python3 scrapy 使用selenium 模拟浏览器操作
零. 在用scrapy爬取数据中,有写是通过js返回的数据,如果我们每个都要获取,那就会相当麻烦,而且查看源码也看不到数据的,所以能不能像浏览器一样去操作他呢?
所以有了->
Selenium 测试直接在浏览器中运行,就像真实用户所做的一样。Selenium 测试可以在 Windows、Linux 和 Macintosh上的 Internet Explorer、Chrome和 Firefox 中运行。其他测试工具都不能覆盖如此多的平台。使用 Selenium 和在浏览器中运行测试还有很多其他好处。
一.http://selenium-python.readthedocs.io/installation.html
下载谷歌浏览器模拟
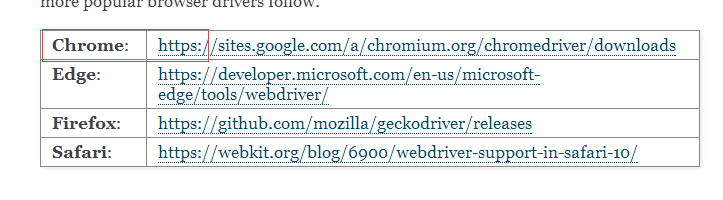
二.安装selenium
pip install selenium
from selenium import webdriver
from scrapy.selector import Selector browser = webdriver.Chrome(executable_path="F:/GitHub/python/chromedriver_win32/chromedriver.exe");
browser.get("https://detail.tmall.com/item.htm?spm=a222t.8063993.4308149192.1.4d1c4546jqNJNV&acm=lb-zebra-164656-978500.1003.4.3165043&id=566510433862&scm=1003.4.lb-zebra-164656-978500.OTHER_222_3165043&scene=taobao_shop&sku_properties=10004:653780895;5919063:6536025")
print(browser.page_source)
t_selector = Selector(text=browser.page_source)
ttt = t_selector.xpath('//*[@class="tm-price"]//text()').extract()
print(ttt)
browser.quit();
模拟访问淘宝
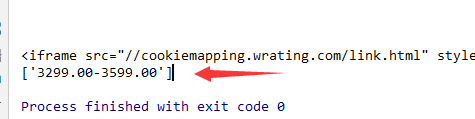
OK! 拿到了淘宝的商品价格了!
python3 scrapy 使用selenium 模拟浏览器操作的更多相关文章
- python下selenium模拟浏览器基础操作
1.安装及下载 selenium安装: pip install selenium 即可自动安装selenium geckodriver下载:https://github.com/mozilla/ge ...
- 孤荷凌寒自学python第八十五天配置selenium并进行模拟浏览器操作1
孤荷凌寒自学python第八十五天配置selenium并进行模拟浏览器操作1 (完整学习过程屏幕记录视频地址在文末) 要模拟进行浏览器操作,只用requests是不行的,因此今天了解到有专门的解决方案 ...
- Python开发爬虫之动态网页抓取篇:爬取博客评论数据——通过Selenium模拟浏览器抓取
区别于上篇动态网页抓取,这里介绍另一种方法,即使用浏览器渲染引擎.直接用浏览器在显示网页时解析 HTML.应用 CSS 样式并执行 JavaScript 的语句. 这个方法在爬虫过程中会打开一个浏览器 ...
- Selenium模拟浏览器抓取淘宝美食信息
前言: 无意中在网上发现了静觅大神(崔老师),又无意中发现自己硬盘里有静觅大神录制的视频,于是乎看了其中一个,可以说是非常牛逼了,让我这个用urllib,requests用了那么久的小白,体会到sel ...
- selenium模拟浏览器对搜狗微信文章进行爬取
在上一篇博客中使用redis所维护的代理池抓取微信文章,开始运行良好,之后运行时总是会报501错误,我用浏览器打开网页又能正常打开,调试了好多次都还是会出错,既然这种方法出错,那就用selenium模 ...
- 浏览器与服务器交互原理以及用java模拟浏览器操作v
浏览器应用服务器JavaPHPApache * 1,在HTTP的WEB应用中, 应用客户端和服务器之间的状态是通过Session来维持的, 而Session的本质就是Cookie, * 简单的讲,当浏 ...
- selenium控制浏览器操作
selenium控制浏览器操作 控制浏览器有哪些操作? 控制页面大小 前进.后退 刷新 自动输入.提交 ........ 控制页面大小,实例: # -*- coding:utf-8 -*- from ...
- 使用selenium模拟浏览器抓取淘宝信息
通过Selenium模拟浏览器抓取淘宝商品美食信息,并存储到MongoDB数据库中. from selenium import webdriver from selenium.common.excep ...
- python爬虫:使用Selenium模拟浏览器行为
前几天有位微信读者问我一个爬虫的问题,就是在爬去百度贴吧首页的热门动态下面的图片的时候,爬取的图片总是爬取不完整,比首页看到的少.原因他也大概分析了下,就是后面的图片是动态加载的.他的问题就是这部分动 ...
随机推荐
- SpringData关键字查询练习
我们在上一节知道SpringData关键字有很多,我就拿几个例子练练手 1.需求我们查询lastName like sun and id < ?的查询 package com.fxr.sprin ...
- (3)在Windows7上搭建Cocos2d-x
工具准备 搭建开发环境需要安装工具包括 Visual Studio python ———(本教程以python2.7.3版本为例),下载地址:http://www.python.org/downloa ...
- Django:学习笔记(8)——文件上传
Django:学习笔记(8)——文件上传 文件上传前端处理 本模块使用到的前端Ajax库为Axio,其地址为GitHub官网. 关于文件上传 上传文件就是把客户端的文件发送给服务器端. 在常见情况(不 ...
- 2017-2018 ACM-ICPC Nordic Collegiate Programming Contest (NCPC 2017) Solution
A - Airport Coffee 留坑. B - Best Relay Team 枚举首棒 #include <bits/stdc++.h> using namespace std; ...
- 【转载】JS Number类型数字位数及IEEE754标准
JS的基础类型Number,遵循 IEEE 754 规范,采用双精度存储(double precision),占用 64 bit.如图 意义 1位用来表示符号位 11位用来表示指数 52位表示尾数 浮 ...
- c++第二十一天
p115~p118: 1.区分int *p[4];和int (*p)[4];.前者是整型指针的数组,后者是指向含有4个整数的数组. 2.规避上述问题的方法就是:使用 auto和 decltype. 3 ...
- STM32端口输入输出模式配置
STM32的IO口模式配置 根据数据手册提供的信息,stm32的io口一共有八种模式,他们分别是: 四种输入模式 上拉输入:通过内部的上拉电阻将一个不确定的信号通过一个电阻拉到高电平. 下拉输入:把电 ...
- Python3.x:函数定义
Python3.x:函数定义 1,函数定义: def 函数名称([参数1,参数2,参数3......]): 执行语句 2,实例一(不带参数和没返回值): def helloWorld(): print ...
- Win32程序支持命令行参数的做法
作者:朱金灿 来源:http://blog.csdn.net/clever101 首先说说Win 32 API程序如何支持命令行参数.Win 32程序的入口函数为: int APIENTRY _tWi ...
- Xshell5 访问虚拟机Ubuntu16.04
1.Ubuntu安装telnet 安装openbsd-inetd sudo apt-get install openbsd-inetd 安装telnetd sudo apt-get install t ...