Learning to Rank之RankNet算法简介
排序一直是信息检索的核心问题之一, Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning to Rank的简介请见我的博文Learning to Rank简介)。LTR有三种主要的方法:PointWise,PairWise,ListWise. RankNet是一种Pairwise方法, 由微软研究院的Chris Burges等人在2005年ICML上的一篇论文Learning to Rank Using Gradient Descent中提出,并被应用在微软的搜索引擎Bing当中。
1. 损失函数
损失函数一直是各种Learning to Rank算法的核心, RankNet亦然.
RankNet是一种Pairwise方法, 定义了文档对<A, B>的概率(假设文档A, B的特征分别为xi,xj):

其中oij=oi-oj, oi=f(xi), RankNet使用神经网络来训练模型, 所以f(xi)是神经网络的输出。
如果文档A比文档B和查询q更加相关, 则目标概率: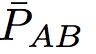 =1, 如果文档B比文档A更相关, 目标函数
=1, 如果文档B比文档A更相关, 目标函数 =0, 如果A和B同样相关, 则=0.5.
=0, 如果A和B同样相关, 则=0.5.
有了模型输出的概率Pij和目标概率, 我们使用交叉熵来作为训练的损失函数:
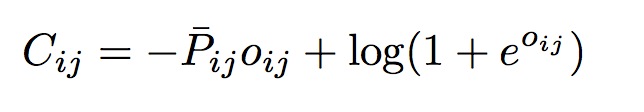
在三种不同的目标概率下, 损失函数和oij之间的关系如下图所示:

可以看到, 在=1时, oij越大损失函数越小, =0时, 越小损失函数越小, =0.5时, =0.5时损失函数最小。
本身也有一些非常好的特性, 给定 和
和 , 得到:
, 得到:
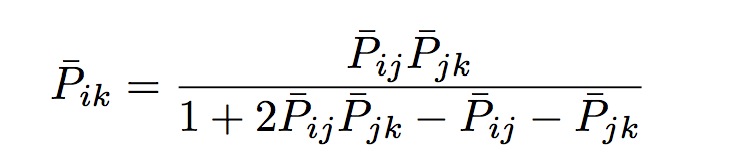
令==P, 得到P和 的关系如下图所示:
的关系如下图所示:
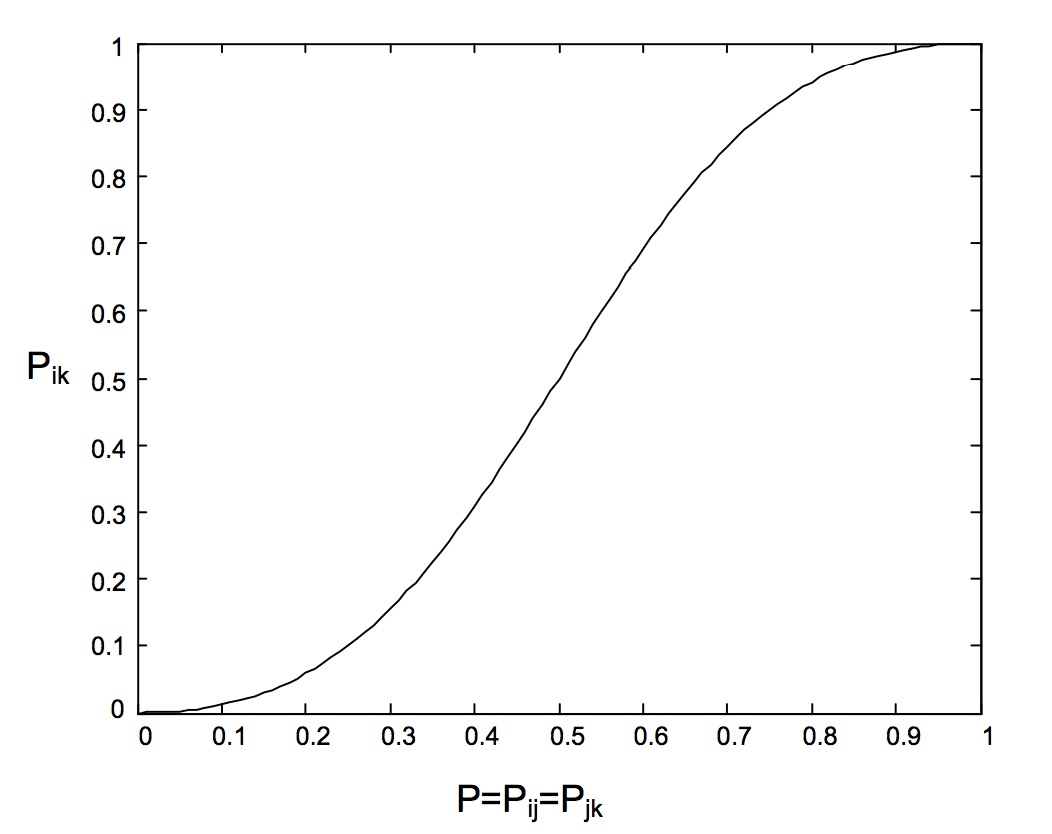
可以看到, 当P>0.5时, 亦即i>j, j>k时, 有>0.5, 亦即i>k, 这说明概率P具有一致性(consistency).
2. RankNet算法
RankNet使用神经网络来训练模型, 使用梯度下降来优化损失函数。特别的, Chris Burges等人在论文中证明, 对于m个文档{d1,d2,...,dm}, 需要且只需要知道相邻文档之间的概率Pij,就可以算出任意两个文档之间的后验概率. 可以实现对m个文档做任意排列, 然后以排列后的相邻文档之间的概率Pij作为训练数据, 然后训练模型, 时间复杂度为O(N), 优于Ranking SVM的O(N2)。
在使用神经网络进行训练时, 将排好序的文档逐个的放入神经网络进行训练, 然后通过前后两个文档之间的oij=oi-oj来训练模型, 每一次迭代, 前向传播m次, 后向反馈m-1次。
RankLib中有RankNet等Learning to Rank算法的开源Java实现。
参考文献:
[1]. Chris Burges, et al. Learning to Rank using Gradient Descent, ICML, 2005.
[2]. Tie-yan Liu. Learning to Rank for Information Retrieval.
[3]. Learning to Rank简介
[4]. RankLib
Learning to Rank之RankNet算法简介的更多相关文章
- 【机器学习】Learning to Rank之Ranking SVM 简介
Learning to Rank之Ranking SVM 简介 排序一直是信息检索的核心问题之一,Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning t ...
- Learning to Rank之Ranking SVM 简介
排序一直是信息检索的核心问题之一,Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning to Rank的简介请见我的博文Learning to Rank简 ...
- [Machine Learning] Learning to rank算法简介
声明:以下内容根据潘的博客和crackcell's dustbin进行整理,尊重原著,向两位作者致谢! 1 现有的排序模型 排序(Ranking)一直是信息检索的核心研究问题,有大量的成熟的方法,主要 ...
- [笔记]Learning to Rank算法介绍:RankNet,LambdaRank,LambdaMart
之前的博客:http://www.cnblogs.com/bentuwuying/p/6681943.html中简单介绍了Learning to Rank的基本原理,也讲到了Learning to R ...
- Learning to Rank算法介绍:RankNet,LambdaRank,LambdaMart
之前的博客:http://www.cnblogs.com/bentuwuying/p/6681943.html中简单介绍了Learning to Rank的基本原理,也讲到了Learning to R ...
- Learning to Rank 简介
转自:http://www.cnblogs.com/kemaswill/archive/2013/06/01/3109497.html,感谢分享! 本文将对L2R做一个比较深入的介绍,主要参考了刘铁岩 ...
- 【机器学习】Learning to Rank 简介
Learning to Rank 简介 去年实习时,因为项目需要,接触了一下Learning to Rank(以下简称L2R),感觉很有意思,也有很大的应用价值.L2R将机器学习的技术很好的应用到了排 ...
- Learning to Rank简介
Learning to Rank是采用机器学习算法,通过训练模型来解决排序问题,在Information Retrieval,Natural Language Processing,Data Mini ...
- Learning to rank基本算法
搜索排序相关的方法,包括 Learning to rank 基本方法 Learning to rank 指标介绍 LambdaMART 模型原理 FTRL 模型原理 Learning to rank ...
随机推荐
- shell基础篇(十)shell脚本的包含
前记 写到这里:shell中基础差不多已经讲完了.希望你已经对shell有了一个基本了解.你可能跃跃欲试,要写一些程序练习一下.这会对你很有好处.建议大家去chinaunix去学习:我是li0924. ...
- @synthesize obj=_obj的意义详解 @property和@synthesize
本文转载至 http://blog.csdn.net/ztp800201/article/details/9231969 http://hi.baidu.com/feng20068123/item/c ...
- PostgreSQL数据库smallint、bigint转到Oracle,要用什么类型替代? 是number么,那长度分别是多少?
个人意见,仅供参考:smallint是有符号或无符号2字节的整数,范围是0-65,536,5位整数bigint是有符号或无符号8字节的整数,范围是0-18,446,744,073,709,551,61 ...
- Maven 环境变量设置
下载Maven 官方下载地址:http://maven.apache.org/download.html 选择你所希望下载的版本,并保存到常用安装目录.这里以Maven 3.2.2 (Binary z ...
- PHP的函数-----生成随机数、日期时间函数
常用的函数 [1] 生成随机数 rand(); 例子: echo rand(); 显示结果: 当刷新时,会有不同的数,默认生成随机数.生成随机数不能控制范围. 如果,想要控制在范围之内,就用: e ...
- MUI 二维码扫描并跳转
1 首页 index.html <li id="html/barcode.html" onclick="clicked(this.id)"> < ...
- Hibernate插入、查询、删除操作 HQL
Hibernate的所有的操作都是通过Session完成的. 基本步骤如下: 1:通过配置文件得到SessionFactory: SessionFactory sessionFactory=new C ...
- 微信小程序 --- action-sheet底部弹框
action-sheet:从屏幕底部弹出一个菜单,选择: 使用的时候,在给不同的 action-sheet-item 添加不同的事件. 效果: (这里的确定可以有多个) 代码: <button ...
- pta 天梯地图 (Dijkstra)
本题要求你实现一个天梯赛专属在线地图,队员输入自己学校所在地和赛场地点后,该地图应该推荐两条路线:一条是最快到达路线:一条是最短距离的路线.题目保证对任意的查询请求,地图上都至少存在一条可达路线. 输 ...
- VM+CentOS+hadoop2.7搭建hadoop完全分布式集群
写在前边的话: 最近找了一个云计算开发的工作,本以为来了会直接做一些敲代码,处理数据的活,没想到师父给了我一个课题“基于质量数据的大数据分析”,那么问题来了首先要做的就是搭建这样一个平台,毫无疑问,底 ...