使用TensorFlow进行中文自然语言处理的情感分析
1 TensorFlow使用
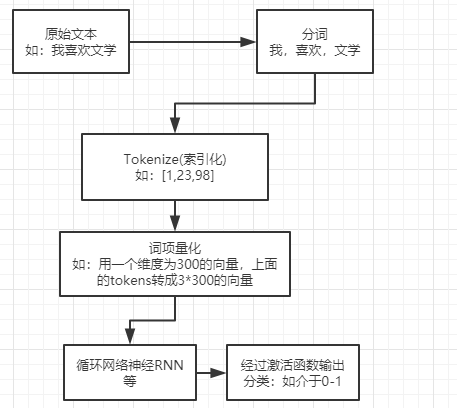
分析流程:
1.1 使用gensim加载预训练中文分词embedding
加载预训练词向量模型:https://github.com/Embedding/Chinese-Word-Vectors/
from gensim.models import KeyedVectors
cn_model = KeyedVectors.load_word2vec_format('H:/词向量/word+Ngram/sgns.zhihu.bigram', binary=False)
查看词语的向量模型表示: 维度为300

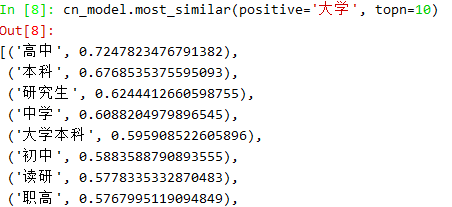
词语相似度:向量余弦值

最相似的词:
1.2 训练样本预料
准备一个训练集,4000个酒店评论,其中2000条为pos积极的,2000条为消极的,每条评论放在一个文件中。
1)文本预处理,分词、索引化
读取数据
import os
import re import jieba
from gensim.models import KeyedVectors cn_model = KeyedVectors.load_word2vec_format('H:/word+Ngram/sgns.zhihu.bigram', binary=False) baseDir = "H:/谭松波老师8++酒店评论++语料/utf-8/4000"
pos_txts = os.listdir("H:/谭松波老师8++酒店评论++语料/utf-8/4000/pos")
neg_txts = os.listdir("H:/bishe/NLP/训练集/谭松波老师8++酒店评论++语料/utf-8/4000/neg") train_text_orig = [] for i in range(len(pos_txts)):
with open(baseDir+"/pos/"+pos_txts[i], errors="ignore", encoding="utf-8") as f:
text = f.read().strip()
train_text_orig.append(text)
f.close()
for i in range(len(neg_txts)):
with open(baseDir+"/neg/"+neg_txts[i], errors="ignore", encoding="utf-8") as f:
text = f.read().strip()
train_text_orig.append(text)
f.close()
分词,建立索引:
# [[句子词索引],[]]
train_tokens = []
for text in train_text_orig:
# 去掉标点符号
text = re.sub("[\s+\.\!\/_,$%^*(+\"\')]+|[+——()?【】“”!,。?、~@#¥%……&*()]+", "", text)
# 结巴分词
cut = jieba.cut(text)
# 结巴分词结果为一个生成器
cut_list = [i for i in cut]
for i, word in enumerate(cut_list):
try:
# 将词转换成索引
cut_list[i] = cn_model.vocab[word].index
except KeyError:
cut_list[i] = 0
train_tokens.append(cut_list)
2)文本长度标准化:
长度参差不齐,我们需要将长度标准化,方便模型进行训练,如果长度太短,会损失太多的信息,而长度太长会浪费太多计算资源
所以说我们要取一个这种的方案,让这个长度基本上涵盖所有的训练样本,又不损失太多的信息
样本长度分布图:
# 看一下样本长度分布图
import matplotlib.pyplot as plt plt.hist(num_tokens, bins=100)
plt.xlim(0, 400)
plt.ylabel("number of tokens")
plt.xlabel("length of tokens")
plt.title("Distribution of tokens length")
plt.show()
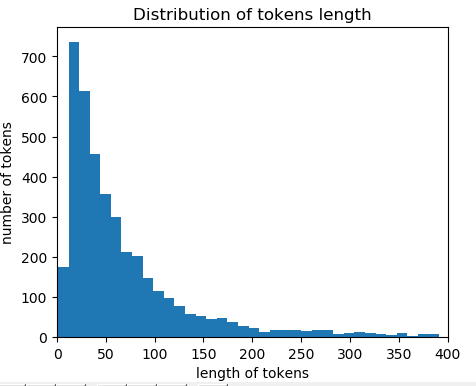
# 取tokens平均值加上两个tokens的标准差
# 假设tokens长度的分布符合正太分布,则max_tokens这个值可以涵盖95%左右的样本
max_tokens = np.mean(num_tokens) + 2 * np.std(num_tokens)
# 取tokens的长度为236时,大约95%左右的样本被涵盖
# 对于长度不足的进行padding,过长的进行修剪
np.sum(num_tokens<max_tokens)/len(num_tokens)
反tokenize
def reverse_token(tokens):
'''
将索引化的句子还原
:param tokens: 句子 [词语,..]
:return:
'''
text = ""
for i in tokens:
if i!=0:
text = text+cn_model.index2word[i]
else:
text =text+" "
return text
3)准备Emdedding Matrix(词向量矩阵)
根据Keras的要求,我们需要准一个维度为(numwords, embeddingdim)的矩阵,num words代表我们使用的词汇的数量,emdedding dimension在我们预训练词向量模型中是300,每个词汇都用长度为300的向量表示(例如: 较好 ->[ 0.056964, -0.127308, -0.118041,...]),注意词向量矩阵是作为训练模型的工具,
# 初始化词向量矩阵-embedding matrix(只用前50000个词)
num_words = 50000
embedding_matrix = np.zeros((num_words, embedding_dim))
# 维度为(50000, 300)的矩阵
for i in range(num_words):
embedding_matrix[i,:]=cn_model[cn_model.index2word[i]] # 将词向量赋值到词向量矩阵中
embedding_matrix = embedding_matrix.astype("float32") # 检查赋值是否正确
np.sum(cn_model[cn_model.index2word[333]]==embedding_matrix[333])
词向量矩阵维度:

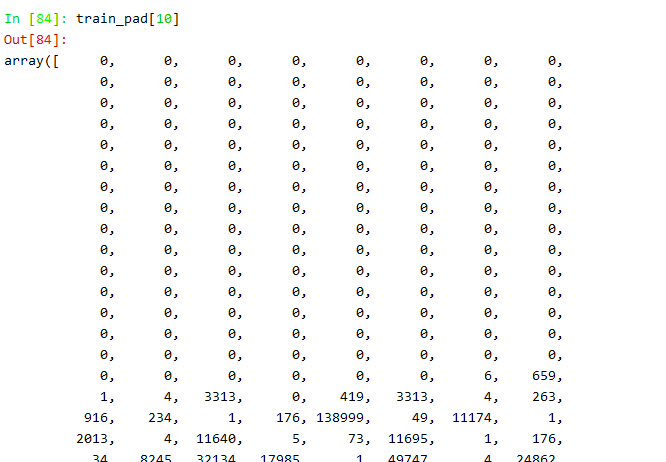
4) padding(填充)和truncating(修剪)
我们把问转换成token(索引)后,每一串索引的长度都不相等,所以为了方便模型的训练我们需要将索引的长度标准化,上面我们选择了使用236这个可以涵盖95%的训练样本的长度,接下来进行padding和truncating,我们一个采用‘pre’的方法,在文本索引的前面填充0。
# 返回一个numpy array
train_pad = pad_sequences(train_tokens, maxlen=max_tokens, padding="pre", truncating="pre")
准备目标向量:
# 准备target向量,前2000个位1,后2000个位0
train_target = np.concatenate((np.ones(2000), np.zeros(2000)))
训练样本和测试样本分离,使用90%的样本来做训练,10%的样本用来做测试:
# 进行训练和测试样本的分割
from sklearn.model_selection import train_test_split
# 90用作训练,正面和负面打乱
X_train, X_test, y_train, y_test = train_test_split(train_pad, train_target, test_size=0.1, random_state=12)

5)使用Keras搭建神经网络模型(LSTM),模型的第一层是Embedding层
end
使用TensorFlow进行中文自然语言处理的情感分析的更多相关文章
- NLP之中文自然语言处理工具库:SnowNLP(情感分析/分词/自动摘要)
一 安装与介绍 1.1 概述 SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个 ...
- Spark2.0 特征提取、转换、选择之二:特征选择、文本处理,以中文自然语言处理(情感分类)为例
特征选择 RFormula RFormula是一个很方便,也很强大的Feature选择(自由组合的)工具. 输入string 进行独热编码(见下面例子country) 输入数值型转换为double(见 ...
- LSTM实现中文文本情感分析
1. 背景介绍 文本情感分析是在文本分析领域的典型任务,实用价值很高.本模型是第一个上手实现的深度学习模型,目的是对深度学习做一个初步的了解,并入门深度学习在文本分析领域的应用.在进行模型的上手实现之 ...
- 中文情感分析——snownlp类库 源码注释及使用
最近发现了snownlp这个库,这个类库是专门针对中文文本进行文本挖掘的. 主要功能: 中文分词(Character-Based Generative Model) 词性标注(TnT 3-gram 隐 ...
- TensorFlow实现文本情感分析详解
http://c.biancheng.net/view/1938.html 前面我们介绍了如何将卷积网络应用于图像.本节将把相似的想法应用于文本. 文本和图像有什么共同之处?乍一看很少.但是,如果将句 ...
- TensorFlow文本情感分析实现
TensorFlow文本情感分析实现 前面介绍了如何将卷积网络应用于图像.本文将把相似的想法应用于文本. 文本和图像有什么共同之处?乍一看很少.但是,如果将句子或文档表示为矩阵,则该矩阵与其中每个单元 ...
- 【HanLP】HanLP中文自然语言处理工具实例演练
HanLP中文自然语言处理工具实例演练 作者:白宁超 2016年11月25日13:45:13 摘要:HanLP是hankcs个人完成一系列模型与算法组成的Java工具包,目标是普及自然语言处理在生产环 ...
- 用python做中文自然语言预处理
这篇博客根据中文自然语言预处理的步骤分成几个板块.以做LDA实验为例,在处理数据之前,会写一个类似于实验报告的东西,用来指导做实验,OK,举例: 一,实验数据预处理(python,结巴分词)1.对于爬 ...
- Tensorflow 免费中文视频教程,开源代码,免费书籍.
Free-Tensorflow Tensorflow 免费中文视频教程,开源代码,免费书籍. 官方教程 官方介绍 https://tensorflow.google.cn/ 安装教程 https:// ...
随机推荐
- 当前安卓App加固到底该如何做到防篡改?
安卓dalvik虚拟机要求dex文件在内存中以明文形式存在,那么任何加壳方法到头来到了内存还是明文存在,各种dump方法终究是可以获得它的.App究竟应该如何加固才能防止被篡改? 加固和 dump ...
- iOS 的各种识别码
在iOS系统中,获取设备唯一标识的方法有很多: 1. x UDID (Unique Device Identifier,已过期) 2. x OPEN UDID (已过期) 3. 广告标示符(IDFA- ...
- 索引+sql优化
索引的概念: 索引是提高查询速度的一种手段.索引有很多种,以下是索引树的结构 要求查询出薪资大于5000的雇员信息,只要在树中找到5000的节点,直接查询该节点右边的数据即可,左边就不用管了,这样提高 ...
- 转载文章 208 个最常见 Java 面试题全解析
最近正值春招,一直在给公司招聘 Java 程序员,我从 2015 年做 TeamLeader 开始就习惯性地收集平时遇到的 Java 技术问题或周围朋友见过的面试题,经过不断筛选,终于凝练成一套实用的 ...
- Elasticsearch 5 Ik+pinyin分词配置详解
版权声明:本文为博主原创文章,地址:http://blog.csdn.net/napoay,转载请留言. 一.拼音分词的应用 拼音分词在日常生活中其实很常见,也许你每天都在用.打开淘宝看一看吧,输入拼 ...
- JAVA数组的定义方式
JAVA中,数组有以下几种定义方式: 1.先定义数组中元素的个数,然后再进行元素赋值 int[] a=new int[2]; a[0]='a'; a[1]='b';a[2]='c'; 2.元素个数与元 ...
- CentOS6.5下telnet服务
00×0 本文介绍Telnet搭建,以及展示这是一个不安全的远程服务. 00×1 服务准备工作 [root@localhost ~]# yum install xinetd telnet-server ...
- Python 的 GIL 是什么鬼,多线程性能究竟如何
作者:卢钧轶(cenalulu) 本文原文地址: http://cenalulu.github.io/python/gil-in-python/ 前言:博主在刚接触Python的时候时常听到GIL这个 ...
- PHP下的浮点运算不准的解决办法
首先看一段代码: 首先看一段代码: <?php $a = 0.1; $b = 0.7; var_dump(($a + $b) == 0.8); 打印出来的值居然为 boolean false P ...
- 数据结构:广义表的实现(Java)
广义表的简单理解在这篇博文中:https://blog.csdn.net/lishanleilixin/article/details/87364496,在此不做赘述. Java实现广义表: pack ...