记一次有关spark动态资源分配和消息总线的爬坑经历
问题:
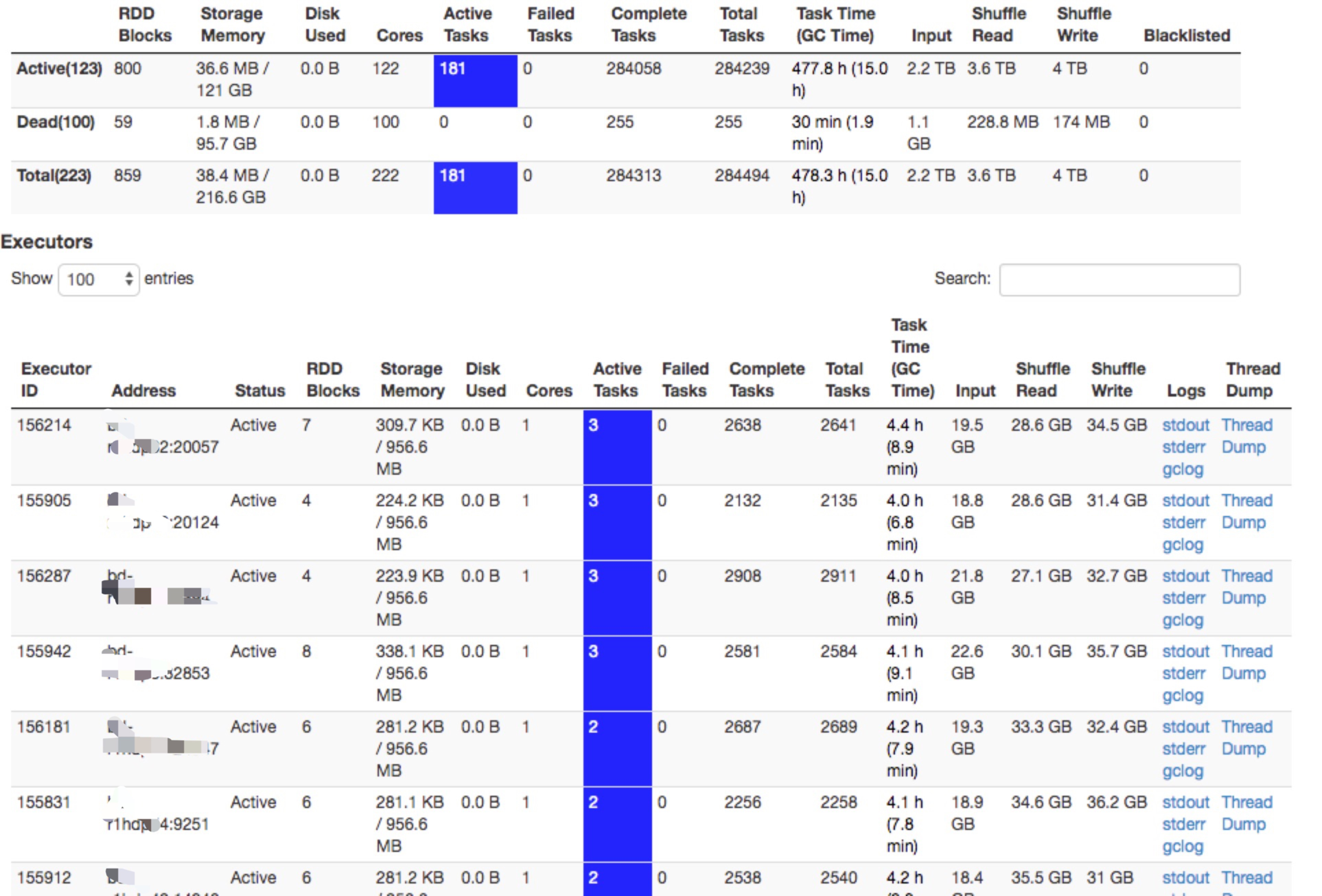
线上的spark thriftserver运行一段时间以后,ui的executor页面上显示大量的active task,但是从job页面看,并没有任务在跑。此外,由于在yarn mode下,默认情况是一个executor只能有一个active task,但是executor页面的active task却可以有多个。而且在没有任务在跑的情况下,动态资源你分配不能生效,spark thriftserver在空闲的情况下资源得不到释放。
问题排查:
1,看到某个executor有大量的active task,首先想到是不是真的是task没有结束。所以首先去对应的executor机器上,查看对应进程的cpu,发现利用率很低。与此同时,打印进程线程栈和正常的executor的线程栈进行对比,发现连行数都是一样的。初步排除了是由于task没有结束,导致task一直在忙的情况。
2,虽然是偶现,但是发现即使某个executor的active task已经很高了(比方说10,大于1),当有新的任务过来时,这个executor仍然可以调度在这个executor上。由此可以确定,在driver内部的dagscheuler和task scheduler中对资源使用情况的相关统计数据是对的。
3,通过1,2的分析,接下来的猜测就是UI显示的数据不对了。2.3以后对ui的模块进行了重新改造,难道是新引入的bug?从官方的jira上搜了一圈,没有发现类似的问题。
4,除了UI上显示的active task不对,spark的动态资源分配也确实没有生效(在没有任务时,executor资源没有释放),说明动态资源分配时获取的系统资源统计也是有误的。于是找了一圈有关动态资源分配的一些jira,还真发现了一些jira(https://issues.apache.org/jira/browse/SPARK-11334)打上补丁,但是UI页面显示的active task肯定和这个issue是没有关系的。
5,到此时,陷入了无解。后来突然想到,无论是UI页面的统计还是动态资源分配,都走的是消息总线机制,之前看源码的时候印象中,消息总线中的消息不是100%不丢的(spark Listener和Metrics机制),所以去日志中搜了一下相关消息,果然发现有消息丢失。

然后翻了一下源码,spark消息这个队列的大小是10000,超过这个值的时候,如果还没有消费掉,就会丢弃消息,然后果断调大到10w,目前已过去三四天了,线上还没有出现这个问题,应该就是这个原因了。
6,进一步思考,为啥会有这个的消息事件呢?spark官方并没有类似的jira,然后想到我们自己跑的spark自行添加了一些event到消息总线,可能是自行添加的event导致的,所以以后自行添加event事件的时候要注意一下这个队列大小的限制。另外,在100%需要对数据进行统计的准备的情况下,使用spark内部的消息总线机制来做异步处理并不是非常的恰当。
记一次有关spark动态资源分配和消息总线的爬坑经历的更多相关文章
- Spark动态资源分配-Dynamic Resource Allocation
微信搜索lxw1234bigdata | 邀请体验:数阅–数据管理.OLAP分析与可视化平台 | 赞助作者:赞助作者 Spark动态资源分配-Dynamic Resource Allocation S ...
- spark动态资源(executor)分配
spark动态资源调整其实也就是说的executor数目支持动态增减,动态增减是根据spark应用的实际负载情况来决定. 开启动态资源调整需要(on yarn情况下) 1.将spark.dynamic ...
- VueRouter爬坑第二篇-动态路由
VueRouter系列的文章示例编写时,项目是使用vue-cli脚手架搭建. 项目搭建的步骤和项目目录专门写了一篇文章:点击这里进行传送 后续VueRouter系列的文章的示例编写均基于该项目环境. ...
- spark on yarn 动态资源分配报错的解决:org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService:spark_shuffle does not exist
组件:cdh5.14.0 spark是自己编译的spark2.1.0-cdh5.14.0 第一步:确认spark-defaults.conf中添加了如下配置: spark.shuffle.servic ...
- 利用动态资源分配优化Spark应用资源利用率
背景 在某地市开展项目的时候,发现数据采集,数据探索,预处理,数据统计,训练预测都需要很多资源,现场资源不够用. 目前该项目的资源3台旧的服务器,每台的资源 内存为128G,cores 为24 (co ...
- Spark如何进行动态资源分配
一.操作场景 对于Spark应用来说,资源是影响Spark应用执行效率的一个重要因素.当一个长期运行的服务,若分配给它多个Executor,可是却没有任何任务分配给它,而此时有其他的应用却资源紧张,这 ...
- spark提交至yarn的的动态资源分配
1.为什么开启动态资源分配 ⽤户提交Spark应⽤到Yarn上时,可以通过spark-submit的num-executors参数显示地指定executor 个数,随后,ApplicationMast ...
- 「Spark从精通到重新入门(二)」Spark中不可不知的动态资源分配
前言 资源是影响 Spark 应用执行效率的一个重要因素.Spark 应用中真正执行 task 的组件是 Executor,可以通过spark.executor.instances 指定 Spark ...
- Spark动态加载外部资源文件
Spark动态加载外部资源文件 1.spark-submit --files 动态加载外部资源文件 之前做一个关于Spark的项目时,因项目中需要读取某个静态资源文件,然后在本地IDEA测试一切皆正常 ...
随机推荐
- 安装sbt
http://www.scala-sbt.org/0.13/docs/zh-cn/Installing-sbt-on-Linux.html [root@hadoop1 target]# curl ht ...
- Serialization and deserialization are bottlenecks in parallel and distributed computing, especially in machine learning applications with large objects and large quantities of data.
Serialization and deserialization are bottlenecks in parallel and distributed computing, especially ...
- (29)java web的hibernate使用-crud的dao
1, 做个简单的util public class HibernateUtils { private static SessionFactory sf; static { //加载主要的配置文件 sf ...
- 关于div li 等标签之间自带间距
可以用float来清除标签之间的间距. ps :ul使用font-size:0 唯一的缺点就是要再次设置LI的font-size
- CSS中的那点事儿(一)--- CSS中的单位2
在上篇博客提到了%.px.em三个单位,其中最复杂的是em,因为要计算当前元素内的font-size,必须知道其父元素的font-size,层层累积,容易出错.现在CSS3中引入了新的单位rem,改变 ...
- Do not throw System.Exception, System.SystemException, System.NullReferenceException, or System.IndexOutOfRangeException intentionally from your own source code
sonarqube的扫描结果提示 https://docs.microsoft.com/en-us/dotnet/csharp/programming-guide/exceptions/creatin ...
- MYSQL进阶学习笔记五:MySQL函数的创建!(视频序号:进阶_13)
知识点六:MySQL函数的创建(13) 内置函数: 自定义函数: 首先查看是否已经开启了创建函数的功能: SHOW VARIABLES LIKE ‘%fun%’; 如果变量的值是OFF,那么需要开启 ...
- CollectionView垂直缩放卡片布局
实现效果 实现思路 从效果图可以看到变化是,越是往中间滚动的item显示最大,越显眼.而越是往前面,或者越是后面的,反而显示越小,这样就形成了视觉差. 实现的思路就是通过重写在可见范围内的所有item ...
- [Selenium] Selenium 疑难杂症
1. jsclick 也不管用 Actions action = new Actions(driver); WebElement theRow = page.getInvisibleElement() ...
- 【CAIOJ 1178】 最长共同前缀长度
[题目链接] 点击打开链接 [算法] EXKMP [代码] #include<bits/stdc++.h> using namespace std; #define MAXL 100001 ...