BUAA_OO_博客作业三
1 JML语言总结
1.1 JML语言的理论基础
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言。JML是一种行为接口规格语言(Behavior Interface Specification Language,BISL),基于Larch方法构建。BISL提供了对方法和类型的规格定义手段。所谓接口即一个方法或类型外部可见的内容。JML主要由Leavens教授在Larch上的工作,并融入了Betrand Meyer, John Guttag等人关于Design by Contract的研究成果。近年来,JML持续受到关注,为严格的程序设计提供了一套行之有效的方法。
JML将注释添加到JAVA代码中,这样我们就可以确定方法所执行的内容,JML 为说明性的描述行为引入了许多构造。这些构造包括模型字段、量词、断言的可见度范围、前提条件、后置条件、不变量、合同继承以及正常行为与异常行为的规范。这些构造使得 JML 的功能变得非常强大。
布尔表达式
| 作用 | 与 | 或 | 非 | 蕴含 | 全称量词 | 存在量词 |
|---|---|---|---|---|---|---|
| JML | && | || | ! | ==> | \forall | \exists |
量化表达式
\sum 返回给定范围内的表达式的和。
\produc 返回给定范围内的表达式的连乘结果
\max 返回给定范围内的表达式的最大值
\min 返回给定范围内的表达式的最小值
\num_of 返回指定变量中满足相应条件的取值个数
操作符
E1<:E2 子类型关系操作符
b_expr1<==>b_expr2 等价关系操作符
b_expr1==>b_expr2 推理操作符
assignable \nothing 变量引用操作符
1.2 应用工具链情况
OpenJML
官网链接:http://www.openjml.org/downloads/
语法检查
openjml -check <source files>
java项目语法检查结果列表
http://www.openjml.org/documentation/checks.shtml
JMLUnitNG
官网链接:http://insttech.secretninjaformalmethods.org/software/jmlunitng/
jar 包链接:http://insttech.secretninjaformalmethods.org/software/jmlunitng/assets/jmlunitng.jar
2 SMT Solver
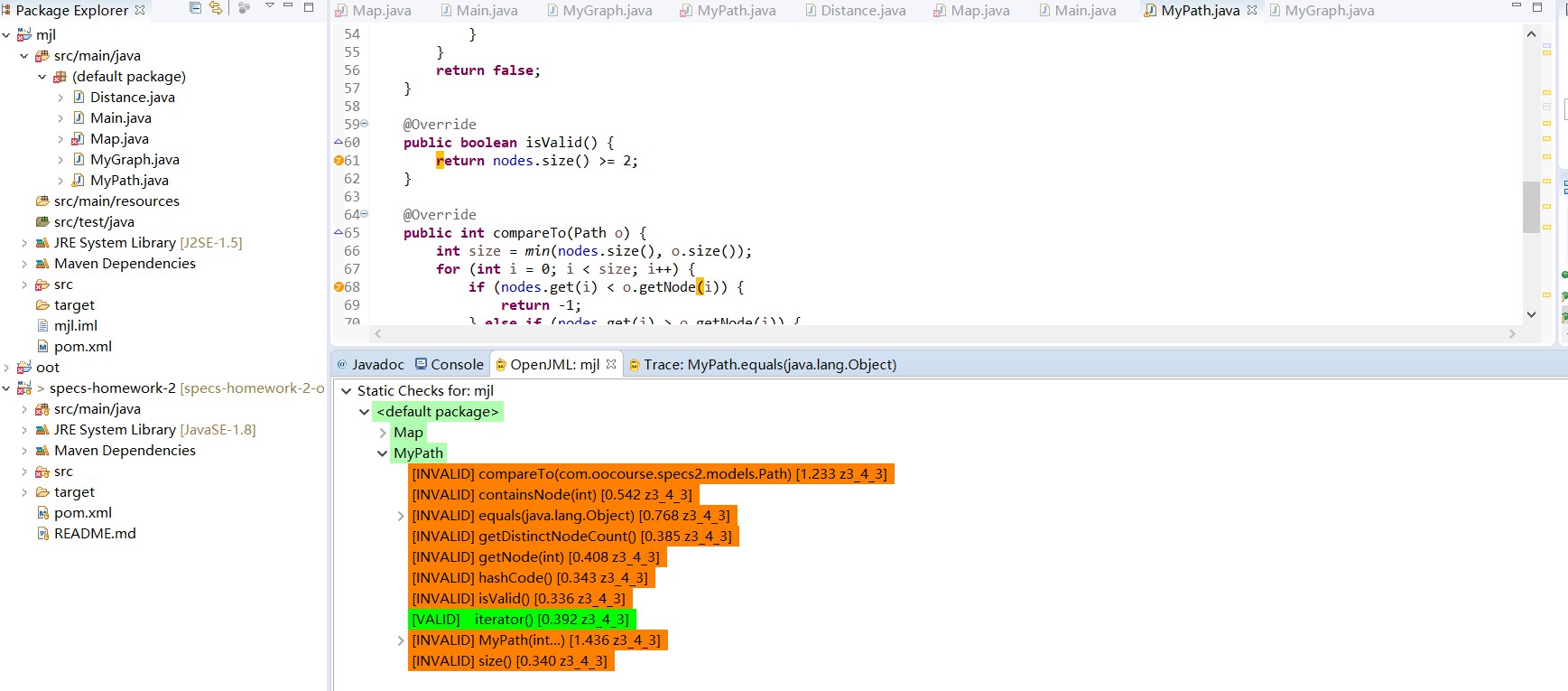
我把第10次作业重新创建成maven项目,然后从IDEA平台转战Eclipse,终于可以使用SMT Solver自动生成测试了,但是我发现测试后我的所有函数基本上都是INVALID,然后我去查看具体错误样例,发现最后一次测试的size都会与真实值差1,我也不太明白为什么会出现这个错误,按道理我是完全按照规格写的。
MyPath.size()自动测试结果图
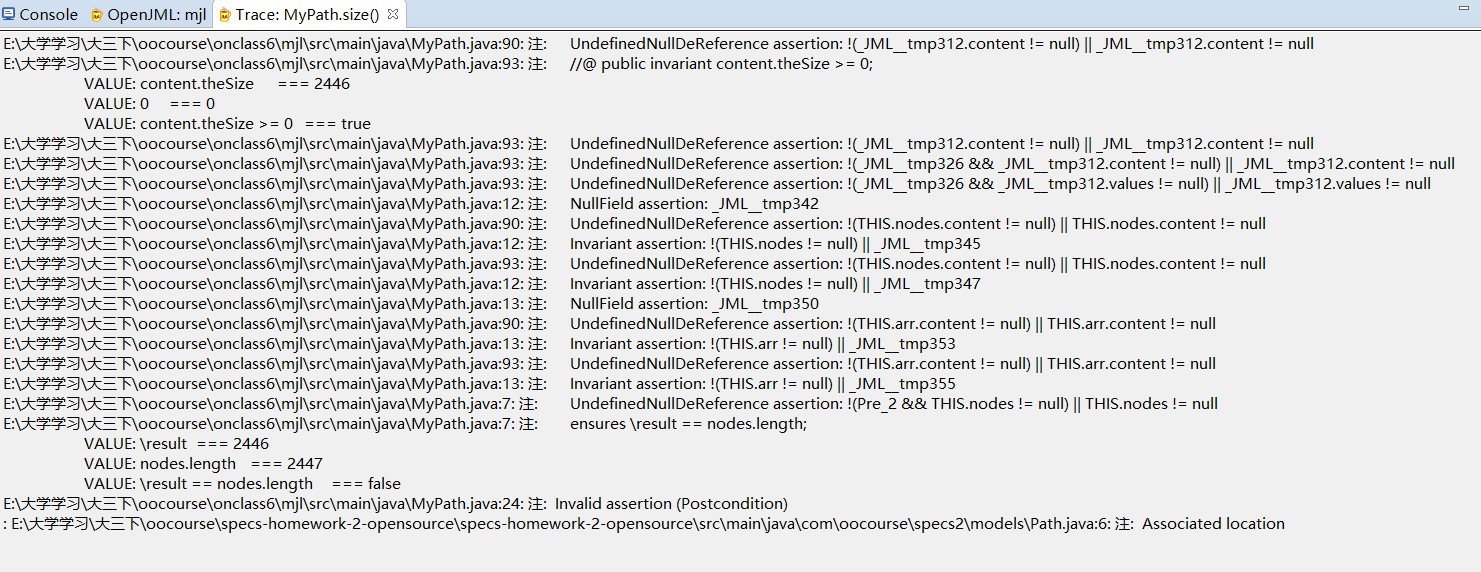
MyPath.equals()自动测试结果图
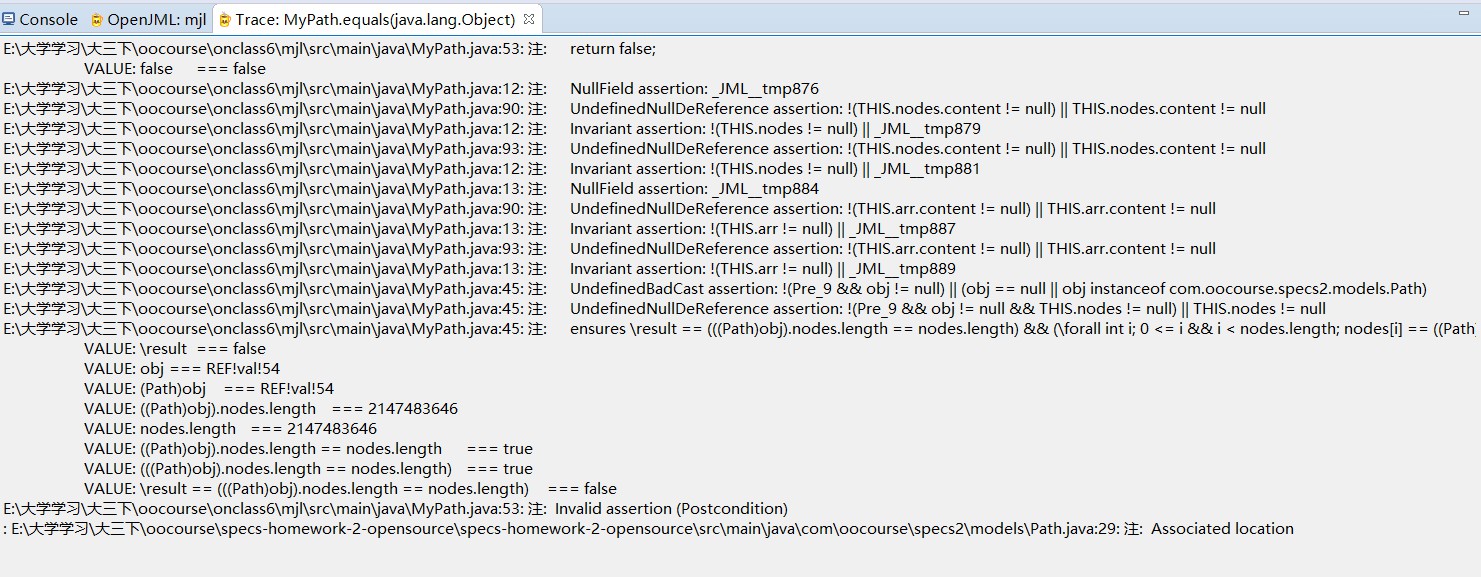
MyPath.getDistinctNodeCount()自动测试结果图
MyPath.compareTo()自动测试结果图
3 JML Unit
使用方式:
1)First, write specifications for methods of interest (i.e. write pre and post conditions using JML syntax).
2)Make sure that your Java code AND jml-release.jar are in your classpath. setenv CLASSPATH “.:/opt/JML/bin/jml-release.jar”
3)Use jmlc command – this is JML compiler. This compiles the Java program with the JML specifications and checks for syntactic errors.
4)Use jmlunit command – this is the JMLUnit test code generator. This generates _JML_TestData.java and _JML_Test.java files (and creates code for all necessary oracles). The first one is used to generate test data. The second one is a test driver.
5)At this point, you can edit the _JML_TestData.java files to add your own test data.
6)Use javac to compile the test driver and test data code.
7)Use jmlrac command – this runs your tests.
实现了对简单函数的JML UNIT自动生成测试检测,指令顺序如下
java -jar E:\JML\JMLUnitNG.jar -cp specs-homework-2-1.2-raw-jar-with-dependencies.jar E:\JML\JML1\src\MyPath.java
javac -cp E:\JML\JMLUnitNG.jar;E:\JML\JML1\src E:\JML\JML1\src\MyPath_JML_Test.java
java -jar E:\JML\openjml-0.8.42-20190401\openjml.jar -exec E:\JML\openjml-0.8.42-20190401\Solvers-windows\z3-4.7.1.exe -cp E:\JML\JML1\specs-homework-1-1.1-raw-jar-with-dependencies.jar -rac E:\JML\JML1\src\MyPath.java
java -cp .;E:\JML\JMLUnitNG.jar;E:\JML\JML1\specs-homework-1-1.1-raw-jar-with-dependencies.jar MyPath_JML_Test

可以发现,JMLUNIT检测了边界条件,将我测试的Mypath中的基础函数进行了正确性检验。
4 我的架构设计
第9次作业
类图
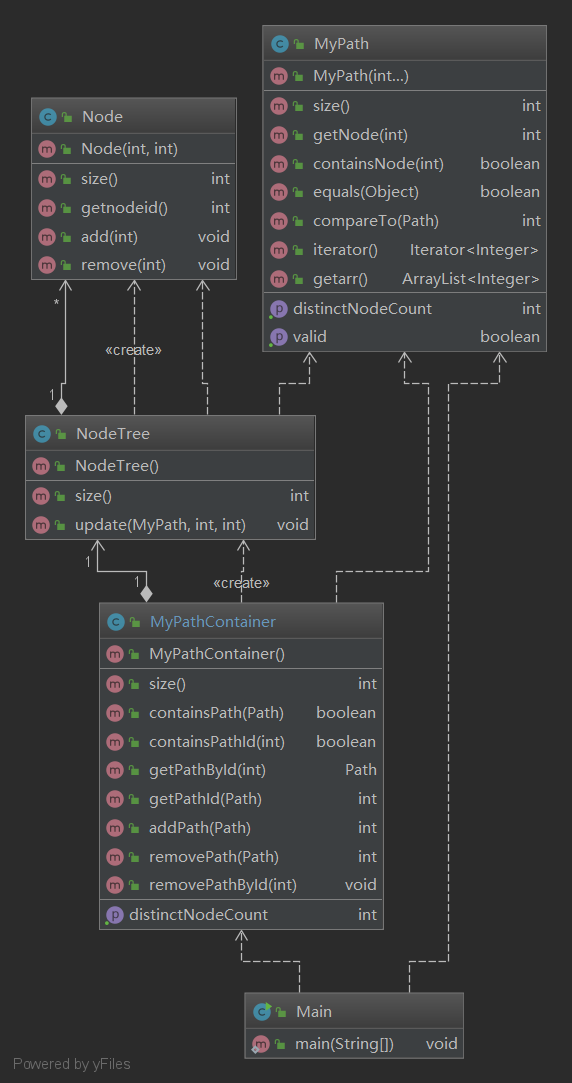
由于这个单元的作业都是按照JML规格进行编写,所以大部分函数的实现都是完全按照规格的步骤进行一步一步编写,这个单元我没有用HashMap这个快捷的数据结构(以为哪一种数据结构都可以通过测试)
在MyPath中定义了以下三种数据,由于我第一次作业的不成熟,我把arr也就是这个path的不同点通过自定义函数的方式传给了MyPathContainer,为了方便我对path中的不同点的查找,但是这样做破坏了path的耦合性(不可取)。
private ArrayList<Integer> nodes;
private ArrayList<Integer> arr;
在MyPathContainer中定义了以下四种数据
private ArrayList<Path> plist;
private ArrayList<Integer> pidList;
private NodeTree nt;
private static int no = 1;
特别说明NodeTree是我当时没想到HashMap,所以自己定义了一个节点与Path连接的类,在这个类里,实现了增删path时对于DistinctNodeCount的更新操作,update这个函数中的func参数就是增删的选择参数,这样我只要在增删path的时候对于这个类进行更新就可以快速改变内容,所以这次作业最难的函数getDistinctNodeCount()我只需要返回这个类的size就可以了。
public class NodeTree {
private ArrayList<Node> nodetree;
public NodeTree() {
nodetree = new ArrayList<>();
}
public int size() {
return nodetree.size();
}
public void update(MyPath o, int pid, int func) {}
第10次作业
类图

由于意识到了HashMap的优势,我把上次作业的大部分数据结构都做了调整,改为HashMap了,下图为我两个主要java函数所使用的数据。
//MyPath.java
private ArrayList<Integer> nodes = new ArrayList<>();
private HashSet<Integer> arr = new HashSet<>();
//MyGraph.java
private HashMap<Path, Integer> plist;
private HashMap<Integer, Path> pidlist;
private HashMap<Integer, Integer> diffnode;
private int no;
private Map map;
由于这次作业中包含的Path和PathContainer两个接口的规格没有发生变动,所以这次作业设计这两个接口的地方基本使用了上次架构,除了改动数据结构的使用,另外就是在addpath和removepath增加了对于图结构的更新操作。
下面来说明我的图类
public class Map {
private HashMap<Integer, HashMap<Integer, Integer>> nodes;
private Distance dis;
private HashSet<Integer> visit;
}
这次作业最重要的就是要实现最短路径的查询,图是一个无权无向图,我选择的是dijistra的更新距离操作。nodes的结构为一个HashMap套另一个HashMap,第一个Integer是一条边的起始顶点,第二个Integer是一条边的结束顶点,第三个Integer是这种边在container中出现的次数,为了对于path增删的时候进行统计更新。
public void addpath(Path path) {
for (int i = 1; i < path.size(); i++) {
int befor = path.getNode(i - 1);
int after = path.getNode(i);
if (!nodes.containsKey(befor)) {
nodes.put(befor, new HashMap<>());
}
if (!nodes.containsKey(after)) {
nodes.put(after, new HashMap<>());
}
HashMap<Integer, Integer> t = nodes.get(befor);
t.merge(after, 1, (oldVal, newVal) -> oldVal + newVal);
t = nodes.get(after);
t.merge(befor, 1, (oldVal, newVal) -> oldVal + newVal);
}
bfs();
}
以addpath为例,每一次MyGraph进行addpath操作的时候,我的map也会对于内部进行更新,由于是无向边,所以我会分别把path里的边正反向加入,这次作业中,我也学会了使用HashMap的merge函数,可以精简的写出合并同种KEY的键对,十分推荐。在这次作业里,由于addpath和removepath的出现次数不多(图结构变更指令,总数不超过20条),所以我选择了对于每次这种操作,我在最后会对于整体进行bfs(),也就是算出所有点之间的最短距离,(但是我bfs位置写错了一个地方,导致TLE了)。dijistra这个算法很简单,但是如果要优化计算时间,则需要用到优先队列,特别说明,PriorityQueue队列是基于堆排序的不断更新排序的,但是如果仅仅是修改已经稳定队列的值或内容,而不进行插入或者删除,那么,这个顺序是不会变的。所以我们在进行更新队列距离值的时候,最好先进行上次Pair的删除,然后在加入新的值保证更新队列顺序。
PriorityQueue<Pair<Integer, Integer>> que =
new PriorityQueue<>(Comparator.comparingInt(Pair::getValue));
最后,对于储存最短距离的结构,我才用了邻接表的方式,由于无向图的属性,所以两个点之间的最短距离跟起始点的顺序没有关系,所以我们可以只存储一半的对应最短距离,减少内存的使用,在查找的时候只要判断是否交换起始顺序便可以快速的查找。
第11次作业
类图
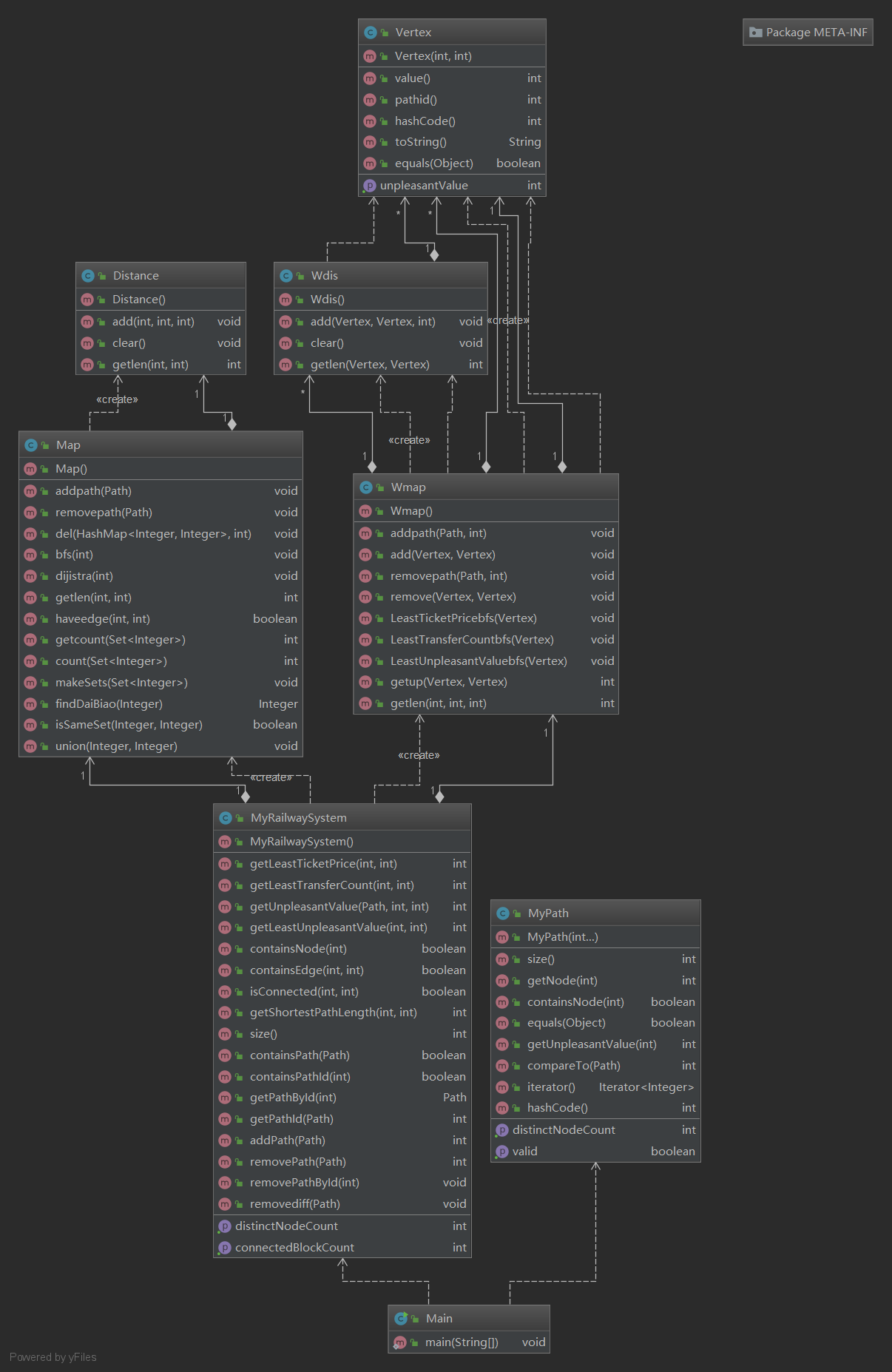
由于第十一次作业对于图的结构有有更加复杂的操作,我对于之前的架构进行了修改,所以我把第10次作业的每次增删path进行整体dijistra改成了只在查找某条路径的时候,对于这条路经序号小的点进行头节点的dijistra,每次把查找的存入BUFFER中以便下次使用,再增山路径的时候对于BUFFER进行清空。
这次作业新增了三个不同的带权图查找,但是都可以通过dijistra这个算法实现,我们只需要考虑的是中间换乘参数的实现和更新的方式。经与同学讨论,最后的思路如下,由于换乘概念的出现,所以每一条边的点都是一个需要区分的点,所以我创建了单独的点类来进行存储。
public class Vertex {
private int nodeid;
private int pathid;
private String name;
public Vertex(int nodeid, int pathid) {
this.nodeid = nodeid;
this.pathid = pathid;
this.name = nodeid + "_" + pathid;
}
@Override
public int hashCode() {
return name.hashCode();
}
}
由于构建了点类,所以可以很好的区分同个序号点,另外就是换乘的思路,就是在每个不同nodeid创建一个上层点,即vertex(nodeid,0),除了同一个path中的点是相互连接的,所有的点都连到上层pathid为0的换乘点,这样在进行dijistra的时候,通过换乘点就相当于在一个站台有个换乘中心,先到达换乘中心,在走向下一个点。对于getLeastTicketPrice、getLeastTransferCount、getLeastUnpleasantValue这三个查询函数,需要构建三个BUFFER进行分别存储之前算过的值(当然也就是存储一半的相对值)。
这个时候就要提到对于JML语言的理解重要性了,如果我们充分理解了每个函数的功能,我们就可以知道,当fromNodeId和toNodeId在一些特殊情况下,不需要调用dijistra这个计算量大的函数,我们只需要进行几行的代码就可以返回正确的结果,这样对于一些特殊情况可以做到快速查询。以getLeastTransferCount为例
if (fromNodeId == toNodeId) {
return 0;
}
if (containsEdge(fromNodeId, toNodeId)) {
return 0;
}
5 BUG及修复
在这个单元,我出现了两次严重的BUG,导致我第9次作业和第10次作业都未能拿到满分,这也是至今为止我成绩最糟糕的一个单元,接下来我分别阐述两次出现bug的原因和解决方法。(第11次作业测试得到满分故下文不会提及)
第9次作业BUG
我在第9次作业的强测最后5个点都出现了CPU_TIME_LIMIT_EXCEED这个cpu运行超时的问题。在通过对于讨论区的仔细研读,我才发现这次作业不能随心的使用数据结构,因为对于getDistinctNodeCount()这个函数,需要对于container里面所有的path进行统计不同点的工作,如果选择ArrayList这样的数据结构,他的查询时间复杂度是O(n),而对于HashMap这样的数据结构,查询的时间复杂度为O(1),对于大量的数据而言,cpu的运行时间会有质的差距。这次作业可惜的是,我考虑到了这个函数的时间复杂度问题,所以自己创建了数据结构存储不同点与path的联系,所以这个函数本身的返回并不需要处理复杂,但是我少考虑了存储数据结构的查询时间复杂度,导致最后强测崩了。在改为HashMap数据结构后,解决了这次作业的BUG。
@Override
public int getDistinctNodeCount() {
return nt.size();
}
第10次作业BUG
在第10次作业结果出来之前,我以为我的程序应该不会有问题,因为他通过了很多的测试,基本的结构的运行时间复杂度在我分析后也是应该不会超出时间限制,但是由于自己的马虎,导致出现了一个致命的BUG,最后这次作业也出现CPU_TIME_LIMIT_EXCEED。下面为错误出现位置的概码。
public void del(HashMap<Integer, Integer> t, int node) {
int num = t.get(node);
if (num == 1) {
t.remove(node);
} else {
t.put(node, num - 1);
}
bfs();
}
这个del函数是由于我的图在进行removepath的时候需要删除正向和反向两条边会调用相似的代码,然后idea显示了duplicate问题,所以我把这个单独实现成一个函数,但是我却忘了把这个函数里的bfs()函数这一行删除,导致如果我在进行removepath的时候,会进行无数次bfs()操作,由于这个致命的BUG,我的强测得到了一个难以言表的分数,也算是给我上了一课,告诉我每次检查代码要仔细再仔细。删除了这个函数的最后一行,程序就不会超限定的CPU运行时间了。
6 单元心得体会
JML规格是对于函数功能的一个总结,如果想要写好JML,则需要对于函数的功能有清晰地理解,首先要做的就是对于函数执行的分类,要把函数正常执行和异常处理分别进行描述,要做到不遗漏任何一种异常处理情况,否则这个规格就不完善;当然对于正常执行也许要把功能写的全面,上次的课上测试就容易把条件遗漏,我们不仅要考虑result中的值满足正确性,还要确定result是否包含全部的结果,所以规格这种严谨性语言需要我们进行验证。对于理解给好的规格,则需要我们仔细研读,由于规格语言不是文字性描述,所以我们不能直观理解这个函数要实现什么东西,但是规格限定死了这个函数的结果状态,所以我们需要一个分号一个分号分开进行阅读,来了解每一个部分所限定的条件,最后作出总结,把规格进行实现,当然我们的数据结构不一定非要按照规格给的写,但是最后的结果一定要与规格吻合,否则无法保证正确性。
BUAA_OO_博客作业三的更多相关文章
- BUAA_OO_博客作业四
BUAA_OO_博客作业四 1 第四单元两次作业的架构设计 1.1 第13次作业 类图 作业要求:通过实现UmlInteraction这个官方提供的接口,来实现自己的UmlInteraction解 ...
- BUAA_OO_博客作业一
BUAA_OO_博客作业一 (一)程序结构分析 1.代码统计 第一次作业 第二次作业 第三次作业 代码复杂度展示第三次作业的 method ev(G) iv(G) v(G) Constant.Cons ...
- BUAA_OO_博客作业二
1.作业设计策略 1.1第一次作业 第一次作业指导书要求是一个单部多线程傻瓜调度(FAFS)电梯的模拟,由于为了可扩展性和模块化设计,第一次作业我采用了三线程,即输入处理线程,调度器线程,电梯线程 ...
- [BUAA OO]第三次博客作业
OO第三次博客作业 1. 规格化设计的发展 我认为,规格化设计主要源自于软件设计的两次危机.第一次是由于大量存在的goto语句,让当时被广泛应用的面向过程式的编程语言臃肿不堪,在逻辑性上与工程规模上鱼 ...
- OO第三次博客作业——规格
OO第三次博客作业——规格 一.调研结果: 规格的历史: 引自博文链接:http://blog.sina.com.cn/s/blog_473d5bba010001x9.html 传统科学的特点是发现世 ...
- [2017BUAA软工]第三次博客作业:案例分析
第三次博客作业:案例分析 1. 调研和评测 1.1 BUG及设计缺陷描述 主要测试博客园在手机端上的使用情况. [BUG 01] 不能后退到上一界面(IOS) 重现步骤:打开博客首页中任意博文,点击博 ...
- OO--第三单元规格化设计 博客作业
OO--第三单元规格化设计 博客作业 前言 第三单元,我们以JML为基础,先后完成了 PathContainer -> Graph -> RailwaySystem 这是一个递进的过程,代 ...
- 个人博客作业Week1
个人博客作业Week1 一.问题 通读<构建之法>我有一下几个问题 PM没有参与代码编如何进行管理. 软件工程师的职业资格考试对我们来说很有必要吗. 当我们为用户开发软件时我们需要了解用户 ...
- java课程设计——博客作业教学数据分析系统(201521123083 戴志斌)
目录 一.团队课程设计博客链接 二.个人负责模块或任务说明 三.自己的代码提交记录截图 四.自己负责模块或任务详细说明 五.课程设计感想 (题外话,终于可以用markdown建目录) 一.团队课程设计 ...
随机推荐
- android 获取屏幕的高度和宽度、获取控件在屏幕中的位置、获取屏幕中控件的高度和宽度
(一)获取屏幕的高度和宽度 有两种方法: 方法1: WindowManager wm = (WindowManager) getContext().getSystemService(Context.W ...
- JavaScript检查是否包含某个字符
转自:http://my.oschina.net/u/1450300/blog/389325 indexOf用法: indexOf 方法返回一个整数值,指出 String 对象内子字符串的开始位置.如 ...
- Flink之Stateful Operators
Implementing Stateful Functions source function的stateful看官网,要加lock Declaring Keyed State at the Runt ...
- E20170804-mk
epic n. 史诗; 叙事诗; 史诗般的作品; estimate vt. 估计,估算; 评价,评论; 估量,估价; Sprint vi. 冲刺,全速短跑; n. 全速短跑; 速度或活动的突然爆发; ...
- Complicated Expressions(表达式转换)
http://poj.org/problem?id=1400 题意:给出一个表达式可能含有多余的括号,去掉多余的括号,输出它的最简形式. 思路:先将表达式转化成后缀式,因为后缀式不含括号,然后再转化成 ...
- codevs1230元素查找(hash)
1230 元素查找 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 钻石 Diamond 题目描述 Description 给出n个正整数,然后有m个询问,每个询问一个 ...
- Django day28 频率组件,解析器
一:频率组件: 1.频率是什么? 节流,访问控制 2. (1)内置的访问频率控制类SimpleRateThrottle (2)写一个类,继承SimpleRateThrottle class MyThr ...
- [Luogu 2678] noip15 子串
[Luogu 2678] noip15 子串 题目描述 有两个仅包含小写英文字母的字符串 A 和 B.现在要从字符串 A 中取出 k 个互不重叠的非空子串,然后把这 k 个子串按照其在字符串 A 中出 ...
- 卸载Mysql connect 6.9.9
我们在卸载MySQL的时候,会发现有一个名为“Connector Net X.X.X”(如:Connector Net 6.9.9)软件总是卸载不成功,下面我们来看看解决方法:1. 在C盘的目录下,有 ...
- [转]Android | Simple SQLite Database Tutorial
本文转自:http://hmkcode.com/android-simple-sqlite-database-tutorial/ Android SQLite database is an integ ...