Convolution Network及其变种(反卷积、扩展卷积、因果卷积、图卷积)
今天,主要和大家分享一下最近研究的卷积网络和它的一些变种。

首先,介绍一下基础的卷积网络。

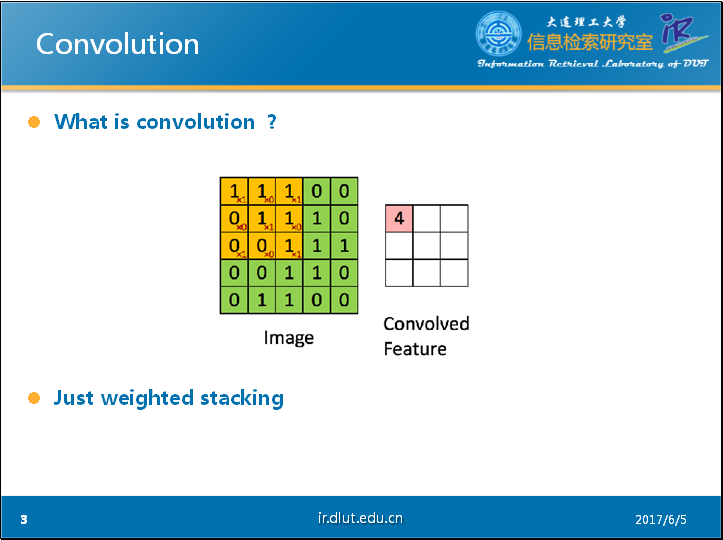
通过PPT上的这个经典的动态图片可以很好的理解卷积的过程。图中蓝色的大矩阵是我们的输入,黄色的小矩阵是卷积核(kernel,filter),旁边的小矩阵是卷积后的输入,通常称为feature map。
从动态图中,我们可以很明白的看出卷积实际上就是加权叠加。
同时,从这个动态图可以很明显的看出,输出的维度小于输入的维度。如果我们需要输出的维度和输入的维度相等,这就需要填充(padding)。

现在我们来看看由padding带来的不同的Conv NN。

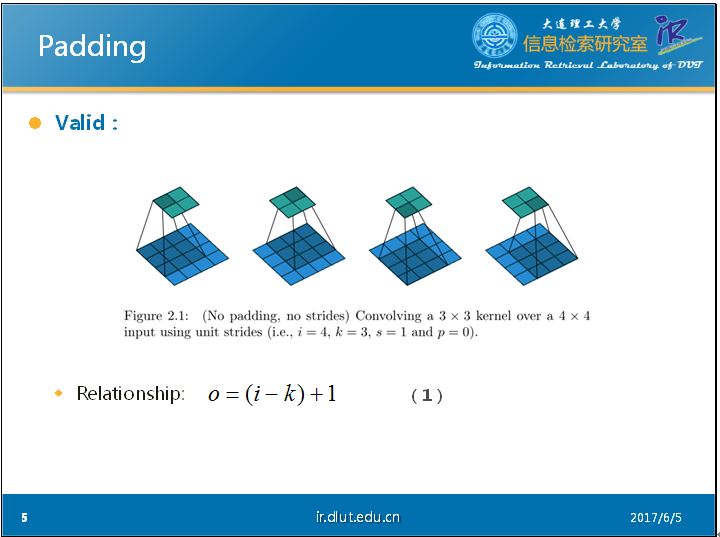
首先,我们来看一下不填充(valid)的Conv NN。
我们可以从PPT中的这个静态的图片看出:输出维度O、卷积核的维度K和输入维度I存在如下关系(公式-1)。其中,我们假定input和kernel都是正方形的,因此,我们可以用4表示4*4的input,3表示3*3的kernel。
当input的维度和output的维度相同时,这种padding叫做same padding。同时也叫做half padding。同样,我们可以根据PPT中的图片看出在包含padding的conv时,输出维度和输入维度对应的关系(公式-2)。其中,p表示padding的维度,在此处,我们同样假定会在长和宽这两个维度进行相同数目的padding。
当我们进行k/2的padding时,我们运用刚才的公式(公式-2)可以得到如下结果。同时如果k是奇数(2n+1),则通过推导可知刚好output维度 = input 维度。

当我们对输入数据的顺序很注重的时候,因果卷积(causal conv)便可以发挥作用。
Causal最初跟随WaveNets一起提出。WaveNets是一个生成模型,主要用来生成音乐。WaveNets是利用卷积来学习t时刻之前的输入数据(音频),来预测t+1时刻的输出。也就是说,该模型输出的最后的X的概率会是如公式-3 所示。在公式-3 和PPT中的动态图片中,我们可以看出,t时刻的输出仅仅依赖于1,2,…,t-1时刻的输入,不会依赖于t+1时刻以及之后时刻的输入。这与BiLSTM的思想截然不同。
当你的模型有这种特殊要求时,便可以采用casual。
在实现上,1D的casual 主要是通过padding来实现的。在2D的casual 主要是通过mask filter map来实现的。


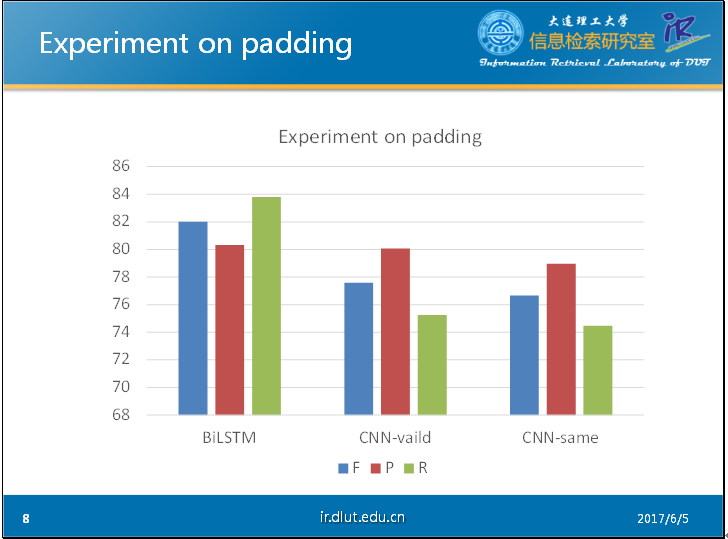
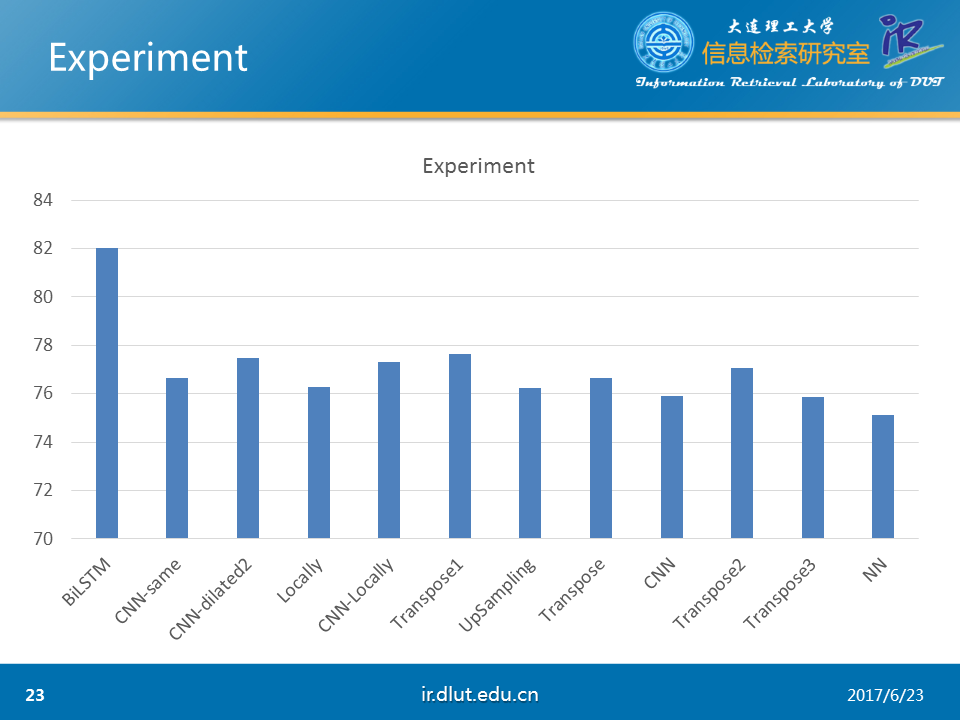
以下是我在CHEMDNER数据集下做的简单的实验。其中输入采用的窗口大小为11. 从图中可以明显看出,没有经过仔细调参的CNN明显弱于BiLSTM,而valid形式的CNN要好于经过padding的CNN。这可能是由于padding会带来噪音,干扰模型。
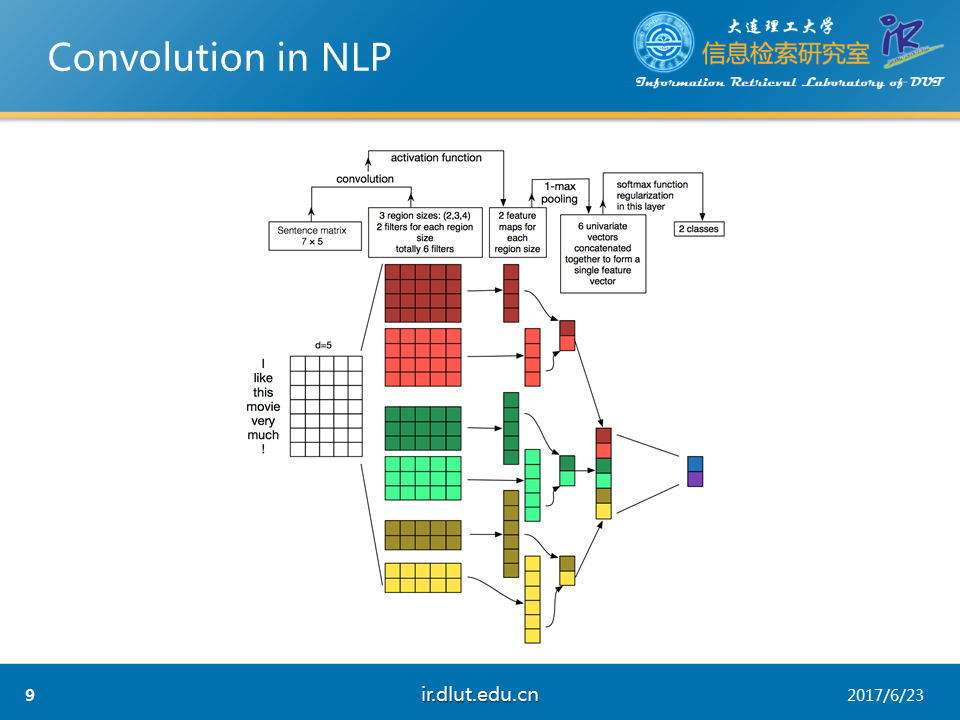
下图,展示了利用CNN来进行NLP任务的流程。可以发现一般会使用多通道的CNN来学习输入的特征,并采用不同的kernel以及pooling。
下面,我们来看一下另一种卷积,扩展卷积(dilated)。扩展卷积目前在NLP上没有应用。主要是用于图像。

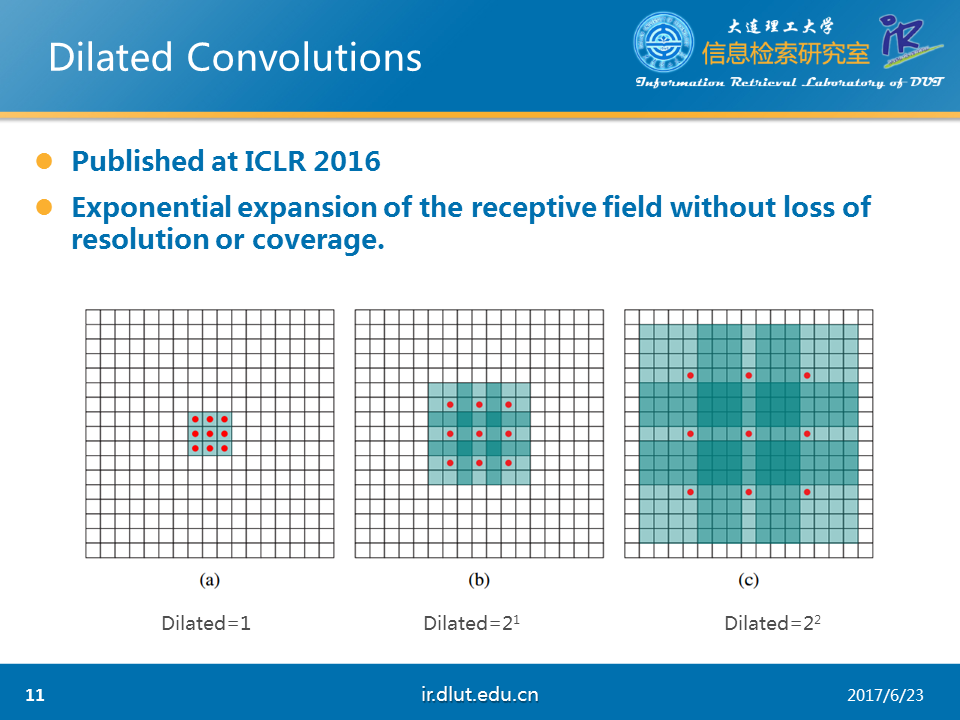
Dilated conv在ICLR 2016上提出。其主要作用是在不增加参数和模型复杂度的条件下,可以指数倍的扩大视觉野(每一个输出是由视觉野大小的输入所决定的)的大小。从下图中可以看出这一效果。蓝色的矩形表示视觉野。红色的小点表示kernel。在图a中,kernel是3*3,视觉野是3*3,dilated=1;在图b中,kernel是3*3,但是视觉野是7*7,dilated=2;在图c中,kernel是3*3,但是视觉野是15*15,dilated=4. 可以看出在dilated(扩展系数)扩大时,视觉野同样扩大。
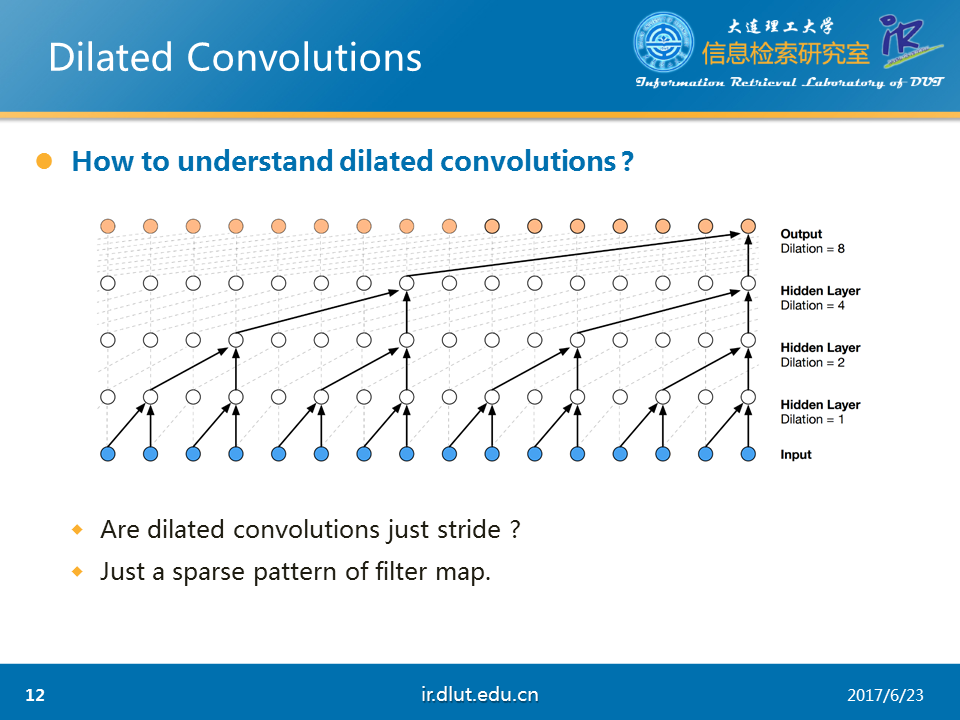
下面,我们使用1D的数据来详细看一下dilated。从下图可以看出,当dilated=2时,每一个输出,“看到了”3个输入(虽然其中2-1=1被忽略了)。当dilated=4时,“看到了”5个输入(4-1=3个被忽略了)
从上面的分析可以看出,dilated与stride非常相似。但dilated与stride可以等同吗?
答案是否定的。我们可以将dilated看成是kernel稀疏化的一种模式。而stride只是dilated的一种特例。根据不同任务,我们可以设计不同的稀疏模式。并不一定要求在宽上的稀疏个数定于长上的稀疏个数。
下图是,论文中给出的效果。该任务是场景分割。Dilated是第4列,标准答案是第5列。可以看出dilated的结果好于其他模型。

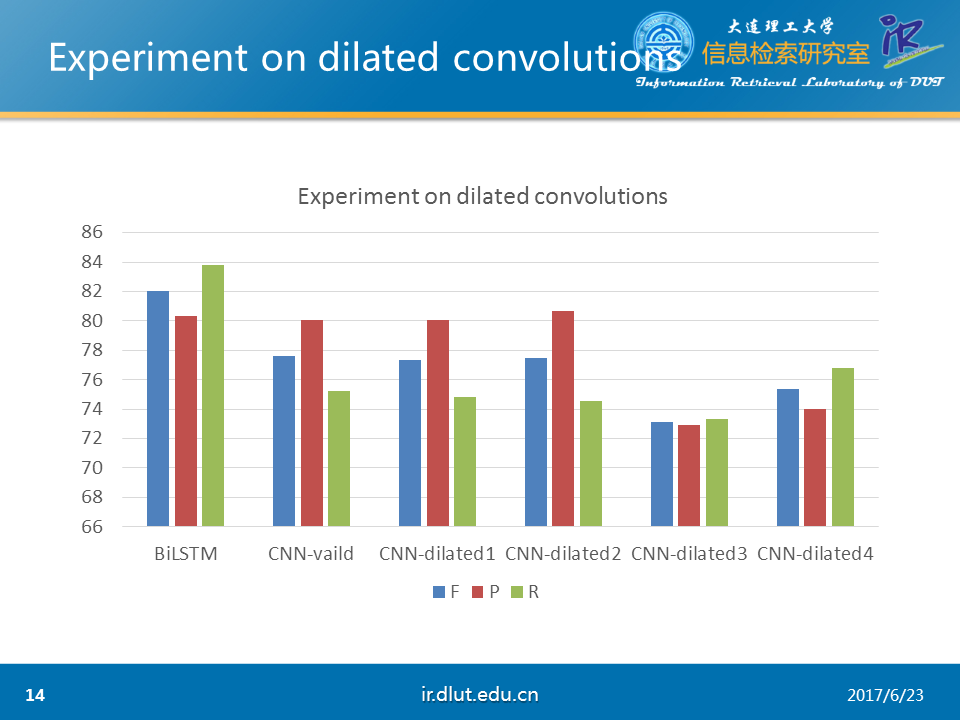
下图同样是在CHEMDNER数据集下做的实验。可以看出dilated较小时与普通CNN性能相同。但较大时性能降低。
由于dilated会稀疏化kernel,所以可能对于NER任务不太适合。但是对于文档分类、关系抽取可能效果会好一些。
下面,我们来看一下反卷积(deconvolution)

我要讲的这篇论文是在CVPR 2010上发表。
Deconv在数学上,是反转卷积的效果。在deconv时,我们仅仅知道h,需要求f和g。然而,在conv时,我们知道g,通过正向传播和方向传播来修改f来得到最好的h。
目前,deconv在实际生活中已经用于信号处理、图像处理等方面。
在deep learning上,主要用于以下三个方面。
l
unsupervised learning: 重构图像
l
CNN可视化:将conv中得到的feature map还原到像素空间,来观察特定的feature map对哪些pattern的图片敏感
l Upsampling:上采样。

Deconv又被称为转置的卷积(transposed
conv)。
我们可以将图中conv的过程用矩阵相乘的形式写出来。其中C表示图中的第一个矩阵。X表示第二个矩阵。Y表示第三个矩阵。在公式的两边,同时乘C的转置便可得到反卷积。
由此可知,在前向传播是使用C,后向传播时使用CT便是普通的conv。反之,则是deconv。

下面,介绍一下deconv在图像重构上的应用。该任务主要是抽取图像的特征。下图是论文提供的结果。可以看出效果不错。

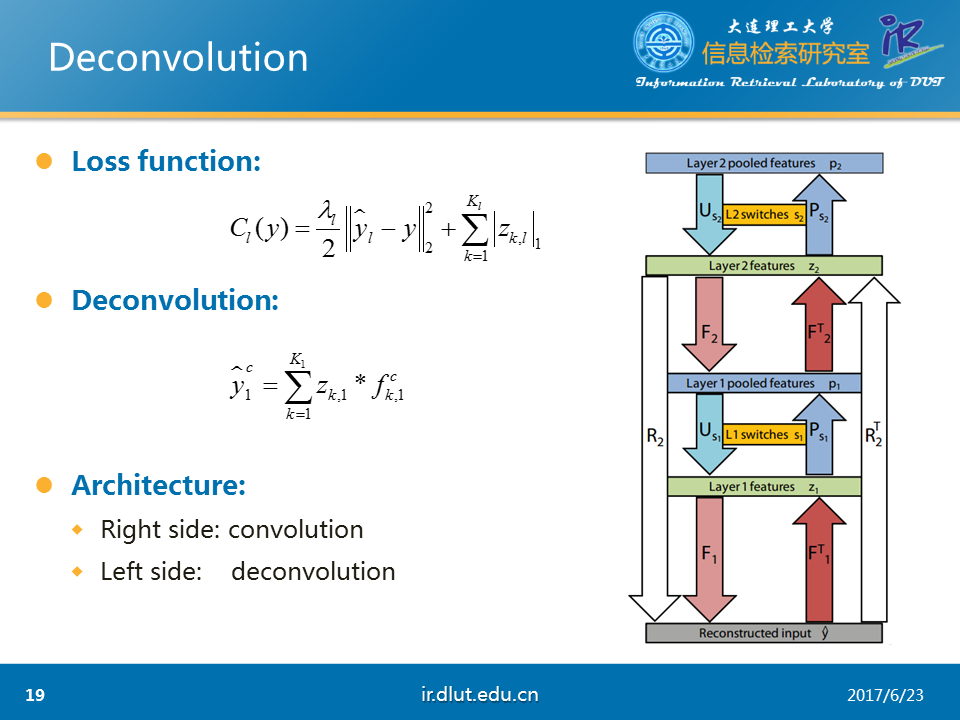
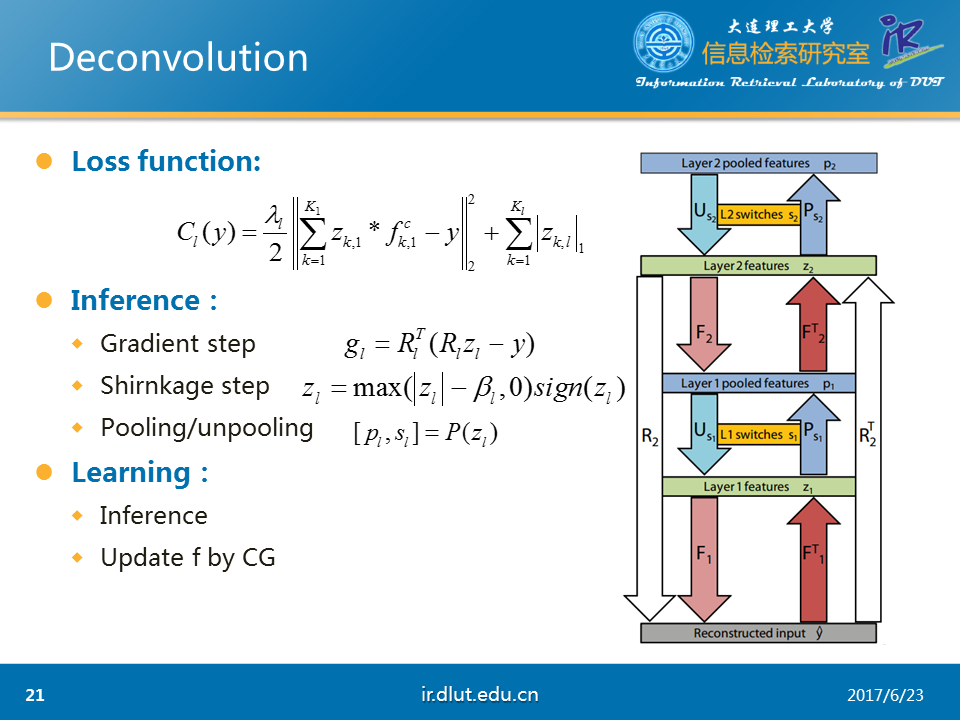
该任务采用的loss如图所示,是典型的重构误差+L1正则。
采用的deconv公式如下。表示重构的输入,z表示conv下的feature map,也就是我们任务的结果,f表示kernel。
旁边的图是系统的大概流程。图中F表示deconv,FT表示conv,P表示pool,U表示unpool。R表示F,U,F操作的联合。RT同理。
在一般的流程中(例如利用CNN来做图像分类时),我们首先将图像的像素点经过FT操作输入到z1层,然后通过P操作,然后得到第一层的输出。随后经过第二层的FT、P操作后,同样可以得到第二层的输出。随后,我们便可以用这个第二层的输出来做相关的任务。比如做图像分类。
但是在deconv中,我们需要反向这一个过程。在开始,假设我们的模型已经训练好了。我的任务是那手上的第二层的输出(同样假设我们已经得到),经过U操作、F操作,可以得到第一层的输出。随后再次经过相同的操作后,可以得到重构的输入。由于我们假设模型已经训练好了,故重构的输入与原始的输入相差会非常小。
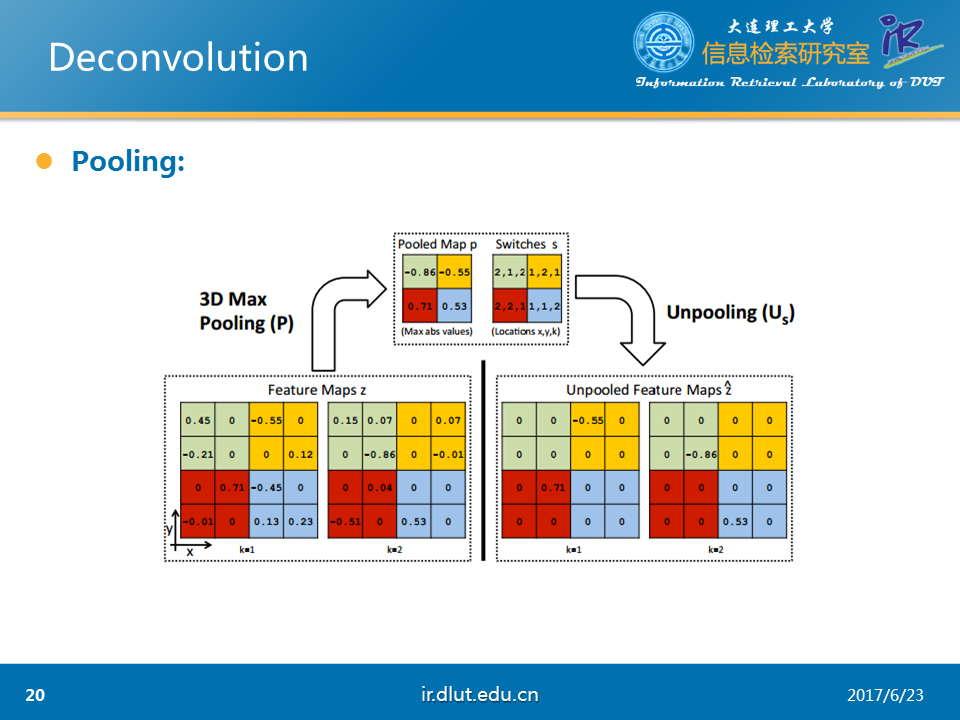
下图是论文中所采用的3D pooling。与我们熟悉的2D的pooling的不同是3D
pooling首先经过2D pooling后,然后在不同的feature map之间再pool一次。所以是3D的。
而unpooling便是3D pooling 的反向过程。
经过3D pooling 和Unpooling后,可以看出结果稀疏了很多。这也是任务的需求。
介绍完大概流程,下面我们来了解一下模型如何训练。由于在deconv中f和g都不知道,所以需要固定f来最优化g和固定g来最优化f。具体来说,在本任务中,deconv中的filter,图片的feature map(z)未知,我们仅仅只知道原始的y,我们需要得到图片的z,也就是在前几页PPT中展示的图片的轮廓图。
为了便于理解,我们将使用训练好的模型称为inference,训练模型称为learning。Inference对应于固定f,最优化z。learning首先会进行inference操作后,然后再固定z,最优化f。
在inference过程中,分为三个步骤,首先在gradient step时,利用反向传播,可以得到loss对于z的梯度。用该梯度更新z。随后,在shirnkage step上,利用图示的函数来稀疏化z,其中,beta是超参。最后,在Pooling step上,经过P操作,便可以得到最后的第二层的输出。总的来说,在inference过程中,我们会重复执行这3步,直到发现最后的loss足够小。
在learning过程中,我们先经过inference后,然后再利用CG算法在固定z下,最优化f。重复经过这两步后,直到发现最后的loss足够下,则该模型已经训练好。
局部连接层(Locally-connected
layers)是conv的一个扩展。在conv中,所有的W都是共享的。但是在locally中,所有的参数并不是共享的。也就是说,在计算上,locally同样会利用W进行conv(加权叠加),但是这个W每个输入都会不一样。
Locally与conv相比,由于W不共享,因而模型能学习到更复杂的特征。同时也越容易过拟合。

下图同样是在CHEMDNER下做的实验。可以看出反卷积(transpose)微好于CNN-same。
下面介绍一下,图卷积(graph
convolution)。

我们首先不介绍graph conv的理论。我们首先介绍如何使用graph conv。
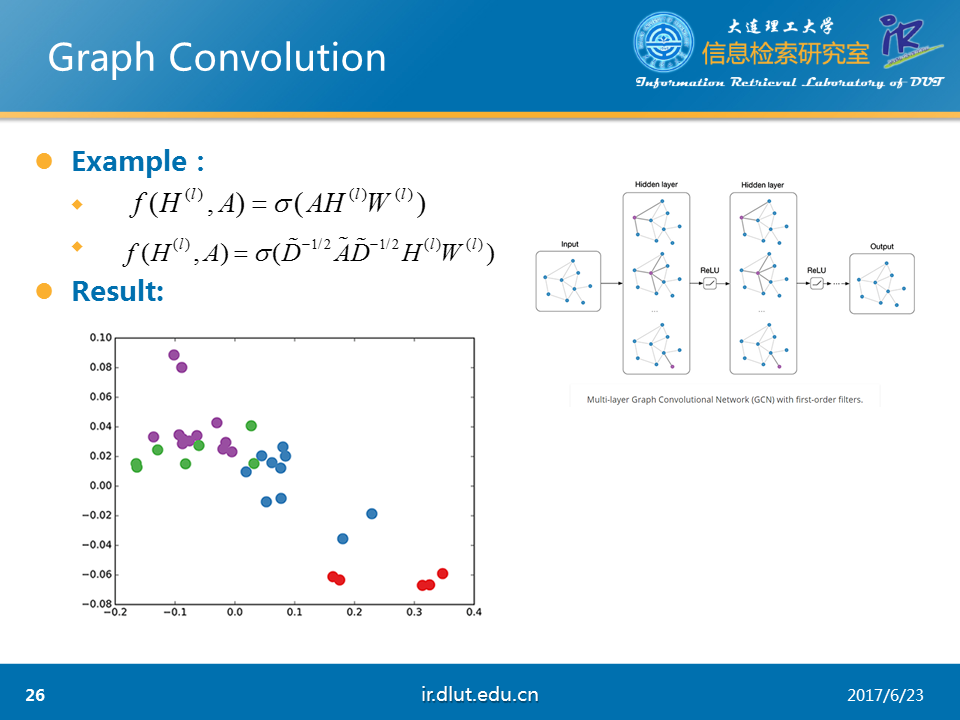
首先,我们知道图 G =(V,E),其中X表示顶点集V的特征,A表示图的结构信息,通常使用邻接矩阵。在一层的graph conv中,使用上层的输出Hl,A和本层的W作为输入,经过某种函数映射f后,便可以得到本层的输出。
下面,我们假设使用如图所示的函数σ。由于A是图的邻接矩阵,所以只有在当前点与其他点有连接的时候才会有值。这样AHW就会表示当前节点的所有邻居在上一层的输出乘以W。这样,我们通过函数σ就仅仅看到了当前点的局部连接。这与conv的局部连接非常相似。因此,我们可以从这一点来理解graph conv。同时,当我们使用多层的graph conv时,H2会利用H1的值,H1利用的是当前节点的1介邻居的信息,而H2便是利用当前节点1介和2介邻居的信息。

我们利用刚才函数的复杂版,在karate-club数据集上,随机初始化W,使用3层的graph conv,将最后的H3输出来,便可以得到如图的结果。可以看到在未训练时,节点之间的向量距离还不错(相同颜色的点距离较近)。
图中Ahat=A+I,Dhat表示Ahat节点度的对角矩阵。
在理论上,我们可以通过两种途径来解释graph
conv。
l 在频谱图理论中,卷积可以表示为矩阵的乘积。将该公式-4运用chebyshev多项式和其他的近似,我们可以得到公式-5.而公式-5 与我们刚才使用的函数σ是基本相同的。
l W-L算法告诉我们,我们可以使用当前节点的邻居表示它。

下面来做一下总结。

总结如下图所示。其中dilated可能在文本分类、关系抽取上会取得较好效果。


Convolution Network及其变种(反卷积、扩展卷积、因果卷积、图卷积)的更多相关文章
- 图卷积神经网络(GCN)入门
图卷积网络Graph Convolutional Nueral Network,简称GCN,最近两年大热,取得不少进展.不得不专门为GCN开一个新篇章,表示其重要程度.本文结合大量参考文献,从理论到实 ...
- Graph Neural Networks:谱域图卷积
以下学习内容参考了:1,2, 0.首先回忆CNN,卷积神经网络的结构和特点 处理的数据特征:具有规则的空间结构(Euclidean domains),都可以采用一维或者二维的矩阵描述.(Convolu ...
- 译:Local Spectral Graph Convolution for Point Set Feature Learning-用于点集特征学习的局部谱图卷积
标题:Local Spectral Graph Convolution for Point Set Feature Learning 作者:Chu Wang, Babak Samari, Kaleem ...
- 最全面的图卷积网络GCN的理解和详细推导,都在这里了!
目录 目录 1. 为什么会出现图卷积神经网络? 2. 图卷积网络的两种理解方式 2.1 vertex domain(spatial domain):顶点域(空间域) 2.2 spectral doma ...
- CNN中各类卷积总结:残差、shuffle、空洞卷积、变形卷积核、可分离卷积等
CNN从2012年的AlexNet发展至今,科学家们发明出各种各样的CNN模型,一个比一个深,一个比一个准确,一个比一个轻量.我下面会对近几年一些具有变革性的工作进行简单盘点,从这些充满革新性的工作中 ...
- 论文解读(NGCF)《LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation》
论文信息 论文标题:LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation论文作者:Xiangn ...
- 谣言检测()《Data Fusion Oriented Graph Convolution Network Model for Rumor Detection》
论文信息 论文标题:Data Fusion Oriented Graph Convolution Network Model for Rumor Detection论文作者:Erxue Min, Yu ...
- 【GCN】图卷积网络初探——基于图(Graph)的傅里叶变换和卷积
[GCN]图卷积网络初探——基于图(Graph)的傅里叶变换和卷积 2018年11月29日 11:50:38 夏至夏至520 阅读数 5980更多 分类专栏: # MachineLearning ...
- 论文解读丨基于局部特征保留的图卷积神经网络架构(LPD-GCN)
摘要:本文提出一种基于局部特征保留的图卷积网络架构,与最新的对比算法相比,该方法在多个数据集上的图分类性能得到大幅度提升,泛化性能也得到了改善. 本文分享自华为云社区<论文解读:基于局部特征保留 ...
随机推荐
- java中你确定用对单例了吗?
作为程序员这样的特殊物种来说,都掌握了一种特殊能力就是编程思想,逻辑比較慎重,可是有时候总会忽略到一些细节,比方我,一直以来总认为Singleton是设计模式里最简单的,不用太在意,然而就是由于这样的 ...
- Python2 列表 cmp() 方法
描述 Python2 列表 cmp() 方法用于比较两个列表,如果 L1 < L2 返回 -1, 如果 L1 == L2 返回 0, 如果 L1 > L2 返回 1. 语法 cmp() 方 ...
- 取出分组后每组的第一条记录(不用group by)按时间排序
--操作日志表 CREATE TABLE [dbo].[JobLog]( [JobLogId] [int] IDENTITY(1,1) NOT NULL, [FunctionId] [nvarchar ...
- 正则表达式写法:Java和Js比较
1.表示数字 Java:\\d Js: \d 比如密码写法,Java中:(^[a-zA-Z\\d]{6,20}$),Js中:/^[a-zA-Z\d]{6,20}$/
- [转]Hspice和Spice Explorer许可文件设置时环境变量FLEXLM_BATCH = 1的一些现象
之前在T400上安装Spice Explorer时碰到运行Spice Explorer时只能看到Log界面,主程序界面自动消失的问题.后经论坛高手指点,在环境变量设置中去掉"FLEXLM_B ...
- android获取对话框文本注意事项
1.View注意设置成final类型如final View layout=.. . 2.获取文本框对象时候格式EditText e = (EditText)layout.findViewById(R. ...
- jvm 性能调优 经验总结---转
最近因项目存在内存泄漏,故进行大规模的JVM性能调优 , 现把经验做一记录. 一.JVM内存模型及垃圾收集算法 1.根据Java虚拟机规范,JVM将内存划分为: New(年轻代) Tenured(年老 ...
- JS页面跳转并及时刷新
"<script type='text/javascript'>alert('操作成功!');window.history.go(-2);window.close();</ ...
- cocos2d-xV3.0rc 环境搭建
一.下载 由于www.cocos2d-x.org很难打开,不知道是不是电信的问题,所以只好在cocoschina论坛里王哲大牛的帖子里找到了一个下载链接:http://126.am/GyU7l0 帖子 ...
- python(34):为什么在Python里推荐使用多进程而不是多线程?
最近在看Python的多线程,经常我们会听到老手说:“Python下多线程是鸡肋,推荐使用多进程!”,但是为什么这么说呢? 要知其然,更要知其所以然.所以有了下面的深 ...