kaggle之数据分析从业者用户画像分析
数据为kaggle社区发布的数据分析从业者问卷调查分析报告,其中涵盖了关于该行业不同维度的问题及调查结果。本文的目的为提取有用的数据,进行描述性展示。帮助新从业的人员更全方位地了解这个行业。
参考学习视频:http://www.tianshansoft.com/
数据集:https://pan.baidu.com/s/1o7BFzFO
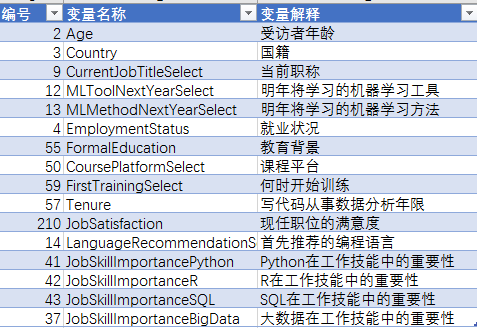
变量说明
数据中包含228个变量,提取其中的一些较有价值的变量进行描述性分析
数据处理
survey <-read.csv(stringsAsFactors = F,file = 'F:\\R/数据科学社区调查/multipleChoiceResponses.csv',header=T,sep=',')
class(survey)
table(survey$Country) #统计每个国家参与人数
查看国家时,发现国家中中国被切分成共和国,民国,台湾,此处自行统一为中国
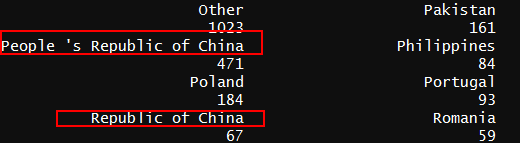
#将大陆,中华民国,台湾统一为中国
survey$Country <- ifelse(survey$Country=="People 's Republic of China"
| survey$Country=='Republic of China'
| survey$Country=='Taiwan'
,'China',survey$Country)
数据描述性展示
探索数据从业者中年龄最小(中位数)的十个国家
#将数据按国家分类,并求年龄的中位数
Country_age <- survey %>% group_by(Country) %>%
summarise(Age_median=median(Age,na.rm = T)) %>%
arrange(Age_median)
head(Country_age)
#绘图,探索数据科学从业者年龄中位数最小的十个国家
p1 <-ggplot(data = head(Country_age,10),aes(reorder(Country,Age_median),Age_median,fill=Country))+
geom_bar(stat='identity')+coord_flip()+
labs(x='年龄',y='国家',title='探索不同国家数据从业者的平均年龄')+
geom_text(aes(label=round(Age_median,0)),hjust=1.5)+
theme(legend.position = 'none',plot.title=element_text(hjust = 0.3))
#绘图,探索数据科学从业者年龄中位数最大的十个国家
p2 <- ggplot(data = tail(Country_age,10),aes(reorder(Country,Age_median),Age_median,fill=Country))+
geom_bar(stat='identity')+coord_flip()+
labs(x='年龄',y='国家')+
geom_text(aes(label=round(Age_median,0)),hjust=1.5)+
theme(legend.position = 'none')
#合并两张图
library(Rmisc)
multiplot(p1,p2,cols = 1)
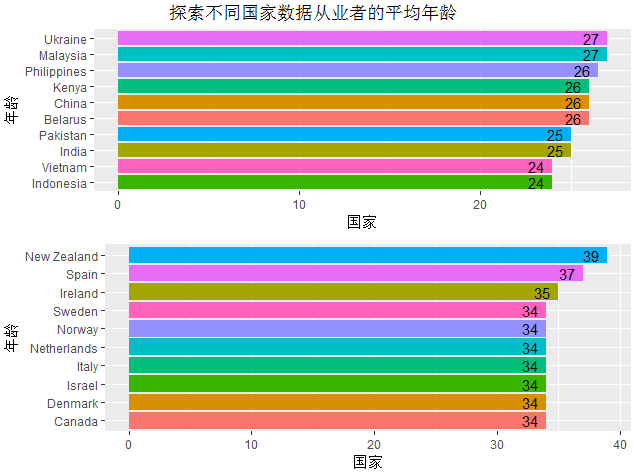
可以看到,按年龄中位数排列的话,亚洲国家在年龄较小的十个国家中占了七席,其中年龄中位数最小的国家为印度尼西亚和越南,只有24岁。中国的数据从业者集中在26岁。而年龄中位数最大的国家中,欧洲国家占了六席,且几乎都为发达国家。可见发达国家在数据科学领域已经有多年的发展。
探索数据从业者的职位名称分类
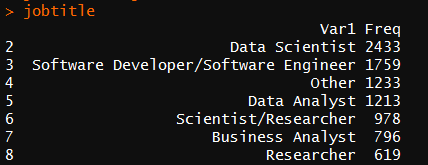
首先对数据整理,得出受访人数最多的前十个职位,且降序排列
#数据科学从业者的职位分类
jobtitle<-table(survey$CurrentJobTitleSelect)%>% #统计频数
as.data.frame()%>% #转化为数据框
arrange(desc(Freq)) #按频数倒序排列(大在前)
jobtitle <- jobtitle[-1,] #人数最多的一行为空值,即职业一栏无填写
接下来进行绘图,将数据可视化
ggplot(data=head(jobtitle,10),aes(x=reorder(Var1,Freq),Freq,fill=Var1))+ #选取受访人数最多的前十个职业
geom_bar(stat = 'identity')+
labs(x='职业',y='人数',title='受访人数最多的十个职位')+
coord_flip()+ #翻转坐标轴
geom_text(aes(label=Freq),hjust=1.5)+ #添加数据标签
theme(legend.position = 'none',plot.title = element_text(hjust = 0.2)) #去除图例,调整标题位置

从图中可看出数据科学家参加问卷调查的人数最多,达2433人。排名第十的为程序员,只有462人
探索中美两国受访者的职业分类
处理数据
diff_nation <- survey[which(survey$Country=='China'),] #提取出国家为中国的调查者信息
diff_nation1 <- survey[which(survey$Country=='United States'),] #提取出国家为美国的调查者信息
china_jobtitle <- table(diff_nation$CurrentJobTitleSelect)%>%as.data.frame()%>%arrange(desc(Freq)) #探索在中国的受访人数较多职位
usa_jobtitle <- table(diff_nation1$CurrentJobTitleSelect)%>%as.data.frame()%>%arrange(desc(Freq)) #探索在美国的受访人数较多职位
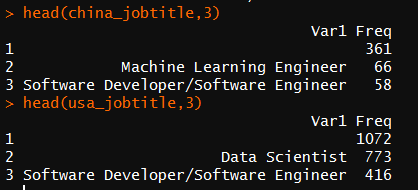
图中可看到,中国的受访者中,有361人没有填写当前职位这一栏。美国也有1072人。在绘图的过程中,需要将这些空值筛选掉
绘图
p3<-ggplot(china_jobtitle[c(2:11),],aes(reorder(Var1,Freq),Freq,fill=Var1))+ #数据集中国前十位热门职业
geom_bar(stat = 'identity')+
labs(x='职业',y='受访人数(中国)',title='中美两国受访者的当前职位对比')+
coord_flip()+ #翻转坐标轴
geom_text(aes(label=Freq),hjust=1)+
theme(legend.position = 'none',plot.title = element_text(size = 15,face = 'bold.italic')) #去除图例,设置标题大小,字体 p4<-ggplot(usa_jobtitle[c(2:11),],aes(reorder(Var1,Freq),Freq,fill=Var1))+ #数据集中国前十位热门职业
geom_bar(stat = 'identity')+
labs(x='职业',y='受访人数(美国)')+
coord_flip()+ #翻转坐标轴
geom_text(aes(label=Freq),hjust=1)+
theme(legend.position = 'none')
#合并两图
multiplot(p3,p4)
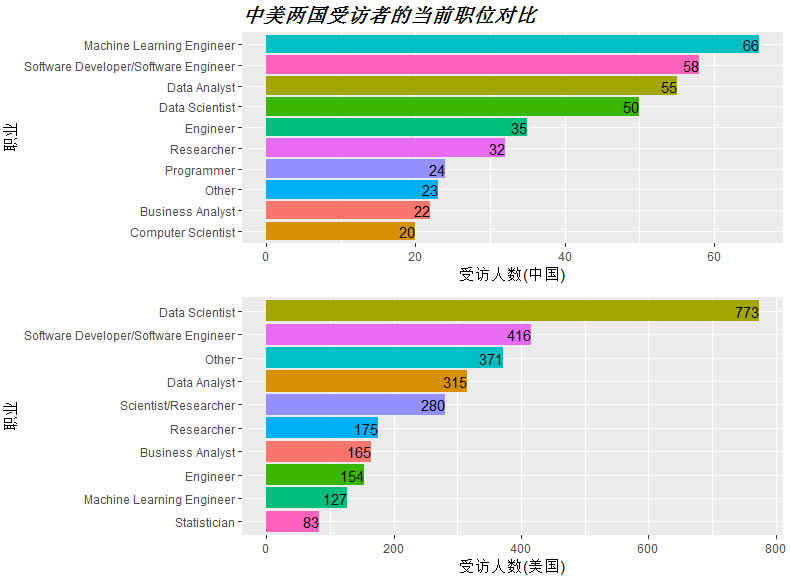
图中可看出,中国的受访者中,人数最多的为数据挖掘工程师,共66人,而美国受访者中最多的为数据科学家,共773人。排在第二位的皆为软件开发工程师。
探索数据科学从业者明年将学习的学习工具
数据处理
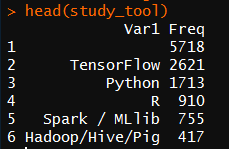
study_tool <- table(survey$MLToolNextYearSelect) %>%
as.data.frame()%>%
arrange(desc(Freq))
绘图
绘图过程与前面大同小异,所以可将绘图函数封装,代入变量即可
##############============封装绘图函数========#####################
fun1 <-function(data1,xlab1,ylab1,xname1,yname1,titlename1){
ggplot(data = data1,aes(x=xlab1,y=ylab1,fill=xlab1))+
geom_bar(stat = 'identity')+
labs(x=xname1,y=yname1,title=titlename1)+
coord_flip()+ #翻转坐标轴
geom_text(aes(label=ylab1),hjust=1)+ #数据标签
theme(legend.position = 'none',plot.title = element_text(size = 15,face = 'bold.italic')) #去除图例,设置标题大小,字体
}
########################################################################
代入变量
#function(data,xlab1,ylab1,var1,xname1,yname1,titlename1)
data <- study_tool[c(2:11),]
xname1 <- '明年将学习的学习工具'
yname1 <- '人数'
titlename1 <- '受访者明年将学习的学习工具调查'
fun1(data,reorder(data$Var1,data$Freq),data$Freq,xname1,yname1,titlename1)
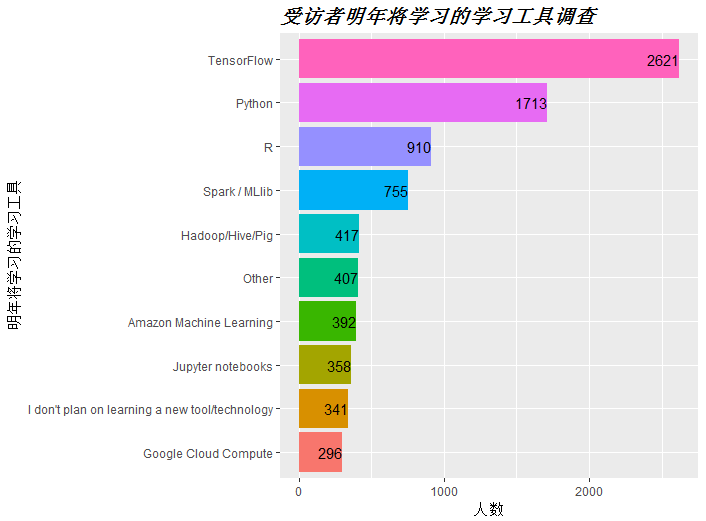
图中可看到,学习TensorFlow将成为明年的趋势,在受访者中,学习的人数达2621人之多。而接下来为python和R。可以预见,这3项将成为以后的主流学习工具。
探索中美两国数据科学从业者明年将学习的学习工具
数据提取
china_studytool <- survey %>% filter(survey$MLToolNextYearSelect !=''&Country=='China') %>%
group_by(MLToolNextYearSelect) %>%
summarise(count=n())%>% #n() 汇总
arrange(desc(count))
以上为提取中国受访者明年将学习的学习工具数据。
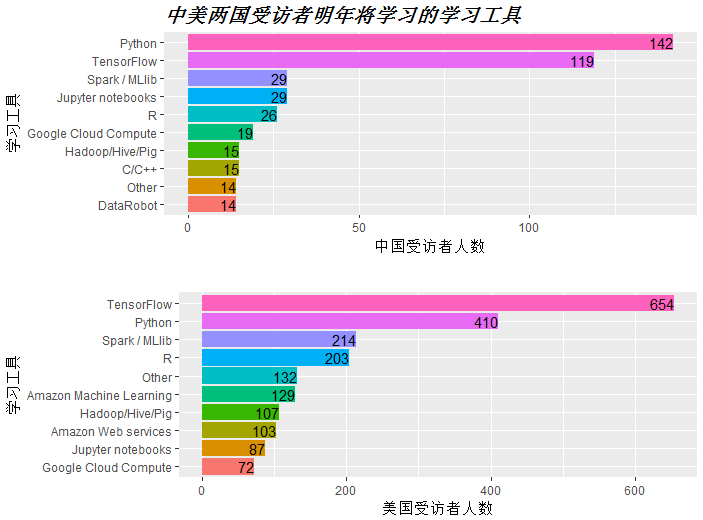
图中可见,中国数据科学从业者明年即将学习的学习工具热度较高的为Python,TensorFlow,Spark,jupyter,R。而美国为TensorFlow,python,sparkR,其他,比较符合国际趋势。
探索数据科学从业者明年将学习的机器学习方法
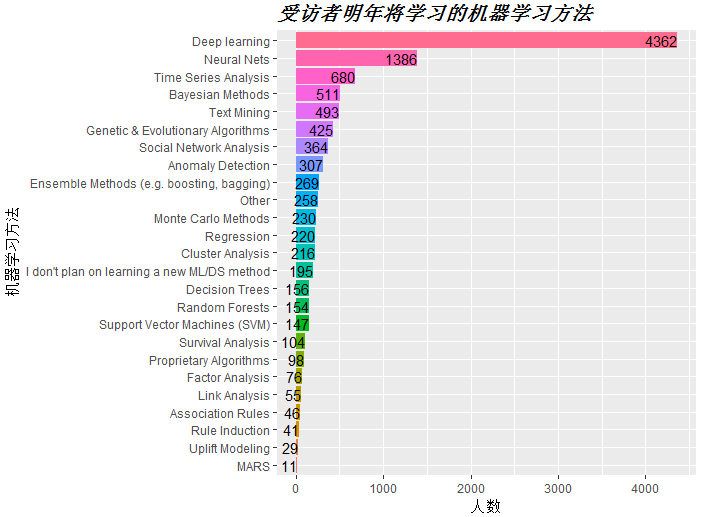
可以看到,当前的机器学习趋势为深度学习,神经网络,时间序列分析,贝叶斯方法,文本挖掘等。对机器学习方法感兴趣的从业者不妨做个参考。
从业者对新手的建议
推荐的编程语言
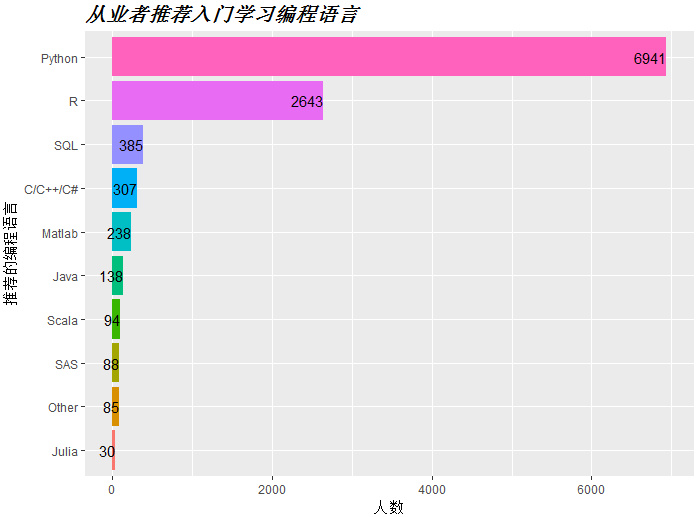
python,R,SQL是入门机器学习的必备技能
kaggle之数据分析从业者用户画像分析的更多相关文章
- 【转】4w+1h 教你如何做用户画像
记得14年开始做用户画像的时候,对于用户画像完全没有概念,以为是要画一幅幅图画,经过两年多的学习和理解,渐渐的总结出了一些方法和技巧,在这里就通过4个W英文字母开头和1个H英文字母开头的单词和大家分享 ...
- doubleclick cookie、动态脚本、用户画像、用户行为分析和海量数据存取 推荐词 京东 电商 信息上传 黑洞 https://blackhole.m.jd.com/getinfo
doubleclick cookie https://mp.weixin.qq.com/s/vZUj-Z9FGSSWXOodGqbYkA 揭密Google的网络广告技术:基于互联网大数据视角 原创: ...
- 【Python数据分析】用户通话行为分析
主要工作: 1.对从网上营业厅拿到的用户数据.xls文件,通过Python的xlrd进行解析,计算用户的主叫被叫次数,通话时间,通话时段. 2.使用matplotlib画图包,将分析的结果直观的绘制出 ...
- 用实战玩转pandas数据分析(一)——用户消费行为分析(python)
CD商品订单数据的分析总结.根据订单数据(用户的消费记录),从时间维度和用户维度,分析该网站用户的消费行为.通过此案例,总结订单数据的一些共性,能通过用户的消费记录挖掘出对业务有用的信息.对其他产 ...
- 商业智能BI与用户行为分析的联系
什么是BI? BI(Business Intelligence)即商业智能,它是一套完整的解决方案,用来将企业中现有的数据进行有效的整合,分析利用企业已有的各种商用数据来了解企业的经营状况和外部环境 ...
- 大数据时代下的用户洞察:用户画像建立(ppt版)
大数据是物理世界在网络世界的映射,是一场人类空前的网络画像运动.网络世界与物理世界不是孤立的,网络世界是物理世界层次的反映.数据是无缝连接网络世界与物理世界的DNA.发现数据DNA.重组数据DNA是人 ...
- 用Mirror,搞定用户画像
Mirror产品概述 Mirror是专为金融行业设计的全面用户画像管理系统.该系统基于星环多年来为多个金融企业客户构建用户画像的经验,深入契合业务需求,实现对用户全方位全维度的刻画.Mirror内置银 ...
- 用SparkSQL构建用户画像
用SparkSQL构建用户画像 二. 前言 大数据时代已经到来,企业迫切希望从已经积累的数据中分析出有价值的东西,而用户行为的分析尤为重要. 利用大数据来分析用户的行为与消费习惯,可以预测商品的发展 ...
- 用户画像(User Profile)
什么是用户画像? 用户画像是根据某个具体的用户的人口学特征.网络浏览内容.网络社交活动和消费行为等信息而抽象出的一个标签化的用户模型.例如某用户的画像是:男,31岁,已婚,收入1万以上,爱美食,团购达 ...
随机推荐
- 乘风破浪:LeetCode真题_021_Merge Two Sorted Lists
乘风破浪:LeetCode真题_021_Merge Two Sorted Lists 一.前言 关于链表的合并操作我们是非常熟悉的了,下面我们再温故一下将两个有序链表合并成一个的过程,这是基本功. 二 ...
- ZT 设计模式六大原则(2):里氏替换原则
设计模式六大原则(2):里氏替换原则 分类: 设计模式 2012-02-22 08:46 23330人阅读 评论(41) 收藏 举报 设计模式class扩展string编程2010 肯定有不少人跟我刚 ...
- pipenv
一. 1. 使用pip安装pipenv及其相关依赖 pip install pipenv 2. 将目录更改为包含你的Python项目的文件夹,并启动Pipenv cd my_project pipen ...
- web安全职位面试题目汇总
Domain 解释一下同源策略 同源策略,那些东西是同源可以获取到的 如果子域名和顶级域名不同源,在哪里可以设置叫他们同源 如何设置可以跨域请求数据?jsonp是做什么的? Ajax Ajax是否遵循 ...
- Mof提权科普
今天再拿一个站的时候遇到了很多问题,拿站的过程就不说了,其中要用到mof提权,不管能不能提下,我进行一个mof提权的科普 这里我综合各类mof提权进行了 综合 首先说一下,无shell情况下的mysq ...
- python30 excel修改模块xlutils
xlrd只读,xlwt只写,xlutils模块则将读写功能结合起来.https://pypi.org/project/xlutils/ 修改excel通过xlutils的copy函数将<clas ...
- xgcom linux下的串口助手
好用到爆@@! 2.Install: Source code: http://code.google.com/p/xgcom/ svn checkout http://xgcom.googlecode ...
- navicat连接PostgreSQL报:column “rolcatupdate” does not exist ...错误的解决办法
avicat premium 连接PostgreSQL出现: column “rolcatupdate” does not exist ... 错误如图: 解决方案: 看看你的navicat 是否为最 ...
- mysql5.6 函数大全
# 数学函数(1)ABS(x)返回x的绝对值(2)PI()返回圆周率π,默认显示6位小数(3)SQRT(x)返回非负数的x的二次方根(4)MOD(x,y)返回x被y除后的余数(5)CEIL(x).CE ...
- 【[国家集训队] Crash 的文明世界】
先写一个五十分的思路吧 首先这道题有一个弱化版 [POI2008]STA-Station 相当于\(k=1\),于是就是一个非常简单的树形\(dp\)的\(up\ \ and\ \ down\)思想 ...