软件架构自学笔记----分享“去哪儿 Hadoop 集群 Federation 数据拷贝优化”
去哪儿 Hadoop 集群 Federation 数据拷贝优化
背景
去哪儿 Hadoop 集群随着去哪儿网的发展一直在优化改进,基本保证了业务数据存储量和计算量爆发式增长下的存储服务质量。然而,随着集群规模的发展,单组 NameNode 组成的集群也到达了新的瓶颈:因为 NameNode 内存使用和元数据量正相关,在 180GB 堆内存配置下,元数据量红线约为 7 亿,而随着集群规模和业务的发展,即使经过小文件合并与数据压缩,仍然无法阻止元数据量逐渐接近红线。而且在性能方面,随着业务的发展,集群规模的扩大,NameNode RPC 响应时间增大,QPS 逐渐降低。
HDFS Federation 是 Hadoop-0.23.0 中为解决 HDFS 单点限制而提出的 NameNode 水平扩展方案。该方案可以为 HDFS 服务创建多个 NameSpace ,从而提高集群的扩展性和隔离性,分散单个 NameNode 的负载。(在 HDFS 中 NameSpace 是指 NameNode 中负责管理文件系统中的树状目录结构以及文件与数据块的映射关系的一层逻辑结构,在 Federation 方案中,NameNode 之间相互隔离,因此社区也用一个 NameSpace 来指代 Federation 中一组独立的 NameNode 及其元数据。)
在 Federation 过程中,非常重要的一个环节就是数据的拷贝。
原来所有的数据都是从源主节点 NameNode1 下访问,例如 /user/flight,/user/hotel 等。 如果 Federation 后,/user/flight 从 NameNode1 访问,/user/hotel 从 NameNode2 访问,这样就需要将 /user/hotel 目录下所有的数据和元数据拷贝到 NameNode2 的集群中。
fastcopy 简介
如果集群数据比较少,可以直接 distcp 完成。
现在去哪儿网的数据,单个 DataNode 的使用占比中位数已经超过 80%,即,要拷贝出 70% 的数据的话,不考虑时间,磁盘空间也满足不了要求。 如果拆成多次操作,周期和运维成本会高出很多。
所以选择了社区中的 fastcopy 方案, https://issues.apache.org/jira/browse/HDFS-2139 ,FastCopy 是 Facebook 开源的数据拷贝方案。主要逻辑就是,从源 NameNode 读文件信息和 block 对应关系,然后在目标 NameNode 上创建文件,添加 block ,拷贝 block 。 其中拷贝 block 的方式(最终数据块的拷贝)是使用 linux 的硬链拷贝来完成,这样就不会增加存储成本了。
fastcopy 的优点,速度快,不占存储空间。也有缺点,是没有进行文件权限和属主的拷贝,还需要再次修改,这个权属从源 NameNode 也需要读所有的文件,然后写到目标 NameNode 去,这个时间基本是拷贝时间的 1/3 到 1/2 。
fastcopy 与 distcp 测试对比
为了更直观的了解 fastcopy 的性能,我们先测试了 fastcopy 和 distcp 的比较。
测试集群环境: 2 个 NameSpace,50 个 DataNode。
测试结果
元数据量从 100 万到 1 亿,fastcopy 花费时间从 0.68 分钟到 90 分钟,distcp 从 5m 到 830m。
元数据总量与拷贝时间折线图:
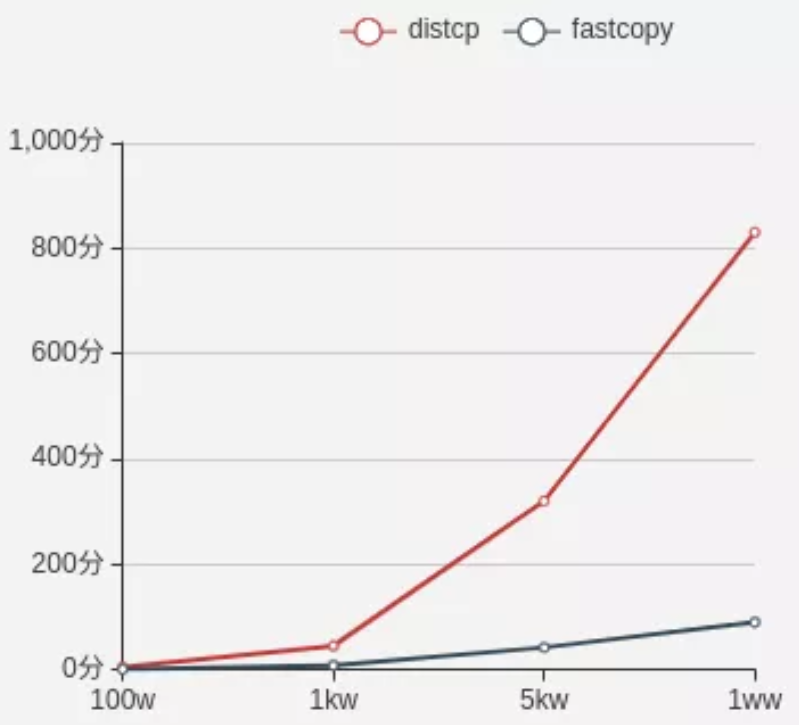
测试分析结论
根据测试结果,生产集群拷贝 5 亿元数据:
distcp 需要花费为 4 天。如果开用 distcp ,公司集群停用 4 天,业务报表统计、业务模型训练等都不可用,这是不可接受的,此方案不通。
fastcopy 需要花费 90*5/60*1.8=13.5 个小时,1.8 为一个系数,表示元数据增大到 7 亿后响应时间增大的程度。fastcopy 拷贝后,还需要对原文件的权限属主进行设置,也需要 6 个小时左右,最终 fastcopy 需要 20 个小时左右,对公司的报表等影响很大。
测试过程中,我们发现 fastcopy 的瓶颈是 active 主节点的并发度。在阅读 fastcopy 源码的过程中,我们发现 fastcopy 对同一个元数据有多次请求。我们准备从这点开始对源码优化。
fastcopy 优化
fastcopy 适用范围较宽,在 Federation 集群中任何一个时间节点都可以使用。
而我们现在面临的是单 NameNode 拆分多个 NameNode 时大量数据迁移时间过长问题。拆分时刻可以停止集群写服务,提前创建 Snapshot ,保证 fsimage 不变,在此前提下我们进行优化。
优化后的 fastcopy 简称 qfastcopy 。
原 fastcopy 流程以及步骤
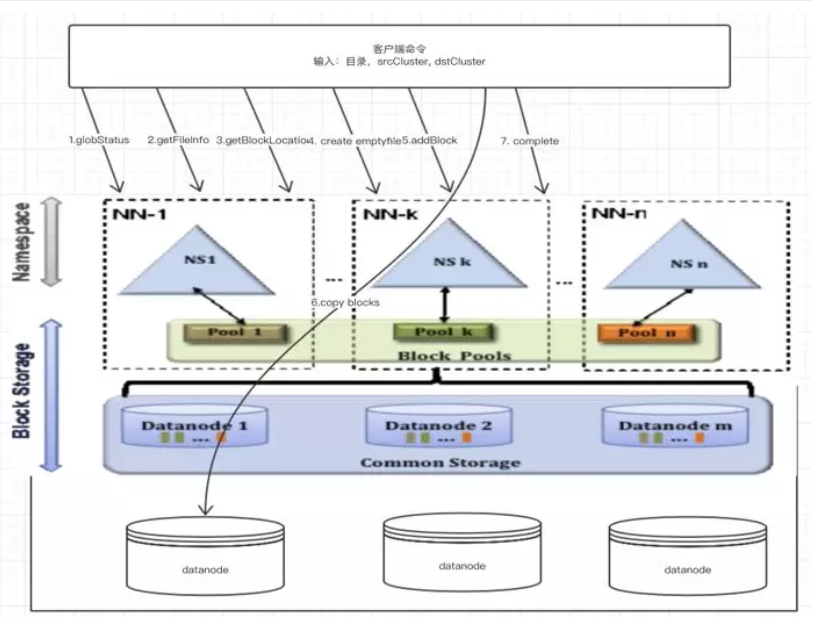

原 fastcopy 步骤所需资源与性能分析

优化方案

qfastcopy
qfastcopy 流程:
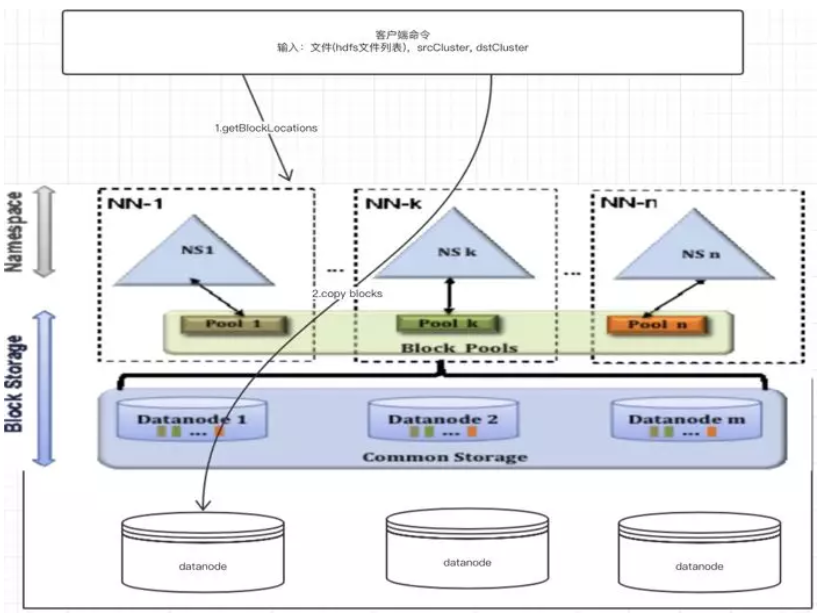
qfastcopy 具体步骤:

qfastcopy 的缺点
使用场景单一,只能在 Federation 过程中 NameNode 拆分时使用,需要提前 copy fsimage 到目标集群。
目标文件与源文件绝对路径相同。
整个流程中集群不能对外提供写操作。
qfastcopy 测试
fastcopy 和 qfastcopy 对比
元数据量与拷贝时间折线图:
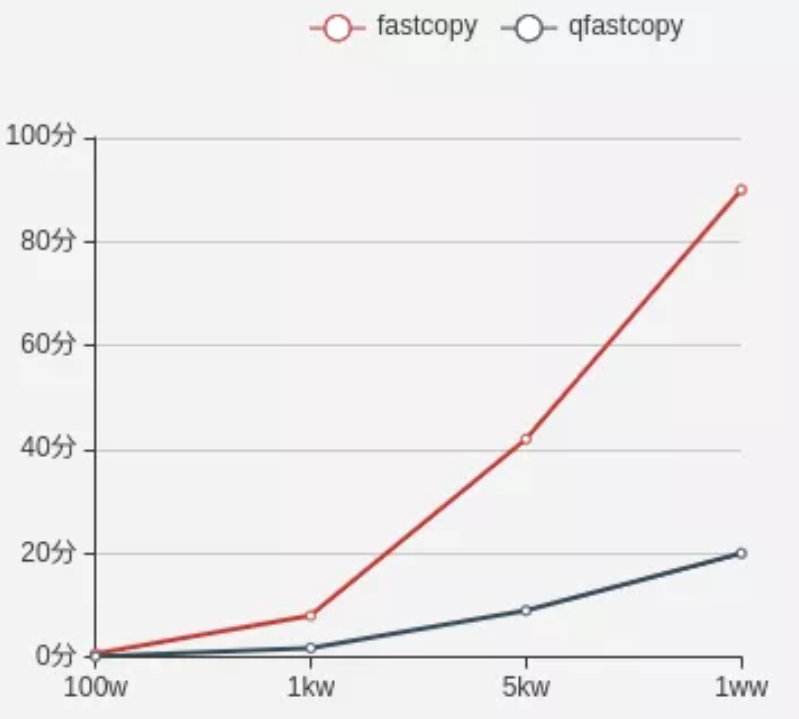
分析与结论
根据测试结果,生产集群拷贝 5 亿元数据,qfastcopy 需要花费 22*5/60*1.8=3.5 小时。
最终,我们将近集群 Federation 的 5 亿元数据拷贝时间从 20 小时优化到了 3.5 小时。
软件架构自学笔记----分享“去哪儿 Hadoop 集群 Federation 数据拷贝优化”的更多相关文章
- 本地日志数据实时接入到hadoop集群的数据接入方案
1. 概述 本手册主要介绍了,一个将传统数据接入到Hadoop集群的数据接入方案和实施方法.供数据接入和集群运维人员参考. 1.1. 整体方案 Flume作为日志收集工具,监控一个文件目录或者一个文 ...
- DistCp 集群之间数据拷贝工具
DistCp(分布式拷贝)是用于大规模集群内部和集群之间拷贝的工具.可以将数据拷贝到另个一集群,也可以将另一个集群的数据拷贝到本集群.
- [hadoop读书笔记] 第九章 构建Hadoop集群
P322 运行datanode和tasktracker的典型机器配置(2010年) 处理器:两个四核2-2.5GHz CPU 内存:16-46GN ECC RAM 磁盘存储器:4*1TB SATA 磁 ...
- (转)hadoop 集群间数据迁移
hadoop集群之间有时候需要将数据进行迁移,如将一些保存的过期文档放置在一个小集群中进行保存. 使用的是社区提供的功能,distcp.用法非常简单: hadoop distcp hdfs://nn1 ...
- Hadoop学习笔记(4)hadoop集群模式安装
具体的过程参见伪分布模式的安装,集群模式的安装和伪分布模式的安装基本一样,只有细微的差别,写在下面: 修改masers和slavers文件: 在hadoop/conf文件夹中的配置文件中有两个文件ma ...
- hadoop 集群中数据块的副本存放策略
HDFS采用一种称为机架感知(rack-aware)的策略来改进数据的可靠性.可用性和网络带宽的利用率.目前实现的副本存放策略只是在这个方向上的第一步.实现这个策略的短期目标是验证它在生产环境下的有效 ...
- [hadoop读书笔记] 第十章 管理Hadoop集群
P375 Hadoop管理工具 dfsadmin - 查询HDFS状态信息,管理HDFS. bin/hadoop dfsadmin -help 查询HDFS基本信息 fsck - 检查HDFS中文件的 ...
- hadoop系列一:hadoop集群安装
转载请在页首明显处注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/6384393.html 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据 ...
- hadoop集群故障排除
故障一:某个datanode节点无法启动 我是以用户名centos安装和搭建了一个测试用的hadoop集群环境,也配置好了有关的权限,所有者.所属组都配成centos:centos [故障现象] 名称 ...
随机推荐
- json转换时区问题-------前端展示时间少8小时--解决方法
在application配置文件中加如下: spring.jackson.time-zone=GMT+8
- (12)GrabCut前景提取
import cv2 import numpy as np import matplotlib.pyplot as plt img = cv2.imread('opencv-python-foregr ...
- spark之scala快速入门
scala和java都是在jvm之上的语言,相对来讲,scala热度比较低,其实并不是一个特别好的语言选择. 原因倒不是因为scala本身的缺点,而是使用人群不够多,论坛和社区不够活跃.这就跟社交软件 ...
- android调试
要进行调试,首先构建app的时候必须选择是Debug模式,而不能是Release模式. 接下来的内容转载自: http://www.cnblogs.com/gaoteng/p/5711314.html ...
- 混合图(dizzy.pas/cpp/c)
混合图(dizzy.pas/cpp/c) [题目描述] Hzwer神犇最近又征服了一个国家,然后接下来却也遇见了一个难题. Hzwer的国家有n个点,m条边,而作为国王,他十分喜欢游览自己的国家.他一 ...
- 墨卡托坐标与LBS应用
今天了解到这边的LBS应用,一般用的是墨卡托坐标. 也就是商品库的商品入库的时候,会根据输入,使用百度地图提供的一个API,来转换成一个墨卡托坐标. 然后用户流量过来的时候,会带来历史坐标,和当前坐标 ...
- 纯CSS实现移动端常见布局——高度和宽度挂钩的秘密
纯CSS实现移动端常见布局--高度和宽度挂钩的秘密 不踩坑不回头.之前我在一个项目中大量使用css3的calc计算属性.写代码的时候真心不要太爽啊-可是在项目上线之后,才让我崩溃了,原因非常easy, ...
- 从一个小demo开始,体验“API经济”的大魅力
写在前面 “API经济”这个词是越来越火了,但是"API经济"具体指的是什么,相信很多人还没有个明确的认识.不过今天我可不打算长篇大论的去讲解一些概念,我们就以“电话号码归属地查询 ...
- Java原型模式之浅拷贝-深拷贝
一.是什么? 浅拷贝:对值类型的成员变量进行值的复制,对引用类型的成员变量仅仅复制引用,不复制引用的对象 深拷贝:对值类型的成员变量进行值的复制,对引用类型的成员变量也进行引用对象的复制 内部机制: ...
- Cocos2d-x教程(26)-Cocos2d-x + Lua脚本实现大地图缩放功能
欢迎增加 Cocos2d-x 交流群: 193411763 视频教程地址:http://www.tudou.com/programs/view/qRiOfppMghM/ 转载请注明原文出处:http: ...