day2之爬取拉勾网
认证流程
浏览器清空cookies
步骤一
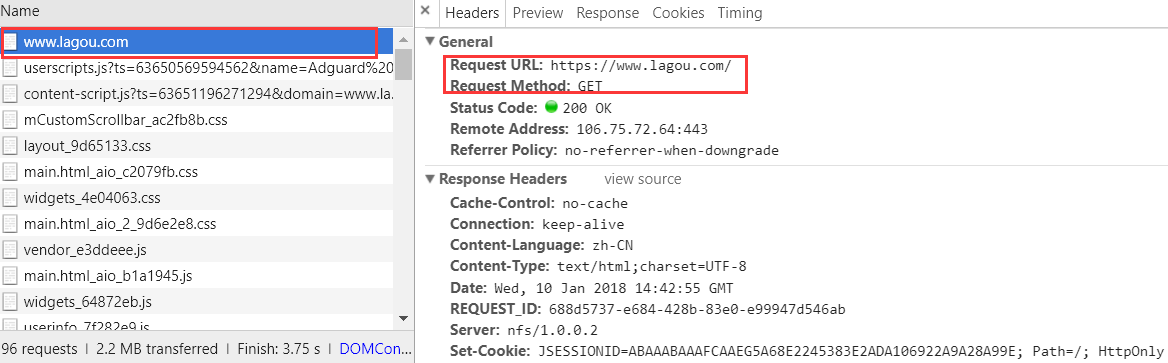
访问拉勾网网站 https://www.lagou.com/
做了些什么:
以get方式请求"https://www.lagou.com/"后,服务器在preview返回的信息包含了 X_Anti_Forge_Token,X_Anti_Forge_Code。
同时返回cookies,因为用requests.session(),所以cookies不考虑。
目标:拿到X_Anti_Forge_Token,X_Anti_Forge_Code。
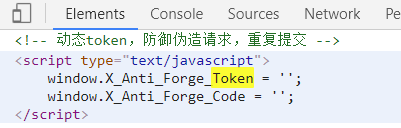
应该对应的是不规则字符串,存疑!
步骤二
登录,先故意输错账户名,密码输对。获取其加密后的数据。拉勾网对密码进行了处理。
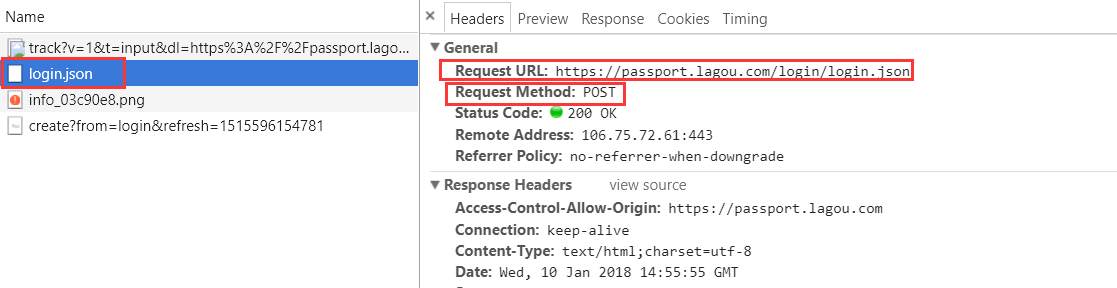
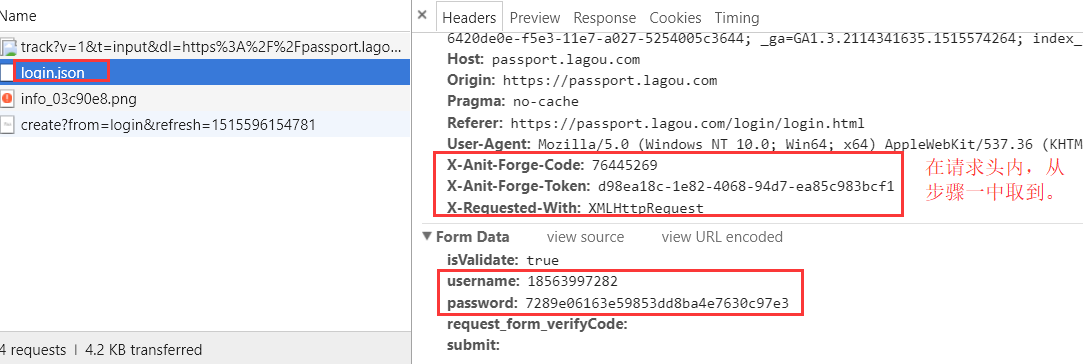
然后,将步骤一拿到的X_Anti_Forge_Token,X_Anti_Forge_Code,和用户名,密码 一起,往" https://passport.lagou.com/login/login.json "以post方式发送。
步骤三
以 get请求 往grant.html发送请求。
作用:获取授权。可能拉勾网比较特殊。
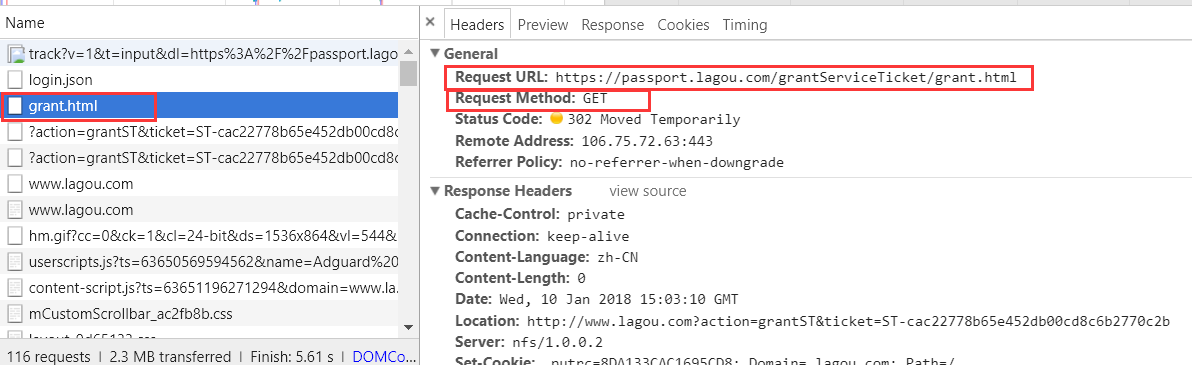
步骤四 验证
访问登录后的某个页面,response.text 拿到数据,判断页面上的某条数据在不在这response.text中。
补充:上述都是用requests.session()做到,所以过程中cookies 让requests模块帮我们处理了。
get,post请求中的User Agent,Referer,具体情况具体填写。
爬取职位信息流程
步骤一
页面进行筛选,url地址栏如果有汉字,真正访问的url会进行编码。条件会以 ?关键字=条件 追加在url末尾。
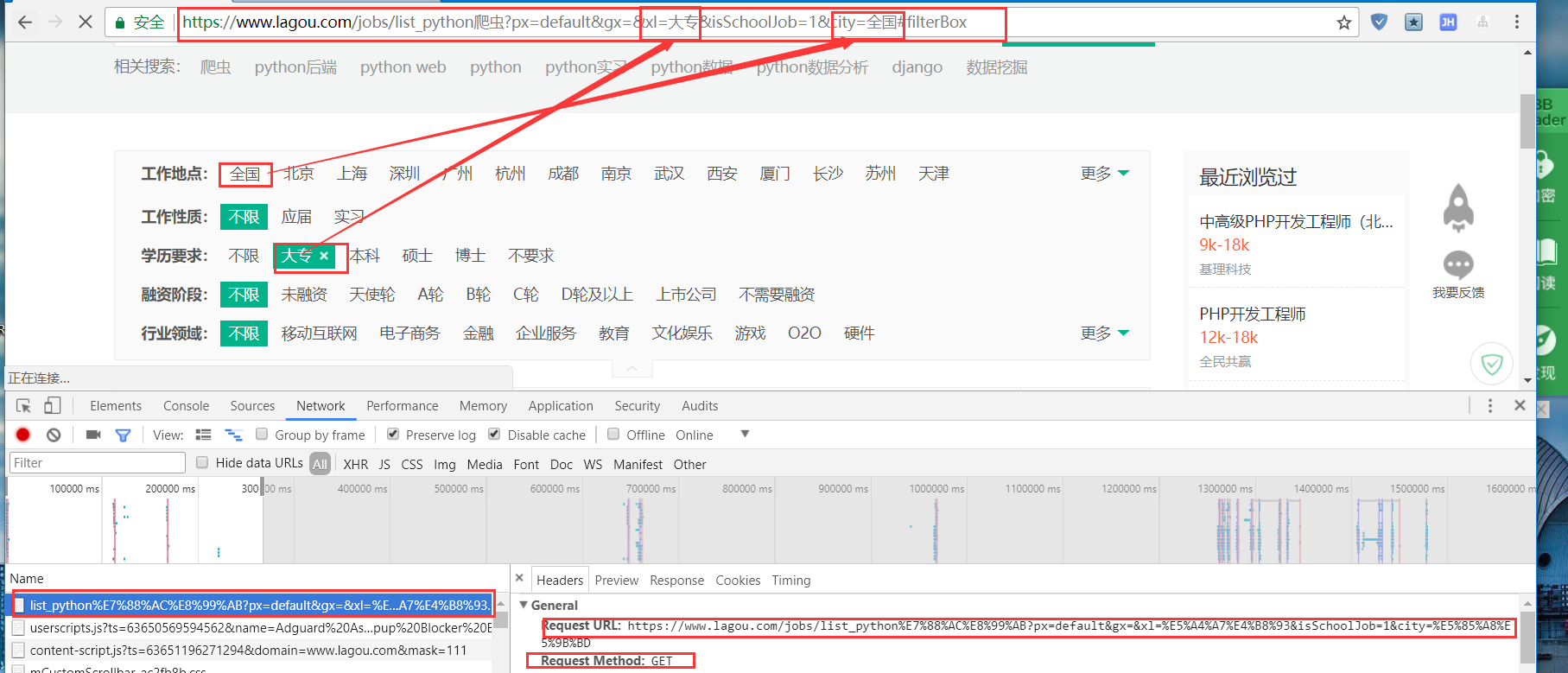
关键来了,然而,在浏览器返回给我们的数据中,和前端页面渲染的并不一致!竟然找不到!
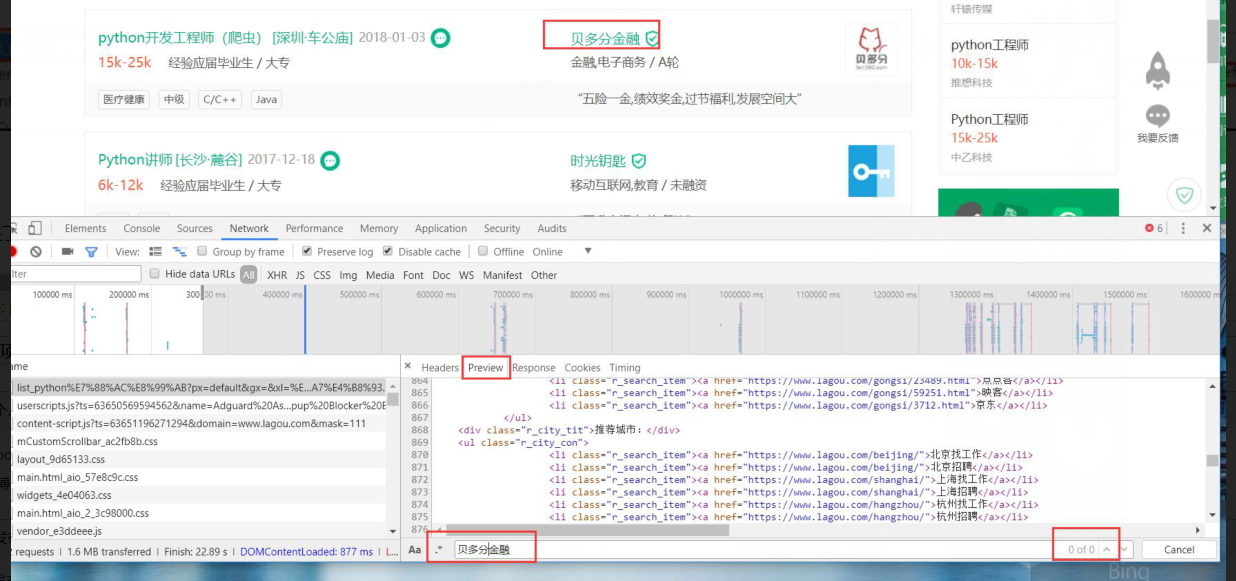
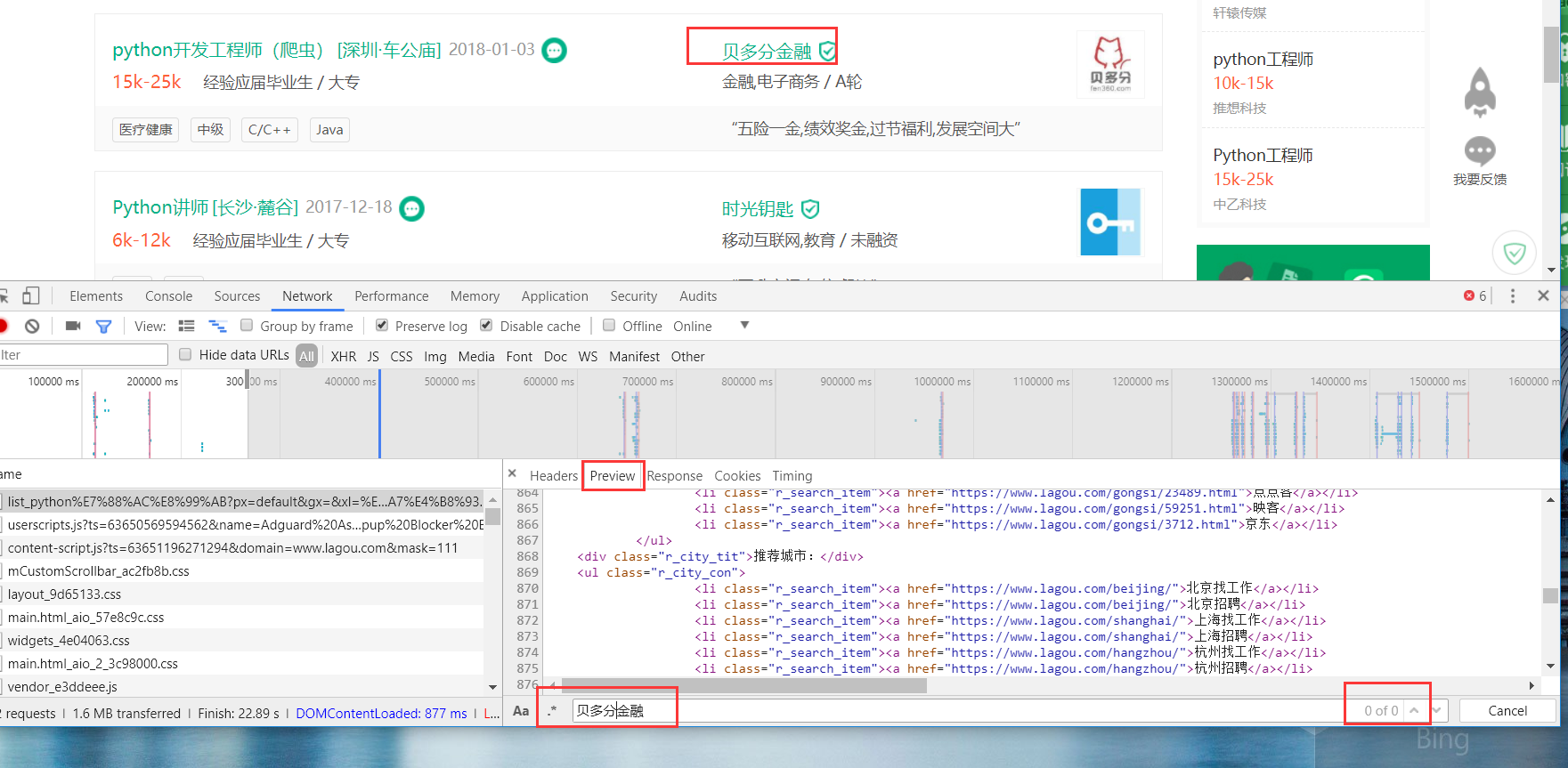
原因何在?
服务器返回来的数据中会有ajax请求,浏览器会自动帮我们完成ajax请求,但是requests模块并不会!
so,在抓包中找到ajax,即XHR。
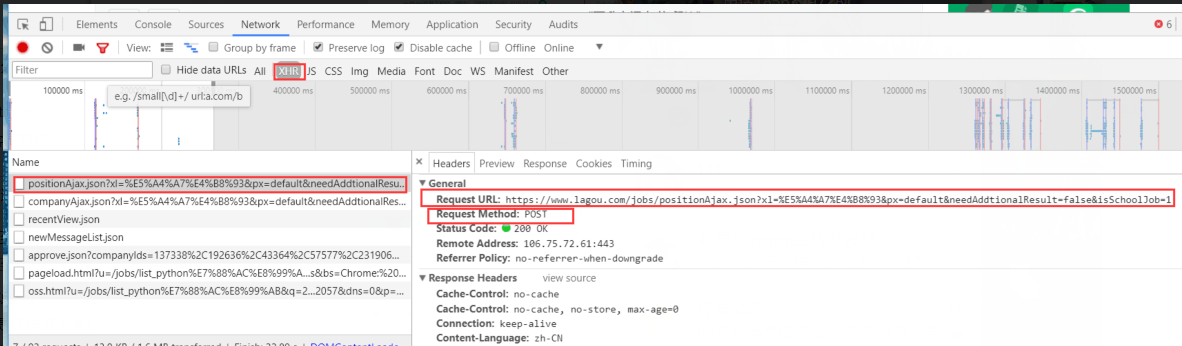
这里才是数据真正存放的地方!
在previes中查找到数据。
数据的格式是字典。
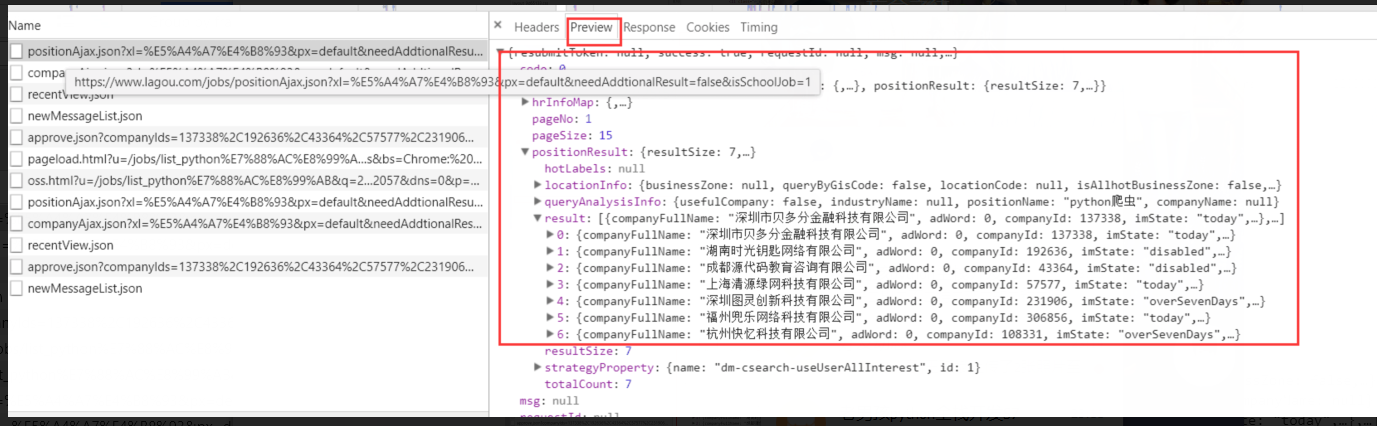
到这里,就可以循环遍历,拿到想要的数据了。
注意,在拉勾网上,positionID,很重要。
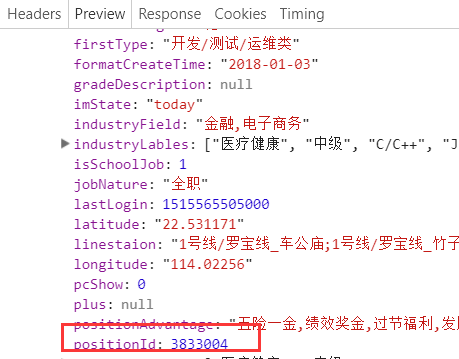

我们可以根据拉勾网,和positionID,拼接出相对应的工作在拉勾网上的站点。
为投简历这个最终目标最准备。
最后一步。投简历。
拿到相关工作的绝对路径后,刷出页面,不要忘了一步,需要拿到 X_Anti_Forge_Token,X_Anti_Forge_Code。
然后,当我们点击"投个简历"的时候,network会刷出一个 deliverResumeBeforce.json。
投简历实际上是往 deliverResumeBeforce.json 发了一个post请求。这就算投递成功。惊不惊喜。但需要data数据,和上一步拿到的X_Anti_Forge_Token,X_Anti_Forge_Code等。
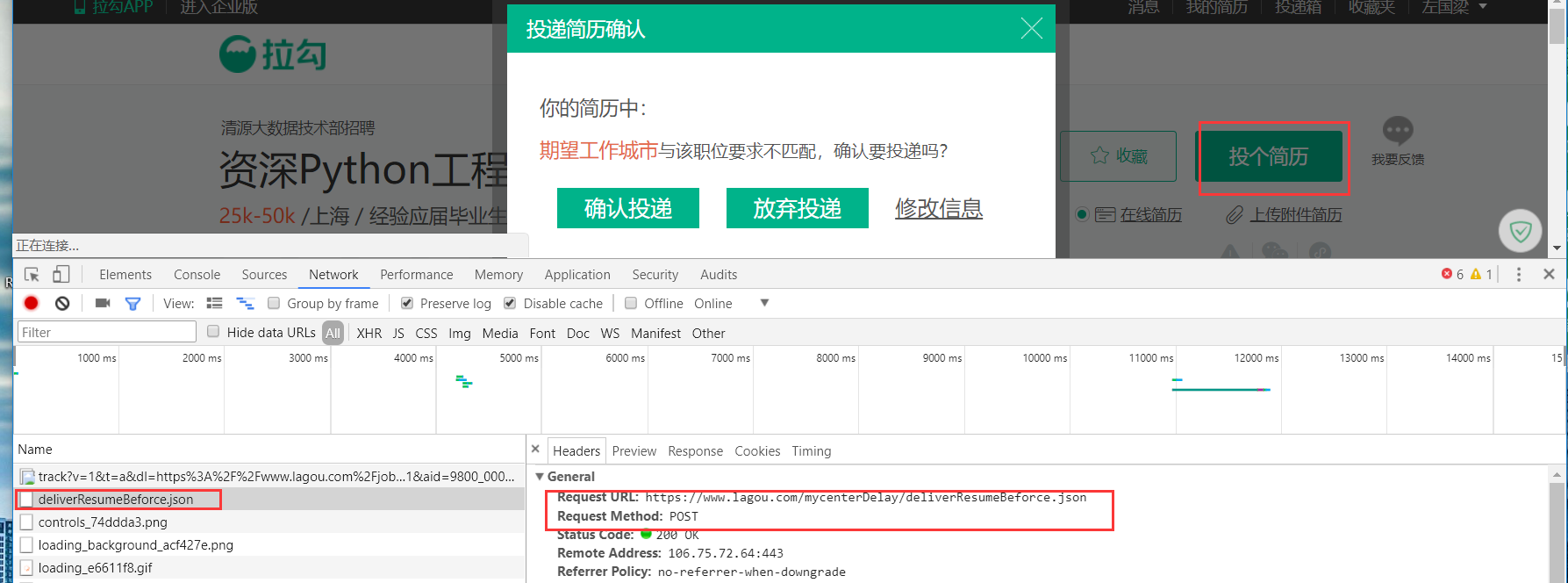
补充:post请求,一般都会有data要发送。
get请求,post请求,在这里不出意外都需要referer,user_agent,不再多言。
感受到了吗,当点击 注册,投个简历,等需要用post方式访问网址,会与前一步get方式访问页面紧密相关。post方式,会用到get方式所返回的某些token,这些token是必不可少的。
回顾讲解时的反思:
grant.html,对其发送get请求,当response 里有location,requests模块自动跳转,不用管了。
后台会发的页面会包含ajax请求,requests不会识别。下载的页面并不含有想要的结果,那就有可能含有ajax请求。应该开心,因为会更方便。
用response.json()直接拿到字典格式的数据。套了好几层的字典。
so,去找浏览器的抓包,看抓到是ajax请求的包,XHR便是。
在这种情况下,请求的url是...Ajax.json,而不是地址栏中的list_python?city=北京...
关键是这个Ajax.json是怎么来的呢?
在我们原以为刷新list_python?...的情况下,response.text含有前端的所有信息,其实并不然。
在浏览器看到的,和response.text并不一样。so,我们考虑到 浏览器用ajax将一部分数据渲染出来。于是,去找ajax请求数据的网址,那里有我们
需要的网址数据。
附上原始代码,并不完全一样。
import requests
import re # 1、============================================认证流程
session = requests.session()
# 第一步:
# 请求的URL:https://passport.lagou.com/login/login.html,
# 请求的方法GET,
# 请求头只包含User-agent r1 = session.get('https://passport.lagou.com/login/login.html',
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
},
) X_Anti_Forge_Token = re.findall("X_Anti_Forge_Token = '(.*?)'", r1.text, re.S)[0]
X_Anti_Forge_Code = re.findall("X_Anti_Forge_Code = '(.*?)'", r1.text, re.S)[0]
# print(X_Anti_Forge_Code)
# print(X_Anti_Forge_Token) # 第二步:
# 1、请求的URL:https://passport.lagou.com/login/login.json,
# 2、请求方法POST,
# 3、请求头:
# Referer:https://passport.lagou.com/login/login.html
# User-Agent:
# X-Anit-Forge-Code
# X-Anit-Forge-Token
# X-Requested-With
# 4、请求体:
# isValidate:true
# username:1111111111
# password:70621c64832c4d4d66a47be6150b4a8e #代表明文密码alex3714
session.post('https://passport.lagou.com/login/login.json',
headers={
'Referer': 'https://passport.lagou.com/login/login.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
'X-Anit-Forge-Code': X_Anti_Forge_Code,
'X-Anit-Forge-Token': X_Anti_Forge_Token,
'X-Requested-With': 'XMLHttpRequest'
},
data={
'isValidate': True,
'username': '18611453110',
'password': '70621c64832c4d4d66a47be6150b4a8e'
}
) # 第三:
# 1、请求的URL:https://passport.lagou.com/grantServiceTicket/grant.html,
# 2、请求方法GET,
# 3、请求头:
# Referer:https://passport.lagou.com/login/login.html
# User-Agent: session.get('https://passport.lagou.com/grantServiceTicket/grant.html',
headers={
'Referer': 'https://passport.lagou.com/login/login.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
}
) # 验证
response = session.get('https://www.lagou.com/resume/myresume.html',
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
}
) # print('18611453110' in response.text) # 2、============================================爬取职位信息
# 1、请求的url:https://www.lagou.com/jobs/positionAjax.json
# 2、请求的方式:POST
# 请求参数:
# gj:3年及以下
# xl:不要求
# jd:不需要融资
# hy:移动互联网
# px:default
# yx:15k-25k
# city:全国
# 3、请求头:
# User-Agent
# Referer:https://www.lagou.com/jobs/list_%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD
# X-Anit-Forge-Code:0
# X-Anit-Forge-Token:None
# X-Requested-With:XMLHttpRequest # 4、请求体:
# first:true
# pn:1
# kd:python数据分析 from urllib.parse import urlencode params = {'kw': 'python数据分析'}
res = urlencode(params).split('=')[-1]
url = 'https://www.lagou.com/jobs/list_' + res
# print(url) response = session.post('https://www.lagou.com/jobs/positionAjax.json',
params={
# 'gj': '3年及以下',
# 'xl': '不要求',
# 'jd': '不需要融资',
# 'hy': '移动互联网',
'px': 'default',
'yx': '15k-25k',
'city': '北京',
'district': '海淀区', },
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
'Referer': url, }) # print(response.status_code)
result = response.json()['content']['positionResult']['result']
for comanpy_info in result:
fullname = comanpy_info['companyFullName']
emp_num = comanpy_info['companySize']
salary = comanpy_info['salary']
workyear = comanpy_info['workYear']
positionName = comanpy_info['positionName']
positionId = comanpy_info['positionId']
detail_url = 'https://www.lagou.com/jobs/%s.html' % (positionId) print(detail_url)
print(fullname)
print(emp_num)
print(salary)
print(workyear)
print(positionName)
print(positionId)
print() # 3、============================================爬取职位信息
# 第一步:请求详情页:
# 1、请求的detail_url:https://www.lagou.com/jobs/3984845.html
# 2、请求的方式:GET
# 3、请求头:
# User-Agent
r1 = session.get(detail_url,
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
}
) X_Anti_Forge_Token = re.findall("X_Anti_Forge_Token = '(.*?)'", r1.text, re.S)[0]
X_Anti_Forge_Code = re.findall("X_Anti_Forge_Code = '(.*?)'", r1.text, re.S)[0] # 第二步:投递简历
# 1、请求的url:https://www.lagou.com/mycenterDelay/deliverResumeBeforce.json
# 2、请求的方式:POST
# 3、请求头:
# User-Agent
# Referer:detail_url
# X-Anit-Forge-Code:31832262
# X-Anit-Forge-Token:9ee8b4bc-7107-49a0-a205-cedd7e77c2d7
# X-Requested-With:XMLHttpRequest # 4、请求体:
# 'positionId':3984845
# 'type':1
# 'force':True session.post('https://www.lagou.com/mycenterDelay/deliverResumeBeforce.json',
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
'Referer': detail_url,
'X-Anit-Forge-Code': X_Anti_Forge_Code,
'X-Anit-Forge-Token': X_Anti_Forge_Token,
'X-Requested-With': 'XMLHttpRequest'
},
data={
'positionId': positionId,
'type': 1,
'force': True
} ) print('投递成功',detail_url)
day2之爬取拉勾网的更多相关文章
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
- node.js爬虫爬取拉勾网职位信息
简介 用node.js写了一个简单的小爬虫,用来爬取拉勾网上的招聘信息,共爬取了北京.上海.广州.深圳.杭州.西安.成都7个城市的数据,分别以前端.PHP.java.c++.python.Androi ...
- 爬取拉勾网招聘信息并使用xlwt存入Excel
xlwt 1.3.0 xlwt 文档 xlrd 1.1.0 python操作excel之xlrd 1.Python模块介绍 - xlwt ,什么是xlwt? Python语言中,写入Excel文件的扩 ...
- python爬取拉勾网数据并进行数据可视化
爬取拉勾网关于python职位相关的数据信息,并将爬取的数据已csv各式存入文件,然后对csv文件相关字段的数据进行清洗,并对数据可视化展示,包括柱状图展示.直方图展示.词云展示等并根据可视化的数据做 ...
- 兴奋与沮丧并存spider爬取拉勾网
兴奋的开发除了爬取拉勾网的爬虫信息,可是当调试都成功了的那一刻,我被拉钩封IP了. 下面是spider的主要内容 import reimport scrapy from bs4 import Beau ...
- Python爬虫实战(一) 使用urllib库爬取拉勾网数据
本笔记写于2020年2月4日.Python版本为3.7.4,编辑器是VS code 主要参考资料有: B站视频av44518113 Python官方文档 PS:如果笔记中有任何错误,欢迎在评论中指出, ...
- Python3爬虫:(一)爬取拉勾网公司列表
人生苦短,我用Python 爬取原因:了解一下Python工程师在北上广等大中城市的薪资水平与入职前要求. Python3基础知识 requests,pyquery,openpyxl库的使用 爬取前的 ...
- python-scrapy爬虫框架爬取拉勾网招聘信息
本文实例为爬取拉勾网上的python相关的职位信息, 这些信息在职位详情页上, 如职位名, 薪资, 公司名等等. 分析思路 分析查询结果页 在拉勾网搜索框中搜索'python'关键字, 在浏览器地址栏 ...
- python爬取拉勾网职位数据
今天写的这篇文章是关于python爬虫简单的一个使用,选取的爬取对象是著名的招聘网站--拉钩网,由于和大家的职业息息相关,所以爬取拉钩的数据进行分析,对于职业规划和求职时的信息提供有很大的帮助. 完成 ...
随机推荐
- codevs 2776 寻找代表元
时间限制: 1 s 空间限制: 256000 KB 题目等级 : 黄金 Gold 题目描述 Description 广州二中苏元实验学校一共有n个社团,分别用1到n编号.广州二中苏元实验 ...
- ajax报错问题的解决
背景:用ajax与服务器页面进行交互 问题:XMLHttpRequest.status==0并且XMLHttpRequest.readyState==0并且textStatus==error 关于XM ...
- 目后佐道IT教育的品牌故事
关于目后佐道 目后佐道IT教育作为中国IT职业教育领导品牌,致力于HTML5.UI.PHP.Java+大数据.Python+人工智能.Linux.产品经理.测试.运维等课程培训.100%全程面授,平均 ...
- (转)MyBatis框架的学习(七)——MyBatis逆向工程自动生成代码
http://blog.csdn.net/yerenyuan_pku/article/details/71909325 什么是逆向工程 MyBatis的一个主要的特点就是需要程序员自己编写sql,那么 ...
- WPF中的TextBlock处理长字符串
Xaml: <StackPanel> <TextBlock Margin="10" Foreground="Red"> This is ...
- 阿里Java架构师面试高频300题:集合+JVM+Redis+并发+算法+框架等
前言 在过2个月即将进入9月了,然而面对今年的大环境而言,跳槽成功的难度比往年高了很多,很明显的感受就是:对于今年的java开发朋友跳槽面试,无论一面还是二面,都开始考验一个Java程序员的技术功底和 ...
- 用python编写九九乘法表
for i in range(1,10): for j in range(1,10): if j >i: print(end='') else: print(j,'*',i,'=',i*j,en ...
- java面试宝典第三弹
Http和Https的区别 超文本传输协议HTTP协议被用于在Web浏览器和网站服务器之间传递信息,HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之 ...
- luogu P1966 火柴排队 (逆序对)
luogu P1966 火柴排队 题目链接:https://www.luogu.org/problemnew/show/P1966 显然贪心的想,排名一样的数相减是最优的. 证明也很简单. 此处就不证 ...
- 【树论 倍增】51nod1709 复杂度分析
倍增与位运算有很多共性:这题做法有一点像「线段树上二分」和「线段树套二分」的关系. 给出一棵n个点的树(以1号点为根),定义dep[i]为点i到根路径上点的个数.众所周知,树上最近公共祖先问题可以用倍 ...