java集合中的HashMap源码分析
1.hashMap中的成员分析
transient Node<K,V>[] table; //为hash桶的数量
/**
* The number of key-value mappings contained in this map.
*/
transient int size; //hashMap中键值对的数量 /**
* The number of times this HashMap has been structurally modified
* Structural modifications are those that change the number of mappings in
* the HashMap or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
*/
transient int modCount; //用来记录hashMap被改变的次数,进行fail-fast /**
* The next size value at which to resize (capacity * load factor).
*
* @serial
*/
// (The javadoc description is true upon serialization.
// Additionally, if the table array has not been allocated, this
// field holds the initial array capacity, or zero signifying
// DEFAULT_INITIAL_CAPACITY.)
int threshold; //用来表示HashMap的阙值 threshold = capacity*loadFactor /**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor; //用来表示HashMap的加载因子
2.hashMap中的重要方法分析
(1).hash方法(用来根据key来获取hash值)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); //注意当key为null是会返回0,hashmap允许key为null进行存储,且存在table[0]的位置。
另外会对获取的hashcode进行高低16位按位与,减小hash冲突的概率
}
(2).tableSizeFor(使用此方法来让我们的容量变为2的倍数)
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
(3).put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true); //会去调用putVal方法
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0) //判断table是否为null或table的大小是否为0
n = (tab = resize()).length; //如果上述条件成立,那么调用resize()方法去扩容
if ((p = tab[i = (n - 1) & hash]) == null) //计算插入的元素在hash桶中的位置,若该位置还没有元素
tab[i] = newNode(hash, key, value, null); //新建一个node节点,并将该节点添加到该位置
else { //否则,执行以下代码
Node<K,V> e; K k;
if (p.hash == hash && //判断该位置的第一个元素是否与我们要插入的元素相同
((k = p.key) == key || (key != null && key.equals(k))))
e = p; //如果相同则记录该节点到变量e
else if (p instanceof TreeNode) //否则判断第一个节点是否为树类型的节点
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); //如果是,则调用树类型的插入操作
else { //否则,第一个元素既不与我们要插入的节点相同,又不是树类型的节点,那么去遍历链表
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) { //若节点为空则表示已经遍历到链表的最后,此时新建一个节点并加入到末尾
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st //判断链表的长度是否大于8
treeifyBin(tab, hash); //将链表转为红黑树
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) //如果某个节点与我们即将插入的节点相同,则跳出循环
break;
p = e;
}
}
if (e != null) { // existing mapping for key //此时e节点中记录的是hashMap中与我们要插入的节点相同的节点,在这里统一进行处理
V oldValue = e.value; //记录旧的value值
if (!onlyIfAbsent || oldValue == null) //通过onlyIfAbsent与oldValue的值判断是否要进行覆盖
e.value = value; //覆盖旧的值
afterNodeAccess(e); //此方法与LinkedHashMap相关,是一个回调方法,我们之后的文章再进行分析
return oldValue; //返回旧的值
}
}
++modCount; //代表hashMap的结构被改变
if (++size > threshold) //判断是否要进行扩容
resize();
afterNodeInsertion(evict); //此方法也是与LinkedHashMap相关的方法
return null;
}
(4).resize(用来对hashMap进行扩容)
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table; //记录原来的table
int oldCap = (oldTab == null) ? 0 : oldTab.length; //判断原来的table是否为空,若为空则oldCap = 0,否则oldCap = oldTab.length
int oldThr = threshold; //记录原来的阙值
int newCap, newThr = 0; //创建变量用来记录新的容量和阙值
if (oldCap > 0) { //判断原来的容量是否大于0,由于HashMap是在第一次put是才会进行初始化,因此此方法也是判断table是要扩容还是要初始化.大于0代表已经初始化过了
if (oldCap >= MAXIMUM_CAPACITY) { //如果原来的容量大于0且大于等于最大值
threshold = Integer.MAX_VALUE; //将阙值设为最大值,并返回原来的容量,代表该table已经不能再进行扩容
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold //新的阙值为原来阙值的一倍
}
else if (oldThr > 0) // initial capacity was placed in threshold //如果说oldCap为0(代表hashMap没有被初始化过)且原来的阙值大于0(此处需要看一下hashmap的构造方法)
newCap = oldThr; //将新的容量设置为原来的阙值
else { // zero initial threshold signifies using defaults//否则说明我们在新建hashMap是没有指定初始值或是我们将初始大小设为了0
newCap = DEFAULT_INITIAL_CAPACITY; //设为默认值16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); //阙值设为16*0.75
}
if (newThr == 0) { //如果新的阙值为0(此处表示在新建hashMap是给定了capacity且不为0)
float ft = (float)newCap * loadFactor; //设置为newCap*loadFactor或是最大值
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr; //设置当前的阙值为新的阙值
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; //以新的容量去新建一个table数组(可能是初始化,也可能是扩容)
table = newTab;
if (oldTab != null) { //若原来的table是否为空,代表现在是要进行扩容操作
for (int j = 0; j < oldCap; ++j) { //遍历hash桶
Node<K,V> e;
if ((e = oldTab[j]) != null) { //遍历每一个hash桶中的元素,并记录第一个节点到变量e
oldTab[j] = null; //将原来的位置设为null
if (e.next == null) //如果只有一个元素
newTab[e.hash & (newCap - 1)] = e; //计算新的位置,并插入
else if (e instanceof TreeNode) //如果是树节点,则转为红黑树的扩容操作
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null; //将每一个桶中的元素分为两类,扩容后的位置与原来相同则记录到loHead,loTail这个链表中,扩容后与原来的位置不同则记录到hiHead,hiTail中
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead; //将loHead链表写入到新的table
}
if (hiTail != null) { //将hiHead链表记录到新的table
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
3.hashMap中的一些细节问题
(1).为什么table的大小为2的倍数,且以2倍进行扩容?
① 在传统的散列中我们一般使用奇数作为table的长度,由于奇数的因子只有1与本身,在进行取余操作时可以避免hash冲突的概率。但是当我们在进行resize操作时需要去一个个的去计算新的位置。
② 当我们以二倍扩容后,我们发现每次扩容后只是hashCode多长来了一位计算为,我们只需要去判断多出来的计算位是1 or 0 就可以判断新的位置不变还是在(oldCap+OldPos)的位置。
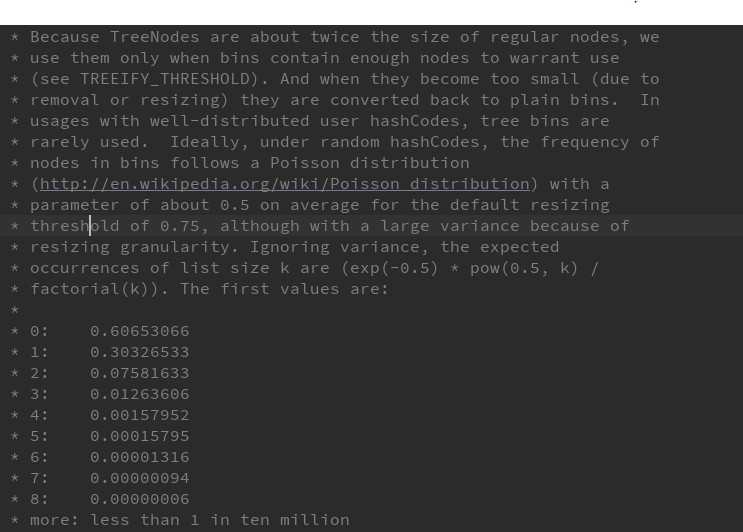
(2).为什么在链表节点大于8是转换为红黑树?(参考源码中的注释)
java集合中的HashMap源码分析的更多相关文章
- Java集合系列[3]----HashMap源码分析
前面我们已经分析了ArrayList和LinkedList这两个集合,我们知道ArrayList是基于数组实现的,LinkedList是基于链表实现的.它们各自有自己的优劣势,例如ArrayList在 ...
- Java集合系列[4]----LinkedHashMap源码分析
这篇文章我们开始分析LinkedHashMap的源码,LinkedHashMap继承了HashMap,也就是说LinkedHashMap是在HashMap的基础上扩展而来的,因此在看LinkedHas ...
- java集合系列之HashMap源码
java集合系列之HashMap源码 HashMap的源码可真不好消化!!! 首先简单介绍一下HashMap集合的特点.HashMap存放键值对,键值对封装在Node(代码如下,比较简单,不再介绍)节 ...
- java集合系列之LinkedList源码分析
java集合系列之LinkedList源码分析 LinkedList数据结构简介 LinkedList底层是通过双端双向链表实现的,其基本数据结构如下,每一个节点类为Node对象,每个Node节点包含 ...
- java集合系列之ArrayList源码分析
java集合系列之ArrayList源码分析(基于jdk1.8) ArrayList简介 ArrayList时List接口的一个非常重要的实现子类,它的底层是通过动态数组实现的,因此它具备查询速度快, ...
- Java集合:HashSet的源码分析
Java集合---HashSet的源码分析 一. HashSet概述: HashSet实现Set接口,由哈希表(实际上是一个HashMap实例)支持.它不保证set 的迭代顺序:特别是它不保证该 ...
- Java集合系列:-----------03ArrayList源码分析
上一章,我们学习了Collection的架构.这一章开始,我们对Collection的具体实现类进行讲解:首先,讲解List,而List中ArrayList又最为常用.因此,本章我们讲解ArrayLi ...
- 【Java集合学习】HashMap源码之“拉链法”散列冲突的解决
1.HashMap的概念 HashMap 是一个散列表,它存储的内容是键值对(key-value)映射. HashMap 继承于AbstractMap,实现了Map.Cloneable.java.io ...
- Java集合系列[1]----ArrayList源码分析
本篇分析ArrayList的源码,在分析之前先跟大家谈一谈数组.数组可能是我们最早接触到的数据结构之一,它是在内存中划分出一块连续的地址空间用来进行元素的存储,由于它直接操作内存,所以数组的性能要比集 ...
随机推荐
- sql unsigned
1.数字类型无符号化,取0以上的值 学习传送门 http://www.cnblogs.com/blankqdb/archive/2012/11/03/blank_qdb.html
- weblogic 初始化
weblogic无法启动,或是忘记了登陆密码,需要初始化,可以删除weblogic配置然后重新生成配置.步骤如下 1> 找到weblogic的启动路径,打开jdeveloper,run后,查看日 ...
- 查询测试程序中的selectOne和selectList函数
selectOne查询一条记录,如果使用selectOne查询多条记录则抛出异常: org.apache.ibatis.exceptions.TooManyResultsException: Expe ...
- Shadow Map 实现极其细节
这里不介绍算法原理,只说说在实现过程中遇到的问题,以及背后的原因.开发环境:opengl 2.0 glsl 1.0. 第一个问题:产生深度纹理. 在opengl中每一次离屏渲染需要向opengl提供 ...
- python socket编程入门(编写server实例)-乾颐堂
python 编写server的步骤: 1. 第一步是创建socket对象.调用socket构造函数.如: socket = socket.socket( family, type ) family参 ...
- Dom4j入门
一.Dom4j API生成xml文件 @Test public void bulidXmlByDom4j(){ //创建document对象 Document document = DocumentH ...
- 获取iOS设备唯一标识
[获取iOS设备唯一标识] 1.已禁用-[UIDevice uniqueIdentifier] 苹果总是把用户的隐私看的很重要.-[UIDevice uniqueIdentifier]在iOS5实际在 ...
- Oracle学习笔记(八)
十一.子查询 1.子查询概述 学习子查询的原因 事例:查询工资比SCOTT高的员工信息 思路:1.scott的工资 select sal from emp where ename='SCOTT'; 2 ...
- Java 代理模式(二) Java中的动态代理
动态代理类 Java动态代理类位于java.lang.reflect包下,一般主要涉及到以下两个类: 1.Interface InvocationHandler 该接口中仅定义了一个方法: Objec ...
- (一)JQuery动态加载js的三种方法
Jquery动态加载js的三种方法如下: 第一种: $.getscript("test.js"); 例如: <script type="text/javascrip ...