Spark Streaming 整合 Kafka
一:通过设置检查点,实现单词计数的累加功能
object StatefulKafkaWCnt {
/**
* 第一个参数:聚合的key,就是单词
* 第二个参数:当前批次产生批次该单词在每一个分区出现的次数
* 第三个参数:初始值或累加的中间结果
*/
val updateFunc = (iter: Iterator[(String, Seq[Int], Option[Int])]) => {
//iter.map(t => (t._1, t._2.sum + t._3.getOrElse(0)))
iter.map{ case(x, y, z) => (x, y.sum + z.getOrElse(0))}
}
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("StatefulKafkaWordCount").setMaster("local[*]")
//Seconds(5)表示5秒处理一个批次 注意Seconds jar包的引用,是spark中的
val ssc = new StreamingContext(conf, Seconds(5))
//如果要使用课更新历史数据(累加),那么就要把终结结果保存起来
//如果resource中没有Hadoop的配置文件信息,则这是一个本地目录,
ssc.checkpoint("./dt")
//zk服务器列表
val zkQuorum = "node-1:2181,node-2:2181,node-3:2181"
val groupId = "g100"
val topic = Map[String, Int]("topic1" -> 1)
//创建DStream,需要KafkaDStream
val data: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc, zkQuorum, groupId, topic)
//对数据进行处理
//Kafak的ReceiverInputDStream[(String, String)]里面装的是一个元组(key是写入的key,value是实际写入的内容)
val lines: DStream[String] = data.map(_._2)
//对DSteam进行操作,你操作这个抽象(代理,描述),就像操作一个本地的集合一样
//切分压平
val words: DStream[String] = lines.flatMap(_.split(" "))
//单词和一组合在一起
val wordAndOne: DStream[(String, Int)] = words.map((_, 1))
//聚合
val reduced: DStream[(String, Int)] = wordAndOne.updateStateByKey(updateFunc, new HashPartitioner(ssc.sparkContext.defaultParallelism), true)
//打印结果(Action)
reduced.print()
//启动sparkstreaming程序
ssc.start()
//等待 退出
ssc.awaitTermination()
}
}
缺点:
当生产者kafka退出,再登录时,消费者无法读取以前的数据
二:Diect Approach 直连方式
将RDD的分区,直接连接到kafka的分区上,使用kafka底层API,效率高,但需要自己维护偏移量
实现方式一:
object KafkaDirectWordCount {
def main(args: Array[String]): Unit = {
//指定组名
val group = "g001"
//创建SparkConf
val conf = new SparkConf().setAppName("KafkaDirectWordCount").setMaster("local[2]")
//创建SparkStreaming,并设置间隔时间
val ssc = new StreamingContext(conf, Duration(5000))
//指定消费的 topic 名字
val topic = "wwcc"
//指定kafka的broker地址(sparkStream的Task直连到kafka的分区上,用更加底层的API消费,效率更高)
val brokerList = "node-4:9092,node-5:9092,node-6:9092"
//指定zk的地址,后期更新消费的偏移量时使用(以后可以使用Redis、MySQL来记录偏移量)
val zkQuorum = "node-1:2181,node-2:2181,node-3:2181"
//创建 stream 时使用的 topic 名字集合,SparkStreaming可同时消费多个topic
val topics: Set[String] = Set(topic)
//创建一个 ZKGroupTopicDirs 对象,其实是指定往zk中写入数据的目录,用于保存偏移量
val topicDirs = new ZKGroupTopicDirs(group, topic)
//获取 zookeeper 中的路径 "/g001/offsets/wordcount/"
val zkTopicPath = s"${topicDirs.consumerOffsetDir}"
//准备kafka的参数
val kafkaParams = Map(
"metadata.broker.list" -> brokerList,
"group.id" -> group,
//从头开始读取数据
"auto.offset.reset" -> kafka.api.OffsetRequest.SmallestTimeString
)
//zookeeper 的host 和 ip,创建一个 client,用于跟新偏移量量的
//是zookeeper的客户端,可以从zk中读取偏移量数据,并更新偏移量
val zkClient = new ZkClient(zkQuorum)
//查询该路径下是否字节点(默认有字节点为我们自己保存不同 partition 时生成的)
// /g001/offsets/wordcount/0/10001"
// /g001/offsets/wordcount/1/30001"
// /g001/offsets/wordcount/2/10001"
//zkTopicPath -> /g001/offsets/wordcount/
val children = zkClient.countChildren(zkTopicPath)
var kafkaStream: InputDStream[(String, String)] = null
//如果 zookeeper 中有保存 offset,我们会利用这个 offset 作为 kafkaStream 的起始位置
var fromOffsets: Map[TopicAndPartition, Long] = Map()
//如果保存过 offset
if (children > 0) {
for (i <- 0 until children) {
// /g001/offsets/wordcount/0/10001
// /g001/offsets/wordcount/0
val partitionOffset = zkClient.readData[String](s"$zkTopicPath/${i}")
// wordcount/0
val tp = TopicAndPartition(topic, i)
//将不同 partition 对应的 offset 增加到 fromOffsets 中
// wordcount/0 -> 10001
fromOffsets += (tp -> partitionOffset.toLong)
}
//Key: kafka的key values: "hello tom hello jerry"
//这个会将 kafka 的消息进行 transform,最终 kafak 的数据都会变成 (kafka的key, message) 这样的 tuple
val messageHandler = (mmd: MessageAndMetadata[String, String]) => (mmd.key(), mmd.message())
//通过KafkaUtils创建直连的DStream(fromOffsets参数的作用是:按照前面计算好了的偏移量继续消费数据)
//[String, String, StringDecoder, StringDecoder, (String, String)]
// key value key的解码方式 value的解码方式
kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, (String, String)](ssc, kafkaParams, fromOffsets, messageHandler)
} else {
//如果未保存,根据 kafkaParam 的配置使用最新(largest)或者最旧的(smallest) offset
kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
}
//偏移量的范围
var offsetRanges = Array[OffsetRange]()
//从kafka读取的消息,DStream的Transform方法可以将当前批次的RDD获取出来
//该transform方法计算获取到当前批次RDD,然后将RDD的偏移量取出来,然后在将RDD返回到DStream
val transform: DStream[(String, String)] = kafkaStream.transform { rdd =>
//得到该 rdd 对应 kafka 的消息的 offset
//该RDD是一个KafkaRDD,可以获得偏移量的范围
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
val messages: DStream[String] = transform.map(_._2)
//依次迭代DStream中的RDD
messages.foreachRDD { rdd =>
//对RDD进行操作,触发Action
rdd.foreachPartition(partition =>
partition.foreach(x => {
println(x)
})
)
for (o <- offsetRanges) {
// /g001/offsets/wordcount/0
val zkPath = s"${topicDirs.consumerOffsetDir}/${o.partition}"
//将该 partition 的 offset 保存到 zookeeper
// /g001/offsets/wordcount/0/20000
ZkUtils.updatePersistentPath(zkClient, zkPath, o.untilOffset.toString)
}
}
ssc.start()
ssc.awaitTermination()
}
}
实现方式二:
object KafkaDirectWordCountV2 {
def main(args: Array[String]): Unit = {
//指定组名
val group = "g001"
//创建SparkConf
val conf = new SparkConf().setAppName("KafkaDirectWordCount").setMaster("local[2]")
//创建SparkStreaming,并设置间隔时间
val ssc = new StreamingContext(conf, Duration(5000))
//指定消费的 topic 名字
val topic = "wwcc"
//指定kafka的broker地址(sparkStream的Task直连到kafka的分区上,用更加底层的API消费,效率更高)
val brokerList = "node-4:9092,node-5:9092,node-6:9092"
//指定zk的地址,后期更新消费的偏移量时使用(以后可以使用Redis、MySQL来记录偏移量)
val zkQuorum = "node-1:2181,node-2:2181,node-3:2181"
//创建 stream 时使用的 topic 名字集合,SparkStreaming可同时消费多个topic
val topics: Set[String] = Set(topic)
//创建一个 ZKGroupTopicDirs 对象,其实是指定往zk中写入数据的目录,用于保存偏移量
val topicDirs = new ZKGroupTopicDirs(group, topic)
//获取 zookeeper 中的路径 "/g001/offsets/wordcount/"
val zkTopicPath = s"${topicDirs.consumerOffsetDir}"
//准备kafka的参数
val kafkaParams = Map(
"metadata.broker.list" -> brokerList,
"group.id" -> group,
//从头开始读取数据
"auto.offset.reset" -> kafka.api.OffsetRequest.SmallestTimeString
)
//zookeeper 的host 和 ip,创建一个 client,用于跟新偏移量量的
//是zookeeper的客户端,可以从zk中读取偏移量数据,并更新偏移量
val zkClient = new ZkClient(zkQuorum)
//查询该路径下是否字节点(默认有字节点为我们自己保存不同 partition 时生成的)
// /g001/offsets/wordcount/0/10001"
// /g001/offsets/wordcount/1/30001"
// /g001/offsets/wordcount/2/10001"
//zkTopicPath -> /g001/offsets/wordcount/
val children = zkClient.countChildren(zkTopicPath)
var kafkaStream: InputDStream[(String, String)] = null
//如果 zookeeper 中有保存 offset,我们会利用这个 offset 作为 kafkaStream 的起始位置
var fromOffsets: Map[TopicAndPartition, Long] = Map()
//如果保存过 offset
if (children > 0) {
for (i <- 0 until children) {
// /g001/offsets/wordcount/0/10001
// /g001/offsets/wordcount/0
val partitionOffset = zkClient.readData[String](s"$zkTopicPath/${i}")
// wordcount/0
val tp = TopicAndPartition(topic, i)
//将不同 partition 对应的 offset 增加到 fromOffsets 中
// wordcount/0 -> 10001
fromOffsets += (tp -> partitionOffset.toLong)
}
//Key: kafka的key values: "hello tom hello jerry"
//这个会将 kafka 的消息进行 transform,最终 kafak 的数据都会变成 (kafka的key, message) 这样的 tuple
val messageHandler = (mmd: MessageAndMetadata[String, String]) => (mmd.key(), mmd.message())
//通过KafkaUtils创建直连的DStream(fromOffsets参数的作用是:按照前面计算好了的偏移量继续消费数据)
//[String, String, StringDecoder, StringDecoder, (String, String)]
// key value key的解码方式 value的解码方式
kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, (String, String)](ssc, kafkaParams, fromOffsets, messageHandler)
} else {
//如果未保存,根据 kafkaParam 的配置使用最新(largest)或者最旧的(smallest) offset
kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
}
//偏移量的范围
var offsetRanges = Array[OffsetRange]()
//直连方式只有在KafkaDStream的RDD中才能获取偏移量,那么就不能到调用DStream的Transformation
//所以只能子在kafkaStream调用foreachRDD,获取RDD的偏移量,然后就是对RDD进行操作了
//依次迭代KafkaDStream中的KafkaRDD
kafkaStream.foreachRDD { kafkaRDD =>
//只有KafkaRDD可以强转成HasOffsetRanges,并获取到偏移量
offsetRanges = kafkaRDD.asInstanceOf[HasOffsetRanges].offsetRanges
val lines: RDD[String] = kafkaRDD.map(_._2)
//对RDD进行操作,触发Action
lines.foreachPartition(partition =>
partition.foreach(x => {
println(x)
})
)
for (o <- offsetRanges) {
// /g001/offsets/wordcount/0
val zkPath = s"${topicDirs.consumerOffsetDir}/${o.partition}"
//将该 partition 的 offset 保存到 zookeeper
// /g001/offsets/wordcount/0/20000
ZkUtils.updatePersistentPath(zkClient, zkPath, o.untilOffset.toString)
}
}
ssc.start()
ssc.awaitTermination()
}
}
三:Receiver 直连方式
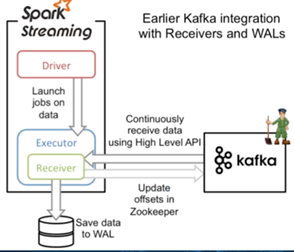
Receiver在固定时长内接收数据,放入内存,使用的是Kafka的高级api,可自己维护偏移量,但是效率低且易丢失
网上找的,亲测可以使用
Spark Streaming 整合 Kafka的更多相关文章
- Spark学习之路(十六)—— Spark Streaming 整合 Kafka
一.版本说明 Spark针对Kafka的不同版本,提供了两套整合方案:spark-streaming-kafka-0-8和spark-streaming-kafka-0-10,其主要区别如下: s ...
- Spark 系列(十六)—— Spark Streaming 整合 Kafka
一.版本说明 Spark 针对 Kafka 的不同版本,提供了两套整合方案:spark-streaming-kafka-0-8 和 spark-streaming-kafka-0-10,其主要区别如下 ...
- spark streaming 整合 kafka(一)
转载:https://www.iteblog.com/archives/1322.html Apache Kafka是一个分布式的消息发布-订阅系统.可以说,任何实时大数据处理工具缺少与Kafka整合 ...
- Spark之 Spark Streaming整合kafka(并演示reduceByKeyAndWindow、updateStateByKey算子使用)
Kafka0.8版本基于receiver接受器去接受kafka topic中的数据(并演示reduceByKeyAndWindow的使用) 依赖 <dependency> <grou ...
- spark streaming 整合kafka(二)
转载:https://www.iteblog.com/archives/1326.html 和基于Receiver接收数据不一样,这种方式定期地从Kafka的topic+partition中查询最新的 ...
- Spark之 Spark Streaming整合kafka(Java实现版本)
pom依赖 <properties> <scala.version>2.11.8</scala.version> <hadoop.version>2.7 ...
- spark streaming整合kafka
版本说明:spark:2.2.0: kafka:0.10.0.0 object StreamingDemo { def main(args: Array[String]): Unit = { Logg ...
- Spark Streaming和Kafka整合保证数据零丢失
当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢失机制.为了体验这个关键的特性,你需要满足以下几个先决条件: 1.输入的数据来自可靠的数据源 ...
- Spark Streaming和Kafka整合是如何保证数据零丢失
转载:https://www.iteblog.com/archives/1591.html 当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢 ...
随机推荐
- linux系统下安装memcached
检查libevent 首先检查系统中是否安装了libevent rpm -qa|grep libevent 如果安装了则查看libevent的安装路径,后续安装时需要用到 rpm -ql libeve ...
- 【剑指Offer】41、和为S的连续正数序列
题目描述: 小明很喜欢数学,有一天他在做数学作业时,要求计算出9~16的和,他马上就写出了正确答案是100.但是他并不满足于此,他在想究竟有多少种连续的正数序列的和为100(至少包括两个数). ...
- 【剑指Offer】29、最小的K个数
题目描述: 输入n个整数,找出其中最小的K个数.例如输入4,5,1,6,2,7,3,8这8个数字,则最小的4个数字是1,2,3,4. 解题思路: 本题最直观的解法就是将输入的n个整数排 ...
- C#第六节课
for循环 using System;using System.Collections.Generic;using System.Linq;using System.Text;using System ...
- Python——Numpy基础知识(一)
一.Numpy的引入 1.标准的Python 中用列表(list)保存一组值,可以当作数组使用.但由于列表的元素可以是任何对象,因此列表中保存的是对象的指针.对于数值运算来说,这种结构显然比较浪费内存 ...
- 佛祖保佑 永无BUG ; 心外无法 法外无心
登录linux命令行后出现的图形 复制图形代码到相应的文件中保存,重新登录即可出现. Usage: For Ubuntu: 12.04: Just copy the content from Budd ...
- Llinux,NFS服务搭建(文件共享)
NFS配置文件权限参数说明(/etc/exports) 1.rw :表示可读写权限. 2.ro :表示只读权限. 3.sync :请求或写入数据时,数据同步写入到NFS Server的硬盘后才返回.( ...
- 论vue项目api相关代码的组织方式
论vue项目api相关代码的组织方式 看了下项目组同事的代码,发现不同项目有不同的组织版本 版本一: ├─apis │ a.api.js │ b.api.js │ b.api.js │ d.api.j ...
- Spring Boot-热部署和Debugger使用(三)
热部署 1.添加热部署pom依赖 <!--热部署插件依赖jar包--> <dependency> <groupId>org.springframework.boot ...
- poj 1274 基础二分最大匹配
#include<stdio.h> #include<string.h> #define N 300 #define inf 0x3fffffff int mark[N],li ...