TensorFlow的序列模型代码解释(RNN、LSTM)---笔记(16)
1、学习单步的RNN:RNNCell、BasicRNNCell、BasicLSTMCell、LSTMCell、GRUCell
(1)RNNCell
如果要学习TensorFlow中的RNN,第一站应该就是去了解“RNNCell”,它是TensorFlow中实现RNN的基本单元,每个RNNCell都有一个call方法,使用方式是:(output, next_state) = call(input, state)。
借助图片来说可能更容易理解。假设我们有一个初始状态h0,还有输入x1,调用call(x1, h0)后就可以得到(output1, h1):
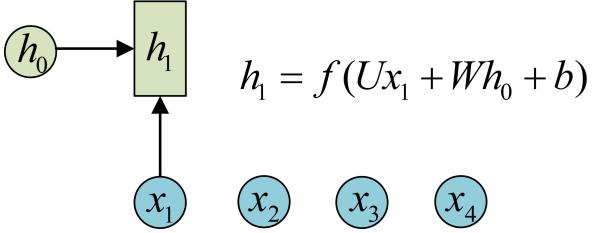
再调用一次call(x2, h1)就可以得到(output2, h2):
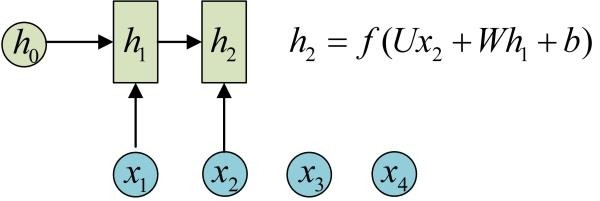
也就是说,每调用一次RNNCell的call方法,就相当于在时间上“推进了一步”,这就是RNNCell的基本功能。
(2)BasicRNNCell和BasicLSTMCell
在代码实现上,RNNCell只是一个抽象类,我们用的时候都是用的它的两个子类BasicRNNCell和BasicLSTMCell。顾名思义,前者是RNN的基础类,后者是LSTM的基础类。这里推荐大家阅读其源码实现(地址:http://t.cn/RNJrfMl),一开始并不需要全部看一遍,只需要看下RNNCell、BasicRNNCell、BasicLSTMCell这三个类的注释部分,应该就可以理解它们的功能了。
除了call方法外,对于RNNCell,还有两个类属性比较重要:
state_size
output_size
前者是隐层的大小,后者是输出的大小。比如我们通常是将一个batch送入模型计算,设输入数据的形状为(batch_size, input_size),那么计算时得到的隐层状态就是(batch_size, state_size),输出就是(batch_size, output_size)。
(3)LSTMCell:
这个类有实现clipping,projection layer,peep-hole等一些lstm的高级变种,BasicLSTMCell仅作为一个基本的basicline结构存在,如果要使用这些高级variant要用LSTMCell这个类。
(4)例子:
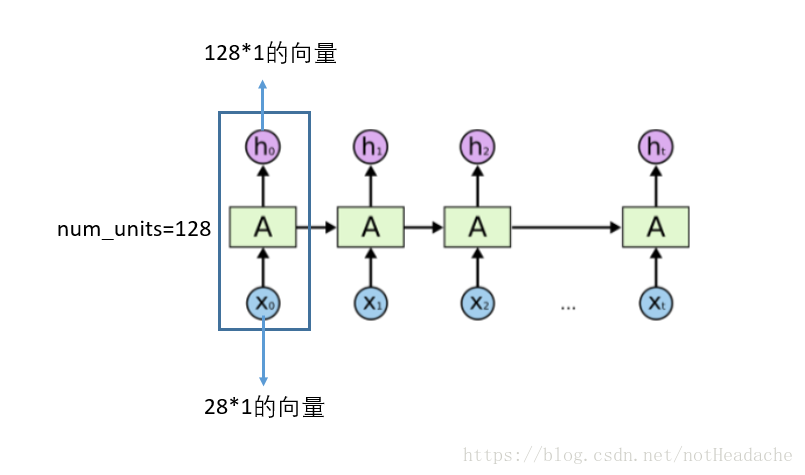
tf.contrib.rnn.BasicLSTMCell:单步的LSTM【LSTMCell】就是下图蓝色框框中的一个。多次调用该函数实现RNNcell就可以实现了时间序列,以下函数dynamic_rnn可以实现循环调用。
BasicLSTMCell(num_units,forget_bias=1.0,state_is_tuple=True,activation=None,reuse=None)
- state_is_tuple 官方建议设置为True。每个lstm cell在t时刻都会产生两个内部状态ct和ht。如果state_is_tuple=True,那么状态ct和ht就是分开记录,放在一个tuple中,如果这个参数没有设定或设置成False,两个状态就按列连接起来,成为[batch, 2n](n是hidden units个数)返回。官方说这种形式马上就要被deprecated了,所有我们在使用LSTM的时候要加上state_is_tuple=True,此时,输入和输出的states为c(cell状态)和h(输出)的二元组。
- forget_bias遗忘门的初始值设为 1,一开始不能遗忘
- num_units:num_units这个参数的大小就是LSTM输出结果的维度。例如num_units=128, 那么LSTM网络最后输出就是一个128维的向量。

https://blog.csdn.net/notHeadache/article/details/81164264 对参数的解释很清楚。
2、initial states初始状态:初始时全部赋值为0状态。
需要有一个self._initial_state来保存我们生成的全0状态,最后直接调用cell的zero_state()方法即可。
self._initial_state = cell.zero_state(batch_size, tf.float32)
state_size是我们在定义cell的时就设置好了的,只是我们的输入input shape=[batch_size, num_steps],我们刚刚定义好的cell会依次接收num_steps个输入然后产生最后的state(n-tuple,n表示堆叠的层数)但是一个batch内有batch_size这样的seq,因此就需要[batch_size,s]来存储整个batch每个seq的状态。
3、DropoutWrapper:
对于rnn的部分不进行dropout,也就是说从t-1时候的状态传递到t时刻进行计算时,这个中间不进行memory的dropout;仅在同一个t时刻中,多层cell之间传递信息的时候进行dropout

上图中,xt−2时刻的输入首先传入第一层cell,这个过程有dropout,但是从t−2时刻的第一层cell传到t−1,t,t+1的第一层cell这个中间都不进行dropout。再从t+1时候的第一层cell向同一时刻内后续的cell传递时,这之间又有dropout了。因此,我们在代码中定义完cell之后,在cell外部包裹上dropout,这个类叫DropoutWrapper,这样我们的cell就有了dropout功能!
例子:
if is_training and config.keep_prob < 1:
lstm_cell = tf.nn.rnn_cell.DropoutWrapper ( cell, input_keep_prob = 1.0,output_keep_prob=config.keep_prob ,seed = None)
参数有input_keep_prob和output_keep_prob,也就是说裹上这个DropoutWrapper之后,如果我希望是input传入这个cell时dropout掉一部分input信息的话,就设置input_keep_prob,那么传入到cell的就是部分input;如果我希望这个cell的output只部分作为下一层cell的input的话,就定义output_keep_prob。不要太方便。
根据Zaremba在paper中的描述,这里应该给cell设置output_keep_prob。
4、学习如何一次执行多步:有四个函数可以用来构建rnn.
(1)tf.nn.dynamic_rnn
dynamic_rnn:基础的RNNCell有一个很明显的问题:对于单个的RNNCell,我们使用它的call函数进行运算时,只是在序列时间上前进了一步。比如使用x1、h0得到h1,通过x2、h1得到h2等。这样的h话,如果我们的序列长度为10,就要调用10次call函数,比较麻烦。对此,TensorFlow提供了一个tf.nn.dynamic_rnn函数,使用该函数就相当于调用了n次call函数。即通过{h0,x1, x2, …., xn}直接得{h1,h2…,hn}。
- cell: RNNCell 实例。
- inputs: RNN输入。如果time_major==False(默认),必须要是形如[batch_size,max_time]的张量, 或者这些元素的嵌套元组。 如果
time_major == True,必须是形如[max_time, batch_size, ...]的张量, 或者这些元素的嵌套元组. 这也可能是一个满足这个属性的(可能嵌套的)张量元组. 前两个维度必须匹配所有输入,否则排名和其他形状组件可能会有所不同. 在这种情况下,每个时间步的单元输入将复制这些元组的结构,除了时间维(从中获取时间)。 在每个时间步的单元格输入将是张量或(可能嵌套的)张量元组,每个张量元素的尺寸为[batch_size,...]。 - initial_state: (可选)RNN的初始状态。 如果cell.state_size是一个整数,则它必须是形如 [batch_size,cell.state_size]的张量。 如果cell.state_size是一个元组,它应该是一个在cell.state_size中具有形状[batch_size,s]的张量元组。
- time_major: 输入和输出张量的形状格式,如果time_major == True,则这些张量必须为[max_time,batch_size,depth]。 如果为false,则这些张量必须为[batch_size,max_time,depth]。 使用time_major = True可以提高效率,因为它避免了RNN计算开始和结束时的转置。 但是,大多数TensorFlow数据都是批处理主数据,所以默认情况下,此功能接受输入并以批处理主要形式发出输出。
- 输出:output:RNN输出张量。如果time_major == False (default),输出张量形如
[batch_size, max_time, cell.output_size]。如果time_major == True, 输出张量形如:[max_time,batch_size,cell.output_size]。
注:如果如果cell.output_size是整数或TensorShape对象的一个(可能是嵌套的)元组,则输出将是与cell.output_size具有相同结构的元组,其包含与具有与cell.output_size中的形状数据相对应的形状的张量。
输出:state:最终状态。 如果cell.state_size是一个int,这将被shaped [batch_size,cell.state_size]。 如果它是一个TensorShape,这将形成[batch_size] + cell.state_size。 如果它是一个(可能是嵌套的)int或TensorShape的元组,它将是一个具有相应形状的元组。 如果单元是LSTMCells状态将是包含每个单元的LSTMStateTuple的元组。
(2)tf.nn.rnn
这个函数和dynamic_rnn的区别就在于,这个需要的inputs是a list of tensor,这个list的长度是num_steps,也就是将每一个时刻的输入切分出来了,tensor的shape=[batch_size, input_size]【这里的input每一个都是word embedding,因此input_size=hidden_units_size】除了输出inputs是list之外,输出稍有差别。输出也是一个长度为T(num_steps)的list,每一个output对应一个t时刻的input(batch_size, hidden_units_size),output shape=[batch_size, hidden_units_size]
(3)state_saving_rnn:
这个方法可以接收一个state saver对象,这是和以上两个方法不同之处,另外其inputs和outputs也都是list of tensors。
(4)tf.nn.static_bidirectional_rnn:
- cell_fw:前向神经元,如BasicRNNCell.
- cell_bw:反向神经元
- input:网络输入,一个长度为T的list,list中的每个Tensor元素shape为[batch_size,input_size]
- initial_state_fw:可选参数。前向RNN的初始RNN,必须是合适类型的Tensor以及shape为[batch_size,cell_fw.state_size]。
- Initial_state_bw:可选参数。同initial_state_fw。
- dtype:初始状态的数据类型。
- sequence_length:一个int32/int64的向量,长度为[batch_size],包含每个序列的实际长度。
- scope:默认为”bidirectional_rnn
返回:
一个(outputs,output_state_fw,output_state_bw)的元组,其中,outputs是一个长度为T的list,list中的每个元素对应每个时间步的输出,它们是深度级联的前向和反向输出。output_state_fw是前向RNN的最终状态,output_state_bw是反向RNN的最终状态。
5、学习如何堆叠RNNCell:MultiRNNCell
很多时候,单层RNN的能力有限,我们需要多层的RNN。将x输入第一层RNN的后得到隐层状态h,这个隐层状态就相当于第二层RNN的输入,第二层RNN的隐层状态又相当于第三层RNN的输入,以此类推。在TensorFlow中,可以使用tf.nn.rnn_cell.MultiRNNCell函数对RNNCell进行堆叠,
cell = tf.nn.rnn_cell.MultiRNNCell([lstm_cell] * config.num_layers, state_is_tuple=True)
先建好MultiRNNCell再初始化:init_state = cell.zero_state(batch_size, tf.float32)
值得学习的地方:
(1) 设置is_training这个标志
这个很有必要,因为training阶段和valid/test阶段参数设置上会有小小的区别,比如test时不进行dropout
(2) 将必要的各类参数都写在config类中独立管理
这个的好处就是各类参数的配置工作和model类解耦了,不需要将大量的参数设置写在model中,那样可读性不仅差,还不容易看清究竟设置了哪些超参数
RNN 小结:
截至目前,TensorFlow的RNN APIs还处于Draft阶段。不过据官方解释,RNN的相关API已经出现在Tutorials里了,大幅度的改动应该是不大可能,现在入手TF的RNN APIs风险应该是不大的。
目前TF的RNN APIs主要集中在tensorflow.models.rnn中的rnn和rnn_cell两个模块。其中,后者定义了一些常用的RNN cells,包括RNN和优化的LSTM、GRU等等;前者则提供了一些helper方法。
创建一个基础的RNN很简单:
from tensorflow.models.rnn import rnn_cell cell = rnn_cell.BasicRNNCell(inputs, state)
创建一个LSTM或者GRU的cell?
cell = rnn_cell.BasicLSTMCell(num_units) #最最基础的,不带peephole。
cell = rnn_cell.LSTMCell(num_units, input_size) #可以设置peephole等属性。
cell = rnn_cell.GRUCell(num_units)
调用呢?
output, state = cell(input, state)
这样自己按timestep调用需要设置variable_scope的reuse属性为True,懒人怎么做,TF也给想好了:
state = cell.zero_state(batch_size, dtype=tf.float32)
outputs, states = rnn.rnn(cell, inputs, initial_state=state)
再懒一点:
outputs, states = rnn.rnn(cell, inputs, dtype=tf.float32)
怕overfit,加个Dropout如何?
cell = rnn_cell.DropoutWrapper(cell, input_keep_prob=0.5, output_keep_prob=0.5)
做个三层的带Dropout的网络?
cell = rnn_cell.DropoutWrapper(cell, output_keep_prob=0.5)
cell = rnn_cell.MultiRNNCell([cell] * 3)
inputs = tf.nn.dropout(inputs, 0.5) #给第一层单独加个Dropout。
一个坑——用rnn.rnn要按照timestep来转换一下输入数据,比如像这样:
inputs = [tf.reshape(t, (input_dim[0], 1)) for t in tf.split(1, input_dim[1], inputs)]
rnn.rnn()的输出也是对应每一个timestep的,如果只关心最后一步的输出,取outputs[-1]即可。
注意一下子返回值的dimension和对应关系,损失函数和其它情况没有大的区别。
目前饱受诟病的是TF本身还不支持Theano中scan()那样可以轻松实现的不定长输入的RNN,不过有人反馈说Theano中不定长训练起来还不如提前给inputs加个padding改成定长的训练快。
摘自 https://www.leiphone.com/news/201709/QJAIUzp0LAgkF45J.html
摘自 https://www.cnblogs.com/mfryf/p/7874784.html
摘自 https://www.cnblogs.com/mfryf/p/7874742.html
TensorFlow的序列模型代码解释(RNN、LSTM)---笔记(16)的更多相关文章
- deeplearning.ai 序列模型 Week 1 RNN(Recurrent Neural Network)
1. Notations 循环序列模型的输入和输出都是时间序列.$x^{(i)<t>}$表示第$i$个输入样本的第$t$个元素,$T_x^{(i)}$表示输入的第$i$个样本的元素个数:$ ...
- Python Tensorflow下的Word2Vec代码解释
前言: 作为一个深度学习的重度狂热者,在学习了各项理论后一直想通过项目练手来学习深度学习的框架以及结构用在实战中的知识.心愿是好的,但机会却不好找.最近刚好有个项目,借此机会练手的过程中,我发现其实各 ...
- 序列模型(3)---LSTM(长短时记忆)
摘自https://www.cnblogs.com/pinard/p/6519110.html 一.RNN回顾 略去上面三层,即o,L,y,则RNN的模型可以简化成如下图的形式: 二.LSTM模型结构 ...
- tensorflow学习之(十一)RNN+LSTM神经网络的构造
#RNN 循环神经网络 import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data tf.se ...
- TensorFlow实现线性回归模型代码
模型构建 1.示例代码linear_regression_model.py #!/usr/bin/python # -*- coding: utf-8 -* import tensorflow as ...
- TensorFlow——LinearRegression简单模型代码
代码函数详解 tf.random.truncated_normal()函数 tf.truncated_normal函数随机生成正态分布的数据,生成的数据是截断的正态分布,截断的标准是2倍的stddev ...
- FaceRank-人脸打分基于 TensorFlow 的 CNN 模型
FaceRank-人脸打分基于 TensorFlow 的 CNN 模型 隐私 因为隐私问题,训练图片集并不提供,稍微可能会放一些卡通图片. 数据集 130张 128*128 张网络图片,图片名: 1- ...
- 深度学习中的序列模型演变及学习笔记(含RNN/LSTM/GRU/Seq2Seq/Attention机制)
[说在前面]本人博客新手一枚,象牙塔的老白,职业场的小白.以下内容仅为个人见解,欢迎批评指正,不喜勿喷![认真看图][认真看图] [补充说明]深度学习中的序列模型已经广泛应用于自然语言处理(例如机器翻 ...
- Coursera Deep Learning笔记 序列模型(一)循环序列模型[RNN GRU LSTM]
参考1 参考2 参考3 1. 为什么选择序列模型 序列模型能够应用在许多领域,例如: 语音识别 音乐发生器 情感分类 DNA序列分析 机器翻译 视频动作识别 命名实体识别 这些序列模型都可以称作使用标 ...
随机推荐
- Java设计模式——外观模式
JAVA 设计模式 外观模式 用途 外观模式 (Facade) 为子系统中的一组接口提供一个一致的界面,此模式定义了一个高层接口,这个接口使得这一子系统更加容易使用. 外观模式是一种结构型模式. 结构
- Android:解决cannot find zipalign的问题
如果当前使用的Android SDK是v20的话,在通过Eclipse或者Intellij IDEA打包Android项目时,会出现一个”cannot find zipalign”的错误. 这个错误的 ...
- js 推断字符串是否包括某字符串
var Cts = "bblText"; if(Cts.indexOf("Text") > 0 ) { alert('Cts中包括Text字符串'); } ...
- ZOJ Monthly, November 2012
A.ZOJ 3666 Alice and Bob 组合博弈,SG函数应用 #include<vector> #include<cstdio> #include<cstri ...
- ZOJ1041 Transmitters
Transmitters Time Limit: 2 Seconds Memory Limit: 65536 KB In a wireless network with multiple t ...
- NSDate时间类/NSDateFormatter日期格式类
#import <Foundation/Foundation.h> int main(int argc, const char * argv[]) { // NSDate 时间类 继承自N ...
- iOS:在UITextField中加入图标
//最左側加图片是下面代码 右側相似 UIImageView *imgView = [[UIImageView alloc] initWithImage:[UIImage imageNamed:@&q ...
- 微信小程序初探(二、分页数据请求)
大家好 波哥小猿又来啦[斜眼笑],昨天咱们讲了微信小程序简单数据请求,有没有照着教程实现请求的同学们啦 实现的同学举个爪[笑脸].哈哈,好了不扯犊子啦,我相信有的同学已经实现了简单的数据请求,没有实现 ...
- css 浮动问题详解
浮动(float),一个我们即爱又恨的属性.爱,因为通过浮动,我们能很方便地布局: 恨,浮动之后遗留下来太多的问题需要解决,特别是IE6-7(以下无特殊说明均指 windows 平台的 IE浏览器). ...
- 原生JS---1
js的历史 在上个世纪的1995年,当时的网景公司正凭借其Navigator浏览器成为Web时代开启时最著名的第一代互联网公司. 由于网景公司希望能在静态HTML页面上添加一些动态效果,于是叫Bren ...