了解移动用户的隐私期望:一种基于推荐的Crowdsourcing方法
应学习之需,最近一段时间阅读了一篇论文,特写下总结,若有纰漏,还望指出。
目录
- 引言
- 推荐机制
- 实现
- 评估
- 心得
1.1 为什么要了解移动用户的隐私期望
1、移动设备的广泛使用存在一些潜在的隐私威胁和信息泄漏。
2、系统供应商针对这个问题已经提出了相应措施,例如:苹果的iOS系统可以让用户控制应用是否可以访问特定的敏感数据源。Android平台同样也有类似的细粒度权限控制机制。然而,存在自身缺点:不包括所有的用户都具备知识背景能够正确地进行隐私配置。同时是一项乏味且具有挑战性的工作。用户体验不高。
3、没有一个简单的规则可以满足所有对于隐私的要求,有些人可能愿意为更好的服务和体验提供一些信息,而另一些人可能不愿意因为隐私问题而分享敏感数据。为了达到每个用户的最佳平衡,理解他们对隐私的期望,并帮助他们相应地设置隐私许可显得至关重要。这也是之所以不采用后面讲到的安全专家建议的原因。
1.2 什么是Crowdsourcing方法和PriWe系统
此方法基于一些关键的见解,即用户如何决定为某个应用程序授予权限的:
1、这一决定取决于用户的特定隐私偏好或关注(与后面提到的“基于用户”相对应);
2、这一决定与用户对某些应用的期望有关(与后面提到的“基于事项”相对应)。
文章提出的方法首先是在用户对应用的隐私偏好和隐私期望之间进行比较,然后根据这些相似性向用户推荐合适的权限设置。方法背后的基本原理是:那些在某些私人数据和/或隐私期望有类似偏好的用户更有可能在相关的隐私项目中作出类似的决定。追求可用性和隐私之间的平衡。
PriWe架构:首先,PriWe可以帮助用户在自己的智能手机上对隐私设置作出更好的决策。其次,由于智能手机的功能有限,分析Crowdsourcing数据和生成建议的过程应该在服务器上完成。如下图所示: 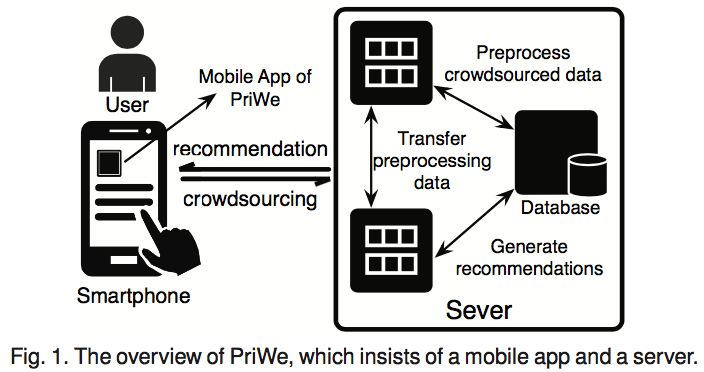
服务器端有两个关键组件:
1、对手机到的数据进行预处理,比如验证和分类;
2、针对不同用户的各种移动应用程序的建议。
2.1 基本思想
传统的推荐系统旨在向一些电子商务市场的客户推荐具有吸引力和感兴趣的商品。因此,每个用户对应一个客户,并且每个隐私设置被映射到一种商品。
Collaborative filtering算法两个主要类别:memory-based and model-based方法。“基于用户”和“基于事项”是memory-based方法的两种关键算法。memory-based算法有以下几种优势:
1、非参数化方法,较少依赖于假定的模型;
2、很容易被推广到更高的维度,容易计算和理解;
3、用户和项目数量上都更加健壮;
4、要求参数数量少,并且计算速度快。
2.2 Item- and user-based collaborative filtering
我们假设有k个用户,每个用户都有m个应用程序。每个应用程序都有n个数据访问权限。定义ri,a,g作为用户i设置的设置的应用程序a的数据权限g。二分变量{0,1},whereri,a,g=0(表示用户不喜欢与任何人分享数据);whereri,a,g=1(表示参与者允许公开信息)
Example 1:两个用户,i和j,都安装了两个应用a,b,每个应用都有两个权限g,h。用户i和j都允许应用a通过设置ri,a,g=1&ri,a,h=1和rj,a,g=1&rj,a,h=1来获取数据权限。在这种情况下,我们认为他们可能有类似的隐私偏好。如果用户i设置ri,a,g=0来组织应用程序b的访问权限g,用户j在这个设置上可能会有相同的选择。
Example 2:应用a’和b’,都安装在由用户i’和用户j’携带的智能手机上。应用a’和b’分别持有权限g’和h’。如果用户i’和j’都拒绝数据访问,即设置ri’,a’,g’=0&ri’,b’,h’=0和rj’,a’,g’=0&rj’,a’,h’=0。我们就认为这两个项目具有相似性。
我们定义su(i,j)作为用户i和j的相似度,基于皮尔森相关系数计算su(i,j)。可能的相似性值在-1和+1之间,值接近+1表示强烈的相似性。PriWe根据用户基本信息将用户为不同的组。
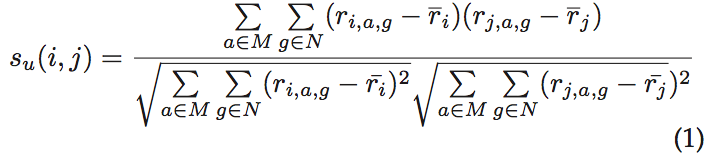
我们通过应用阈值或top-N策略得到相似用户集:
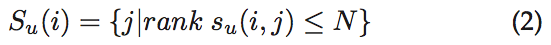
同样,我们定义si(g,h)作为隐私权限g和h的相似度。我们采用了相似度的余弦相似度来计算用户的平均设置行为的差异。

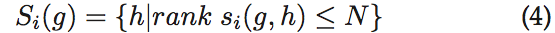

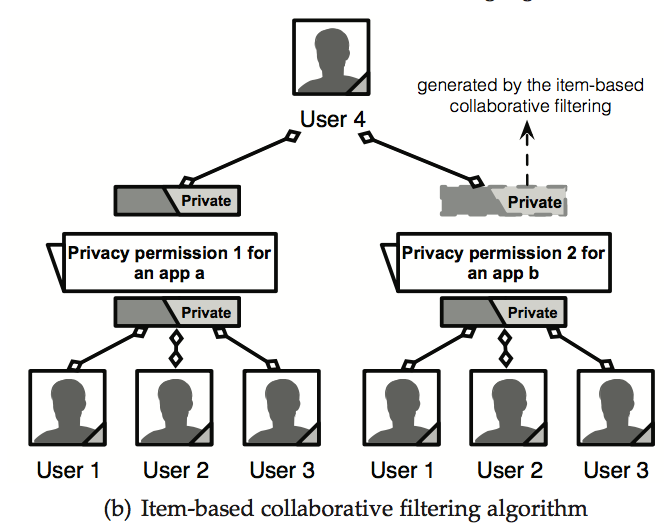
2.3 probabilistic-based similarity fusion框架
基本思想:基于概略为两个相似度su(i,j)、si(g,h)提供不同的权重,相应地结合。
为了降低影响,通过删除平均值将收集的结果标准化:
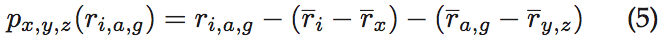
我们定义了一个关于隐私设置的空间样本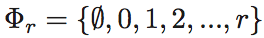 。在我们的案例中实际上有3项,
。在我们的案例中实际上有3项, 。
。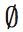 表示未知的隐私设置;0意味着用户关注信息是私有的;1表示用户允许信息的披露。定义
表示未知的隐私设置;0意味着用户关注信息是私有的;1表示用户允许信息的披露。定义 作为用户x在应用y的许可z上作出决定的条件概率。
作为用户x在应用y的许可z上作出决定的条件概率。
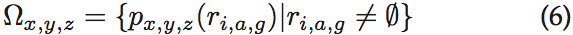
我们可以根据集合中规范化的隐私设置得到条件概率:
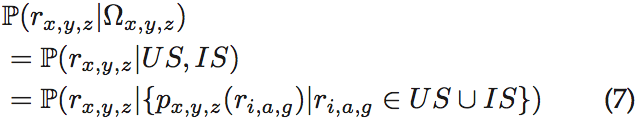
我们引入了两个独立二元指示器I1和I2表示集US和IS的依赖关系。I1=1表示对集US依赖。I2=0表示独立性。
使用欧氏距离产生相似函数:
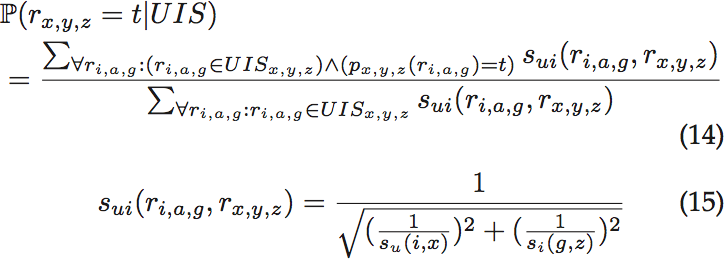
结合上面的条件概率估计得到结果:
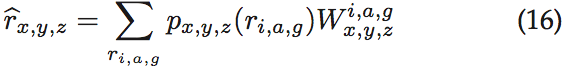
where
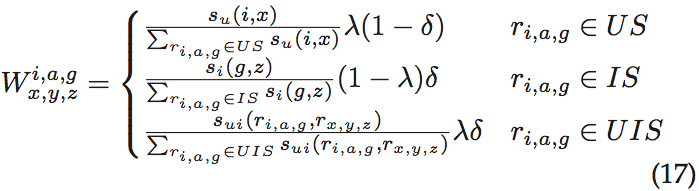
3.1 PriWe App
两个主要目标:1、提供一些用户设置或更改权限设置相关隐私的输入组件;2、接收服务器生成的推荐,在用户确认的基础上能够自动进行推荐设置。用户可以浏览安装的应用及授予的权限。我们总结了11种滥用数据安卓应用的权限并且讨论了它们的风险。

PriWe应用程序需要root权限,或者作为系统级进程运行。不建议用户root他们的智能手机。
3.2 PriWe Server
服务器设计用来分析收集到的数据并且相应的生成推荐。服务器有三个关键的组件,数据预处理、推荐生成、展示和强化。
4 评估
推荐算法的准确行(有效性),Rp表示实验过程中参与者所有的隐私设置,Ri代表了PriWe提供的相应的隐私权限设置的建议。
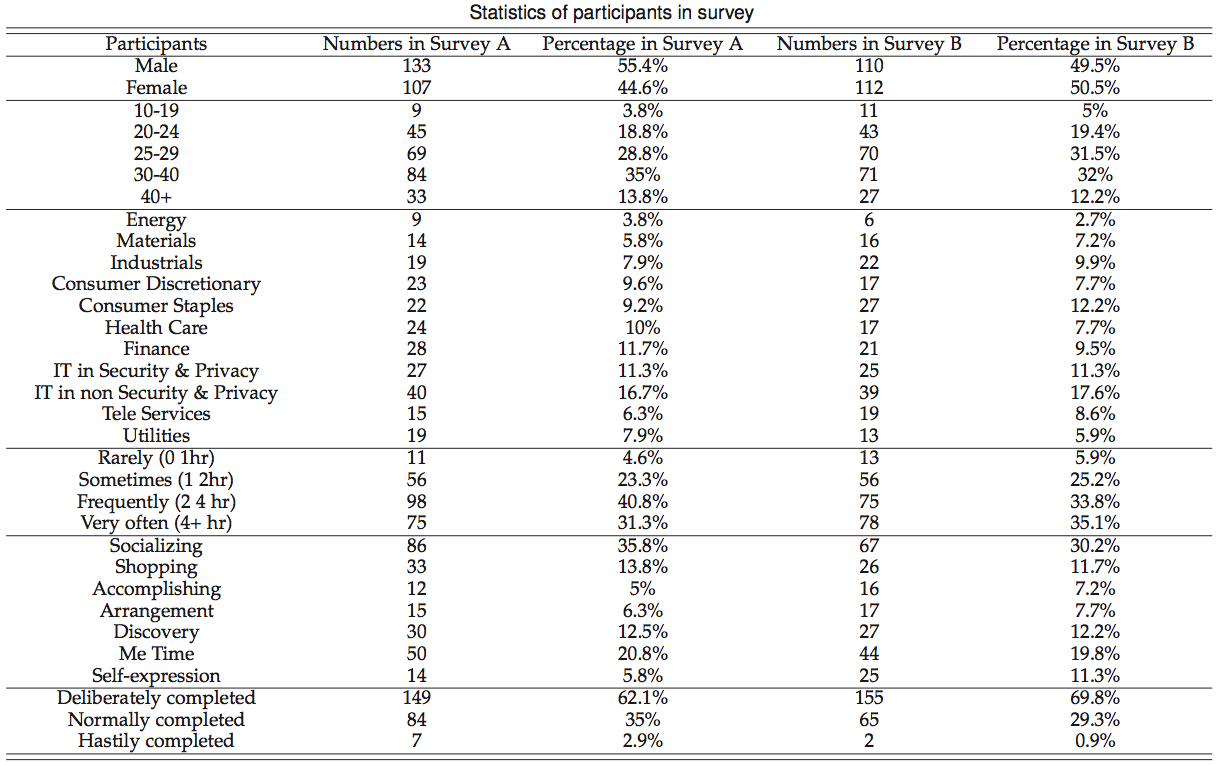
结果表明,基于问卷调查A和B的结果比基于问卷调查A或B的结果更好。这表明当数据集由更多的crowdsourced权限设置组成时,这些建议可以达到更高的准确率。两项调查的结合也能在一定程度上克服数据稀疏问题。
结果显示特征:1、由PriWe提供给男性参与者的准确度比女性要高一些;2、随着参与者年龄的增长,精准度会逐渐提高;3、对于有信息技术背景的参与者来说,对参与者的建议的准确性要高于所有被选中的参与者。
5. 心得
PriWe系统旨在理解用户对隐私的期望,并对其安装的移动应用的隐私设置提出建议,以满足用户的隐私期望,并能够被用户接受,从而帮助他们在智能手机应用程序中减轻隐私泄漏。在这个信息化时代,智能手机中存储着大量个人信息和敏感信息,因此,隐私保护就显得尤为重要,我们日常在使用智能手机的过程中都会遇到个人隐私泄漏的困扰,本篇论文针对这个问题提出来了解决方案。
了解移动用户的隐私期望:一种基于推荐的Crowdsourcing方法的更多相关文章
- 进程?线程?多线程?同步?异步?守护线程?非守护线程(用户线程)?线程的几种状态?多线程中的方法join()?
1.进程?线程?多线程? 进程就是正在运行的程序,他是线程的集合. 线程是正在独立运行的一条执行路径. 多线程是为了提高程序的执行效率.2.同步?异步? 同步: 单线程 异步: 多线程 3.守护线程? ...
- Gitlab用户在组中有五种权限:Guest、Reporter、Developer、Master、Owner
Gitlab权限管理Gitlab用户在组中有五种权限:Guest.Reporter.Developer.Master.Owner Guest:可以创建issue.发表评论,不能读写版本库Reporte ...
- MYSQL添加远程用户或允许远程访问三种方法
添加远程用户admin密码为password GRANT ALL PRIVILEGES ON *.* TO admin@localhost IDENTIFIED BY \'password\' WIT ...
- HOSt ip is not allowed to connect to this MySql server, MYSQL添加远程用户或允许远程访问三种方法
HOSt ip is not allowed to connect to this MySql server 报错:1130-host ... is not allowed to connect to ...
- Gitlab用户在组中有五种权限
Gitlab用户在组中有五种权限:Guest.Reporter.Developer.Master.Owner Guest:可以创建issue.发表评论,不能读写版本库 Reporter:可以克隆代码, ...
- java servlet 几种页面跳转的方法及传值
java servlet 几种页面跳转的方法及传值 java web 页面之间传值有一下这几种方式1.form 表单传递参数2.url地址栏传递参数3.session4.cookie5.appli ...
- tmpfs:一种基于内存的文件系统
tmpfs是一种基于内存的文件系统, tmpfs有时候使用rm(物理内存),有时候使用swap(磁盘一块区域).根据实际情况进行分配. rm:物理内存.real memery的简称? 真实内存就是电脑 ...
- Linux操作系统下三种配置环境变量的方法
现在使用linux的朋友越来越多了,在linux下做开发首先就是需要配置环境变量,下面以配置java环境变量为例介绍三种配置环境变量的方法. 1.修改/etc/profile文件 如果你的计算机仅仅作 ...
- Java常见的几种内存溢出及解决方法
Java常见的几种内存溢出及解决方法[情况一]:java.lang.OutOfMemoryError:Javaheapspace:这种是java堆内存不够,一个原因是真不够(如递归的层数太多等),另一 ...
随机推荐
- hdu 4970 Killing Monsters(数组的巧妙运用) 2014多校训练第9场
pid=4970">Killing Monsters ...
- 关于java及多线程
http://www.w3cschool.cc/java/java-multithreading.html
- IDEA失效的解决办法
1.根据下图进行操作即可解决
- java类载入器——ClassLoader
Java的设计初衷是主要面向嵌入式领域,对于自己定义的一些类,考虑使用依需求载入原则.即在程序使用到时才载入类,节省内存消耗,这时就可以通过类载入器来动态载入. 假设你平时仅仅是做web开发,那应该非 ...
- hdoj-2090-算菜价(水题)
算菜价 Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Submis ...
- Spring如何实现IOC和AOP的,说出实现原理。
用过spring的朋友都知道spring的强大和高深,都觉得深不可测,其实当你真正花些时间读一读源码就知道它的一些技术实现其实是建立在一些最基本的技术之上而已:例如AOP(面向方面编程)的实现是建立在 ...
- win10 tortoiseSVN文件夹及文件图标不显示解决方法
对于SVN来说,因为每个图标都代表着不同的含义,预示着不同的状态,是指示灯的作用,如果没有正确的图标很可能造成数据的丢失等. 输入:win+R,输入regedit,调出注册表信息,按下Ctrl+F,在 ...
- mysql11---主键普通全文索引
.1主键索引添加 当一张表,把某个列设为主键的时候,则该列就是主键索引 create table aaa (id int unsigned primary key auto_increment , n ...
- ubuntu mysql5.7源码安装
本系列的lnmp的大框架基本上是按照http://www.linuxzen.com/lnmphuan-jing-da-jian-wan-quan-shou-ce-si-lnmpda-jian-yuan ...
- android 代码优化:关闭输出日志
android关闭日志 我们在开发时,经常会输出各种日志来debug代码.但是等到应用发布的apk运行时不希望它输出日志. 关闭输出日志Log.v(),Log.i(),Log.w(),Log.v(), ...