EM 最大似然概率估计
转载请注明出处 Leavingseason http://www.cnblogs.com/sylvanas2012/p/5053798.html
EM框架是一种求解最大似然概率估计的方法。往往用在存在隐藏变量的问题上。我这里特意用"框架"来称呼它,是因为EM算法不像一些常见的机器学习算法例如logistic regression, decision tree,只要把数据的输入输出格式固定了,直接调用工具包就可以使用。可以概括为一个两步骤的框架:
E-step:估计隐藏变量的概率分布期望函数(往往称之为Q函数 ,它的定义在下面会详细给出);
,它的定义在下面会详细给出);
M-step:求出使得Q函数最大的一组参数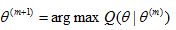
实际使用过程中,我们先要根据不同的问题先推导出Q函数,再套用E-M两步骤的框架。
下面来具体介绍为什么要引入EM算法?
不妨把问题的全部变量集(complete data)标记为X,可观测的变量集为Y,隐藏变量集为Z,其中X = (Y , Z) . 例如下图的HMM例子, S是隐变量,Y是观测值:

又例如,在GMM模型中(下文有实例) ,Y是所有观测到的点,z_i 表示 y_i 来自哪一个高斯分量,这是未知的。
问题要求解的是一组参数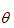 , 使得
, 使得 最大。在求最大似然时,往往求的是对数最大:
最大。在求最大似然时,往往求的是对数最大:  (1)
(1)
对上式中的隐变量做积分(求和):
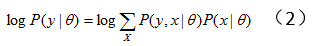
(2)式往往很难直接求解。于是产生了EM方法,此时我们想要最大化全变量(complete data)X的对数似然概率 :假设我们已经有了一个模型参数
:假设我们已经有了一个模型参数 的估计(第0时刻可以随机取一份初始值),基于这组模型参数我们可以求出一个此时刻X的概率分布函数。有了X的概率分布函数就可以写出
的估计(第0时刻可以随机取一份初始值),基于这组模型参数我们可以求出一个此时刻X的概率分布函数。有了X的概率分布函数就可以写出 的期望函数,然后解出使得期望函数最大的
的期望函数,然后解出使得期望函数最大的 值,作为更新的
值,作为更新的 参数。基于这个更新的再重复计算X的概率分布,以此迭代。流程如下:
参数。基于这个更新的再重复计算X的概率分布,以此迭代。流程如下:
Step 1: 随机选取初始值
Step 2:给定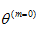 和观测变量Y, 计算条件概率分布
和观测变量Y, 计算条件概率分布
Step 3:在step4中我们想要最大化,但是我们并不完全知道X(因为有一些隐变量),所以我们只好最大化的期望值, 而X的概率分布也在step 2 中计算出来了。所以现在要做的就是求期望,也称为Q函数:
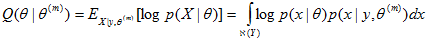
其中,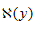 表示给定观测值y时所有可能的x取值范围,即
表示给定观测值y时所有可能的x取值范围,即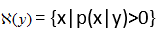
Step 4 求解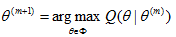
Step 5 回到step 2, 重复迭代下去。
为什么要通过引入Q函数来更新theta的值呢?因为它和我们的最大化终极目标(公式(1))有很微妙的关系:
定理1:
证明:在step4中,既然求解的是arg max, 那么必然有 。于是:
。于是:

其中,(3)到(4)是因为X=(Y , Z), y=T(x), T是某种确定函数,所以当x确定了,y也就确定了(但反之不成立);即:  而(4)中的log里面项因为不包含被积分变量x,所以可以直接提到积分外面。
而(4)中的log里面项因为不包含被积分变量x,所以可以直接提到积分外面。
所以E-M算法的每一次迭代,都不会使目标值变得更差。但是EM的结果并不能保证是全局最优的,有可能收敛到局部最优解。所以实际使用中还需要多取几种初始值试验。
实例:高斯混合模型GMM
假设从一个包含k个分量的高斯混合模型中随机独立采样了n个点 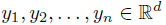 , 现在要估计所有高斯分量的参数
, 现在要估计所有高斯分量的参数 。 例如图(a)就是一个k=3的一维GMM。
。 例如图(a)就是一个k=3的一维GMM。

高斯分布函数为:

令 为第m次迭代时,第i个点来自第j个高斯分量的概率,那么:
为第m次迭代时,第i个点来自第j个高斯分量的概率,那么:
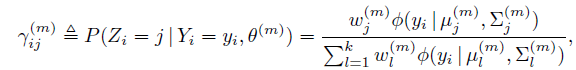 并且
并且 
因为每个点是独立的,不难证明有:

于是首先写出每个 :
:

忽略常数项,求和,完成E-step:

为简化表达,再令 ,
,
Q函数变为:
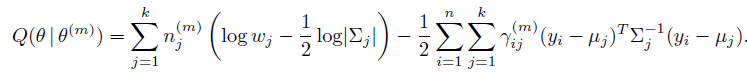
现在到了M-step了,我们要解出使得Q函数最大化的参数。最简单地做法是求导数为0的值。
首先求w。 因为w有一个约束:

可以使用拉格朗日乘子方法。 除去和w无关的项,写出新的目标函数:
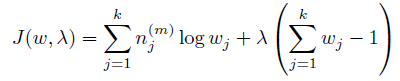
求导:
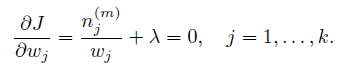
很容易解出w:

同理解出其他参数:



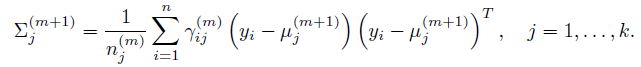
总结:个人觉得,EM算法里面最难懂的是Q函数。初次看教程的时候, 很能迷惑人,要弄清楚是变量,是需要求解的;
很能迷惑人,要弄清楚是变量,是需要求解的; 是已知量,是从上一轮迭代推导出的值。
是已知量,是从上一轮迭代推导出的值。
EM 最大似然概率估计的更多相关文章
- 最大似然概率(MLE)和最大后验概率(MAP)
https://blog.csdn.net/u011508640/article/details/72815981
- Expectation maximization - EM算法学习总结
原创博客,转载请注明出处 Leavingseason http://www.cnblogs.com/sylvanas2012/p/5053798.html EM框架是一种求解最大似然概率估计的方法.往 ...
- EM算法(Expectation Maximization Algorithm)初探
1. 通过一个简单的例子直观上理解EM的核心思想 0x1: 问题背景 假设现在有两枚硬币Coin_a和Coin_b,随机抛掷后正面朝上/反面朝上的概率分别是 Coin_a:P1:-P1 Coin_b: ...
- 机器学习——EM算法
1 数学基础 在实际中,最小化的函数有几个极值,所以最优化算法得出的极值不确实是否为全局的极值,对于一些特殊的函数,凸函数与凹函数,任何局部极值也是全局极致,因此如果目标函数是凸的或凹的,那么优化算法 ...
- 基于贝叶斯网(Bayes Netword)图模型的应用实践初探
1. 贝叶斯网理论部分 笔者在另一篇文章中对贝叶斯网的理论部分进行了总结,在本文中,我们重点关注其在具体场景里的应用. 2. 从概率预测问题说起 0x1:条件概率预测模型之困 我们知道,朴素贝叶斯分类 ...
- 从MAP角度理解神经网络训练过程中的正则化
在前面的文章中,已经介绍了从有约束条件下的凸优化角度思考神经网络训练过程中的L2正则化,本次我们从最大后验概率点估计(MAP,maximum a posteriori point estimate)的 ...
- 统计学方法(PCA、ICA、RCA、LCA)
---------------------------------------------------------------------------------------------------- ...
- EM算法——有隐含变量时,极大似然用梯度法搞不定只好来猜隐含变量期望值求max值了
摘自:https://www.zhihu.com/question/27976634 简单说一下为什么要用EM算法 现在一个班里有50个男生,50个女生,且男生站左,女生站右.我们假定男生的身高服从正 ...
- llvm中如何利用分支概率和基本块频率估计
1. 背景 llvm自2.9版以后,已经集成了对分支概率和基本块频率的静态分析. 分支概率(branch probability)是指在程序的控制流图中,从控制流从一个基本块A到其任意后继基本块Si的 ...
随机推荐
- .NET委托解析(异步委托)
上一篇我们了解到了,委托的基本感念,列举了几个委托的实例,并根据实例来反编译源码查看.NET 委托的内部实现,从浅入深的角度来详细的去解析委托的实质,本文将系上篇继续讨论异步委托的实现以及异步委托的源 ...
- 【升级至sql 2012】sqlserver mdf向上兼容附加数据库(无法打开数据库 'xxxxx' 版本 611。请将该数据库升级为最新版本。)
sqlserver mdf向上兼容附加数据库(无法打开数据库 'xxxxx' 版本 611.请将该数据库升级为最新版本.) 最近工作中有一个sqlserver2005版本的mdf文件,还没有log文件 ...
- python + docker, 实现天气数据 从FTP获取以及持久化(一)
前情提要 最近项目需要天气数据(预报和历史数据)来作为算法程序的输入. 项目的甲方已经购买了天气数据, 依照他们的约定,天气数据的供应商会将数据以"文本" (.TXT)的方式发到F ...
- js 按字段分组
var data = [{"id":"32b80b76-a81e-4545-8065-1e7c57180801","userId":&quo ...
- 分布式锁实践(一)-Redis编程实现总结
写在最前面 我在之前总结幂等性的时候,写过一种分布式锁的实现,可惜当时没有真正应用过,着实的心虚啊.正好这段时间对这部分实践了一下,也算是对之前填坑了. 分布式锁按照网上的结论,大致分为三种:1.数据 ...
- opencv_traincascade 训练自己的检测器
2013年08月08日 ⁄ 综合 ⁄ 共 1061字 ⁄ 字号 小 中 大 ⁄ 评论关闭 经过近一个月的工程实战,把自己累积的经验分享给大家,教你如何训练一个收敛的,比opencv自带的data效 ...
- 点赞功能实现 $(tag).css('属性', '样式')
1. 创建标签 document.createElement() 2.$(tag).css('属性', 样式) 赋予标签属性样式 3.设置定时器 改变位置 大小 <!DOCTYPE html&g ...
- 跨域资源共享/option 请求产生原因
https://blog.csdn.net/hfahe/article/details/7730944
- 初认识ZK
转自:https://www.jianshu.com/p/8e322462bcca 前言: 前段时间做了sdk直播服务,由于给游戏接入,所以必须要考虑并发性能问题,大家知道直播聊天,房间人数多了的话是 ...
- 【转】关于BeanUtils.copyProperties的用法和优缺点
一.简介: BeanUtils提供对Java反射和自省API的包装.其主要目的是利用反射机制对JavaBean的属性进行处理.我们知道,一个JavaBean通常包含了大量的属性,很多情况下,对Jav ...