关于解决乱码问题的一点探索之一(涉及utf-8和GBK)
在使用Visual Studio 2005进行MFC开发的时候,发现自动添加的注释变成了乱码。像这样:
// TODO: ÔÚ´ËÌí¼ÓרÓôúÂëºÍ/»òµ÷ÓûùÀà还有这样:
// TODO: ÔÚ´ËÌí¼ÓÏûÏ¢´¦Àí³ÌÐò´úÂëºÍ/»òµ÷ÓÃĬÈÏÖµ它们正确的显示应该是
// TODO: 在此添加专用代码和/或调用基类和
// TODO: 在此添加消息处理程序代码和/或调用默认值
当保存的时候,还出现了这样的对话框:
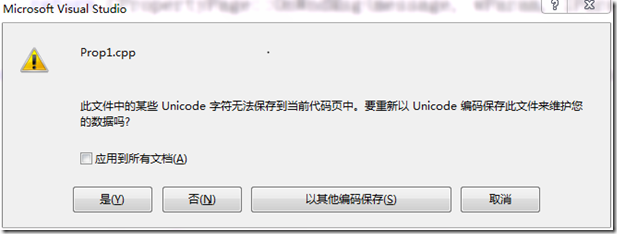
网上找了各种教程,包括什么设置“自动识别不带签名的utf-8”什么的,都没有用。所以考虑自己解决。下面是我的探索过程:
一,保存文件
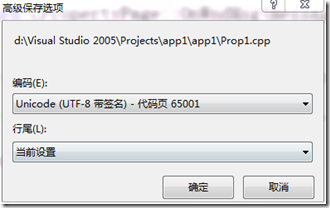
首先,将文件以“Unicode(UTF-8带签名) 代码页:65001”的形式进行保存(带签名的UTF-8是指有BOM的UTF-8,至于带BOM和不带BOM的UTF-8有什么区别,请戳此)。如下图:
二,查看文件的16进制代码(就是查看文件实际上保存成什么数据了)
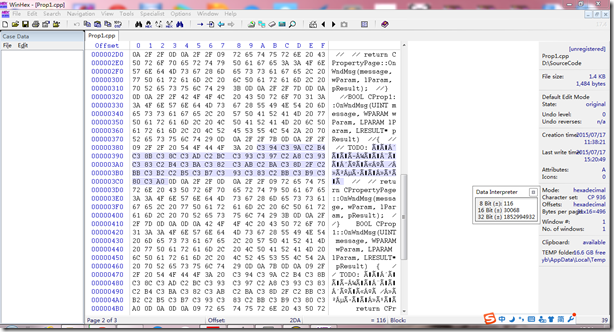
使用WinHex软件打开刚刚保存的文件(当然,使用UltraEdit也可以),查看文件的16进制代码。我们找到乱码的地方,把它的16进制代码找出来,如下:
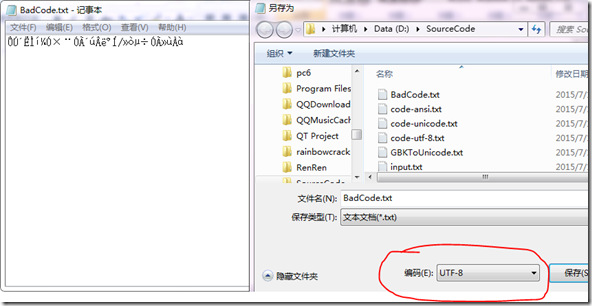
为了更清楚地演示,我将乱码单独拷出来,一定要注意将文本保存成UTF-8(最好带BOM,如果使用Windows自带的文本编辑器编辑就自带BOM)保存成这样:
文件对应的16进制代码为:

最前面的三个字节“EF BB BF”就是前面所述的BOM标记,从第四个字节开始,就是文件的实际内容。观察后发现,在实际内容部分,奇数位上不是C2就是C3,偶数位的没有规律,同时,我们找出原话“在此添加专用代码和/或调用基类”对应的GBK编码值,进行比较。
表一:乱码文件中的16进制数据:
0xc3 0x94 0xc3 0x9a
0xc2 0xb4 0xc3 0x8b
0xc3 0x8c 0xc3 0xad
0xc2 0xbc 0xc3 0x93
0xc3 0x97 0xc2 0xa8
0xc3 0x93 0xc3 0x83
0xc2 0xb4 0xc3 0xba
0xc3 0x82 0xc3 0xab
0xc2 0xba 0xc3 0x8d
0x2f
0xc2 0xbb 0xc3 0xb2
0xc2 0xb5 0xc3 0xb7
0xc3 0x93 0xc3 0x83
0xc2 0xbb 0xc3 0xb9
0xc3 0x80 0xc3 0xa0
表二:“在此添加专用代码和/或调用基类”对应的GBK编码值,每个字符(汉字或者/)对应一行:
0xd4 0xda
0xb4 0xcb
0xcc 0xed
0xbc 0xd3
0xd7 0xa8
0xd3 0xc3
0xb4 0xfa
0xc2 0xeb
0xba 0xcd
0x2f
0xbb 0xf2
0xb5 0xf7
0xd3 0xc3
0xbb 0xf9
0xc0 0xe0
4,分析
仔细观察上面的两个表中的数据,我们不难发现以下规律:
1,将表一每行中奇数位置(除了’/’那行)的C2、C3的值去掉,剩下的值和表二中的数据高度相似。
2,除了’/’那行,表一每行中奇数位置为C2的,后面的偶数位数字就和表二中对应位(表一种第二列对应表二第一列,表一第四列对应表二中第二列)相同,表一每行中奇数位为C3的,后面的偶数位数字加上16进制数0x40后也与表二中对应位相同(对应法则同前)。
3,由于乱码文件是以utf-8存储的,但是经过转换后得到的编码为GBK,我们大致可以知道,出现乱码的原因就是visual studio 2005将两种编码搞混了,这应该算是一个bug吧。。毕竟visual studio 2013就从来没有碰到过。。
5,解决问题
根据上面的规律,我们使用二进制方式读取utf-8格式编码的文件数据后经转化然后输出到GBK编码的文件中即可修正问题了。
按照以上的规律编写一段简单的C语言程序:
#include <stdio.h>
#include <stdlib.h> int main(int argc, char const *argv[])
{
FILE* fp;
FILE* fp2;
//打开存储乱码的文件,utf-8格式,二进制打开
if((fp2=fopen("BadCode.txt","rb+"))==NULL)
{
printf("Open Source File Failed!\n");
system("pause");
exit();
}
//打开、新建存储处理后数据的文件
if((fp=fopen("BadCodeH.txt","w+"))==NULL)
{
printf("Open/Create Destination File Failed!\n");
system("pause");
exit();
}
//纪录奇数位(高位)的数据
unsigned ch;
//纪录偶数位(低位)的数据
unsigned cl;
//获得数据
ch=fgetc(fp2);
//判断文件的格式,utf-8或者Unicode,并跳过BOM字符
if(ch==0xef)
{
fgetc(fp2);
fgetc(fp2);
ch=fgetc(fp2);
}
else if(ch==0xff)
{
fgetc(fp2);
ch=fgetc(fp2);
}
//不达结尾
while(!feof(fp2))
{
//ASCII字符,正常输出
if(ch<=0x7f)
{
fputc(ch,fp);
}
//奇数位为0xC3,获得偶数位后加0x40后输出
else if(ch==0xc3)
{
cl=fgetc(fp2);
cl+=0x40;
fputc(cl,fp);
}
//奇数位为0xC2,获得偶数位后直接输出
else if(ch==0xc2)
{
cl=fgetc(fp2);
fputc(cl,fp);
}
//其他情况,直接输出
else
{
fputc(ch,fp);
}
//获得下一个数据
ch=fgetc(fp2);
} fclose(fp);
fclose(fp2);
system("pause");
return ;
}
操作实例结果如下图:
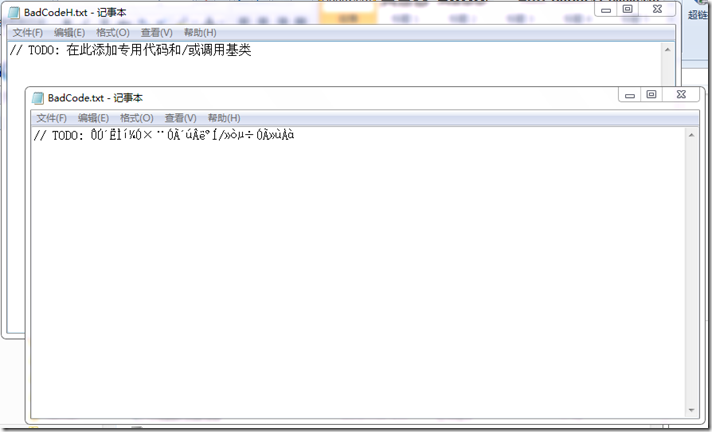
6,更一般的情况(既有正确的中文字符又有乱码)
我们必须注意到一点:上面的C语言程序只适合一种情况:就是乱码文档格式为utf-8且文档中只存在中文乱码字符与ASCII字符。但是我们很多时候是源码中既有正确的中文字符又有乱码字符,这时上面的程序就无效了,因为我们需要将正确中文字符的utf-8编码转换为GBK编码才可以。我们尝试修改上面的代码来解决这个问题。
对于既有乱码又有正常字符的文件来说,只要将正确的中文字符的utf-8编码转化为GBK编码就解决问题了,所以主要问题的关键就是建立一个utf-8与GBK编码的转换表。baidu一下,我们很容易找到了这个表,然后,就写了以下的程序。UnicodeToGBK.txt文件请戳下载地址:
#include <stdio.h>
#include <stdlib.h>
//将gbk编码值存入数组中utf-8编码对应的位置上
bool ReadTable(unsigned* mapValue2)
{
//声明文件指针
FILE* fp;
//打开转换表文件,文件中第一列为汉字的GBK编码,第二列为utf-8编码
//以可读写方式打开
if (NULL == (fp = fopen("Utf8ToGBKTable.txt", "r+")))
{
printf("Open Table Failed!");
system("pause");
return false;
}
//记录gbk的编码值
unsigned gbk=;
//临时记录各位数据
unsigned data;
//记录utf-8的编码值
unsigned long utf=;
//循环次数记号
unsigned id=;
while(!feof(fp))
{
//获得第一列gbk的编码值
for (int i = ; i < ; ++i)
{
data=fgetc(fp);
data=data>='A'?data-'A'+:data-'';
gbk=gbk*+data;
}
//跳过tab键
fgetc(fp);
//获得第二列utf-8的编码值
for (int i = ; i < ; ++i)
{
data=fgetc(fp);
data=data>='A'?data-'A'+:data-'';
utf=utf*+data;
}
if (id>)
{
printf("%d\t%ld\n",gbk,utf );
}
mapValue2[utf-]=gbk;
fgetc(fp);
// fgetc(fp);
//重置数据
gbk=;
utf=;
id++;
} fclose(fp);
return true;
} int main(int argc, char const *argv[])
{
FILE* fp;
FILE* fp2;
//打开存储乱码的文件,utf-8格式,二进制打开
if((fp2=fopen("BadCode.txt","rb+"))==NULL)
{
printf("Open Source File Failed!\n");
system("pause");
exit();
}
//打开、新建存储处理后数据的文件
if((fp=fopen("BadCodeH.txt","w+"))==NULL)
{
printf("Open/Create Destination File Failed!\n");
system("pause");
exit();
}
unsigned mapValue2[];
if(!ReadTable(mapValue2))
{ printf("Convert Failed!\n");
system("pause");
exit(1);
} //纪录奇数位(高位)的数据
unsigned ch;
//纪录偶数位(低位)以及utf-8高位的数据
unsigned cl;
//记录utf-8末位字节的信息
unsigned cu;
////记录正常字符的utf-8编码
unsigned long utf;
//记录正常字符的gbk编码
unsigned cgbk;
//获得数据
ch=fgetc(fp2);
//判断文件的格式,utf-8或者Unicode,并跳过BOM字符
if(ch==0xef)
{
fgetc(fp2);
fgetc(fp2);
ch=fgetc(fp2);
}
else if(ch==0xff)
{
fgetc(fp2);
ch=fgetc(fp2);
}
//不达结尾
while(!feof(fp2))
{
//ASCII字符,正常输出
if(ch<=0x7f)
{
fputc(ch,fp);
}
//奇数位为0xC3,获得偶数位后加0x40后输出
else if(ch==0xc3)
{
cl=fgetc(fp2);
cl+=0x40;
fputc(cl,fp);
}
//奇数位为0xC2,获得偶数位后直接输出
else if(ch==0xc2)
{
cl=fgetc(fp2);
fputc(cl,fp);
}
//其他情况,即正常utf-8字符,转换为GBK字符后输出
else
{ //获得utf-8的中位字节
cl=fgetc(fp2);
//获得utf-8的末尾字节
cu=fgetc(fp2);
//计算utf-8编码
utf=ch*+cl*+cu;
//获得对应的gbk编码
cgbk=mapValue2[utf-0xe4b880];
//输出数据
fputc(cgbk/,fp);
fputc(cgbk%,fp);
}
//获得下一个数据
ch=fgetc(fp2);
} fclose(fp);
fclose(fp2);
system("pause");
return ;
}
使用上面的代码进行测试,就得到下面的结果,表明此算法是有效的。

至此,虽然有点麻烦,但是问题也算解决了。
关于解决乱码问题的一点探索之一(涉及utf-8和GBK)的更多相关文章
- 关于解决乱码问题的一点探索之二(涉及Unicode(utf-16)和GBK)
在上篇日志中(链接),我们讨论了utf-8编码和GBK编码之间转化的乱码问题,这一篇我们讨论Unicode(utf-16编码方式)与GBK编码之间转换的乱码问题. 在Windows系统 ...
- mysql 使用set names 解决乱码问题的原理
解决乱码的方法,我们经常使用“set names utf8”,那么为什么加上这句代码就可以解决了呢?下面跟着我一起来深入set names utf8的内部执行原理 先说MySQL的字符集问题.Wind ...
- servlet 解决乱码问题
对于servlet大家应该都很熟悉了,今天再复习一下,如果有哪里写的不好或不对的地点希望广大的网友批评指正.今天只讨论get和post两w种方式,他们之间有很多的不同点,所以解决编码的方式也会不一样, ...
- 关于Mysql中文乱码问题该如何解决(乱码问题完美解决方案)(转)
这篇文章给大家介绍关于Mysql中文乱码问题该如何解决(乱码问题完美解决方案)的相关资料,还给大家收集些关于MySQL会出现中文乱码原因常见的几点,小伙伴快来看看吧 最近两天做项目总是被乱码问题困 ...
- SpringMVC解决乱码
SpringMVC解决乱码 在web.xml中配置如下代码
- http get/post解决乱码问题
<form method="默认为get"-> <s:form mothod="默认为post"-> ================= ...
- 上传Text文档并转换为PDF(解决乱码)
前些日子,Insus.NET有分享一篇<上传Text文档并转换为PDF>http://www.cnblogs.com/insus/p/4313092.html 它是按最简单与默认方式来处理 ...
- php 解决乱码的通用方法
一,出现乱码的原因分析 1,保存文件时候,文件有自己的文件编码,就是汉字,或者其他国语言,以什么编码来存储 2,输出的时候,要给内容指定编码,如以网页的形势输入时<meta http-equiv ...
- 为sublime安装package control 解决乱码问题 Mac版
为sublime安装package control Mac版参考 https://sublime.wbond.net/installation 防止中文乱码其实只需要2个东东 一个GBK enc ...
随机推荐
- 1.Hadoop集群安装部署
Hadoop集群安装部署 1.介绍 (1)架构模型 (2)使用工具 VMWARE cenos7 Xshell Xftp jdk-8u91-linux-x64.rpm hadoop-2.7.3.tar. ...
- Python-条件语句和循环语句
·条件语句 笔记: If 布尔值: print(‘hello,world!’) 当表达式为布尔表达式时,Flase None 0 ”” () [] {} 都视为假! @ ...
- 蓝牙耳机电路和PCB(网上下载用于练习)
这个是文件 https://pan.baidu.com/s/1smIyd_aNIt-ON8z8AeWn4Q 密码 w6ju 这是导入进去以后的样子,前面步骤我就跳过了 这是原作者的布局 但是我在看原理 ...
- 【转】ASP.NET 防止同一用户同时登陆
要防止同一用户同时登陆,首页应该记录在线用户的信息(这里与用户名为例),然后判断正在登陆的用户里面是否已存在.在这里使用一个cache存放已经登陆的用户名,但是还有一个问题就是要知道用户是什么时候离开 ...
- 20155338 《Java程序设计》实验一(Java开发环境的熟悉)实验报告
20155338 <Java程序设计>实验一(Java开发环境的熟悉)实验报告 一.实验内容及步骤 1.用JDK编译.运行简单的java程序 步骤一(新建文件夹): 打开windows下的 ...
- tableView--iOS11适配和iPhoneX适配
1.UIScrollView及其子类在IOS 11之前的版本UI显示完全正常,但是在IOS 11上面会显示奇葩的界面. (1)先看一下UITablevIew. 原本在VC里面的automaticall ...
- 解决 mysql in 查询排序问题
select id,title from za_item where -- id ,) 返回的结果第一条是对应id是1000,第二条是1003. 如果我们想让结果和in里面的排序一致,可以这么做. s ...
- 解决数据库SUSPECT(置疑)状态
在虚拟机中运行数据库不小心强制关机了,结果有一个重要的数据库后面加上了一个suspect的关键字,在管理器中打不开,程序也不能运行. 网上有很多分析的方法,试了一些不管用,最后用这种方法解决了,记录一 ...
- c# IE浏览器清除缓存没用
再想买更新JS和css文件之后, 使用 internet 里面的删除选项 发现样式和事件还是没用变 最终发现 需要 按 f12 找到这个清缓存才正常解决问题
- 深入理解C++中的Const,Mutable以及Volatile
我一直认为const表示一个常量,常量就是一个无法被修改的值,但是没有深入理解const的实现,甚至不知道mutable和volatile的存在,最近在书中看到了这一部分的知识,所以本文将详细解析这几 ...