一致性hash 大众点评订单分库分表实践
井底之蛙 https://mp.weixin.qq.com/s?src=3×tamp=1543228894&ver=1&signature=uF6nV0yYseJ554HjTj8Z2E3ogX05l14gv88Je-2mvUxRt61gl07eWEpf*tU5NHitn3pZ3IEKmlrHK*2xMiceDtgvPpk7y8pZUrAibjAcsmyKQzQiQ9cbjMbhx-GUWVNltVqTj6lv2Jv70sP1nuCFPA==
背景
订单单表早已突破两百G,因查询维度较多,即使加了两个从库,各种索引优化,依然存在很多查询不理想的情况;加之去年大量的抢购活动的开展,数据库达到瓶颈,应用只能通过限速、异步队列等对其进行保护;同时业务需求层出不穷,原有的订单模型很难满足业务需求,但是基于原订单表的DDL又非常吃力,无法达到业务要求;随着这些问题越来越突出,订单数据库的切分就愈发急迫了。
我们的目标是未来十年内不需要担心订单容量的问题
垂直切分
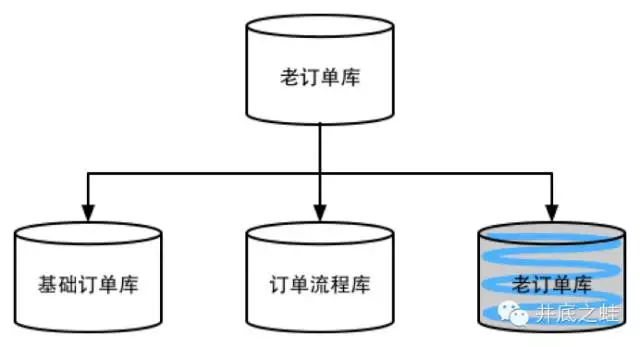
先对订单库进行垂直切分,将原有的订单库分为基础订单库、订单流程库等,这篇文章就不展开讲了。
水平切分
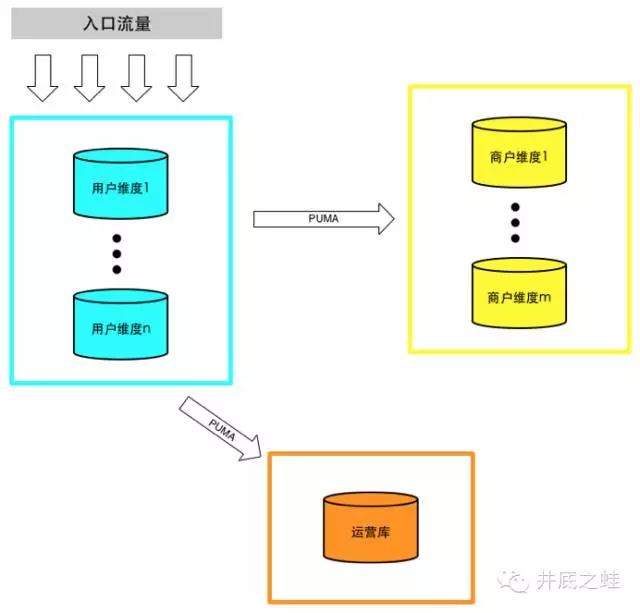
垂直切分缓解了原来单集群的压力,但是在抢购时依然捉襟见肘,并且原有的的订单模型已经无法满足业务需求,于是我们设计了一套新的统一订单模型,为同时满足C端用户、B端商户、客服、运营等的需求,我们分别通过用户ID和商户ID进行切分,并通过PUMA同步到一个运营库
切分策略
1、查询切分
将id和库的mapping关系记录在一个单独的库中
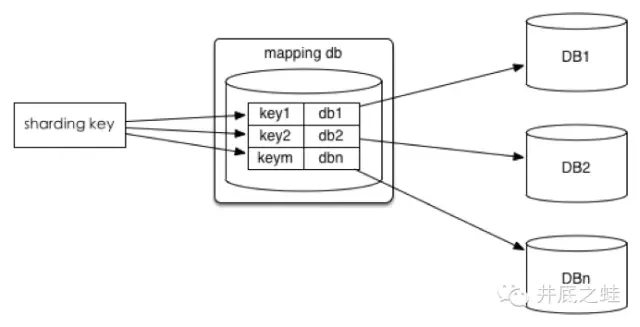
优点:id和库的mapping算法可以随意更改
缺点:引入额外的单点
2、范围切分
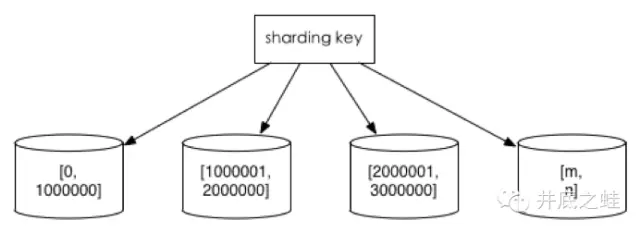
比如按照时间区间或id区间来切分
优点:单表大小可控,天然水平扩展
缺点:无法解决集中写入瓶颈的问题
3、hash切分
一般采用mod来切分,下面着重讲一下mod的策略
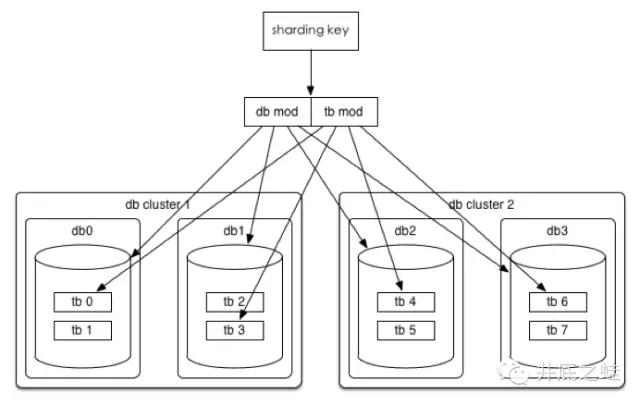
数据水平切分后我们希望是一劳永逸或者是易于水平扩展的,所以推荐采用mod 2^n这种一致性哈希
以统一订单库为例,我们分库分表的方案是32*32的,即通过userId后四位mod 32分到32个库中,同时再将userId后四位div 32 mod 32将每个库分为32个表,共计分为1024张表。线上部署情况为8个集群(主从),每个集群4个库。
为什么说这种方式是易于水平扩展的呢?我们分析如下两个场景
场景一:数据库性能达到瓶颈
方法一:
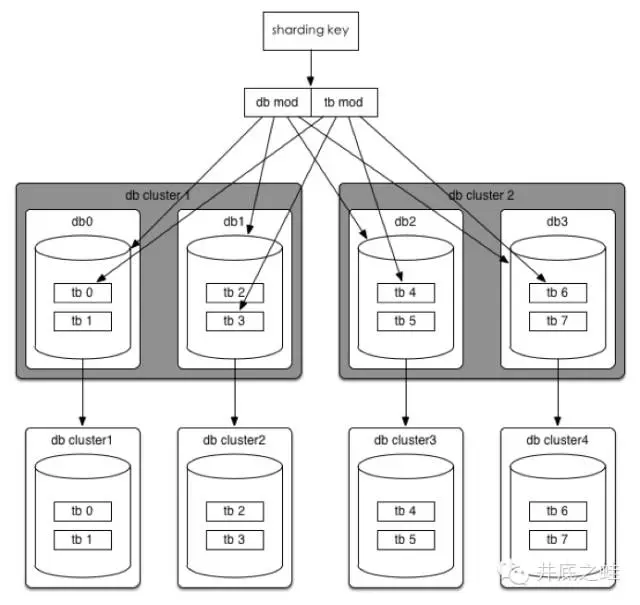
按照现有规则不变,可以直接扩展到32个数据库集群
方法二:
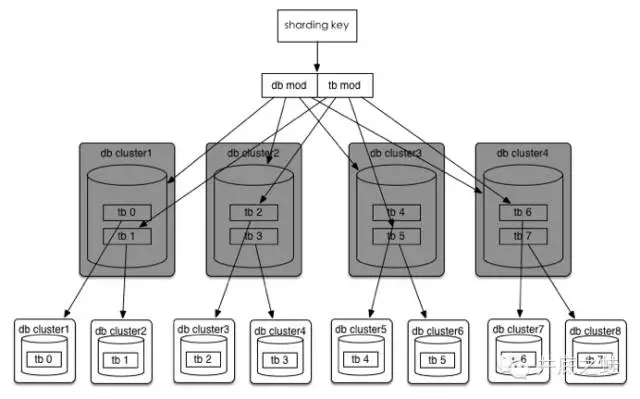
如果32个集群也无法满足需求,那么将分库分表规则调整为(32*2^n)*(32/2^n),可以达到最多1024个集群
场景二:单表容量达到瓶颈(或者1024已经无法满足你)
方法:
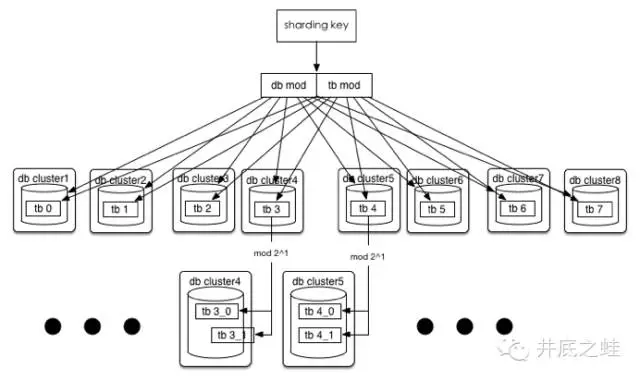
假如单表都已突破200G,200*1024=200T(按照现有的订单模型算了算,大概一万千亿订单,相信这一天,恩,指日可待!),没关系,32*(32*2^n),这时分库规则不变,单库里的表再进行裂变,当然,在目前订单这种规则下(用userId后四位 mod)还是有极限的,因为只有四位,所以最多拆8192个表,至于为什么只取了后四位,后面会有篇幅讲到。
另外一个维度是通过shopId进行切分,规则8*8和userId比较类似,就不再赘述,需要注意的是shop库我们仅存储了订单主表,用来满足shop维度的查询。
唯一ID方案
这个方案也很多,主流的有那么几种
1、利用数据库自增ID
优点:最简单
缺点:单点风险、单机性能瓶颈
2、利用数据库集群并设置相应的步长(Flickr方案)
优点:高可用、ID较简洁
缺点:需要单独的数据库集群
3、Twitter snowflake
优点:高性能高可用、易拓展
缺点:需要独立的集群以及ZK
4、一大波GUID、Random算法
优点:简单
缺点:生成ID较长,有重复几率
我们的方案:
为了减少运营成本并减少额外的风险我们排除了所有需要独立集群的方案,采用了带有业务属性的方案:
时间戳+用户标识码+随机数
有下面几个好处:
方便、成本低
基本无重复的可能
自带分库规则,这里的用户标识码即为用户ID的后四位,在查询的场景下,只需要订单号就可以匹配到相应的库表而无需用户ID,只取四位是希望订单号尽可能的短一些,并且评估下来四位已经足够
可排序,因为时间戳在最前面
当然也有一些缺点,比如长度稍长,性能要比int/bigint的要稍差等。
其他问题?
事务支持:我们是将整个订单领域聚合体切分,维度一致,所以对聚合体的事务是支持的
复杂查询:垂直切分后,就跟join说拜拜了;水平切分后,查询的条件一定要在切分的维度内,比如查询具体某个用户下的各位订单等;禁止不带切分的维度的查询,即使中间件可以支持这种查询,可以在内存中组装,但是这种需求往往不应该在在线库查询或者可以通过其他方法转换到切分的维度以实现。
数据迁移
数据库拆分一般是业务发展到一定规模后的优化和重构,为了支持业务快速上线,很难一开始就分库分表,垂直拆分还好办,改改数据源就搞定了,一旦开始水平拆分,数据清洗就是个大问题,为此,我们经历了以下几个阶段
第一阶段:
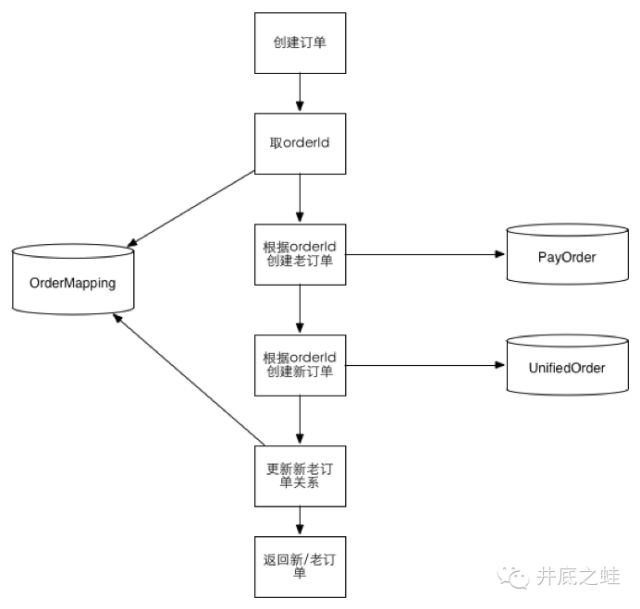
数据库双写(事务成功以老模型为准),查询走老模型
每日job数据对账(通过DW),并将差异补平
通过job导历史数据
第二阶段:
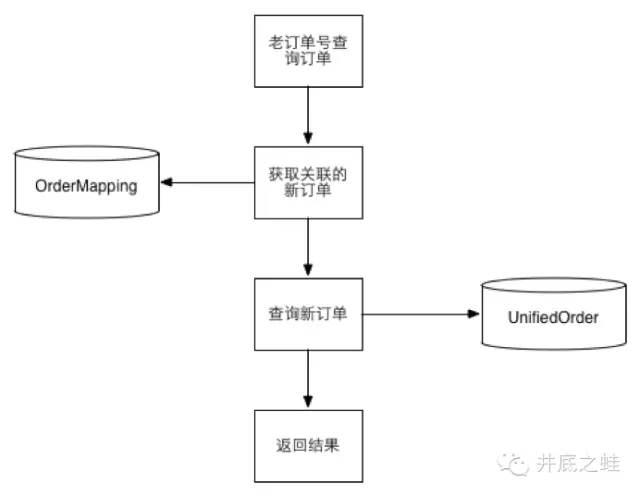
历史数据导入完毕并且数据对账无误
依然是数据库双写,但是事务成功与否以新模型为准,在线查询切新模型
每日job数据对账,将差异补平
第三阶段:
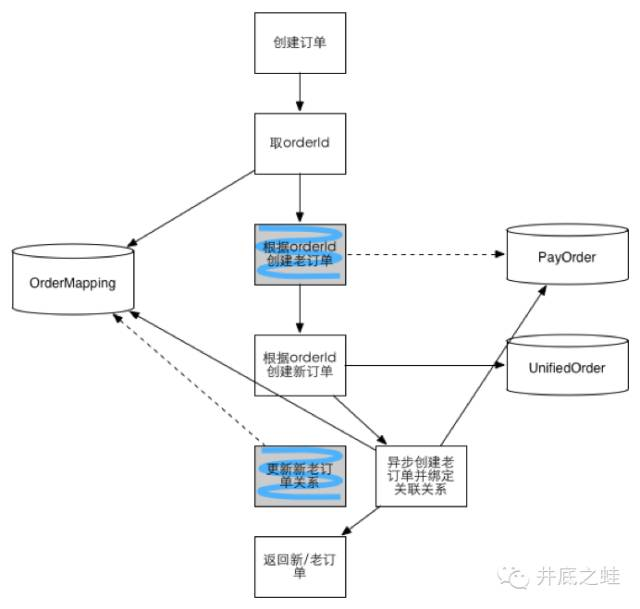
老模型不再同步写入,仅当订单有终态时才会异步补上
此阶段只有离线数据依然依赖老的模型,并且下游的依赖非常多,待DW改造完就可以完全废除老模型了
一些思考:
并非所有表都需要水平拆分,要看增长的类型和速度,水平拆分是大招,拆分后会增加开发的复杂度,不到万不得已不使用
在大规模并发的业务上,尽量做到在线查询和离线查询隔离,交易查询和运营/客服查询隔离
拆分的维度的选择很重要,要尽可能在解决拆分前的问题的基础上,便于开发
数据库没你想象的那么坚强,需要保护,尽量使用简单的、良好索引的查询,这样数据库整体可控,也易于长期容量规划以及水平扩展
最后感谢一下棒棒的DBA团队和数据库中间件团队对项目的大力协助!
-
一致性哈希
- 中文名
- 一致性哈希
- 时 间
- 1997年
- 地 区
- 麻省理工学院
- (参见
- 扩展阅读
哈希算法
在上式中,P表示全部缓冲的大小。不难看出,当缓冲大小发生变化时(从P1到P2),原来所有的哈希结果均会发生变化,从而不满足单调性的要求。
结论
一致性hash 大众点评订单分库分表实践的更多相关文章
- MySQL订单分库分表多维度查询
转自:http://blog.itpub.net/29254281/viewspace-2086198/ MySQL订单分库分表多维度查询 MySQL分库分表,一般只能按照一个维度进行查询. 以订单 ...
- MyCat | 分库分表实践
引言 先给大家介绍2个概念:数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式. 切分模式 一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这种切可以称之 ...
- MariaDB Spider 数据库分库分表实践
分库分表 一般来说,数据库分库分表,有以下做法: 按哈希分片:根据一条数据的标识计算哈希值,将其分配到特定的数据库引擎中: 按范围分片:根据一条数据的标识(一般是值),将其分配到特定的数据库引擎中: ...
- 分布式数据库中间件 MyCat | 分库分表实践
MyCat 简介 MyCat 是一个功能强大的分布式数据库中间件,是一个实现了 MySQL 协议的 Server,前端人员可以把它看做是一个数据库代理中间件,用 MySQL 客户端工具和命令行访问:而 ...
- SpringBoot+MybatisPlus+Mysql+Sharding-JDBC分库分表实践
一.序言 在实际业务中,单表数据增长较快,很容易达到数据瓶颈,比如单表百万级别数据量.当数据量继续增长时,数据的查询性能即使有索引的帮助下也不尽如意,这时可以引入数据分库分表技术. 本文将基于Spri ...
- 分库分表实践-Sharding-JDBC
最近一段时间在研究分库分表的一些问题,正好周末有点时间就简单做下总结,也方便自己以后查看. 关于为什么要做分库分表,什么是水平分表,垂直分表等概念,相信大家都知道,这里就不在赘述了. 本文只讲述使用S ...
- 面试官:"谈谈分库分表吧?"
原文链接:面试官:"谈谈分库分表吧?" 面试官:“有并发的经验没?” 应聘者:“有一点.” 面试官:“那你们为了处理并发,做了哪些优化?” 应聘者:“前后端分离啊,限流啊 ...
- mysql分库分表那些事
为什么使用分库分表? 如下内容,引用自 Sharding Sphere 的文档,写的很大气. <ShardingSphere > 概念 & 功能 > 数据分片> 传统的 ...
- OneProxy分库分表演示--楼方鑫
OneProxy分库分表演示 (杭州平民软件有限公司) OneProxy是为MySQL精心设计的数据访问层,可以为任何开发语言提供对MySQL数据库的智能数据路由功能,比如单点切换.读写分离.分库分表 ...
随机推荐
- 扒一扒MathType不为人知的技巧
MathType作为一款编辑数学公式的神器,很多人在使用它时只是很简单地使用了一些最基本的模板,很多功能都没有使用.MathType功能比你想象中的大很多,今天我们就来扒一扒MathType那些不为人 ...
- 如何用MathType快速输入公式
我们在写论文的时候,如果涉及到数学公式的话,我们一般都会使用MathType软件,但同时对于一些新手来说不太用使用此款软件,输入公式时就会很慢,今天教大家如何利用MathType快速输入公式. 具体方 ...
- 解决IE6双倍边距BUG
解决IE6双倍边距BUG,只要满足下面3个条件才会出现这个BUG: 1)要为块状元素; 2)要左侧浮动; 3)要有左外边距(margin-left); 解决这个BUG很容易,只需要在相应的块状元素的C ...
- VR资源浏览网站
https://my.matterport.com 资源 https://my.matterport.com/show/?m=kCeVCzCjQ5s
- python常用内置模块,执行系统命令的模块
Subprocess模块 python3.5将使用Subprocess模块跟操作系统进行交互,比如系统命令,他将替换 os.system os.spawn* subprocess.run()方法封装的 ...
- ionic 下拉刷新,上拉加载更多
1)下拉刷新用的是 ion-refresher,使用示例如下: <ion-refresher pulling-text="Pull to refresh..." on-ref ...
- ZooKeeper(六)-- CAP和BASE理论、ZAB协议
一.CAP理论和BASE理论 1.CAP理论 CAP理论,指的是在一个分布式系统中,不可能同时满足Consistency(一致性). Availability(可用性).Partition toler ...
- 简要说说NUC972和linux的那些大坑
刚开始装虚拟机,按照步骤,一步一步,装完,发现虚拟机连不上网,后来在网上得知得需要启动虚拟机设置,可是观察我的虚拟机并没有该选项,起初我认为是版本的问题,可是后来才发现,一时贪便宜,图省事,就没有注册 ...
- 微信开放平台全网发布时,检测失败 —— C#
主要就是三个:返回API文本消息,返回普通文本消息,发送事件消息 --会出现失败的情况 (后续补充说明:出现检测出错,不一定是代码出现了问题,也有可能是1.微信方面检测时出现服务器请求失败,2.我 ...
- Python-Numpy的tile函数用法
1.函数的定义与说明 函数格式tile(A,reps) A和reps都是array_like A的类型众多,几乎所有类型都可以:array, list, tuple, dict, matrix以及基本 ...