从Chrome源码看audio/video流媒体实现一(转)
现在绝大多数的网站已经从flash播放器转向了浏览器原生的audio/video播放器,浏览器是如何加载和解析多媒体资源的,这对于web开发者来说是一个黑盒,所以很有必要看一下浏览器是怎么实现的,Chromium文档介绍了整体的过程是这样的:
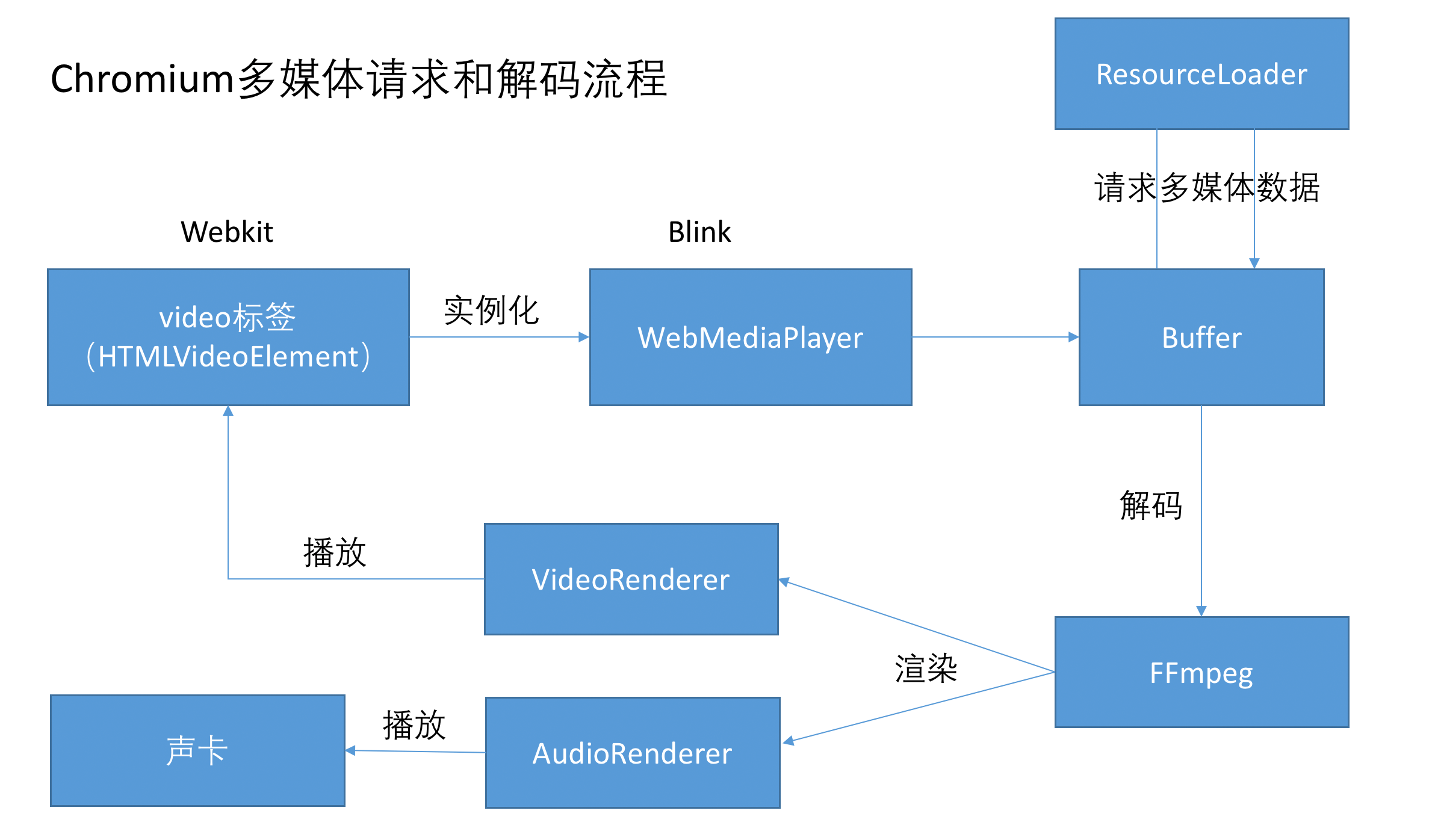
大体来说,由video标签创建一个DOM对象,它会实例化一个WebMediaPlayer,这个player是控制中枢,player驱使Buffer去请求多媒体数据,然后交由FFmpeg进行多路解复用和音视频解码(FFmpeg是一个开源的第三方音视频解码库),再把解码后的数据传给相应的渲染器对象进行渲染绘制,最后让video标签去显示或者声卡进行播放。
这里面有两个问题需要重点关注:
(1)编解码的过程是怎么样的?
(2)流媒体数据的传输是怎么控制的?
1. 编解码基础
摄像机或者相机通过镜头里的感光元件,把收到的光转换为电子像素,一个像素是由rgba 4通道组成,在视频里面通常只有rgb 3通道,共8b * 3 = 24b = 3B即3个字节,一个1080p(1920 * 1080),帧率为30fps(一秒钟有30张图片)时长为1分钟的视频有多大呢?计算如下:
3B * 1920 * 1080 * 30 * 60 = 12441600000B = 10GB
约有10GB,一个100分钟的电影就需要占用1TB的硬盘空间,所以如果没有压缩的话这个体积是非常巨大的。但是我们看到一个1080p的mp4文件(h264,普通码率)平均1分钟的体积只有100MB不到,如下图所示:
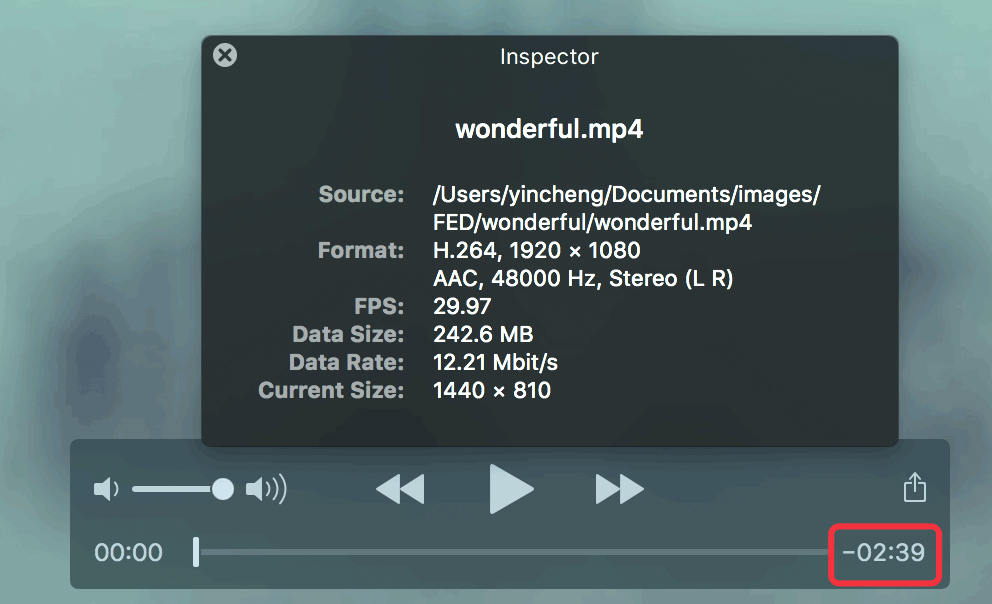
在这个例子里面,h264编码的mp4文件压缩比达到了100:1。
因此编码的目的就是压缩,而解码的目的就是解压缩。压缩又分为有损压缩和无损压缩,无损压缩如gzip/flac,是可以还原成原本未压缩的完整数据,而有损压缩如h264/mp3等一旦压完之后就无法再还原成更高清晰度的数据了。
视频编码通常都是有损压缩,目标是降低一点清晰度的同时让体积得到大大的减少,降低的清晰度能达到对人眼不可察觉或者几乎无法分辨的水平。主要是方法是去除视频里面的冗余信息,对于很多不是剧烈变化的场面,相邻帧里面有很多重复信息,通过帧间预测等方法分析和去除,而帧内预测可去掉同个帧里的重复信息,还有对画面观众比较关注的前景部分高码率编码,而对背景部分做低码率编码,等等,这些取决于不同的压缩算法。
视频的编码方式从MPEG-1(VCD)到MPEG-2(DVD)再到MPEG-4(数码相机),再到现在主流的网络视频用的h264和比较新的h265,同等压缩质量下,压缩率不断地提到提升,它们可能都是.mp4的文件后缀,mp4格式是一个容器, 可以支持流式传输,不用把整个文件下载下来才播放。另外还有谷歌主导的VP8、VP9和AV1编码(主要在WebRTC里面使用)。编码的压缩率越好,它的算法通常会更复杂,所以一些低端设备可能会扛不住进而使用较老的编码格式。
解码的目的就是解压缩,把数据还原成原始的像素。FFmpeg是一个很出名的开源的编解码C库,Chrome也使用了它做为它的解码器之一,并且有人把它转成了WASM,可以在网页上跑。
视频是用rga像素表示相对比较好理解,声音又是怎么表达呢?
屏幕图像是用rgb即红绿蓝三原色混合组成各种各样的颜色,而声音是物体振动挤压空气形成的声波,它主要有3个感观属性:音量(振幅)、音调(频率)、音色,不同材料的音色不一样,但是一个几块钱的耳机为什么能够发出各种各样的音色的声音呢?
要形成声音需要振幅的周期性变化,如果只是振幅不断单向变大是形成不了声音的,下图表示一个声音的振幅随时间变化的波形:
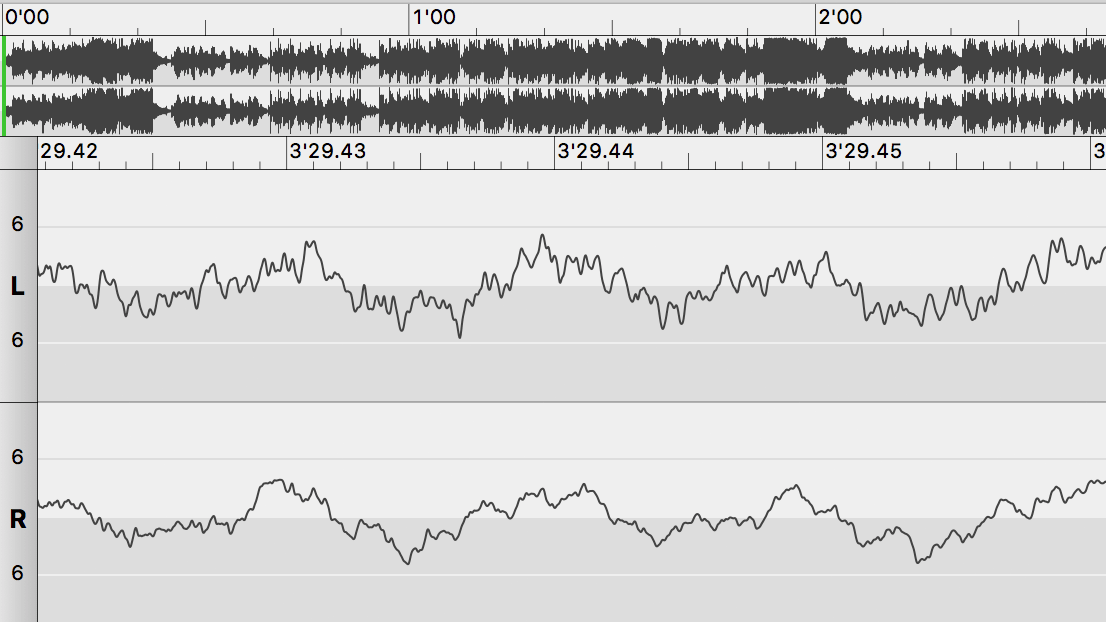
纯音的波形是一个正弦曲线,但是在现实世界里面一个物体主体部分在振动的同时,它上面的不同部位也会在做自己的振动,主体振动发出的声音叫基音,子部位发出的声音叫谐音,谐音往往有成百上千个,也就是说有上千个正弦曲线叠加:
y = 1/2 sin(x) + 3/7 sin(x) + …
就形成了上面不规则的周期性曲线。这条曲线就决定了声音的所有属性包括音量(最大振幅和最小振幅的差距)、音调(周期性变化的快慢)以及音色,一个确定的波形就确定了音色。也就是说只要把喇叭按照上面的振幅移动就能够还原记录的声音。这就是声音播放的原理,没错就是这么简单。那么这些帧幅是怎么记录的呢?
视频是每秒25或者30帧图像形成连续的动画,用离散来表示连续,声音也是同样道理,它有一个采样率的概念,麦克风把声音转化为不同强度的电流信号,就像开了一个水龙头源源不断地流水,每一点的水温都是不一样的,如果采样率为1k Hz即1s 1000次,1s测1000次流过的水的温度,CD唱片音质的采样率44.1k Hz,所以为了高保真,1s需要测44k次。
温度大小表示也是连续的,所以有一个位深的概念,位深为16位则表示有16位二进制数来表示水温的水平,从低到高共65536个层次。
所以采样率和位深就决定了音质的好坏,我们知道CD是超高音质的代表了,它的采样率是44.1kHz和位深是16位,1分钟的双声道(立体音)声音的CD格式存储需要占用的硬盘空间大小为:
44100 * 16b * 60 / 8 * 2 = 10MB
所以一个没有压缩的声音1分钟需要10MB的空间,记录为PCM格式,而FLAC/APE等编码是无损压缩,相对zip/gzip,它的特点是能够实时播放。
而mp3格式是有损压缩,它有一个码率的概率,标准规定码率最高为320kbps,常见的还有128kbps/192kbps等,如果码率为192kbps,它是意思是每秒有192kb大小的内容:192kb = 192kB/ 8 = 24kB,每分钟有24kB * 60 = 1.44MB,相对于PCM的10MB,压缩比为7 : 1,所以这个压缩率也是挺高的,对于192kbps的音质和无损音质,一般的音响或者普通人的耳朵来说已经无法分辨。
MP3压缩的原理主要是人耳的听觉掩蔽效应,对低频声音会比高频的声音感知度更高,压缩时进行频谱分析,把一些高频的声音降低分配的位数,从而达到极小失真但大大小减少体积的目的。
h264的音轨主要使用AAC编码格式,相对于mp3同等音质AAC的压缩率更高。
所以声音解码的目的就是把mp3/aac等格式还原成原始的PCM格式。
2. Chrome的buffer控制加载机制
在流媒体传输里面有一个重要的概念就是buffer缓冲空间大小,如果buffer太大,那么一次性下载的数据太多,用户还没播到那里不划算,相反如果buffer太小不够播放可能会经常卡住加载。在实时传输领域,实时流媒体通信的双方如果buffer太大的话会导致延迟太大,如果buffer太小那么能做的事情就比较少如拥塞控制、丢包重传等。
我们可以来看一下Chrome播放音视频的时候buffer是怎么控制的,它的实现是在src/media/blink/multibuffer_data_source.cc这个文件的UpdateBufferSizes函数,简单来说就是每次都往后预加载10s的播放长度,并且最大不超过50MB,最小不小于2MB,往前是保留2s播放长度。
详细来说,首先要获取码率,即1s的音视频需要占用的空间,如下代码所示:
|
1
2
3
4
5
6
7
8
9
10
|
// If bitrate is not known, use this.
const int64_t kDefaultBitrate = 200 * 8 << 10; // 200 Kbps.
// Maximum bitrate for buffer calculations.
const int64_t kMaxBitrate = 20 * 8 << 20; // 20 Mbps.
// Use a default bit rate if unknown and clamp to prevent overflow.
int64_t bitrate = clamp<int64_t>(bitrate_, 0, kMaxBitrate);
if (bitrate == 0)
bitrate = kDefaultBitrate;
|
有一个默认码率是200Kbps,最大码率不超过20Mbps,如果还不知道码率的情况下就使用默认码率。在使用一个mp3文件做demo研究的时候发现preload了3次之后才拿到码率,如下图所示:

码率为128kbps,知道码率之后再获取播放速率通常为默认的1倍速,进而知道10s应该是多少空间:
// 这里的播放速率playback_rate为1
|
1
2
3
4
5
6
7
|
// Increase buffering slowly at a rate of 10% of data downloaded so
// far, maxing out at the preload size.
int64_t extra_buffer = std::min(
preload, url_data_->BytesReadFromCache() * kSlowPreloadPercentage / 100);
// Add extra buffer to preload.
preload += extra_buffer;
|
对一个60Mb的视频,播放到中间的时候,这个extra_buffer的值大概就是3MB,如下打印输出:
../../media/blink/multibuffer_data_source.cc, 733: extra_buffer = 3107155
然后把preload值传给BufferReader,由它去触发请求相应的数据。这个是使用http range功能请求相应范围的字节数,如下检查Chrome的请求:
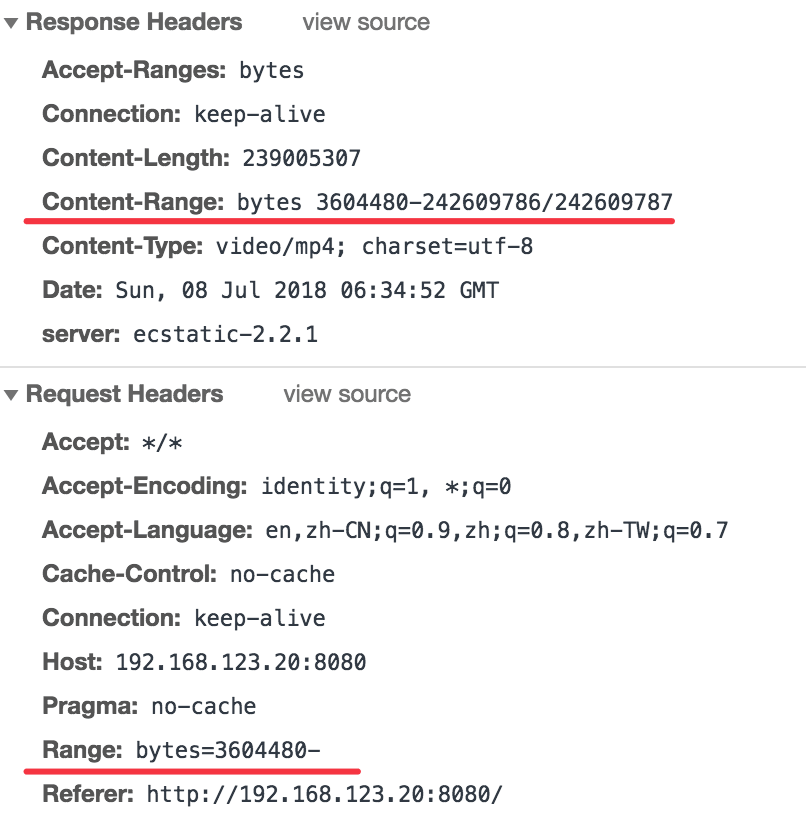
在某个请求里面Chrome请求的范围起点是从3604480开始,没有终点,但是这里并不是说Chrome只是发一个请求然后一次性把整个文件下载下来了,它应该是通过拥塞窗口之类的方法控制接收的速率,具体没有深入去研究,把视频暂停了你会发现加载停止了,再播放原先的http返回数据量又开始变大。
对于很多视频网站我们发现他们的range都是指定明确范围的:

相比之下原生播放器的策略只是使用一个http连接加载不同字节范围的视频数据,而视频网站是每需要一个range的数据的时候就发一个请求。这些请求的响应状态码都是206,表示返回部分内容。如果连接断了或者服务端只返回部分数据就关闭连接,那么chrome会重新发个请求。另外打开页面的时候chrome不会提前预加载数据,只有点击播放了才加载音视步内容。并且preload的buffer size是在加载过程中周期性更新的。
综上,本篇主要介绍了编解码的基础,chrome的buffer加载机制,以及chrome加载和解析流媒体的基本模型,我们还没有讨论具体的解码过程,下一篇将会继续研究。
从Chrome源码看audio/video流媒体实现一(转)的更多相关文章
- 从Chrome源码看audio/video流媒体实现二(转)
第一篇主要介绍了Chrome加载音视频的缓冲控制机制和编解码基础,本篇将比较深入地介绍解码播放的过程.以Chromium 69版本做研究. 由于Chromium默认不能播放Mp4,所以需要需要改一下源 ...
- 从Chrome源码看浏览器的事件机制
.aligncenter { clear: both; display: block; margin-left: auto; margin-right: auto } .crayon-line spa ...
- 从Chrome源码看JS Array的实现
.aligncenter { clear: both; display: block; margin-left: auto; margin-right: auto } .crayon-line spa ...
- 从Chrome源码看浏览器如何构建DOM树
.aligncenter { clear: both; display: block; margin-left: auto; margin-right: auto } p { font-size: 1 ...
- 从微信小程序开发者工具源码看实现原理(一)- - 小程序架构设计
使用微信小程序开发已经很长时间了,对小程序开发已经相当熟练了:但是作为一名对技术有追求的前端开发,仅仅熟练掌握小程序的开发感觉还是不够的,我们应该更进一步的去理解其背后实现的原理以及对应的考量,这可能 ...
- 从微信小程序开发者工具源码看实现原理(四)- - 自适应布局
从前面从微信小程序开发者工具源码看实现原理(一)- - 小程序架构设计可以知道,小程序大部分是通过web技术进行渲染的,也就是最终通过浏览器的dom tree + cssom来生成渲染树:既然最终是通 ...
- 从源码看Azkaban作业流下发过程
上一篇零散地罗列了看源码时记录的一些类的信息,这篇完整介绍一个作业流在Azkaban中的执行过程,希望可以帮助刚刚接手Azkaban相关工作的开发.测试. 一.Azkaban简介 Azkaban作为开 ...
- Google Chrome 源码下载地址 (Google Chrome Source Code Download)
1. Google Chrome 源码 SVN 地址:http://src.chromium.org/svn.包含有 Chrome.Gears.Webkit.GCC 等源码以及编译依赖工具.Chrom ...
- 解密随机数生成器(二)——从java源码看线性同余算法
Random Java中的Random类生成的是伪随机数,使用的是48-bit的种子,然后调用一个linear congruential formula线性同余方程(Donald Knuth的编程艺术 ...
随机推荐
- python+caffe训练自己的图片数据流程
1. 准备自己的图片数据 选用部分的Caltech数据库作为训练和测试样本.Caltech是加州理工学院的图像数据库,包含Caltech101和Caltech256两个数据集.该数据集是由Fei-Fe ...
- 用ksh运行一个helloworld
本文目的在于记录和回顾.不建议当教程. Linux上没有ksh的话yum install ksh就可以了 直接上图 vim一个文件后缀名是ksh 内容是和shell差不多 然后赋予这个文件可执行权限 ...
- 转:IE 无法使用 js trim() 的解决方法
http://hi.baidu.com/yuiezt/item/756d0f4ec4d2640ec11613f9 var aa = $("#id").val().trim() ...
- 【原创】Google的文本内容对比代码
/* * Diff Match and Patch * * Copyright 2006 Google Inc. * http://code.google.com/p/google-diff-matc ...
- Python读取Matlab的.mat文件
参考网站: https://blog.csdn.net/rumswell/article/details/8545087 数据: R 22*22 double 部分截图如下: 使用sicpy.io即可 ...
- 路飞学城Python-Day16
- layero和index
zIndex:layer.zIndex, success:function(index,layero){ //layero 为当前层的DOM对象 var zIndex = layer.index; $ ...
- DedeCMS搜索结果页面调用自定义字段的方法
有时候在我们需要在dedecms的搜索结果页面调用自定义字段,尤其是在做下载站的时候,需要在搜索结果页调用软件大小以及软件等级等等,但是我们发现在搜索结果页模板中使用“[field:字段名]”标签无法 ...
- 关于JavaScript中this的指向,你知晓几分?请速来围观!
---恢复内容开始--- 一.this是什么东东? this是指包含它的函数作为方法被调用时所属的对象.这句话理解起来跟卵一样看不懂,但是如果你把它拆分开来变成这三句话后就好理解一点了. 1.包含它的 ...
- [六省联考2017]分手是祝愿(期望+DP)
题解 很容易想出来最优策略是什么. 就是从n到1看到开着的灯就把它关了 我们预处理出当前状态把灯全部关闭后的最少步数cnt 然后我们的主人公就要瞎按... 设dp[i]代表当前状态最优解为i步时走到d ...