Base64是最常用的编码之一,比如开发中用于传递参数、现代浏览器中的<img />标签直接通过Base64字符串来渲染图片以及用于邮件中等等。Base64编码在RFC2045中定义,它被定义为:Base64内容传送编码被设计用来把任意序列的8位字节描述为一种不易被人直接识别的形式。
Base64是最常用的编码之一,比如开发中用于传递参数、现代浏览器中的<img />标签直接通过Base64字符串来渲染图片以及用于邮件中等等。Base64编码在RFC2045中定义,它被定义为:Base64内容传送编码被设计用来把任意序列的8位字节描述为一种不易被人直接识别的形式。
我们知道,任何数据在计算机中都是以二进制的方式存储的。一个字节为8位,一个字符在计算机中存储为一个或多个字节,比如英文字母、数字以及英文标点符号就是用一个 字节来存储的,通常称为ASCII码。而简体中文、繁体中文、日文以及韩文等都是用多字节来存储的,通常称为多字节字符。因为Base64编码是对字符串的编码表示进行处理的,不同编码的字符串的Base64的结果是不同的,所以我们需要了解基本的字符编码知识。
字符编码基础
计算机最开始只支持ASCII码,一个字符用一个字节表示,只用了低7位,最高位为0,因此总共有128个ASCII码,范围为0~127。后来为了支持多种地区的语言,各大组织机构和IT厂商开始发明它们自己的编码方案,以便弥补ASCII编码的不足,如GB2312编码、GBK编码和Big5编码等。但这些编码都只是针对局部地区或少数语言文字,没有办法表达所有的语言文字。而且这些不同的编码之间并没有任何联系,它们之间的转换需要通过查表来实现。
为了提高计算机的信息处理和交换功能,使得世界各国的文字都能在计算机中处理,从1984年起,ISO组织就开始研究制定一个全新的标准:通用多八位(即多字节)编码字符集(Universal Multiple-Octet Coded Character Set),简称UCS。标准的编号为:ISO 10646。这一标准为世界各种主要语言的字符(包括简体及繁体的中文字)及附加符号,编制统一的内码。
统一码(Unicode)是Universal Code的缩写,是由另一个叫“Unicode学术学会”(The Unicode Consortium)的机构制定的字符编码系统。Unicode与ISO 10646国际编码标准从内容上来说是同步一致的。具体可参考:Unicode 。
ANSI
ANSI不代表具体的编码,它是指本地编码。比如在简体版windows上它表示GB2312编码,在繁体版windows上它表示Big5编码,在日文操作系统上它表示JIS编码。所以如果您新建了个文本文件并保存为ANSI编码,那么您现在应该知道这个文件的编码为本地编码。
Unicode
Unicode编码是和字符表一一映射的。比如56DE代表汉字'回',这种映射关系是固定不变的。通俗的说Unicode编码就是字符表的坐标,通过56DE就能找到汉字'回'。Unicode编码的实现包括UTF8、UTF16、UTF32等等。
Unicode本身定义的就是每个字符的数值,是字符和自然数的映射关系,而UTF-8或者UTF-16甚至UTF-32则定义了如何在字节流中断字,是计算机领域的概念。

通过上图我们知道,UTF-8编码为变长的编码方式,占1~6个字节,可通过Unicode编码值的区间来判断,并且每个组成UTF8字符的字节都是有规律可循的。本文只讨论UTF8和UTF16这两种编码。
UTF16
UTF16编码使用固定的2个字节来存储。因为是多字节存储,所以它的存储方式分为2种:大端序和小端序。UTF16编码是Unicode最直接的实现方式,通常我们在windows上新建文本文件后保存为Unicode编码,其实就是保存为UTF16编码。UTF16编码在windows上采用小端序的方式存储,以下我新建了个文本文件并保存为Unicode编码来测试,文件中只输入了一个汉字'回',之后我用Editplus打开它,切换到十六进制方式查看,如图所示:

我们看到有4个字节,前2个字节FF FE是文件头,表示这是一个UTF16编码的文件,而DE 56则是'回'的UTF16编码的十六进制。我们经常使用的JavaScript语言,它内部就是采用UTF16编码,并且它的存储方式为大端序,来看一个例子:
1 |
<script type="text/javascript"> |
2 |
console.group('Test Unicode: '); |
3 |
console.log(('回'.charCodeAt(0)).toString(16).toUpperCase()); |

很明显跟刚才Editplus显示的不一样,顺序是相反的,这是因为字节序不一样。具体可参考:UTF-16 。
UTF8
UTF8是采用变长的编码方式,为1~6个字节,但通常我们只把它看作单字节或三字节的实现,因为其它情况实在少见。UTF8编码通过多个字节组合的方式来显示,这是计算机处理UTF8的机制,它是无字节序之分的,并且每个字节都非常有规律,详见上图,在此不再详述。
UTF16和UTF8的相互转换
UTF16转UTF8
UTF16和UTF8之间的相互转换可以通过上图的转换表来实现,判断Unicode码所在的区间就可以得到这个字符是由几个字节所组成,之后通过移位来实现。我们用汉字'回'来举一个转换的例子。
我们已经知道汉字'回'的Unicode码是0x56DE,它介于U+00000800 – U+0000FFFF之间,所以它是用三个字节来表示的。

所以我们需要将0x56DE这个双字节的值变为三字节的值,注意上图中的x部分,就是对应0x56DE的各位字节,如果您数一下x的个数,会发现刚好是16位。
转换思路
从0x56DE中取出4位放在低位,并和二进制的1110结合,这就是第一个字节。从0x56DE中剩下的字节中取出6位放在低位,并和二进制的10结合,这就是第二个字节。第三个字节依照类似的方式实现。
代码实现
为了让大家更好的理解,以下代码只是实现汉字'回'的转换,代码如下:
01 |
<script type="text/javascript"> |
04 |
* U+00000000 – U+0000007F 0xxxxxxx |
05 |
* U+00000080 – U+000007FF 110xxxxx 10xxxxxx |
06 |
* U+00000800 – U+0000FFFF 1110xxxx 10xxxxxx 10xxxxxx |
07 |
* U+00010000 – U+001FFFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
08 |
* U+00200000 – U+03FFFFFF 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
09 |
* U+04000000 – U+7FFFFFFF 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
12 |
* '回'的Unicode编码为:0x56DE,它介于U+00000800 – U+0000FFFF之间,所以它占用三个字节。 |
13 |
* U+00000800 – U+0000FFFF 1110xxxx 10xxxxxx 10xxxxxx |
17 |
var byte1 = 0xE0 | ((ucode >> 12) & 0x0F); |
19 |
var byte2 = 0x80 | ((ucode >> 6) & 0x3F); |
21 |
var byte3 = 0x80 | (ucode & 0x3F); |
22 |
var utf8 = String.fromCharCode(byte1) |
23 |
+ String.fromCharCode(byte2) |
24 |
+ String.fromCharCode(byte3); |
26 |
console.group('Test UTF16ToUTF8: '); |

输出的结果看起来像乱码,这是因为JavaScript不知道如何显示UTF8的字符。您或许会说输出不正常转换还有什么用,但您应该知道转换的目的还经常用于传输或API的需要。
UTF8转UTF16
这是UTF16转换到UTF8的逆转换,同样需要对照转换表来实现。还是接上一个例子,我们已经得到了汉字'回'的UTF8编码,这是三个字节的,我们只需要按照转换表来转成双字节的,如图所示,我们需要保留下所有的x。
代码如下:
01 |
<script type="text/javascript"> |
04 |
* U+00000000 – U+0000007F 0xxxxxxx |
05 |
* U+00000080 – U+000007FF 110xxxxx 10xxxxxx |
06 |
* U+00000800 – U+0000FFFF 1110xxxx 10xxxxxx 10xxxxxx |
07 |
* U+00010000 – U+001FFFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
08 |
* U+00200000 – U+03FFFFFF 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
09 |
* U+04000000 – U+7FFFFFFF 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
12 |
* '回'的Unicode编码为:0x56DE,它介于U+00000800 – U+0000FFFF之间,所以它占用三个字节。 |
13 |
* U+00000800 – U+0000FFFF 1110xxxx 10xxxxxx 10xxxxxx |
17 |
var byte1 = 0xE0 | ((ucode >> 12) & 0x0F); |
19 |
var byte2 = 0x80 | ((ucode >> 6) & 0x3F); |
21 |
var byte3 = 0x80 | (ucode & 0x3F); |
22 |
var utf8 = String.fromCharCode(byte1) |
23 |
+ String.fromCharCode(byte2) |
24 |
+ String.fromCharCode(byte3); |
26 |
console.group('Test UTF16ToUTF8: '); |
29 |
/** ------------------------------------------------------------------------------------*/ |
31 |
var c1 = utf8.charCodeAt(0); |
32 |
var c2 = utf8.charCodeAt(1); |
33 |
var c3 = utf8.charCodeAt(2); |
35 |
* 需要通过判断特定位的方式来转换,但这里是已知是三个字节,所以忽略判断,而是直接拿到所有的x,组成16位。 |
36 |
* U+00000800 – U+0000FFFF 1110xxxx 10xxxxxx 10xxxxxx |
38 |
// 丢弃第一个字节的高四位并和第二个字节的高四位组成一个字节 |
39 |
var b1 = (c1 << 4) | ((c2 >> 2) & 0x0F); |
41 |
var b2 = ((c2 & 0x03) << 6) | (c3 & 0x3F); |
43 |
var ucode = ((b1 & 0x00FF) << 8) | b2; |
44 |
console.group('Test UTF8ToUTF16: '); |
45 |
console.log(ucode.toString(16).toUpperCase(), String.fromCharCode(ucode)); |

知道了转换规则,就很容易实现了。
Base64编码
Base64编码要求把3个8位字节(3*8=24)转化为4个6位的字节(4*6=24),之后在6位的前面补两个0,形成8位一个字节的形式。由于2的6次方为64,所以每6个位为一个单元,对应某个可打印字符。当原数据不是3的整数倍时,如果最后剩下两个输入数据,在编码结果后加1个“=;如果最后剩下一个输入数据,编码结果后加2个“=;如果没有剩下任何数据,就什么都不要加,这样才可以保证资料还原的正确性。
转码对照表
每6个单元高位补2个零形成的字节位于0~63之间,通过在转码表中查找对应的可打印字符。“=”用于填充。如下图所示为转码表。
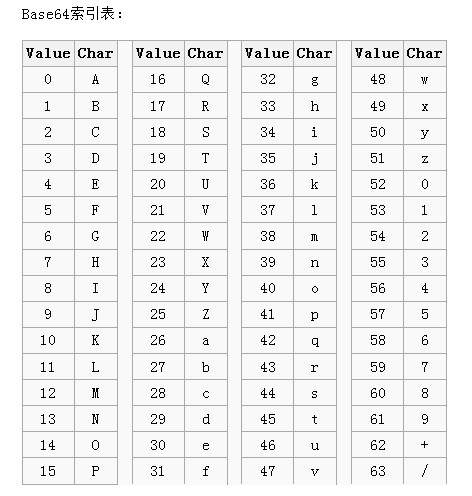
具体可参考: Base64 。
Base64解码
解码是编码的逆过程,先看后面补了几个“=”号,最多只可能补2个“=”号。一个“=”相当于补了2个0,所以去掉后面补的0后,再按8位展开,即可还原。
JavaScript实现Base64的编码和解码
之前已经详细讲解了整个过程,本文的例子都是采用UTF8编码的字符串作为Base64编码的基础。因为JavaScript内部是使用Unicode编码,所以需要有个转换过程,原理之前也详细讲解过并给出了示例,以下是代码实现:
001 |
<script type="text/javascript"> |
004 |
* U+00000000 – U+0000007F 0xxxxxxx |
005 |
* U+00000080 – U+000007FF 110xxxxx 10xxxxxx |
006 |
* U+00000800 – U+0000FFFF 1110xxxx 10xxxxxx 10xxxxxx |
007 |
* U+00010000 – U+001FFFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
008 |
* U+00200000 – U+03FFFFFF 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
009 |
* U+04000000 – U+7FFFFFFF 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
014 |
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', |
015 |
'I', 'J', 'K', 'L', 'M', 'N', 'O' ,'P', |
016 |
'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', |
017 |
'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', |
018 |
'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', |
019 |
'o', 'p', 'q', 'r', 's', 't', 'u', 'v', |
020 |
'w', 'x', 'y', 'z', '0', '1', '2', '3', |
021 |
'4', '5', '6', '7', '8', '9', '+', '/' |
023 |
UTF16ToUTF8 : function(str) { |
024 |
var res = [], len = str.length; |
025 |
for (var i = 0; i < len; i++) { |
026 |
var code = str.charCodeAt(i); |
027 |
if (code > 0x0000 && code <= 0x007F) { |
028 |
// 单字节,这里并不考虑0x0000,因为它是空字节 |
029 |
// U+00000000 – U+0000007F 0xxxxxxx |
030 |
res.push(str.charAt(i)); |
031 |
} else if (code >= 0x0080 && code <= 0x07FF) { |
033 |
// U+00000080 – U+000007FF 110xxxxx 10xxxxxx |
035 |
var byte1 = 0xC0 | ((code >> 6) & 0x1F); |
037 |
var byte2 = 0x80 | (code & 0x3F); |
039 |
String.fromCharCode(byte1), |
040 |
String.fromCharCode(byte2) |
042 |
} else if (code >= 0x0800 && code <= 0xFFFF) { |
044 |
// U+00000800 – U+0000FFFF 1110xxxx 10xxxxxx 10xxxxxx |
046 |
var byte1 = 0xE0 | ((code >> 12) & 0x0F); |
048 |
var byte2 = 0x80 | ((code >> 6) & 0x3F); |
050 |
var byte3 = 0x80 | (code & 0x3F); |
052 |
String.fromCharCode(byte1), |
053 |
String.fromCharCode(byte2), |
054 |
String.fromCharCode(byte3) |
056 |
} else if (code >= 0x00010000 && code <= 0x001FFFFF) { |
058 |
// U+00010000 – U+001FFFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
059 |
} else if (code >= 0x00200000 && code <= 0x03FFFFFF) { |
061 |
// U+00200000 – U+03FFFFFF 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
062 |
} else /** if (code >= 0x04000000 && code <= 0x7FFFFFFF)*/ { |
064 |
// U+04000000 – U+7FFFFFFF 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
070 |
UTF8ToUTF16 : function(str) { |
071 |
var res = [], len = str.length; |
073 |
for (var i = 0; i < len; i++) { |
074 |
var code = str.charCodeAt(i); |
076 |
if (((code >> 7) & 0xFF) == 0x0) { |
079 |
res.push(str.charAt(i)); |
080 |
} else if (((code >> 5) & 0xFF) == 0x6) { |
083 |
var code2 = str.charCodeAt(++i); |
084 |
var byte1 = (code & 0x1F) << 6; |
085 |
var byte2 = code2 & 0x3F; |
086 |
var utf16 = byte1 | byte2; |
087 |
res.push(Sting.fromCharCode(utf16)); |
088 |
} else if (((code >> 4) & 0xFF) == 0xE) { |
090 |
// 1110xxxx 10xxxxxx 10xxxxxx |
091 |
var code2 = str.charCodeAt(++i); |
092 |
var code3 = str.charCodeAt(++i); |
093 |
var byte1 = (code << 4) | ((code2 >> 2) & 0x0F); |
094 |
var byte2 = ((code2 & 0x03) << 6) | (code3 & 0x3F); |
095 |
var utf16 = ((byte1 & 0x00FF) << 8) | byte2 |
096 |
res.push(String.fromCharCode(utf16)); |
097 |
} else if (((code >> 3) & 0xFF) == 0x1E) { |
099 |
// 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
100 |
} else if (((code >> 2) & 0xFF) == 0x3E) { |
102 |
// 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
103 |
} else /** if (((code >> 1) & 0xFF) == 0x7E)*/ { |
105 |
// 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
111 |
encode : function(str) { |
115 |
var utf8 = this.UTF16ToUTF8(str); // 转成UTF8 |
117 |
var len = utf8.length; |
120 |
var c1 = utf8.charCodeAt(i++) & 0xFF; |
121 |
res.push(this.table[c1 >> 2]); |
124 |
res.push(this.table[(c1 & 0x3) << 4]); |
128 |
var c2 = utf8.charCodeAt(i++); |
131 |
res.push(this.table[((c1 & 0x3) << 4) | ((c2 >> 4) & 0x0F)]); |
132 |
res.push(this.table[(c2 & 0x0F) << 2]); |
136 |
var c3 = utf8.charCodeAt(i++); |
137 |
res.push(this.table[((c1 & 0x3) << 4) | ((c2 >> 4) & 0x0F)]); |
138 |
res.push(this.table[((c2 & 0x0F) << 2) | ((c3 & 0xC0) >> 6)]); |
139 |
res.push(this.table[c3 & 0x3F]); |
144 |
decode : function(str) { |
149 |
var len = str.length; |
154 |
code1 = this.table.indexOf(str.charAt(i++)); |
155 |
code2 = this.table.indexOf(str.charAt(i++)); |
156 |
code3 = this.table.indexOf(str.charAt(i++)); |
157 |
code4 = this.table.indexOf(str.charAt(i++)); |
159 |
c1 = (code1 << 2) | (code2 >> 4); |
160 |
c2 = ((code2 & 0xF) << 4) | (code3 >> 2); |
161 |
c3 = ((code3 & 0x3) << 6) | code4; |
163 |
res.push(String.fromCharCode(c1)); |
166 |
res.push(String.fromCharCode(c2)); |
169 |
res.push(String.fromCharCode(c3)); |
174 |
return this.UTF8ToUTF16(res.join('')); |
178 |
console.group('Test Base64: '); |
179 |
var b64 = Base64.encode('Hello, oschina!又是一年春来到~'); |
181 |
console.log(Base64.decode(b64)); |

不得不说,在JavaScript中实现确实很麻烦。我们来看下PHP对同样的字符串编码的结果:

因为字符编码是一样的,所以结果也一样。
- Linux系统Domino704升级为901 64位的步骤及注意事项
[背景] 随便系统业务量的不断增大,应用数据库越来越多.与第三方接口的需求越来越多.文档量越来越多,32位的domino对server的利用率已无法满足系统需求的日益增长,低版本号的domino ...
- oracle 11g自动时间分区备忘
一.时间date类型:create table spdb_demo(outBeginDate date,)partition by range(outBeginDate) interval(numto ...
- 克隆server2008R2造成SID冲突
在云上搞的虚拟机,安装5台winserver2008r2,搭域环境,域环境搭好之后,改域用户为管理员,死活更改不成功,之前在测试环境搞域环境时碰到克隆镜像系统全部还原后搭建域环境不成功的情况,后来全部 ...
- Oracle内存管理(之二)
[深入解析--eygle] 学习笔记 1.2.2 UGA和CGA UGA(用户全局区)由用户会话数据.游标状态和索引区组成.在共享server模式下,一个共享服务进程被多个用户进程共享,此时UGA是S ...
- Python之L.reverse()和L.sort()
# -*- coding: utf-8 -*- #python 27 #xiaodeng #Python之L.reverse()和L.sort() #http://python.jobbole.com ...
- with/as上下文管理器
# -*- coding: utf-8 -*- #python 27 #xiaodeng #Python学习手册 868 #with/as上下文管理器 #with语句的基本格式: with open( ...
- 8、java内部类
一.基本介绍 内部类是指在一个外部类的内部再定义一个类.类名不需要和文件夹相同. 内部类可以是静态static的,也可用public,default,protected和private修饰:而外部顶级 ...
- Linux生成高强度密码
在撰写,自动化脚本.往往需要添加账户及密码.如何自动化填写随机密码,有点意思.... 01.openssl生成密码 [root@mvp ~]# openssl rand -base 14Usage: ...
- Oracle EBS WMS功能介绍(二)
Oracle EBS WMS功能介绍(二) (版权声明,本人原创或者翻译的文章如需转载,如转载用于个人学习,请注明出处.否则请与本人联系,违者必究) 出货物流逻辑主要包括 1. 打包.能够进 ...
- JDK 生成数字证书
JDK(keytool.exe)生成数字证书 2010-11-21 15:52 QUOTE: keytool JAVA是个密钥和证书管理工具.它使用户能够管理自己的公钥/私钥对及相关证书,用于(通过数 ...