jemalloc内存分配器详解
前言
C 中动态内存分配malloc 函数的背后实现有诸派:dlmalloc 之于 bionic;ptmalloc 之于 glibc;allocation zones 之于 mac os x/ios;以及 jemalloc 之于 FreeBSD/NetBSD/Firefox。
malloc 实现对性能有较大影响,而 jemalloc 似乎是目前诸实现中最强的,并在 facebook 内广泛使用,参见 facebook 的使用心得。
对此,我们按照知乎 “怎样给招式起一个一听就很厉害的名字?” 的指导,拟了本文标题,并速度道来。
2 简介
这是一个关于电商的故事,我下了一个单,订购一块 N 字节的内存,并等待它的到达。怎样做到即时送达?
如果订购的内存是个小件(好比一块橡皮、一本书或是一个微波炉等),那么直接从同城仓库送出。
如果订购的内存是个大件(好比电视机、空调等),那么得从区域仓库(例如华东区仓库)送出。
如果订购的内存是个巨大件(好比汽车、轮船),那么得从全国仓库送出。
在 jemalloc 类比过来的物流系统中,同城仓库相当于 tcache —— 线程独有的内存仓库;区域仓库相当于 arena —— 几个线程共享的内存仓库;全国仓库相当于全局变量指向的内存仓库,为所有线程可用。
在 jemalloc 中,整块批发内存,之后或拆开零售,或整块出售。整块批发的内存叫做 chunk,对于小件和大件订单,则进一步拆成 run。
Chunk 的大小为 4MB(可调)或其倍数,且为 4MB 对齐;而 run 大小为页大小的整数倍。
在 jemalloc 中,小件订单叫做 small allocation,范围大概是 1-57344 字节。并将此区间分成 44 档,每次小分配请求归整到某档上。例如,小于8字节的,一律分配 8 字节空间;17-32分配请求,一律分配 32 字节空间。
对于上述 44 档,有对应的 44 种 runs。每种 run 专门提供此档分配的内存块(叫做 region)。
大件订单叫做 large allocation,范围大概是 57345-4MB不到一点的样子,所有大件分配归整到页大小。
以上总结成下图:

上图中:
- arena_chunk_t:属于 arena 的 chunk 头部有此结构体。该结构体末尾是一个数组
arena_chunk_map_t map[]。 - run for small allocation。主要特点是分成了等长的若干 regions,每次请求分配出一个 region。通过头部元数据(详见 5)来记录分配状态,例如标记分配状态的 bitmap。
- run for large allocation,无元数据。
- 未分配的 run。它将被分割用于 2 情形,或者 3 情形。
最后,巨大件订单,叫做 huge allocation,所有巨大件请求归整到标准 chunk 大小(4MB)的整数倍。
3 分配内存
下面我们从 jemalloc 代码中,来一探其诸分配过程。分配函数的入口在je_malloc/MALLOC_BODY/imalloc/imalloct。
jemalloc 的内存分配,可分成四类:
- 内部使用
- 用于 small allocation
- 用于 large allocation
- 用于 huge allocation,分配出的内存全部交付使用
其中 small 和 large allocation较为复杂,且以下图作为地图,来导游下: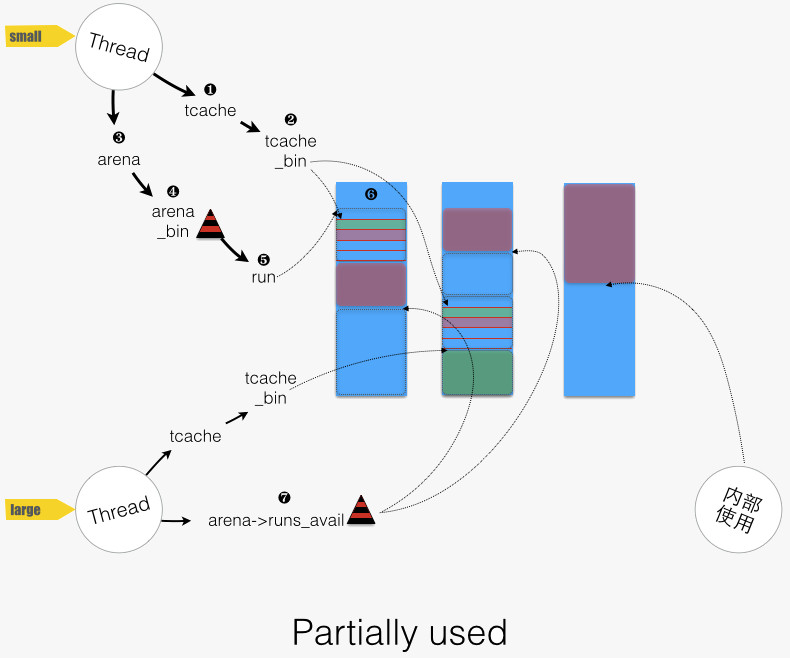
3.1 Small allocation
对于 small allocation,需要确定 请求大小 对应 到哪一“档位” 上,确定的公式如下: small_size2bin[(size - 1) » 3],该公式通过查数组,来确定“档位”。
在 jemalloc 中,某“档位”上可分配的内存资源,用 bin 来管理。
回到 small allocation 过程,首先从线程本身的 tcache 中去满足,函数路径为imalloct/arena_malloc/tcache_alloc_small:
- 图中的 “1 -> 2”:找到对应的 bin,然后尝试分配。函数路径为
tcache_alloc_small/tcache_alloc_easy(tcache_bin) - 当 tcache_bin 为空时,从 arena 进货,填充(
arena_tcache_fill_small)后再分配,函数路径为tcache_alloc_small/tcache_alloc_small_hard
tcache 特性关闭时,则从 arena 中分配,函数路径为imalloct/arena_malloc/arena_malloc_small:
- 图中“3 -> 4”:找到对应的 bin。
- 图中“4 -> 5”:从 bin 中选择一个 run
- 尝试 arena_bin->run_cur ,即目前正在使用的 run。
- 若该 run_cur 已满,则从 bin 中选择地址最低的 run。arena_bin->runs 用了一个红黑树来按地址排序全部的runs。函数路径为
arena_malloc_small/arena_bin_malloc_hard/arena_bin_nonfull_run_get/arena_bin_nonfull_run_tryget - 若 bin 为空,则从 arena->runs_avail 中找空间,分配新的 run。函数路径为
arena_bin_nonfull_run_get/arena_run_alloc_small/arena_run_alloc_small_helper。 - 尼玛 arena->runs_avail 也空间不够了,只好重新弄个 chunk,分出所需空间,剩余部分放入 arena->runs_avail 。
- 图中“5”:从 run 中分配一个 region,对应函数为
arena_run_reg_alloc(run, bin_info)。
3.2 Large allocation
首先从 tcache 中满足。对于 large allocation,tcache 将“档位”的概念拓展,其“档位”计算公式如下: NBINS + (size » PAGE) – 1。
函数路径为arena_malloc/tcache_alloc_large,两点说明:
- tcache 只涵盖一部分的 large allocation 请求(size 小于等于 tcache_maxclass)
- 对应的 tcache_bin 为空时,不进行填充,而是走非 tcache 分配。这点与 small allocation 的情形是不同的。
tcache 特性关闭,或者请求大小超过 tcache 中最大 bin 覆盖范围时,则从 arena 中分配,函数路径为arena_malloc/arena_malloc_large:
- 图中“7”:从 arena->runs_avail 中,找出适合空间中地址最低的一块空间,分割出空间,将剩余部分重新放回 arena->runs_avail 中。函数路径为
arena_malloc_large/arena_run_alloc_large_helper - 若 arena->runs_avail 空间也不够,重新分配 chunk,分出所需空间,剩余部分放入 arena->runs_avail 。
3.3 内部使用
内部使用所需的内存分配,使用 base_alloc,只申请,不释放。因此在当前使用的 chunk 中,分配区域呈现线性增长。
base_alloc 使用场合有:
- nodes:用来管理未使用的 chunks。在 base_alloc 基础上再封一层 base_node_alloc,先从 base_nodes 缓冲中取,失败再调用 base_alloc;释放函数 base_node_dealloc 将 node 链接入 base_nodes。
- 其他:如 arenas、arena_t、tcache_bin_info 等。
3.4 实际分配函数
前述,je_malloc 总是按照 chunk 尺寸从 OS 批发内存,对应函数为 chunk_alloc。
chunk_alloc 先从“回收站”中回收不用的chunk,若没无再从 OS 批发。
chunk_alloc 有几个有名的客户:
- arena_chunk_alloc,分配 arena 名下的 chunk(供 small/large allocation 分配)。arena_chunk_alloc 分配时,先看本 arena 下是否有备用的 chunk,没有再调 chunk_alloc。
- base_alloc,base_alloc 在当前使用的 chunk 空间不足时,调用 chunk_alloc。
- huge_malloc,用于满足 huge allocation。
上述提及的 chunks “回收站”,用于回收释放的 chunk,如下图所示:
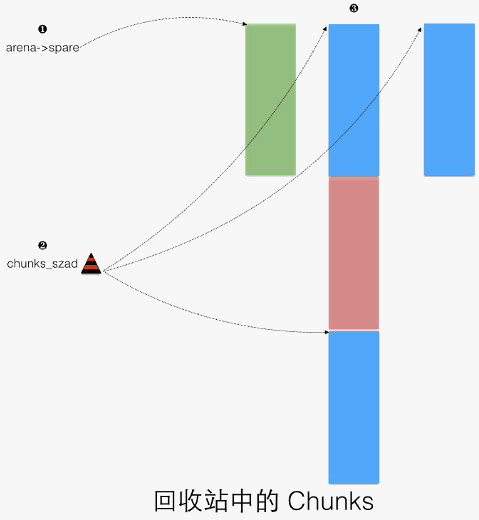
- arena 中的备用 chunk,供 arena_chunk_alloc 中使用。
- chunks_szad_*,红黑树,按照先尺寸、后地址来排序所有不用的 chunks。
- 一个 3 个标准 chunks 大小的 chunk,中间一个 chunk 被分配出。首尾不用的 chunks 被 chunks_szad_* 引用。
4 小结
至此,我们粗步游了一遍 jemalloc 的内存分配,眼花撩乱了没?
总结一下 jemalloc 的设计思路:
- 减少多线程竞争。例如引入 tcache,以及线程均分布到若干个 arena(s)。
- 地址空间重用,减少碎片:
- Small allocation,“归档位”、从各 runs 中分配
- 红黑树来保证同等条件下,总是从低地址开始分配
- 合并相邻的空闲空间
- 保持 cache 热度,例如 tcache,地址空间重用。
- 各种对齐,自然对齐,cache line 对齐。
同时,我们也看到 jemalloc 有层层缓冲,例如:
- tcache
- arenas 名下的缓冲:bins 管理的 runs(for small allocations) 以及 arena->runs_avail
- 内部使用的缓冲,base_nodes 以及其当前使用的 chunk 的剩余空间
- 回收站中的 chunks,例如 chunks_szad_*,arena->spare
由此,在一个普遍使用 jemalloc 的系统中会产生许多内存额外占用,这对实时性要求较高、内存较为紧张的移动设备而言是不可接受的。
我们可以调节 jemalloc 配置,来减少额外的内存占用,例如将 chunksize 调整为 1MB、调节 small allocation 所需“档位”数目、tcache 大小调整,等等。
同时,更重要的,jemalloc 中的内存释放系统,能否及时平衡额外的占用,我们将在下一篇中来看看。
最后,是否存在一种有效的联动机制,在系统整体内存紧张时,通知各进程释放掉额外的缓冲?这样就不用 OOM killer 了。
在上面的讲解中,我们看到了一个类似电商物流体系的内存分配体系,其中 tcache 是本线程内存仓库; arena 是几个线程共享的区域内存仓库;并且存在所有线程共用的内存仓库。
另一方面,jemalloc 按照内存分配请求的尺寸,分了 small allocation (例如 1 – 57344B)、 large allocation (例如 57345 – 4MB )、 huge allocation (例如 4MB以上)。
jemalloc 以 chunk (例如标准大小为 4MB)为单位批发内存,并再分成 run(s) 来满足实际的需求。对于 small allocation ,进一步将 run 分成 region(s) 。
最后,疑惑 jemalloc 的层层缓冲,会造成过多的内存占用,这对实时性要求较高,内存较为紧张的移动设备影响较大。对此,jemalloc 如何应对呢?还有,是否存在系统内存紧张时,减少缓冲的联动机制呢?
2 How to free()?
在内存分配时,jemalloc 按照 small/large/huge allocation 来特殊处理。因此,释放时,需要由地址来判断为何种分配类型。
我们知道分配出去的空间,都属于某个 chunk,首先通过将地址对齐到 标准 chunk 大小,找到所属 chunk(还记得 chunk 是按照 标准 chunk 大小对齐的么)。函数路径:je_free/ifree/iqalloc/iqalloct/idalloct:
- 对于 huge allocation,free 的地址本身在 chunk 边界上。搜索全局的 huge 树来获得本次分配的长度。函数路径:
idalloct/huge_dalloc。 - 对于 small/large allocation,根据 free 的地址所在页在 chunk 内的相对页号,访问 chunk 头部的 arena_chunk_map_t 数组,获得进一步的信息,函数路径为
idalloct/arena_dalloc。下图为其示意:
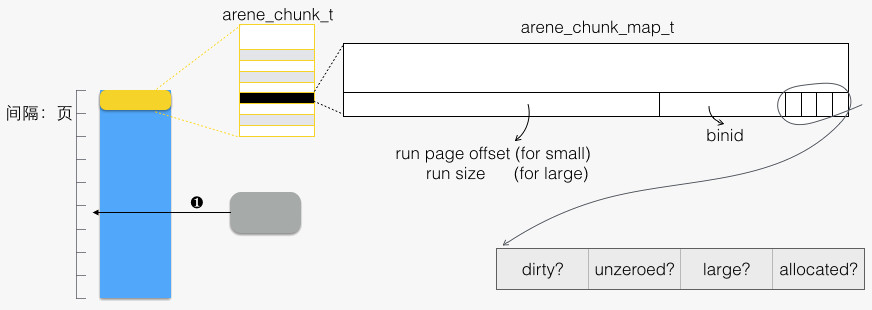
对于 small allocation,large 位为 0。下面以 small allocation 为主线,开展一场内存回归之旅。
2.1 free to tcache
下图为 tcache 的示意,tcache 用于屏蔽常用的内存分配和释放(所有 small 和部分 large 类型的),免得“代码走的太远”。函数路径: arena_dalloc/tcache_dalloc_small
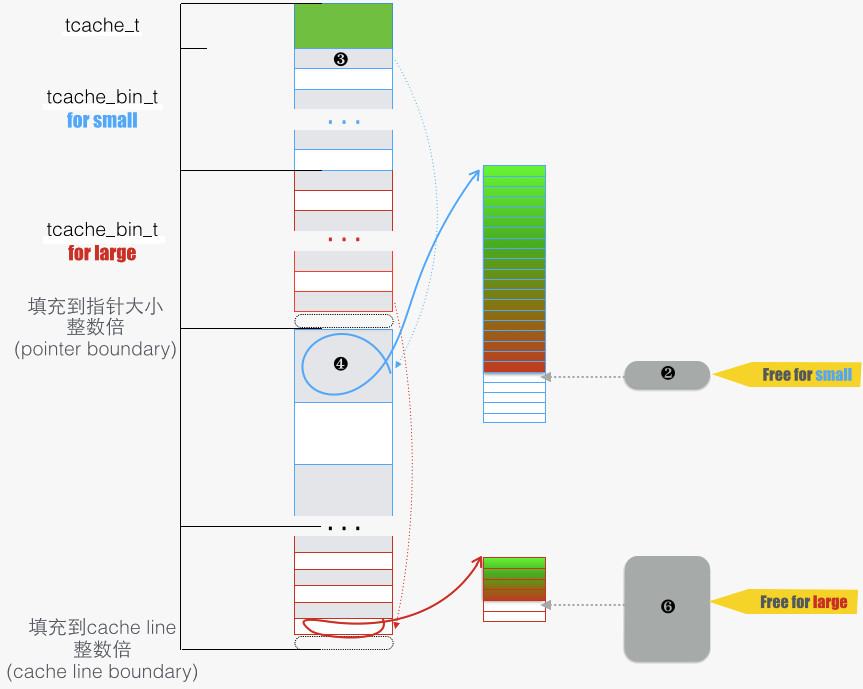
- 2 → 3:释放一段 region,首先要知道所属 bin(tcache_bin_t)。Q:如何找到所属 bin?可以从对应 arena_chunk_map_t 成员中的 binid 域。
- 3 → 4:tcache_bin_t 用指针数组来收纳释放的内存,这是一个栈的结构。最近释放的内存放在栈顶,使得下次被先分配出去。如此能保持 cache 热度。
2.2 缩减 tcache
当 tcache_bin_t 满了以后,或者 GC 事件被触发,则降低 tcache_bin_t 中缓冲内存的数量,如下图:
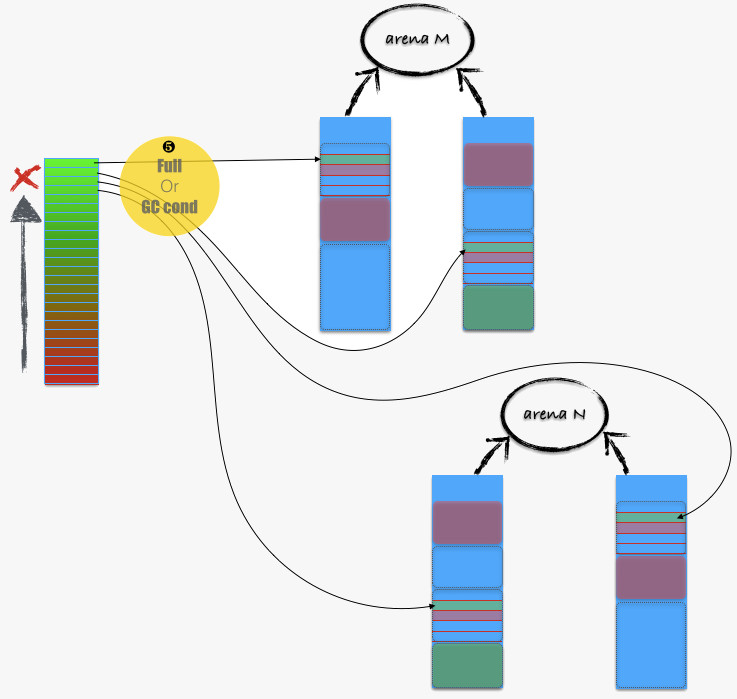
基本上的过程就是让 tcache_bin_t 中部分缓冲内存“各回各家” —— 回到所在 arena 中的 chunk 中的 run 内。
注意,刷的过程是将 栈底 N 个内存刷回,然后将其它部分整体移到栈底,这么做同样是保持 cache 热度。
啰嗦下 flush 触发的两个条件:
- tcache_bin_t 满了。函数路径为
tcache_dalloc_small/tcache_bin_flush_small。 - GC 条件满足。函数路径为
tcache_dalloc_small/tcache_event/tcache_event_hard/tcache_bin_flush_small。注意:此时 flush 的 bin,由 tcache->next_gc_bin 指出。
再来看看具体的回归过程,即从 tcache_bin_t 到 run,函数路径为tcache_bin_flush_small/arena_dalloc_bin_locked。如下图所示:
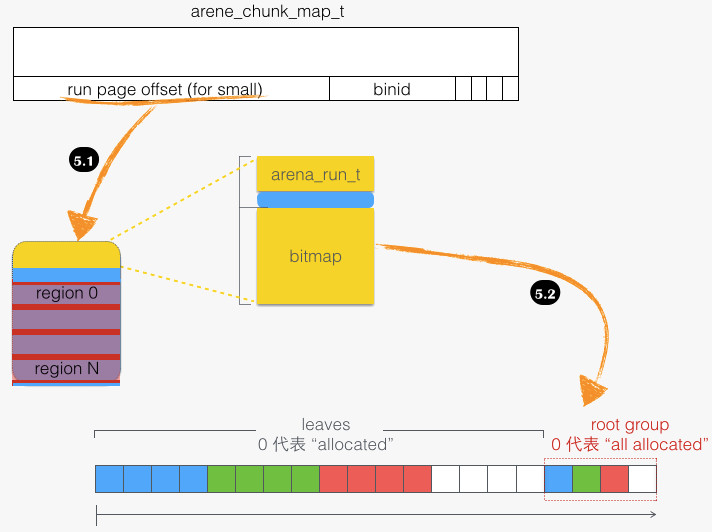
- 5 → 5.1:首先找到 run 结构体,然后才能塞回去。run 结构体在整个 run 块头部(图中黄色部分),我们知道 run 块本身占有多个页面,待“回归”的 region 本身可能在 run 中间某个页,这需要通过 “ run page offset ”来定位 run 块的起始位置,从而找到 run 结构体。
- 5.1 → 5.2:释放具体的 region,主要是将 region 在 bitmap 中对应位置 1。两个细节:一是 region 索引通过函数
arena_run_regind获得,该函数试图避免整数除法,来减少计算开销;二是 bitmap 这个数据结构,为 sfu 操作 (set first unallocated)) 优化,而 sfu 正是为了实现 jemalloc 先分配出低地址的设计。bitmap 背后围绕“扫描最先设置位”的指令实现,该指令被封装到函数 ffsl 中。
对应函数路径为 arena_dalloc_bin_locked/arena_run_reg_dalloc。
2.3 释放 run
当 region 刷回 run,可能产生两种“深远”影响,如下图:
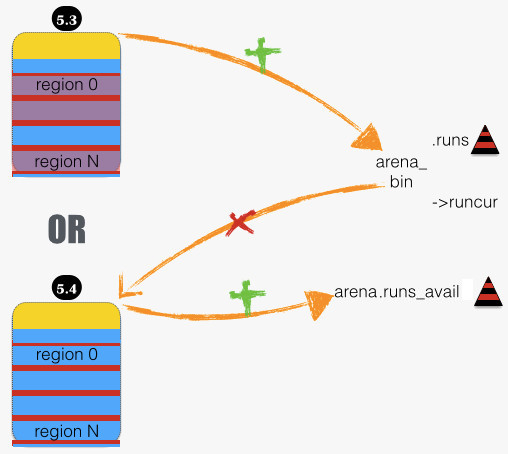
- 5.3: 当原来全用完的 run,现在有一个 region 可分配了,将其插入所属 bin 中,供分配。
- 5.4:当 run 全空了,则释放之:从所属 bin 中移除,并将空间交还给 arena.runs_avail。
下图展开 5.4 部分细节,函数路径为 arena_dalloc_bin_locked/arena_dalloc_bin_run:
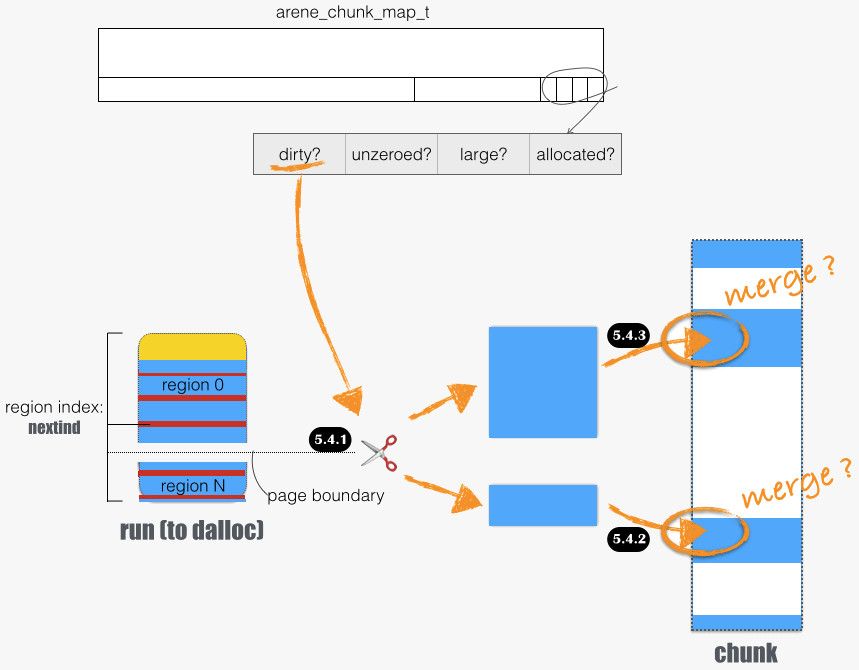
在 jemalloc 中,定义了内存区域的额外属性:
- dirty? 一个内存区域被分配出去以后,就是“脏”的。脏的意思是,虚拟地址背后的物理页被分配了。jemalloc 有定期的清理过程,通过 “madvise(addr, length, MADV_DONTNEED)” 释放背后的物理内存。
- unzeored? 某些情况下,从 OS 批发来的内存区域已经初始化成全零了,例如 “madvise(addr, length, MADV_DONTNEED) 以后” 。如此标记后可免除某些清零操作。
dirty 页面一定是 unzeroed。当一个分配出去的、clean 的 run 被释放,并回归 arena.runs_avail,就会标记为 dirty。一个例外是 run for small allocation,通过 nextind 成员我们可以知道,哪些页面没有事实上被分配出。5.4.1 展示了这种情形:
- run 后半部分未被分配,且原 run 是干净的。如 5.4.2:这部分塞回所在 chunk 时,会与之后相邻的、 干净 的空闲内存区域合并(如果存在的话),函数路径为
arena_dalloc_bin_run/arena_run_trim_tail/arena_run_dalloc/arena_run_coalesce - run 前半部分被分配了,故是脏的。如 5.4.3:这部分塞回所在 chunk 时,会与之前相邻的、 脏 的空闲内存区域尝试合并(如果存在的话),函数路径为
arena_dalloc_bin_run/arena_run_dalloc/arena_run_coalesce
这里细节再啰嗦下:arena_run_dalloc 函数中会尝试合并。为方便合并,需要在 run 首尾页面的两项 arena_chunk_map_t 赋值为有意义值。
2.4 释放 chunk
释放 run 以后,进一步可能导致 chunk 被释放。函数路径为:arena_run_dalloc/arena_chunk_dealloc:
arena_avail_remove把 chunk 从 arena.runs_avail 和 arena.chunks_dirty 中移除。- 进入 arena->spare,并“挤走(chunk_dealloc)”先前的spare chunk。这又体现了维持 cache 热度的原则。
唠叨下 chunk_dealloc,对于走 mmap 从 os 批发的内存(which is mo ren fang shi),该函数会通过 mnumap 进行释放,而不是放到 chunks_szad 全局红黑树中。
对于走 sbrk 从 OS 批发的内存,则在放入 chunks_szad 全局红黑树前,通过 madvise 通知 OS 来释放背后的物理页面。
所以 chunk 的释放,实际上释放了 chunk 的物理内存。
2.5 垃圾回收
最后,来看下 jemalloc 是如何运功逼走多余内存缓冲的。jemalloc 中,有两个层面的回收,一是 tcache 中多余缓冲赶到 arena 中;二是将 arena.runs_avail 中多余的物理内存释放掉一些。分别是下表的左右两部分:
|
tcache_event_hard |
arena_maybe_purge |
|
|
作用对象 |
tcache |
arena |
|
阀值条件 |
tbin->low_water > 0 |
npurgeable = ndirty – npurgatory threshold = nactive >> lg_dirty_mult npurgeable > threshold |
|
GC 对象 |
tcache->next_gc_bin (bin 索引号) |
arena->chunks_dirty (红黑树) |
|
GC 数量 |
3/4 * low_water |
npurgeable – threshold |
|
反馈1 |
调整填充率 (lg_fill_div) |
ndirty 减少 |
|
反馈2 |
low_water = ncached (GC 完成后的 ncached 另:low_water <= ncached) |
npurgatory 减少 |
来啰嗦下右边过程,函数路径为 arena_run_dalloc/arena_maybe_purge/arena_purge:
- 以 chunk 为单位进行。chunk 从 arena.chunks_dirty 中取,实际上是先处理含有分离的脏区域多(ndirty),且因此导致较多碎片(nruns_adjac)的情况。
- 对每个 chunk 用函数
arena_chunk_purge来洗净。该函数先让脏块 “出列”,再进行 “清洗”,最后再 “入列”:- “出列”:挑选碎片区域,分配出来(
arena_run_split_large),并放入一个临时链表。所谓碎片是指,两块空闲的区域,地址相接邻,但由于其干净程度不一样,成了碎掉的两片。 - “清洗”:遍历链表,用 madvise 逐一洗干净。
- “入列”:释放回去(
arena_run_dalloc),前述释放时会进行合并(arena_run_coalesce),由此减少了碎片,并可能导致整个chunk 被释放。
- “出列”:挑选碎片区域,分配出来(
3 小结
至此,终于写完了这篇长的要死的文章。忽想起张无忌学完了太极剑,啥招都忘了,只会了剑(贱?)意。那么忘了 jemalloc 那些细招,剩下了哪些贱意呢?随便说说有
- 循环利用最近扔掉的内存,因为 cache 还有印象,对这块内存比较熟悉。
- 总是从最低地址分配,创造局部性环境。毕竟 cache 记性不好,跨度太大的内存人家反应慢。
- 打通任督二脉,及时逼走多余的缓冲内存。
回头看看之前的疑问,层层缓冲会不会使进程过多占用内存呢?
- tcache 过多的内存缓冲 —— GC 会处理的。
- arena.bins —— for small allocation,无处理。
- arena.avail_runs —— GC 会处理的。
- arena->spare —— 如果是 dirty 的,无处理。保持直到有新释放的 chunk 进入 spare,挤走本座。
- 内部使用的缓冲 —— 无处理。
- chunks_szad —— 无物理内存占用。
OK,除了第 2 和 第 4 点需要改进下以外,其他看起来都有应对机制了。其中第 2 点可以通过调整 run 大小 和 档位来缓解。
第 4 点,是一个可优化的地方。
最后,系统物理内存紧张时,能否进行联动,即缩减应用额外的内存缓冲呢?也许我们可以引入一种特殊的 madvise 指示,告诉内核这段地址空间是作缓冲的,在紧张时可以优先释放,且不用交换。
jemalloc内存分配器详解的更多相关文章
- C语言内存对齐详解(2)
接上一篇:C语言内存对齐详解(1) VC对结构的存储的特殊处理确实提高CPU存储变量的速度,但是有时候也带来了一些麻烦,我们也屏蔽掉变量默认的对齐方式,自己可以设定变量的对齐方式.VC 中提供了#pr ...
- C语言内存对齐详解(3)
接上一篇:C语言内存对齐详解(2) 在minix的stdarg.h文件中,定义了如下一个宏: /* Amount of space required in an argument list for a ...
- Tomcat内存设置详解
Java内存溢出详解 一.常见的Java内存溢出有以下三种: 1. java.lang.OutOfMemoryError: Java heap space ----JVM Heap(堆)溢出 JVM在 ...
- Tomcat内存溢出详解【转载】
本文转载自 http://elf8848.iteye.com/blog/378805 Java内存溢出详解 一.常见的Java内存溢出有以下三种: 1. java.lang.OutOfMemoryEr ...
- Linux 内存机制详解宝典
Linux 内存机制详解宝典 在linux的内存分配机制中,优先使用物理内存,当物理内存还有空闲时(还够用),不会释放其占用内存,就算占用内存的程序已经被关闭了,该程序所占用的内存用来做缓存使用,对于 ...
- (转)Tomcat内存设置详解
Java内存溢出详解 一.常见的Java内存溢出有以下三种: 1. java.lang.OutOfMemoryError: Java heap space ----JVM Heap(堆)溢出JVM在启 ...
- Java学习之二维数组定义与内存分配详解
二维数组:就是元素为一维数组的一个数组. 格式1: 数据类型[][] 数组名 = new 数据类型[m][n]; m:表示这个二维数组有多少个一维数组. n:表示每一个一维数组的元素有多少个. 注意: ...
- String类内存空间详解
java.lang.String类内存问题详解 字符串理解的难点在于其在堆内存空间上的特殊性,字符串String对象在堆内存上有两种空间: 字符串池(String pool):特殊的堆内存,专门存放S ...
- 《转载》Tomcat内存设置详解
原文地址:Java内存溢出详解 一.常见的Java内存溢出有以下三种: 1. java.lang.OutOfMemoryError: Java heap space ----JVM Heap(堆)溢出 ...
随机推荐
- 用训练好的caffemodel来进行分类
caffe程序自带有一张小猫图片,存放路径为caffe根目录下的 examples/images/cat.jpg, 如果我们想用一个训练好的caffemodel来对这张图片进行分类,那该怎么办呢? 如 ...
- springMVC中不通过注解方式获取指定Service的javabean
如TestService,其实现为TestServiceImpl,则可以通过 TestService testService = (TestService)SpringContextHolder.ge ...
- 递归--练习11--noi9273 PKU2506Tiling
递归--练习11--noi9273 PKU2506Tiling 一.心得 25 a[i]%=10;(高精度时) 26 这里错了,花了好久改好 27 28 29 int* f(int n){ 30 if ...
- bzoj2330: [SCOI2011]糖果 差分约束系统
幼儿园里有N个小朋友,lxhgww老师现在想要给这些小朋友们分配糖果,要求每个小朋友都要分到糖果.但是小朋友们也有嫉妒心,总是会提出一些要求,比如小明不希望小红分到的糖果比他的多,于是在分配糖果的时候 ...
- zoj3261变形并查集
需要变形的并查集,这题错了好久,一直没a掉,终于在重写第三次的时候a了 先保存数据,把不需要拆分的边合并,逆向计算,需要拆分时就合并,之前不知道为啥写搓了,tle好久 #include<map& ...
- 310. Minimum Height Trees -- 找出无向图中以哪些节点为根,树的深度最小
For a undirected graph with tree characteristics, we can choose any node as the root. The result gra ...
- notepad++个人专注
notepad++个人专注 快捷键 功能 1 Ctrl>>>>>>>>>> Ctrl + b 匹配括号 Ctrl + d 选中 ...
- Xilinx Microblaze Bootloader
作者:Hello,Panda 一般而言,Xilinx Microblaze会被用来在系统中做一些控制类和简单接口的辅助性工作,比如运行IIC.SPI.UART之类的低速接口驱动,对FPGA逻辑功能模块 ...
- python的单元测试代码编写流程
单元测试: 单元测试是对单独的代码块分别进行测试, 以确保它们的正确性, 单元测试主要还是由开发人员来做, 其余的集成测试和系统测试由专业的测试人员来做. python的单元测试代码编写主要记住以下几 ...
- RF/GBDT/XGBoost/LightGBM简单总结(完结)
这四种都是非常流行的集成学习(Ensemble Learning)方式,在本文简单总结一下它们的原理和使用方法. Random Forest(随机森林): 随机森林属于Bagging,也就是有放回抽样 ...