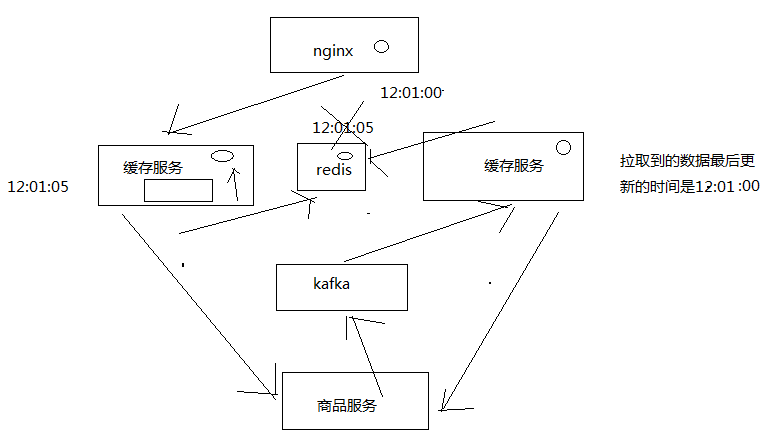
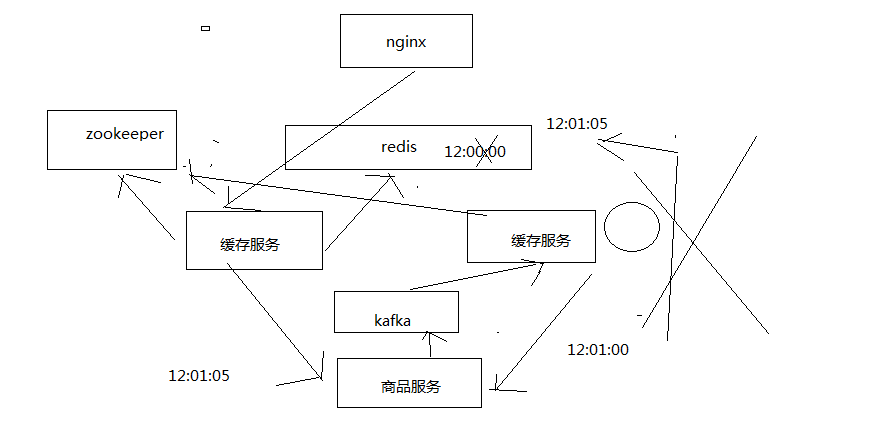
1、主动更新
监听kafka消息队列,获取到一个商品变更的消息之后,去哪个源服务中调用接口拉取数据,更新到ehcache和redis中
先获取分布式锁,然后才能更新redis,同时更新时要比较时间版本
2、被动重建
直接读取源头数据,直接返回给nginx,同时推送一条消息到一个队列,后台线程异步消费
后台现成负责先获取分布式锁,然后才能更新redis,同时要比较时间版本
// 加代码,在将数据直接写入redis缓存之前,应该先获取一个zk的分布式锁
private static SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
ZooKeeperSession zkSession = ZooKeeperSession.getInstance();
zkSession.acquireDistributedLock(productId); // 获取到了锁
// 先从redis中获取数据
ProductInfo existedProductInfo = cacheService.getProductInfoFromReidsCache(productId); if(existedProductInfo != null) {
// 比较当前数据的时间版本比已有数据的时间版本是新还是旧
try {
Date date = sdf.parse(productInfo.getModifiedTime());
Date existedDate = sdf.parse(existedProductInfo.getModifiedTime()); if(date.before(existedDate)) {
System.out.println("current date[" + productInfo.getModifiedTime() + "] is before existed date[" + existedProductInfo.getModifiedTime() + "]");
return;
}
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("current date[" + productInfo.getModifiedTime() + "] is after existed date[" + existedProductInfo.getModifiedTime() + "]");
} else {
System.out.println("existed product info is null......");
} cacheService.saveProductInfo2ReidsCache(productInfo); // 释放分布式锁
zkSession.releaseDistributedLock(productId);
if(productInfo == null) {
// 就需要从数据源重新拉去数据,重建缓存,但是这里先不讲
String productInfoJSON = "{\"id\": 2, \"name\": \"iphone7手机\", \"price\": 5599, \"pictureList\":\"a.jpg,b.jpg\", \"specification\": \"iphone7的规格\", \"service\": \"iphone7的售后服务\", \"color\": \"红色,白色,黑色\", \"size\": \"5.5\", \"shopId\": 1, \"modified_time\": \"2017-01-01 12:01:00\"}";
productInfo = JSONObject.parseObject(productInfoJSON, ProductInfo.class);
// 将数据推送到一个内存队列中
RebuildCacheQueue rebuildCacheQueue = RebuildCacheQueue.getInstance();
rebuildCacheQueue.putProductInfo(productInfo);
}
import java.util.concurrent.ArrayBlockingQueue; /**
* 重建缓存的内存队列
*
*/
public class RebuildCacheQueue { private ArrayBlockingQueue<ProductInfo> queue = new ArrayBlockingQueue<ProductInfo>(1000); public void putProductInfo(ProductInfo productInfo) {
try {
queue.put(productInfo);
} catch (Exception e) {
e.printStackTrace();
}
} public ProductInfo takeProductInfo() {
try {
return queue.take();
} catch (Exception e) {
e.printStackTrace();
}
return null;
} /**
* 内部单例类
*/
private static class Singleton { private static RebuildCacheQueue instance; static {
instance = new RebuildCacheQueue();
} public static RebuildCacheQueue getInstance() {
return instance;
} } public static RebuildCacheQueue getInstance() {
return Singleton.getInstance();
} public static void init() {
getInstance();
} }
import java.text.SimpleDateFormat;
import java.util.Date;
import com.roncoo.eshop.cache.model.ProductInfo;
import com.roncoo.eshop.cache.service.CacheService;
import com.roncoo.eshop.cache.spring.SpringContext;
import com.roncoo.eshop.cache.zk.ZooKeeperSession; /**
* 缓存重建线程
*/
public class RebuildCacheThread implements Runnable { private static SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); public void run() {
RebuildCacheQueue rebuildCacheQueue = RebuildCacheQueue.getInstance();
ZooKeeperSession zkSession = ZooKeeperSession.getInstance();
CacheService cacheService = (CacheService) SpringContext.getApplicationContext()
.getBean("cacheService"); while(true) {
ProductInfo productInfo = rebuildCacheQueue.takeProductInfo(); zkSession.acquireDistributedLock(productInfo.getId()); ProductInfo existedProductInfo = cacheService.getProductInfoFromReidsCache(productInfo.getId()); if(existedProductInfo != null) {
// 比较当前数据的时间版本比已有数据的时间版本是新还是旧
try {
Date date = sdf.parse(productInfo.getModifiedTime());
Date existedDate = sdf.parse(existedProductInfo.getModifiedTime()); if(date.before(existedDate)) {
System.out.println("current date[" + productInfo.getModifiedTime() + "] is before existed date[" + existedProductInfo.getModifiedTime() + "]");
continue;
}
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("current date[" + productInfo.getModifiedTime() + "] is after existed date[" + existedProductInfo.getModifiedTime() + "]");
} else {
System.out.println("existed product info is null......");
} cacheService.saveProductInfo2ReidsCache(productInfo);
}
} }
启动线程:
new Thread(new RebuildCacheThread()).start();
分布式缓存重建并发冲突和zookeeper分布式锁解决方案的更多相关文章
- Apache Ignite——集合分布式缓存、计算、存储的分布式框架
Apache Ignite内存数据组织平台是一个高性能.集成化.混合式的企业级分布式架构解决方案,核心价值在于可以帮助我们实现分布式架构透明化,开发人员根本不知道分布式技术的存在,可以使分布式缓存.计 ...
- 分布式缓存之Memcache
〇.为什么要用分布式缓存 1.软件从单机到分布式 走向分布式第一步就是解决:多台机器共享登录信息的问题. 例如:现在有三台机器组成了一个Web的应用集群,其中一台机器用户登录,然后其他另外两台机器共享 ...
- 5个强大的Java分布式缓存框架推荐
在开发中大型Java软件项目时,很多Java架构师都会遇到数据库读写瓶颈,如果你在系统架构时并没有将缓存策略考虑进去,或者并没有选择更优的 缓存策略,那么到时候重构起来将会是一个噩梦.本文主要是分享了 ...
- 一个技术汪的开源梦 —— 公共组件缓存之分布式缓存 Redis 实现篇
Redis 安装 & 配置 本测试环境将在 CentOS 7 x64 上安装最新版本的 Redis. 1. 运行以下命令安装 Redis $ wget http://download.redi ...
- [.NET领域驱动设计实战系列]专题八:DDD案例:网上书店分布式消息队列和分布式缓存的实现
一.引言 在上一专题中,商家发货和用户确认收货功能引入了消息队列来实现的,引入消息队列的好处可以保证消息的顺序处理,并且具有良好的可扩展性.但是上一专题消息队列是基于内存中队列对象来实现,这样实现有一 ...
- .NET Core应用中使用分布式缓存及内存缓存
.NET Core针对缓存提供了很好的支持 ,我们不仅可以选择将数据缓存在应用进程自身的内存中,还可以采用分布式的形式将缓存数据存储在一个“中心数据库”中.对于分布式缓存,.NET Core提供了针对 ...
- JAVA系统架构高并发解决方案 分布式缓存 分布式事务解决方案
JAVA系统架构高并发解决方案 分布式缓存 分布式事务解决方案
- ZooKeeper 分布式锁 Curator 源码 03:可重入锁并发加锁
前言 在了解了加锁和锁重入之后,最需要了解的还是在分布式场景下或者多线程并发加锁是如何处理的? 并发加锁 先来看结果,在多线程对 /locks/lock_01 加锁时,是在后面又创建了新的临时节点. ...
- Zookeeper + Guava loading cache 实现分布式缓存
1. 概述 项目中,创建的活动内容存入redis,然后需要用到活动内容的地方,从redis去取,然后参与计算. 活动数据的一个特点是更新不频繁.数据量不大.因为项目部署一般是多机器.多实例,除了red ...
随机推荐
- React 如何适用less
1.使用 create-react-app 创建的项目,默认情况下是看不到 webpack 相关的配置文件,我们需要给它暴露出来,使用下面命令即可: npm run eject 2.添加less np ...
- 【Beta】Scrum meeting 9
目录 写在前面 进度情况 任务进度表 Beta-1阶段燃尽图 遇到的困难 照片 commit记录截图 文档集合仓库 后端代码仓库 技术博客 写在前面 例会时间:5.13 22:30-22:45 例会地 ...
- Gamma阶段第二次scrum meeting
每日任务内容 队员 昨日完成任务 明日要完成的任务 张圆宁 #91 用户体验与优化https://github.com/rRetr0Git/rateMyCourse/issues/91(持续完成) # ...
- 使用Rome读取RSS报错,org.xml.sax.SAXParseException: 前言中不允许有内容。
这是我遇到过的最奇葩的错误 new URL的时候,使用静态变量就会报错org.xml.sax.SAXParseException: 前言中不允许有内容. URL url = new URL(Strin ...
- Delaunay和Voronoi
什么是Delaunay三角剖分? 图1:Delaunay三角剖分偏爱小角度 给定平面中的一组点,三角剖分指的是将平面细分为三角形,这些点为顶点.在图1中,我们在左侧图像上看到了一组地标,在中间图像上看 ...
- 深度相机Astra Pro测试教程
最近在微信群内,很多群友在群友的推荐下,购买了Astra pro的深度相机,价格地道,物超所值!群友反馈积极,所以这里出一波简单的教程. 以下内容知识抛砖引玉,主要讲解windows下和Ubunt ...
- Hadoop深入学习之HA
1. 基本原理 2.x版本中,HDFS架构解决了单点故障问题,即引入双NameNode架构,同时借助共享存储系统来进行元数据的同步,共享存储系统类型一般有几类,如:Shared NAS+NFS.Boo ...
- 图像拼接(image stitching)
# OpenCV中stitching的使用 OpenCV提供了高级别的函数封装在Stitcher类中,使用很方便,不用考虑太多的细节. 低级别函数封装在detail命名空间中,展示了OpenCV算法实 ...
- 【Spring Cloud学习之四】Zuul网关
环境 eclipse 4.7 jdk 1.8 Spring Boot 1.5.2 Spring Cloud 1.2 一.接口网关接口网关:拦截所有的请求,交由接口网关,然后接口网关进行转发,类似ngi ...
- Vue项目引入百度地图
先去百度开放平台申请ak.http://lbsyun.baidu.com/ 进来之后 按照步骤走,先登录百度账号,然后申请成为开发者,然后申请ak密钥 填写完毕后提交,会给你邮箱发个激活邮件 点击申请 ...