kaggle-泰坦尼克号Titanic-2
下面我们再来看看各种舱级别情况下各性别的获救情况
fig = plt.figure()
fig.set(alpha=0.5)
plt.title(u"根据舱等级和性别的获救情况",fontproperties=getChineseFont()) ax1 = fig.add_subplot(141)
data_train.Survived[data_train.Sex == 'female'][data_train.Pclass != 3].value_counts().plot(kind='bar', label="female highclass", color='#FA2479') ax1.set_xticklabels(['survived','unsurvived'],rotation=0)
ax1.legend(["female/hight_level"], loc='best') ax2=fig.add_subplot(142, sharey=ax1)
data_train.Survived[data_train.Sex == 'female'][data_train.Pclass == 3].value_counts().plot(kind='bar', label='female, low class', color='pink')
ax2.set_xticklabels(["unsurvived", "survived"], rotation=0)
plt.legend(["female/low_level"], loc='best') ax3=fig.add_subplot(143, sharey=ax1)
data_train.Survived[data_train.Sex == 'male'][data_train.Pclass != 3].value_counts().plot(kind='bar', label='male, high class',color='lightblue')
ax3.set_xticklabels(["unsurvived", "survived"], rotation=0)
plt.legend(["male/hight_level"], loc='best') ax4=fig.add_subplot(144, sharey=ax1)
data_train.Survived[data_train.Sex == 'male'][data_train.Pclass == 3].value_counts().plot(kind='bar', label='male low class', color='steelblue')
ax4.set_xticklabels(["unsurvived", "survived"], rotation=0)
plt.legend(["male/low_level"], loc='best') plt.show()
得到下图

下面再看看大家族对结果有什么影响
g = data_train.groupby(['SibSp','Survived'])
df = pd.DataFrame(g.count()['PassengerId']) print(df)
|
PassengerId |
||
|
SibSp |
Survived |
|
|
0 |
0 |
398 |
|
1 |
210 |
|
|
1 |
0 |
97 |
|
1 |
112 |
|
|
2 |
0 |
15 |
|
1 |
13 |
|
|
3 |
0 |
12 |
|
1 |
4 |
|
|
4 |
0 |
15 |
|
1 |
3 |
|
|
5 |
0 |
5 |
|
8 |
0 |
7 |
g = data_train.groupby(['Parch','Survived'])
df = pd.DataFrame(g.count()['PassengerId'])
print(df)
|
PassengerId |
||
|
Parch |
Survived |
|
|
0 |
0 |
445 |
|
1 |
233 |
|
|
1 |
0 |
53 |
|
1 |
65 |
|
|
2 |
0 |
40 |
|
1 |
40 |
|
|
3 |
0 |
2 |
|
1 |
3 |
|
|
4 |
0 |
4 |
|
5 |
0 |
4 |
|
1 |
1 |
|
|
6 |
0 |
1 |
基本没看出什么特殊关系,暂时作为备选特征。
ticket是船票编号,应该是unique的,和最后的结果没有太大的关系,不纳入考虑的特征范畴
cabin只有204个乘客有值,我们先看看它的一个分布
分布不均匀,应该算作类目型的,本身缺失值就多,还如此不集中,注定很棘手。如果直接按照类目特征处理,太散了,估计每个因子化后的特征都得不到什么权重。加上这么多缺失值,要不先把cabin缺失与否作为条件(虽然这部分信息缺失可能并非未登记,可能只是丢失而已,所以这样做未必妥当)。先在有无cabin信息这个粗粒度上看看Survived的情况。
#cabin的值计数太分散了,绝大多数Cabin值只出现一次。感觉上作为类目,加入特征未必会有效
#那我们一起看看这个值的有无,对于survival的分布状况,影响如何吧
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数 Survived_cabin = data_train.Survived[pd.notnull(data_train.Cabin)].value_counts()
Survived_nocabin = data_train.Survived[pd.isnull(data_train.Cabin)].value_counts()
df=pd.DataFrame({'Notnull':Survived_cabin, 'null':Survived_nocabin}).transpose()
df.plot(kind='bar', stacked=True)
plt.title(u"按Cabin有无看获救情况",fontproperties=getChineseFont())
plt.xlabel(u"Cabin有无",fontproperties=getChineseFont())
plt.ylabel(u"人数",fontproperties=getChineseFont())
plt.show() #似乎有cabin记录的乘客survival比例稍高,那先试试把这个值分为两类,有cabin值/无cabin值,一会儿加到类别特征好了
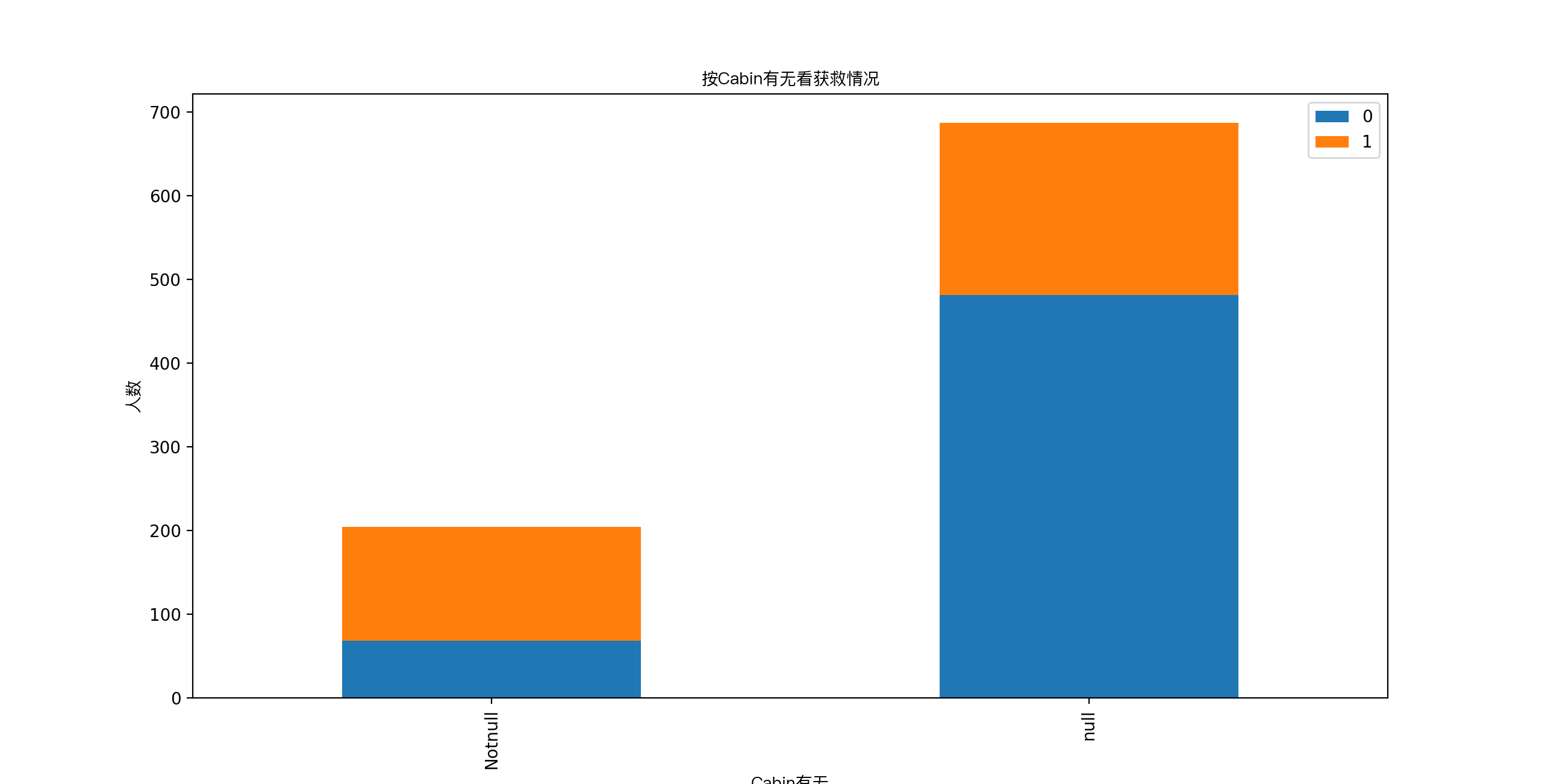
似乎有cabin的存活率高一些。
因此,我们从最明显突出的数据属性开始,cabin和age,有丢失数据对进一步研究影响较大。
Cabin:暂时按照上面分析的,按Cabin有无数据,将这个属性处理成Ye和No两种类型。
Age:对于年龄缺失,我们会有以下几种处理方法
1.如果缺失的样本占总数比例极高,可能就要直接舍弃了,作为特征加入的话,可能导致噪声的产生,影响最终结果。
2.如果缺失值样本适中,并且该属性非连续值特征属性,那就把NaN作为一个新类别,加到类别特征中。
3.如果缺失值样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如这里的age,可以考虑每隔2/3岁为一个步长),然后把它离散化之后把NaN作为一个type加到属性类目中。
4.有些情况下,缺失值个数并不多,也可以试着根据已有的值,拟合一下数据补充上。
本例中,后两种方式应该都是可行的,我们先试着补全。
我们使用scikit-learn中的RandomForest拟合一下缺失的年龄数据
def set_missing_ages(df):
'''
使用RandomForestClassifier填充缺失的年龄
:param df:
:return:
'''
#把已有的数值型特征取出来丢进Random Forest Regressor中
age_df = df[['Age','Fare','Parch','SibSp','Pclass']]
#乘客分成已知年龄和未知年龄两部分
known_age = age_df[age_df.Age.notnull()].as_matrix()
unknown_age = age_df[age_df.Age.isnull()].as_matrix() y = known_age[:,0]#y即目标年龄
X = known_age[:,1:]#X即特征属性值 rfr = RandomForestRegressor(random_state=0,n_estimators=2000,n_jobs=-1)
rfr.fit(X,y) predictedAges = rfr.predict(unknown_age[:,1::])
df.loc[(df.Age.isnull()),'Age'] = predictedAges
return df,rfr def set_Cabin_type(df):
#有客舱信息的为Yes,无客舱信息的为No
df.loc[(df.Cabin.notnull()), 'Cabin'] = "Yes"
df.loc[(df.Cabin.isnull()), 'Cabin'] = "No"
return df data_train, rfr = set_missing_ages(data_train)
data_train = set_Cabin_type(data_train)
print(data_train)
|
PassengerId |
Survived |
Pclass |
Name |
Sex |
Age |
SibSp |
Parch |
Ticket |
Fare |
Cabin |
Embarked |
|
|
0 |
1 |
0 |
3 |
Braund, Mr. Owen Harris |
male |
22.000000 |
1 |
0 |
A/5 21171 |
7.2500 |
No |
S |
|
1 |
2 |
1 |
1 |
Cumings, Mrs. John Bradley (Florence Briggs Th... |
female |
38.000000 |
1 |
0 |
PC 17599 |
71.2833 |
Yes |
C |
|
2 |
3 |
1 |
3 |
Heikkinen, Miss. Laina |
female |
26.000000 |
0 |
0 |
STON/O2. 3101282 |
7.9250 |
No |
S |
|
3 |
4 |
1 |
1 |
Futrelle, Mrs. Jacques Heath (Lily May Peel) |
female |
35.000000 |
1 |
0 |
113803 |
53.1000 |
Yes |
S |
|
4 |
5 |
0 |
3 |
Allen, Mr. William Henry |
male |
35.000000 |
0 |
0 |
373450 |
8.0500 |
No |
S |
|
5 |
6 |
0 |
3 |
Moran, Mr. James |
male |
23.828953 |
0 |
0 |
330877 |
8.4583 |
No |
Q |
|
6 |
7 |
0 |
1 |
McCarthy, Mr. Timothy J |
male |
54.000000 |
0 |
0 |
17463 |
51.8625 |
Yes |
S |
|
7 |
8 |
0 |
3 |
Palsson, Master. Gosta Leonard |
male |
2.000000 |
3 |
1 |
349909 |
21.0750 |
No |
S |
|
8 |
9 |
1 |
3 |
Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) |
female |
27.000000 |
0 |
2 |
347742 |
11.1333 |
No |
S |
|
9 |
10 |
1 |
2 |
Nasser, Mrs. Nicholas (Adele Achem) |
female |
14.000000 |
1 |
0 |
237736 |
30.0708 |
No |
C |
|
10 |
11 |
1 |
3 |
Sandstrom, Miss. Marguerite Rut |
female |
4.000000 |
1 |
1 |
PP 9549 |
16.7000 |
Yes |
S |
|
11 |
12 |
1 |
1 |
Bonnell, Miss. Elizabeth |
female |
58.000000 |
0 |
0 |
113783 |
26.5500 |
Yes |
S |
|
12 |
13 |
0 |
3 |
Saundercock, Mr. William Henry |
male |
20.000000 |
0 |
0 |
A/5. 2151 |
8.0500 |
No |
S |
|
13 |
14 |
0 |
3 |
Andersson, Mr. Anders Johan |
male |
39.000000 |
1 |
5 |
347082 |
31.2750 |
No |
S |
|
14 |
15 |
0 |
3 |
Vestrom, Miss. Hulda Amanda Adolfina |
female |
14.000000 |
0 |
0 |
350406 |
7.8542 |
No |
S |
|
15 |
16 |
1 |
2 |
Hewlett, Mrs. (Mary D Kingcome) |
female |
55.000000 |
0 |
0 |
248706 |
16.0000 |
No |
S |
|
16 |
17 |
0 |
3 |
Rice, Master. Eugene |
male |
2.000000 |
4 |
1 |
382652 |
29.1250 |
No |
Q |
|
17 |
18 |
1 |
2 |
Williams, Mr. Charles Eugene |
male |
32.066493 |
0 |
0 |
244373 |
13.0000 |
No |
S |
|
18 |
19 |
0 |
3 |
Vander Planke, Mrs. Julius (Emelia Maria Vande... |
female |
31.000000 |
1 |
0 |
345763 |
18.0000 |
No |
S |
|
19 |
20 |
1 |
3 |
Masselmani, Mrs. Fatima |
female |
29.518205 |
0 |
0 |
2649 |
7.2250 |
No |
C |
|
20 |
21 |
0 |
2 |
Fynney, Mr. Joseph J |
male |
35.000000 |
0 |
0 |
239865 |
26.0000 |
No |
S |
|
21 |
22 |
1 |
2 |
Beesley, Mr. Lawrence |
male |
34.000000 |
0 |
0 |
248698 |
13.0000 |
Yes |
S |
|
22 |
23 |
1 |
3 |
McGowan, Miss. Anna "Annie" |
female |
15.000000 |
0 |
0 |
330923 |
8.0292 |
No |
Q |
|
23 |
24 |
1 |
1 |
Sloper, Mr. William Thompson |
male |
28.000000 |
0 |
0 |
113788 |
35.5000 |
Yes |
S |
|
24 |
25 |
0 |
3 |
Palsson, Miss. Torborg Danira |
female |
8.000000 |
3 |
1 |
349909 |
21.0750 |
No |
S |
|
25 |
26 |
1 |
3 |
Asplund, Mrs. Carl Oscar (Selma Augusta Emilia... |
female |
38.000000 |
1 |
5 |
347077 |
31.3875 |
No |
S |
|
26 |
27 |
0 |
3 |
Emir, Mr. Farred Chehab |
male |
29.518205 |
0 |
0 |
2631 |
7.2250 |
No |
C |
|
27 |
28 |
0 |
1 |
Fortune, Mr. Charles Alexander |
male |
19.000000 |
3 |
2 |
19950 |
263.0000 |
Yes |
S |
|
28 |
29 |
1 |
3 |
O'Dwyer, Miss. Ellen "Nellie" |
female |
22.380113 |
0 |
0 |
330959 |
7.8792 |
No |
Q |
|
29 |
30 |
0 |
3 |
Todoroff, Mr. Lalio |
male |
27.947206 |
0 |
0 |
349216 |
7.8958 |
No |
S |
|
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
|
861 |
862 |
0 |
2 |
Giles, Mr. Frederick Edward |
male |
21.000000 |
1 |
0 |
28134 |
11.5000 |
No |
S |
|
862 |
863 |
1 |
1 |
Swift, Mrs. Frederick Joel (Margaret Welles Ba... |
female |
48.000000 |
0 |
0 |
17466 |
25.9292 |
Yes |
S |
|
863 |
864 |
0 |
3 |
Sage, Miss. Dorothy Edith "Dolly" |
female |
10.888325 |
8 |
2 |
CA. 2343 |
69.5500 |
No |
S |
|
864 |
865 |
0 |
2 |
Gill, Mr. John William |
male |
24.000000 |
0 |
0 |
233866 |
13.0000 |
No |
S |
|
865 |
866 |
1 |
2 |
Bystrom, Mrs. (Karolina) |
female |
42.000000 |
0 |
0 |
236852 |
13.0000 |
No |
S |
|
866 |
867 |
1 |
2 |
Duran y More, Miss. Asuncion |
female |
27.000000 |
1 |
0 |
SC/PARIS 2149 |
13.8583 |
No |
C |
|
867 |
868 |
0 |
1 |
Roebling, Mr. Washington Augustus II |
male |
31.000000 |
0 |
0 |
PC 17590 |
50.4958 |
Yes |
S |
|
868 |
869 |
0 |
3 |
van Melkebeke, Mr. Philemon |
male |
25.977889 |
0 |
0 |
345777 |
9.5000 |
No |
S |
|
869 |
870 |
1 |
3 |
Johnson, Master. Harold Theodor |
male |
4.000000 |
1 |
1 |
347742 |
11.1333 |
No |
S |
|
870 |
871 |
0 |
3 |
Balkic, Mr. Cerin |
male |
26.000000 |
0 |
0 |
349248 |
7.8958 |
No |
S |
|
871 |
872 |
1 |
1 |
Beckwith, Mrs. Richard Leonard (Sallie Monypeny) |
female |
47.000000 |
1 |
1 |
11751 |
52.5542 |
Yes |
S |
|
872 |
873 |
0 |
1 |
Carlsson, Mr. Frans Olof |
male |
33.000000 |
0 |
0 |
695 |
5.0000 |
Yes |
S |
|
873 |
874 |
0 |
3 |
Vander Cruyssen, Mr. Victor |
male |
47.000000 |
0 |
0 |
345765 |
9.0000 |
No |
S |
|
874 |
875 |
1 |
2 |
Abelson, Mrs. Samuel (Hannah Wizosky) |
female |
28.000000 |
1 |
0 |
P/PP 3381 |
24.0000 |
No |
C |
|
875 |
876 |
1 |
3 |
Najib, Miss. Adele Kiamie "Jane" |
female |
15.000000 |
0 |
0 |
2667 |
7.2250 |
No |
C |
|
876 |
877 |
0 |
3 |
Gustafsson, Mr. Alfred Ossian |
male |
20.000000 |
0 |
0 |
7534 |
9.8458 |
No |
S |
|
877 |
878 |
0 |
3 |
Petroff, Mr. Nedelio |
male |
19.000000 |
0 |
0 |
349212 |
7.8958 |
No |
S |
|
878 |
879 |
0 |
3 |
Laleff, Mr. Kristo |
male |
27.947206 |
0 |
0 |
349217 |
7.8958 |
No |
S |
|
879 |
880 |
1 |
1 |
Potter, Mrs. Thomas Jr (Lily Alexenia Wilson) |
female |
56.000000 |
0 |
1 |
11767 |
83.1583 |
Yes |
C |
|
880 |
881 |
1 |
2 |
Shelley, Mrs. William (Imanita Parrish Hall) |
female |
25.000000 |
0 |
1 |
230433 |
26.0000 |
No |
S |
|
881 |
882 |
0 |
3 |
Markun, Mr. Johann |
male |
33.000000 |
0 |
0 |
349257 |
7.8958 |
No |
S |
|
882 |
883 |
0 |
3 |
Dahlberg, Miss. Gerda Ulrika |
female |
22.000000 |
0 |
0 |
7552 |
10.5167 |
No |
S |
|
883 |
884 |
0 |
2 |
Banfield, Mr. Frederick James |
male |
28.000000 |
0 |
0 |
C.A./SOTON 34068 |
10.5000 |
No |
S |
|
884 |
885 |
0 |
3 |
Sutehall, Mr. Henry Jr |
male |
25.000000 |
0 |
0 |
SOTON/OQ 392076 |
7.0500 |
No |
S |
|
885 |
886 |
0 |
3 |
Rice, Mrs. William (Margaret Norton) |
female |
39.000000 |
0 |
5 |
382652 |
29.1250 |
No |
Q |
|
886 |
887 |
0 |
2 |
Montvila, Rev. Juozas |
male |
27.000000 |
0 |
0 |
211536 |
13.0000 |
No |
S |
|
887 |
888 |
1 |
1 |
Graham, Miss. Margaret Edith |
female |
19.000000 |
0 |
0 |
112053 |
30.0000 |
Yes |
S |
|
888 |
889 |
0 |
3 |
Johnston, Miss. Catherine Helen "Carrie" |
female |
16.232379 |
1 |
2 |
W./C. 6607 |
23.4500 |
No |
S |
|
889 |
890 |
1 |
1 |
Behr, Mr. Karl Howell |
male |
26.000000 |
0 |
0 |
111369 |
30.0000 |
Yes |
C |
|
890 |
891 |
0 |
3 |
Dooley, Mr. Patrick |
male |
32.000000 |
0 |
0 |
370376 |
7.7500 |
No |
Q |
891 rows × 12 columns
使用逻辑回归模型时,需要输入的特征都是数值型特征,我们通常会先对类别型特征因子化/one-hot编码。
例如:
以Embarked为例,原本一个属性维度,因为其取值是[S,C,Q]中任意一个,将其平展开为 Embarked_C,Embarked_S,Embarked_Q三个属性
之前Embarked取值为S的,此时的Embarked_S取值为1,而Embarked_C,Embarked_Q则取值为0
之前Embarked取值为C的,此时的Embarked_C取值为1,而Embarked_S,Embarked_Q则取值为0
之前Embarked取值为Q的,此时的Embarked_Q取值为1,而Embarked_C,Embarked_S则取值为0
下面使用pandas的get_dummies来完成这个工作,并拼接在前面的data_train之上,如下所示:
dummies_Cabin = pd.get_dummies(data_train['Cabin'], prefix='Cabin')
dummies_Embarked = pd.get_dummies(data_train['Embarked'], prefix='Embarked')
dummies_Sex = pd.get_dummies(data_train['Sex'], prefix='Sex')
dummies_Pclass = pd.get_dummies(data_train['Pclass'], prefix='Pclass')
df = pd.concat([data_train, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True) print(df)
|
PassengerId |
Survived |
Age |
SibSp |
Parch |
Fare |
Cabin_No |
Cabin_Yes |
Embarked_C |
Embarked_Q |
Embarked_S |
Sex_female |
Sex_male |
Pclass_1 |
Pclass_2 |
Pclass_3 |
|
|
0 |
1 |
0 |
22.000000 |
1 |
0 |
7.2500 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
|
1 |
2 |
1 |
38.000000 |
1 |
0 |
71.2833 |
0 |
1 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
|
2 |
3 |
1 |
26.000000 |
0 |
0 |
7.9250 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
|
3 |
4 |
1 |
35.000000 |
1 |
0 |
53.1000 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
1 |
0 |
0 |
|
4 |
5 |
0 |
35.000000 |
0 |
0 |
8.0500 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
|
5 |
6 |
0 |
23.828953 |
0 |
0 |
8.4583 |
1 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
1 |
|
6 |
7 |
0 |
54.000000 |
0 |
0 |
51.8625 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
1 |
0 |
0 |
|
7 |
8 |
0 |
2.000000 |
3 |
1 |
21.0750 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
|
8 |
9 |
1 |
27.000000 |
0 |
2 |
11.1333 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
|
9 |
10 |
1 |
14.000000 |
1 |
0 |
30.0708 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
|
10 |
11 |
1 |
4.000000 |
1 |
1 |
16.7000 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
|
11 |
12 |
1 |
58.000000 |
0 |
0 |
26.5500 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
1 |
0 |
0 |
|
12 |
13 |
0 |
20.000000 |
0 |
0 |
8.0500 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
|
13 |
14 |
0 |
39.000000 |
1 |
5 |
31.2750 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
|
14 |
15 |
0 |
14.000000 |
0 |
0 |
7.8542 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
|
15 |
16 |
1 |
55.000000 |
0 |
0 |
16.0000 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
0 |
|
16 |
17 |
0 |
2.000000 |
4 |
1 |
29.1250 |
1 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
1 |
|
17 |
18 |
1 |
32.066493 |
0 |
0 |
13.0000 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
|
18 |
19 |
0 |
31.000000 |
1 |
0 |
18.0000 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
|
19 |
20 |
1 |
29.518205 |
0 |
0 |
7.2250 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
|
20 |
21 |
0 |
35.000000 |
0 |
0 |
26.0000 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
|
21 |
22 |
1 |
34.000000 |
0 |
0 |
13.0000 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
|
22 |
23 |
1 |
15.000000 |
0 |
0 |
8.0292 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
|
23 |
24 |
1 |
28.000000 |
0 |
0 |
35.5000 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
1 |
0 |
0 |
|
24 |
25 |
0 |
8.000000 |
3 |
1 |
21.0750 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
|
25 |
26 |
1 |
38.000000 |
1 |
5 |
31.3875 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
|
26 |
27 |
0 |
29.518205 |
0 |
0 |
7.2250 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
|
27 |
28 |
0 |
19.000000 |
3 |
2 |
263.0000 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
1 |
0 |
0 |
|
28 |
29 |
1 |
22.380113 |
0 |
0 |
7.8792 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
|
29 |
30 |
0 |
27.947206 |
0 |
0 |
7.8958 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
|
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
|
861 |
862 |
0 |
21.000000 |
1 |
0 |
11.5000 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
|
862 |
863 |
1 |
48.000000 |
0 |
0 |
25.9292 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
1 |
0 |
0 |
|
863 |
864 |
0 |
10.888325 |
8 |
2 |
69.5500 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
|
864 |
865 |
0 |
24.000000 |
0 |
0 |
13.0000 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
|
865 |
866 |
1 |
42.000000 |
0 |
0 |
13.0000 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
0 |
|
866 |
867 |
1 |
27.000000 |
1 |
0 |
13.8583 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
|
867 |
868 |
0 |
31.000000 |
0 |
0 |
50.4958 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
1 |
0 |
0 |
|
868 |
869 |
0 |
25.977889 |
0 |
0 |
9.5000 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
|
869 |
870 |
1 |
4.000000 |
1 |
1 |
11.1333 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
|
870 |
871 |
0 |
26.000000 |
0 |
0 |
7.8958 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
|
871 |
872 |
1 |
47.000000 |
1 |
1 |
52.5542 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
1 |
0 |
0 |
|
872 |
873 |
0 |
33.000000 |
0 |
0 |
5.0000 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
1 |
0 |
0 |
|
873 |
874 |
0 |
47.000000 |
0 |
0 |
9.0000 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
|
874 |
875 |
1 |
28.000000 |
1 |
0 |
24.0000 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
|
875 |
876 |
1 |
15.000000 |
0 |
0 |
7.2250 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
|
876 |
877 |
0 |
20.000000 |
0 |
0 |
9.8458 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
|
877 |
878 |
0 |
19.000000 |
0 |
0 |
7.8958 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
|
878 |
879 |
0 |
27.947206 |
0 |
0 |
7.8958 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
|
879 |
880 |
1 |
56.000000 |
0 |
1 |
83.1583 |
0 |
1 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
|
880 |
881 |
1 |
25.000000 |
0 |
1 |
26.0000 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
0 |
|
881 |
882 |
0 |
33.000000 |
0 |
0 |
7.8958 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
|
882 |
883 |
0 |
22.000000 |
0 |
0 |
10.5167 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
|
883 |
884 |
0 |
28.000000 |
0 |
0 |
10.5000 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
|
884 |
885 |
0 |
25.000000 |
0 |
0 |
7.0500 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
|
885 |
886 |
0 |
39.000000 |
0 |
5 |
29.1250 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
|
886 |
887 |
0 |
27.000000 |
0 |
0 |
13.0000 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
|
887 |
888 |
1 |
19.000000 |
0 |
0 |
30.0000 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
1 |
0 |
0 |
|
888 |
889 |
0 |
16.232379 |
1 |
2 |
23.4500 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
|
889 |
890 |
1 |
26.000000 |
0 |
0 |
30.0000 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
|
890 |
891 |
0 |
32.000000 |
0 |
0 |
7.7500 |
1 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
1 |
891 rows × 16 columns
kaggle-泰坦尼克号Titanic-2的更多相关文章
- 数据分析-kaggle泰坦尼克号生存率分析
概述 1912年4月15日,泰坦尼克号在首次航行期间撞上冰山后沉没,2224名乘客和机组人员中有1502人遇难.沉船导致大量伤亡的原因之一是没有足够的救生艇给乘客和船员.虽然幸存下来有一些运气因素,但 ...
- kaggle 泰坦尼克号问题总结
学习了机器学习这么久,第一次真正用机器学习中的方法解决一个实际问题,一步步探索,虽然最后结果不是很准确,仅仅达到了0.78647,但是真是收获很多,为了防止以后我的记忆虫上脑,我决定还是记录下来好了. ...
- 【项目实战】Kaggle泰坦尼克号的幸存者预测
前言 这是学习视频中留下来的一个作业,我决定根据大佬的步骤来一步一步完成整个项目,项目的下载地址如下:https://www.kaggle.com/c/titanic/data 大佬的传送门:http ...
- Kaggle入门——泰坦尼克号生还者预测
前言 这个是Kaggle比赛中泰坦尼克号生存率的分析.强烈建议在做这个比赛的时候,再看一遍电源<泰坦尼克号>,可能会给你一些启发,比如妇女儿童先上船等.所以是否获救其实并非随机,而是基于一 ...
- kaggle& titanic代码
这两天报名参加了阿里天池的’公交线路客流预测‘赛,就顺便先把以前看的kaggle的titanic的训练赛代码在熟悉下数据的一些处理.题目根据titanic乘客的信息来预测乘客的生还情况.给了titan ...
- kaggle Titanic心得
Titanic是kaggle上一个练手的比赛,kaggle平台提供一部分人的特征,以及是否遇难,目的是预测另一部分人是否遇难.目前抽工作之余,断断续续弄了点,成绩为0.79426.在这个比赛过程中,接 ...
- 我的第一个 Kaggle 比赛学习 - Titanic
背景 Titanic: Machine Learning from Disaster - Kaggle 2 年前就被推荐照着这个比赛做一下,结果我打开这个页面便蒙了,完全不知道该如何下手. 两年后,再 ...
- 机器学习案例学习【每周一例】之 Titanic: Machine Learning from Disaster
下面一文章就总结几点关键: 1.要学会观察,尤其是输入数据的特征提取时,看各输入数据和输出的关系,用绘图看! 2.训练后,看测试数据和训练数据误差,确定是否过拟合还是欠拟合: 3.欠拟合的话,说明模 ...
- 20151007kaggle Titanic心得
Titanic是kaggle上一个练手的比赛,kaggle平台提供一部分人的特征,以及是否遇难,目的是预测另一部分人是否遇难.目前抽工作之余,断断续续弄了点,成绩为0.79426.在这个比赛过程中,接 ...
- 如何做到机器学习竞赛Kaggle排名前2%
原创文章,同步首发自作者个人博客 .转载请务必在文章开头显眼处注明出处 摘要 本文详述了如何通过数据预览,探索式数据分析,缺失数据填补,删除关联特征以及派生新特征等方法,在Kaggle的Titanic ...
随机推荐
- Linux内核gpiolib注册建立过程
1.相关的数据结构 struct s3c_gpio_chip { // 这个结构体是三星在移植gpiolib时封装的一个结构体 用来描述一组gpio端口信息 struct gpio_chip chip ...
- test20181016 B君的第三题
题意 B 君的第三题(haskell) 题目描述 大学四年,我为什么,为什么不好好读书,没找到和你一样的工作. B 君某天看到了这样一个题,勾起了无穷的回忆. 输入\(n, k\) 和一棵\(n\) ...
- 使用Spec Markdown 编写手册文档
Spec Markdown 是一个基于markdown 的文档编写工具,安装简单,可以让我们编写出专业的文档 参考项目 https://github.com/rongfengliang/spec-md ...
- redis的maxmemory与maxmemory-policy关系
如果redis配置了maxmemory和maxmemory-policy策略,则当redis内存数据达到maxmemory时,会根据maxmemory-policy配置来淘汰内存数据,以避免OOM.r ...
- POJ3070 矩阵快速幂模板
题目:http://poj.org/problem?id=3070 矩阵快速幂模板.mod写到乘法的定义部分就行了. 别忘了 I ( ) 和 i n i t ( ) 要传引用! #include< ...
- thinkphp 模型验证
<?php class FormModel extends Model { // 自动验证设置 /* * 一:自动验证 自动验证的定义是这样的:array(field,rule,message, ...
- http://www.bootcss.com/p/font-awesome/
集成 将Font Awesome 集成到 Bootstrap 非常容易,还可以被单独使用. 最简单的 Bootstrap + Font Awesome 集成方式 使用这种方式将 Font Awesom ...
- user_add示例
#!/usr/bin/python3# -*- coding: utf-8 -*-# @Time : 2018/5/28 16:51# @File : use_test_add.py 数据 ...
- 使用docker快速搭建环境-安装mysql
install docker sudo apt-get install -y docker.io download mysql sudo docker pull mysql start mysql s ...
- (1/24) 认识webpack
1.什么是webpack (1)webpack是一个模块打包工具,它做的事情是,分析你的项目结构,找到JavaScript模块以及其它的一些浏览器不能直接运行的拓展语言(Scss,TypeScript ...