Spark在Windows下的环境搭建
本文转载自:http://blog.csdn.net/u011513853/article/details/52865076
由于Spark是用Scala来写的,所以Spark对Scala肯定是原生态支持的,因此这里以Scala为主来介绍Spark环境的搭建,主要包括四个步骤,分别是:JDK的安装,Scala的安装,Spark的安装,Hadoop的下载和配置。为了突出”From Scratch”的特点(都是标题没选好的缘故),所以下面的步骤稍显有些啰嗦,老司机大可不必阅读,直接跳过就好。
这里我省略掉了jdk的安装和配置。
二. Scala的安装
首先从DOWNLOAD PREVIOUS VERSIONS下载到对应的版本,在这里需要注意的是,Spark的各个版本需要跟相应的Scala版本对应,比如我这里使用的Spark 1.6.2就只能使用Scala 2.10的各个版本,目前最新的Spark 2.0就只能使用Scala 2.11的各个版本,所以下载的时候,需要注意到这种Scala版本与Spark版本相互对应的关系。我这里现在用的是Scala 2.10.6,适配Spark从1.3.0到Spark 1.6.2之间的各个版本。在版本页面DOWNLOAD PREVIOUS VERSIONS选择一个适合自己需要的版本后,会进入到该版本的具体下载页面,如下图所示,记得下载二进制版本的Scala,点击图中箭头所指,下载即可:

下载得到Scala的msi文件后,可以双击执行安装。安装成功后,默认会将Scala的bin目录添加到PATH系统变量中去(如果没有,和JDK安装步骤中类似,将Scala安装目录下的bin目录路径,添加到系统变量PATH中),为了验证是否安装成功,开启一个新的cmd窗口,输入scala然后回车,如果能够正常进入到Scala的交互命令环境则表明安装成功。如下图所示:
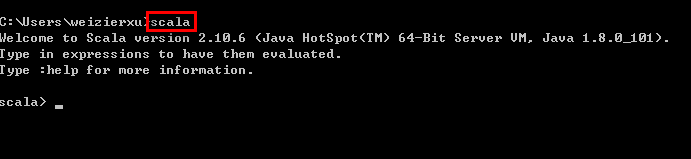
如果不能显示版本信息,并且未能进入Scala的交互命令行,通常有两种可能性:
- Path系统变量中未能正确添加Scala安装目录下的bin文件夹路径名,按照JDK安装中介绍的方法添加即可。
- Scala未能够正确安装,重复上面的步骤即可。
三. Spark的安装
Spark的安装非常简单,直接去Download Apache Spark。有两个步骤:
- 选择好对应Hadoop版本的Spark版本,如下图中所示;
- 然后点击下图中箭头所指的
spark-1.6.2-bin-hadoop2.6.tgz,等待下载结束即可。
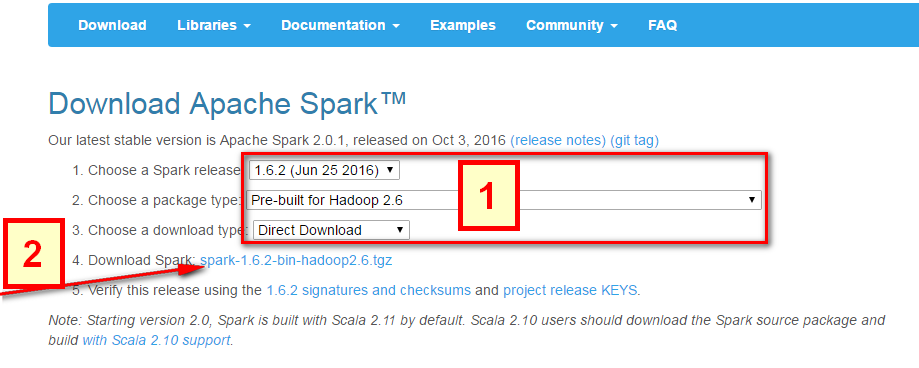
这里使用的是Pre-built的版本,意思就是已经编译了好了,下载来直接用就好,Spark也有源码可以下载,但是得自己去手动编译之后才能使用。下载完成后将文件进行解压(可能需要解压两次),最好解压到一个盘的根目录下,并重命名为Spark,简单不易出错。并且需要注意的是,在Spark的文件目录路径名中,不要出现空格,类似于“Program Files”这样的文件夹名是不被允许的。
解压后基本上就差不多可以到cmd命令行下运行了。但这个时候每次运行spark-shell(spark的命令行交互窗口)的时候,都需要先cd到Spark的安装目录下,比较麻烦,因此可以将Spark的bin目录添加到系统变量PATH中。例如我这里的Spark的bin目录路径为D:\Spark\bin,那么就把这个路径名添加到系统变量的PATH中即可,方法和JDK安装过程中的环境变量设置一致,设置完系统变量后,在任意目录下的cmd命令行中,直接执行spark-shell命令,即可开启Spark的交互式命令行模式。
四.HADOOP下载
系统变量设置后,就可以在任意当前目录下的cmd中运行spark-shell,但这个时候很有可能会碰到各种错误,这里主要是因为Spark是基于Hadoop的,所以这里也有必要配置一个Hadoop的运行环境。在Hadoop Releases里可以看到Hadoop的各个历史版本,这里由于下载的Spark是基于Hadoop 2.6的(在Spark安装的第一个步骤中,我们选择的是Pre-built for Hadoop 2.6),我这里选择2.6.4版本,选择好相应版本并点击后,进入详细的下载页面,如下图所示,选择图中红色标记进行下载,这里上面的src版本就是源码,需要对Hadoop进行更改或者想自己进行编译的可以下载对应src文件,我这里下载的就是已经编译好的版本,即图中的’hadoop-2.6.4.tar.gz’文件。
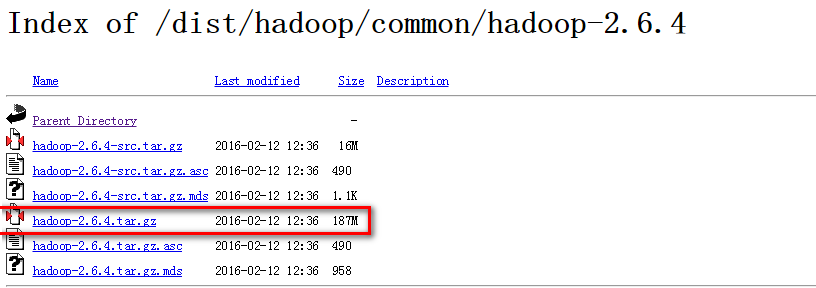
下载并解压到指定目录,然后到环境变量部分设置HADOOP_HOME为Hadoop的解压目录,我这里是F:\Program Files\hadoop,然后再设置该目录下的bin目录到系统变量的PATH下,我这里也就是F:\Program Files\hadoop\bin,如果已经添加了HADOOP_HOME系统变量,也可以用%HADOOP_HOME%\bin来指定bin文件夹路径名。这两个系统变量设置好后,开启一个新的cmd,然后直接输入spark-shell命令。
正常情况下是可以运行成功并进入到Spark的命令行环境下的,但是对于有些用户可能会遇到空指针的错误。这个时候,主要是因为Hadoop的bin目录下没有winutils.exe文件的原因造成的。这里的解决办法是:
- 去 https://github.com/steveloughran/winutils 选择你安装的Hadoop版本号,然后进入到bin目录下,找到winutils.exe文件,下载方法是点击winutils.exe文件,进入之后在页面的右上方部分有一个Download按钮,点击下载即可。
- 下载好winutils.exe后,将这个文件放入到Hadoop的bin目录下,我这里是F:\Program Files\hadoop\bin。
- 在打开的cmd中输入
F:\Program Files\hadoop\bin\winutils.exe chmod 777 /tmp/hive
这个操作是用来修改权限的。注意前面的F:\Program Files\hadoop\bin部分要对应的替换成实际你所安装的bin目录所在位置。
经过这几个步骤之后,然后再次开启一个新的cmd窗口,如果正常的话,应该就可以通过直接输入spark-shell来运行Spark了。
正常的运行界面应该如下图所示:
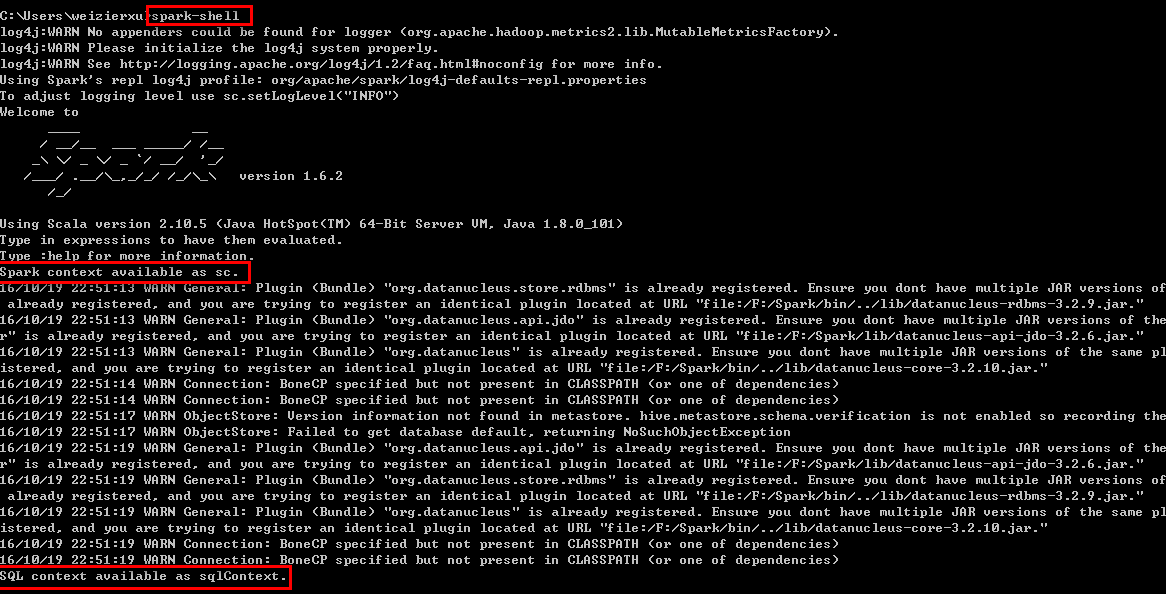
从图中可以看到,在直接输入spark-shell命令后,Spark开始启动,并且输出了一些日志信息,大多数都可以忽略,需要注意的是两句话:
Spark context available as sc.
SQL context available as sqlContext.
Spark context和SQL context分别是什么,后续再讲,现在只需要记住,只有看到这两个语句了,才说明Spark真正的成功启动了。
五. Python下的PySpark
针对Python下的Spark,和Scala下的spark-shell类似,也有一个PySpark,它同样也是一个交互式的命令行工具,可以对Spark进行一些简单的调试和测试,和spark-shell的作用类似。对于需要安装Python的来说,这里建议使用Python(x,y),它的优点就是集合了大多数的工具包,不需要自己再单独去下载而可以直接import来使用,并且还省去了繁琐的环境变量配置,下载地址是Python(x,y) - Downloads,下载完成后,双击运行安装即可。因为本教程主要以Scala为主,关于Python的不做过多讲解。
并且,pyspark的执行文件和spark-shell所在路径一致,按照上述方式解压好spark后,可以直接在cmd的命令行窗口下执行pyspark的命令,启动python的调试环境。
但是如果需要在python中或者在类似于IDEA IntelliJ或者PyCharm等IDE中使用PySpark的话,需要在系统变量中新建一个PYTHONPATH的系统变量,然后
PATHONPATH=%SPARK_HOME%\python;%SPARK_HOME%\python\lib\py4j-0.10.4-src.zip
设置好后,建议使用PyCharm作为IDE(因为IDEA IntelliJ的设置繁琐很多,没耐心了设置一堆参数啦,哈哈哈)
六. 小结
至此,基本的Spark本地调试环境便拥有了,对于初步的Spark学习也是足够的。但是这种模式在实际的Spark开发的时候,依然是不够用的,需要借助于一个比较好用的IDE来辅助开发过程。下一讲就主要讲解ItelliJ IDEA以及Maven的配置过程。
七. Tips
- 血的教训:永远不要在软件的安装路径中留有任何的空格
- 网上找Hadoop 2.7.2的winutils.exe找不到的时候,直接用2.7.1的winutils.exe,照样能用
(2017.06.14更新)
参考
- PATH and CLASSPATH(Oracle官方给出的一些关于Path和CLASSPATH的解释,推荐)
- Difference among JAVA_HOME,JRE_HOME,CLASSPATH and PATH
- Java中设置classpath、path、JAVA_HOME的作用
- Why does starting spark-shell fail with NullPointerException on Windows?(关于如何解决启动spark-shell时遇到的NullPointerException问题)
Spark在Windows下的环境搭建的更多相关文章
- Spark在Windows下的环境搭建(转)
原作者:xuweimdm 原文网址:http://blog.csdn.net/u011513853/article/details/52865076 由于Spark是用Scala来写的,所以Spa ...
- Spark学习笔记--Spark在Windows下的环境搭建
本文主要是讲解Spark在Windows环境是如何搭建的 一.JDK的安装 1.1 下载JDK 首先需要安装JDK,并且将环境变量配置好,如果已经安装了的老司机可以忽略.JDK(全称是JavaTM P ...
- 二、Spark在Windows下的环境搭建
由于Spark是用Scala来写的,所以Spark对Scala肯定是原生态支持的,因此这里以Scala为主来介绍Spark环境的搭建,主要包括四个步骤,分别是:JDK的安装,Scala的安装,Spar ...
- Spark学习笔记--Spark在Windows下的环境搭建(转)
本文主要是讲解Spark在Windows环境是如何搭建的 一.JDK的安装 1.1 下载JDK 首先需要安装JDK,并且将环境变量配置好,如果已经安装了的老司机可以忽略.JDK(全称是JavaTM P ...
- Windows下的环境搭建Erlang
Windows下的环境搭建 Erlang 一.安装编译器 在http://www.erlang.org/download.html下载R16B01 Windows Binary File并安装. 二. ...
- Redis在windows下的环境搭建
Redis在windows下的环境搭建 下载windows版本redis,,官方下载地址:http://redis.io/download, 不过官方没有Windows版本,官网只提供linux版本的 ...
- 2017.7.18 windows下ELK环境搭建
参考来自:Windows环境下ELK平台的搭建 另一篇博文:2017.7.18 linux下ELK环境搭建 0 版本说明 因为ELK从5.0开始只支持jdk 1.8,但是项目中使用的是JDK 1.7, ...
- Windows下Django环境搭建
总体示意图如下: Windows下搭建Django环境 1.安装Python版本 2.安装pip工具,一般Python安装都会自动会有这个,在你python安装命令下Scripts文件夹下 3.dj ...
- windows下cocos2d-x环境搭建
该教程使用的cocos2dx的版本为3.14,3之后的大概都差不多 Python环境搭建: cocos2dx在windows上新建工程需要用到python脚本,安装python-2.7.x,可以上py ...
随机推荐
- c#pdf查看器
Free Spire.PDF for .NET is a Community Edition of the Spire.PDF for .NET, which is a totally free PD ...
- 【Docker】Windows下docker环境搭建及解决使用非官方终端时的连接问题
背景 时常有容器方面的需求,经常构建调试导致测试环境有些混乱,所以想在本地构建一套环境,镜像调试稳定后再放到测试环境中. Windows Docker 安装 安装docker toolbox 博主的电 ...
- Android之获取输入用户名与密码发送短信
打算在过两三天的时间我就要准备出发去浙江了,所以把之前的资料来个总结. 这都是在课堂上做过的作业. 好了,废话少说,直接上代码. 步骤: 1.设置单击事件2.获取输入的QQ号码与密码3.判断输入获取的 ...
- 网络TCP建立连接为什么需要三次握手而结束要四次
忽然顿悟了,不管三次握手,还是四次握手,这是保证信息来回两个链路可达(也就是信息能从A到B,也能从B到A)的最低要求.-2018-9-17-晚上九点 举个打电话的例子: A : 你好我是A,你听得到我 ...
- css括号风格
1.nested 2.expanded 3.compact 压缩但是不去掉空格和注释 4.compressed 压缩并且去掉空格和注释,并且有的压缩变量名也会改变.
- IOS-适配iOS10以及Xcode8
现在在苹果的官网上,我们已经可以下载到Xcode8的GM版本了,加上9.14日凌晨,苹果就要正式推出iOS10系统的推送了,在此之际,iOS10的适配已经迫在眉睫啦,不知道Xcode8 beat版本, ...
- hdu5818
题解: 维护两个左偏树 按照左偏树模板来做 代码: #include<cstdio> #include<cmath> #include<algorithm> #in ...
- 前端常用框架和js插件 UI组件等
前言:写这个随笔,是记录一下工作以来用到的各种框架.以免日后忘记: JS库: 1. jquery.js 2. zepto.js ----jquery的精简版,专门用于手机上的,但是zepto主体默认是 ...
- ES6介绍二 函数的增强
ES6对于函数的使用新增了很多实用的API,JS的函数跟很多后台语言PHP,ASP.NET开始看齐: 1. 参数默认值: 以前我们为了给函数创建默认值,必须用一种冗杂的语句,而且有歧义的语句. //E ...
- Vim技能修炼教程(17) - 编译自己的Vim
编译自己的Vim 前面我们已经对Vim有比较丰富的了解了.我们也知道Vim有很多编译时的选项,很多功能依赖于这些编译选项.其中最重要的就是脚本语言的支持,很多发行版本是不全的.为了支持我们所需要的功能 ...