1st 英文文章词频统计
英文文章词频统计:
功能:统计一篇英文文章的单词总数及出现频数并输出,之后排序,输出频数前十的单词及其频数。
实现方法:使用C语言,用fopen函数读入txt文件,fscanf函数逐个读入单词,结构体wordNode存储单词及其频数,以链表的形式连接在一起,最后使用插入排序进行分析,输出频数最高的5个单词。
头文件
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
定义宏
#define ERROR 1
#define OK 0
#define WORD_LENGTH 250
自定义数据类型
typedef int status; typedef struct Node
{
char word[WORD_LENGTH];
int time;
struct Node *next;
}wordNode;
定义全局变量
wordNode *headNode = NULL;
声明所有使用的函数
wordNode *wordSearch(char *word,int *num);
status wordCount(char *word,int *num);
void printCountList(int *num);
void PrintFirstFiveTimes();
void mergeSort(wordNode **head);
void FrontBackSplit(wordNode *head,wordNode **pre,wordNode **next);
void wordJob(char word[]);
wordNode *SortedMerge(wordNode *pre,wordNode *next);
void release();
主函数
status main(int argc,char *argv[])
{
char temp[WORD_LENGTH];//定义用以临时存放单词的数组
FILE *file;
int count;
int articleWordNum = ;//定义统计结点个数的变量
int *num = &articleWordNum;
if((file = fopen("F:\\zc\\c\\yjs\\file.txt", "r")) == NULL)
{
printf("文件读取失败!");
exit();
}
while((fscanf(file,"%s",temp))!= EOF)
{
wordJob(temp);
count = wordCount(temp,num);
}
fclose(file);
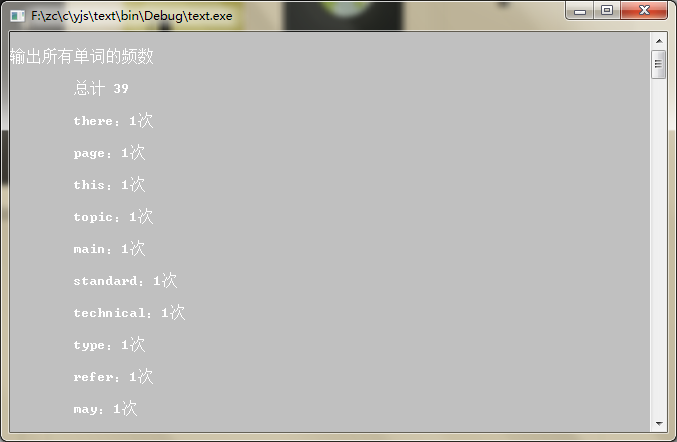
printf("\n输出所有单词的频数\n");
printCountList(num);
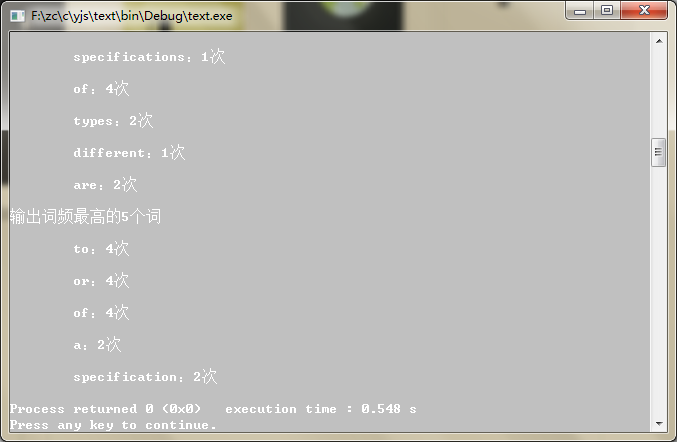
printf("\n输出词频最高的5个词\n");
mergeSort(&headNode); //排序
PrintFirstFiveTimes();
release();
return ;
}
查找单词所在结点并返回其地址
wordNode *wordSearch(char *word,int *num)
{
wordNode *node;
wordNode *nextNode = headNode;
wordNode *preNode = NULL;
char a[WORD_LENGTH];
if(headNode == NULL)
{
node = (wordNode*)malloc(sizeof(wordNode));
strcpy(node->word, word);
node->time = ;
*num+=;
headNode = node;
return node;
}
while(nextNode != NULL) //查找匹配单词
{
strcpy(a,nextNode->word);
if(strcmp(a, word) == )
{
return nextNode;
}
preNode = nextNode;
nextNode = nextNode->next;
} if(nextNode == NULL)
{
node = (wordNode*)malloc(sizeof(wordNode));
strcpy(node->word, word);
node->time = ;
node->next = headNode->next;
headNode->next = node;
*num+=;
return node;
}
else
return nextNode;
}
进行词频统计
status wordCount(char *word,int *num)
{
wordNode *tmpNode = NULL;
tmpNode = wordSearch(word,num); //word所在的节点
if(tmpNode == NULL)
{
return ERROR;
}
tmpNode->time++;
return ;
}
输出所有词频
void printCountList(int *num)
{
if(headNode == NULL)
{
printf("该文件无内容!");
}
else
{
wordNode *preNode = headNode;
printf("\n\t总计 %d \n",*num);
while(preNode != NULL)
{
printf("\n\t%s:%d次\n",preNode->word,preNode->time);
preNode = preNode->next;
}
}
}
输出词频最高的10个词
void PrintFirstFiveTimes()
{
if(headNode == NULL)
{
printf("该文件无内容!");
}
else
{
wordNode *preNode = headNode;
int i = ;
while (preNode != NULL && i<=)
{
printf("\n\t%s:%d次\n",preNode->word,preNode->time);
preNode = preNode->next;
i++;
}
}
}
对词频统计结果进行归并排序
void mergeSort(wordNode **headnode)
{
wordNode *pre,*next,*head;
head = *headnode;
if(head == NULL || head->next == NULL)
{
return;
}
FrontBackSplit(head,&pre,&next);
mergeSort(&pre);
mergeSort(&next);
*headnode = SortedMerge(pre,next);
}
取尾节点
void FrontBackSplit(wordNode *source,wordNode **pre,wordNode **next)
{
wordNode *fast;
wordNode *slow;
if(source == NULL || source->next == NULL)
{
*pre = source;
*next = NULL;
}
else
{
slow = source;
fast = source->next;
while(fast != NULL)
{
fast = fast->next;
if(fast != NULL)
{
slow = slow->next;
fast = fast->next;
}
}
*pre = source;
*next = slow->next;
slow->next = NULL;
}
}
取频数最大的节点作为头节点
wordNode *SortedMerge(wordNode *pre,wordNode *next)
{
wordNode *result = NULL;
if(pre == NULL)
return next;
else if(next == NULL)
return pre;
if(pre->time >= next->time)
{
result = pre;
result->next = SortedMerge(pre->next,next);
}
else
{
result = next;
result->next = SortedMerge(pre,next->next);
}
return result;
}
处理单词
void wordJob(char word[])
{
int i,k;
for(i = ;i<strlen(word);i++)
{
if(word[i]>='A'&& word[i]<='Z')
{
word[i] += ;
continue;
}
if(word[i]<'a'||word[i]>'z')
{
if(i == (strlen(word)-))
{
word[i] = '\0';
}
else
{
k = i;
while(i < strlen(word))
{
word[i] = word[i+];
i++;
}
i = k;
}
}
}
}
释放所有结点内存
void release()
{
if(headNode == NULL)
return;
wordNode *pre = headNode;
while(pre != NULL)
{
headNode = pre->next;
free(pre);
pre = headNode;
}
}
git@git.coding.net:amberpass/Calculate_words.git
https://git.coding.net/amberpass/Calculate_words.git
程序运行结果:
1st 英文文章词频统计的更多相关文章
- 【第二周】Java实现英语文章词频统计(改进1)
本周根据杨老师的spec对英语文章词频统计进行了改进 1.需求分析: 对英文文章中的英文单词进行词频统计并按照有大到小的顺序输出, 2.算法思想: (1)构建一个类用于存放英文单词及其出现的次数 cl ...
- 【第二周】Java实现英语文章词频统计
1.需求:对于给定的英文文章进行单词频率的统计 2.分析: (1)建立一个如下图所示的数据库表word_frequency用来存放单词和其对应数量 (2)Scanner输入要查询的英文文章存入Stri ...
- java词频统计——web版支持
需求概要: 1.把程序迁移到web平台,通过用户上传TXT的方式接收文件. 2.用户直接输入要统计的文本,服务器返回结果 3.在页面上给出链接 (如果有封皮.作者.字数.页数等信息更佳)或表格,展示经 ...
- 词频统计Web工程
本次将原本控制台工程迁移到了web工程上.. 需求: 1.把程序迁移到web平台,通过用户上传TXT的方式接收文件: 2.在页面上给出链接 (如果有封皮.作者.字数.页数等信息更佳)或表格,展示经典英 ...
- 个人项目----词频统计WEB(部分功能)
需求分析 1.使用web上传txt文件,对上传的txt进行词频统计. 2.将统计后的结果输出到web页面,力求界面优美. 3.在界面上展示所给url的文章词频统计,力求界面优美. 3.将每个单词同四. ...
- Java实现的词频统计——Web迁移
本次将原本控制台工程迁移到了web工程上,依旧保留原本控制台的版本. 需求: 1.把程序迁移到web平台,通过用户上传TXT的方式接收文件: 2.在页面上给出链接 (如果有封皮.作者.字数.页数等信息 ...
- 1.字符串操作:& 2.英文词频统计预处理
1.字符串操作: 解析身份证号:生日.性别.出生地等. ID = input('请输入十八位身份证号码: ') if len(ID) == 18: print("你的身份证号码是 " ...
- Python——字符串、文件操作,英文词频统计预处理
一.字符串操作: 解析身份证号:生日.性别.出生地等. 凯撒密码编码与解码 网址观察与批量生成 2.凯撒密码编码与解码 凯撒加密法的替换方法是通过排列明文和密文字母表,密文字母表示通过将明文字母表向左 ...
- 组合数据类型,英文词频统计 python
练习: 总结列表,元组,字典,集合的联系与区别.列表,元组,字典,集合的遍历. 区别: 一.列表:列表给大家的印象是索引,有了索引就是有序,想要存储有序的项目,用列表是再好不过的选择了.在python ...
随机推荐
- 在全志V3/V3s和索智S3/S3L上调试32MB NorFlash
选取MX25L25635F作为调试对象,其他型号的NorFlash开发调试原理基本一致.为了使V3/V3s/S3/S3L识别32MB NorFlash并正常工作,主要针对以下三个部分进行开发和调试.下 ...
- PMU 精密测量单元
PMU(Precision Measurement Unit,精密测量单元)用于精确的DC参数测量,它能驱动电流进入器件而去量测电压或者为器件加上电压而去量测产生的电流.PMU的数量跟测试机的等级有关 ...
- 20155322 2017-2018-1《信息安全系统设计》第十周 课下作业-IPC
20155322 2017-2018-1<信息安全系统设计>课下作业-IPC 作业内容 研究Linux下IPC机制:原理,优缺点,每种机制至少给一个示例,提交研究博客的链接. 共享内存 管 ...
- P3368 【模板】树状数组 2(区间增减,单点查询)
P3368 [模板]树状数组 2 题目描述 如题,已知一个数列,你需要进行下面两种操作: 1.将某区间每一个数数加上x 2.求出某一个数的和 输入输出格式 输入格式: 第一行包含两个整数N.M,分别表 ...
- virsh常用维护命令
virsh常用命令 一些常用命令参数 [root@kvm-server ~]# virsh --help #查看命令帮忙 [ro ...
- 求助:springboot调用存储过程并使用了pagehelper分页时报错com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException
存储过程如下: dao层的sql Controller层调用: html页面 没有使用pagehelper分页之前,可以正常使用 使用了pagehelper之后就报错 ### Error queryi ...
- Mybatis传递参数的三种方式
第一种: Dao层使用@Param注解的方法 VersionBox getVersionByVersionNumAndVersionType(@Param("versionNum" ...
- javaweb(三十四)——使用JDBC处理MySQL大数据
一.基本概念 大数据也称之为LOB(Large Objects),LOB又分为:clob和blob,clob用于存储大文本,blob用于存储二进制数据,例如图像.声音.二进制文等. 在实际开发中,有时 ...
- SteamVR Unity Plugin - v2.0.1中的InteractionSystem
最近写VR项目的时候用到了SteamVR Unity Plugin - v2.0.1插件,感觉比之前用到的SteamVR plugin for Unity - v1.2.2版本改进了很多,就算不用VR ...
- 003 -- Dubbo简单介绍
1:Dubbo的基本概念 dubbo是阿里巴巴SOA服务治理 方案的核心框架,每天为20000+个服务次的数据量访问支持.dubbo是一个分布式的服务框架,致力于提供高性能和透明化的RPC远程服务调用 ...