Spark SQL入门案例之人力资源系统数据处理
通过该案例,给出一个比较完整的、复杂的数据处理案例,同时给出案例的详细解析。
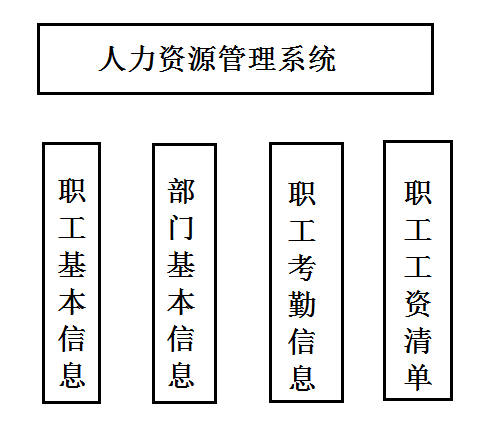
人力资源系统的管理内容组织结构图
1) 人力资源系统的数据库与表的构建。
2) 人力资源系统的数据的加载。
3) 人力资源系统的数据的查询。
职工基本信息
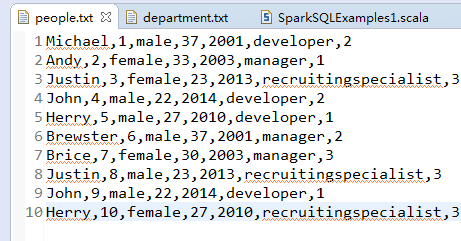
职工姓名,职工id,职工性别,职工年龄,入职年份,职位,所在部门id
Michael,1,male,37,2001,developer,2
Andy,2,female,33,2003,manager,1
Justin,3,female,23,2013,recruitingspecialist,3
John,4,male,22,2014,developer,2
Herry,5,male,27,2010,developer,1
Brewster,6,male,37,2001,manager,2
Brice,7,female,30,2003,manager,3
Justin,8,male,23,2013,recruitingspecialist,3
John,9,male,22,2014,developer,1
Herry,10,female,27,2010,recruitingspecialist,3
部门基本信息
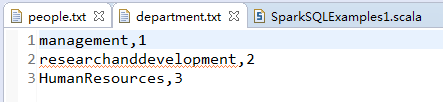
部门名称,编号,数据内容
management,1
researchanddevelopment,2
HumanResources,3
职工考勤信息
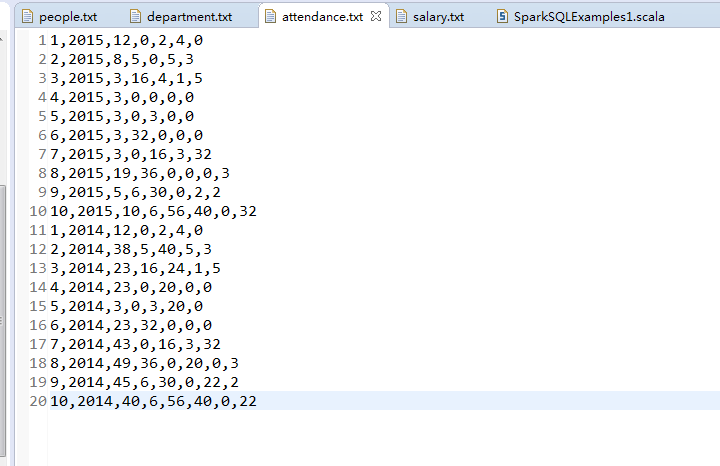
职工id,年,月信息,职工加班,迟到,旷工,早退小时数信息
1,2015,12,0,2,4,0
2,2015,8,5,0,5,3
3,2015,3,16,4,1,5
4,2015,3,0,0,0,0
5,2015,3,0,3,0,0
6,2015,3,32,0,0,0
7,2015,3,0,16,3,32
8,2015,19,36,0,0,0,3
9,2015,5,6,30,0,2,2
10,2015,10,6,56,40,0,32
1,2014,12,0,2,4,0
2,2014,38,5,40,5,3
3,2014,23,16,24,1,5
4,2014,23,0,20,0,0
5,2014,3,0,3,20,0
6,2014,23,32,0,0,0
7,2014,43,0,16,3,32
8,2014,49,36,0,20,0,3
9,2014,45,6,30,0,22,2
10,2014,40,6,56,40,0,22
职工工资清单
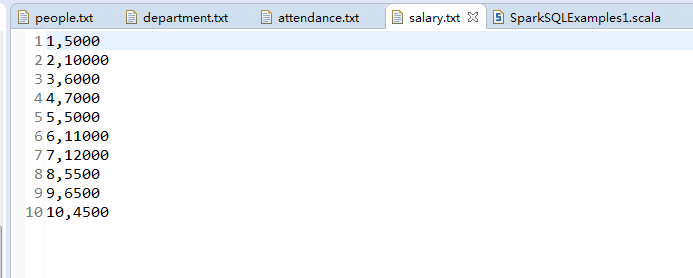
职工id,工资
1,5000
2,10000
3,6000
4,7000
5,5000
6,11000
7,12000
8,5500
9,6500
10,4500
人力资源系统的数据库与表的构建
将人力资源系统的数据加载到Hive仓库的HRS数据中,并对人力资源系统的数据分别建表。
1、启动spark-shell
bin/spark-shell --executor-memory 2g --driver-memory 1g --master spark://spark01:7077
其中,spark01为当前Spark集群的master节点。
由于,当前使用Hive作为数据仓库,至于如何安装与配置,不多赘述,很简单,进行hive-site.xml文件配置并启动了metastore服务等准备操作。
除去多余的日志信息:
scala > import org.apache.log4j.{Level,Logger}
scala > Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
scala > Logger.getLogger("org.apache.spark,sql").setLevel(Level.WARN)
scala > Logger.getLogger("org.apache.hadoop.hive.ql").setLevel(Level.WARN)
以应用程序方式提交时,可以在配置文件conf/log4j.properties中设置日志等级,如下
log4j.logger.org.apache.spark = WARN
log4j.logger.org.apache.spark.sql= WARN
log4j.logger.org.apache.hadoop.hive.ql = WARN
2、构建与使用HRS数据库
1)使用CREATE DATABASE语句创建,名为HRS的数据库,存放人力资源系统里的所有数据。
scala > sqlContext.sql("CREATE DATABASE HRS")
2)使用人力资源系统的数据库HRS
scala > sqlContext.sql("USE HRS")
3、数据建表
1) 构建职工基本信息表people
scala > sqlContext.sql("CREATE TABLE IF NOT EXISTS people(
name STRING,
id INT,
gender STRING,
age INT,
year INT,
position STRING,
depID INT
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n'")
2)构建部门基本信息表department
scala > sqlContext.sql("CREATE TABLE IF NOT EXISTS department(
name STRING,
depID INT
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n'")
3) 构建职工考勤信息表attendance
scala > sqlContext.sql("CREATE TABLE IF NOT EXISTS attendance(
id INT,
year INT,
month INT,
overtime INT,
latetime INT,
absenteeism INT,
leaveearlytime INT
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n'")
4) 构建职工工资清单表salary
scala > sqlContext.sql("CREATE TABLE IF NOT EXISTS attendance(
id INT,
salary INT
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n'")
人力资源系统的数据的加载
分别将本地这4个文件的数据加载到四个表
1)职工基本信息表的加载数据操作
scala > sqlContext.sql("LOAD DATA LOCAl INPATH '/usr/local/data/people.txt' OVERWRITE INTO TABLE people")
其中,OVERWRITE 表示覆盖当前表的数据,即先清除表数据,再将数据insert到表中。
2)部门基本信息表的加载数据操作
scala > sqlContext.sql("LOAD DATA LOCAl INPATH '/usr/local/data/department.txt' OVERWRITE INTO TABLE department")
3)职工考勤基本信息表的加载数据操作
scala > sqlContext.sql("LOAD DATA LOCAl INPATH '/usr/local/data/attendance.txt' OVERWRITE INTO TABLE attendance")
4)职工工资基本信息表的加载数据操作
scala > sqlContext.sql("LOAD DATA LOCAl INPATH '/usr/local/data/salary.txt' OVERWRITE INTO TABLE salary")
人力资源系统的数据的加载
人力资源系统的数据常见的查询操作有部门职工数的查询、部门职工的薪资topN的查询、部门职工平均工资的排名、各部门每年职工薪资的总数查询等。
查看各表的信息,同时查看界面回显中的schema信息
scala > sqlContext.sql("SELECT * FROM people)
scala > sqlContext.sql("SELECT * FROM department)
scala > sqlContext.sql("SELECT * FROM attendance)
scala > sqlContext.sql("SELECT * FROM salary)
1、部门职工数的查询
首先将people表数据与department表数据进行join操作,然后根据department的部门名进行分组,分组后针对people中唯一标识一个职工的id字段进行统计,最后得到各个部门对应的职工总数统计信息。
scala > sqlContext.sql("SELECT b.name,count(a.id) FROM people a JOIN department b on a.depid = b.depid GROUP BY b.name").show
name _c1
HumanResources 4
researchanddeveloper 3
management 3
2、对各个部门职工薪资的总数、平均值的排序
首先根据部门id将people表数据与department表数据进行join操作,根据职工id join salary表数据,然后根据department的部门名进行分组,分组后针对职工的薪资进行求和或求平均值,并根据该值大小进行排序。(默认排序为从小到大)
scala > sqlContext.sql("SELECT b.name,sum(c.salary) AS s FROM people a JOIN department b on a.depid = b.depid JOIN salary c ON a.id = c.id GROUP BY b.name ORDER BY s").show
name s
management 21500
researchanddeveloper 23000
HumanResources 28000
查询各个部门职工薪资的平均值的排序
scala > sqlContext.sql("SELECT b.name,avg(c.salary) AS s FROM people a JOIN department b ON a.depid = b.depid JOIN salary c ON a.id = c.id GROUP BY b.name ORDER BY s").show
name s
HumanResources 7000.0
management 7166.666666666667
researchanddeveloper 7666.666666666667
3、查询各个部门职工的考勤信息
首先根据职工id将attendance考勤表数据与people职工表数据进行join操作,并计算职工的考勤信息,然后根据department的部门名、考勤信息的年份进行分组,分组后针对职工的考勤信息进行统计。
scala > sqlContext.sql("SELECT b.name,sum(h.attdinfo),h.year from(SELECT a.id,a.depid,at.year,at.month,overtime - latetime -absenteeism -leaveearytime as attdinfo FROM attendance at JION people a on at.id = a.id) h JOIN department b on h.depid = b.depid GROUP BY b.name, h.year").show
name _c1 year
management _112 2014
management _32 2015
HumanResources _139 2014
HumanResources _99 2015
researchanddeveloper 6 2014
researchanddeveloper 26 2015
其中,返回结果中的第一行表示字段名,_c1为新增的考勤信息统计结果字段名,其他行表示对应字段的值。
4、合并前面的全部查询
scala > sqlContext.sql("select e.name,e.pcount,f.sumsalary,f.avgsalary,j.year,j.sumattd FROM (SELECT b.name,count(a.id) AS pcount FROM people a JOIN department b on a.depid = b.depid GROUP BY b.name ORDER BY pcount) e JOIN (SELECT b.name,sum(s.salary) as sumsalary,avg(c.salary) as avgsalary FROM people a JOIN department b on a.depid = b.depid JOIN salary c on a.id = c.id GROUP BY b.name ORDER BY sumsalary) f on (e.name = f.name) JOIN (SELECT b.name ,sum(h,attdinfo) AS sumattd,h.year FROM (SELECT a.id,a.depid,at.year,at.month,overtime -latetime -absenteeism -leaveearytime AS attdinfo FROM attendance at JOIN people a on at.id = a.id) h JOIN department b on h.depid = b.depid GROUP BY b.name,h.year) j on f.name = j.name OREDER BY f.name").show
将前面的几个查询,合并到一个SQL语句中,最后得到各部门的各种统计信息。包括部门职工数、部门薪资、部门每年的考勤统计等信息。
name pcount sumsalary avgsalary year sumattd
HumanResources 4 28000 7000.0 2014 139
HumanResources 4 28000 7000.0 2015 99
management 3 21500 7166.666666666667 2014 112
management 3 21500 7166.666666666667 2015 32
researchanddeveloper 3 2300 7666.666666666667 2014 6
researchanddeveloper 3 2300 7666.666666666667 2015 26
Spark SQL入门案例之人力资源系统数据处理的更多相关文章
- Spark SQL入门用法与原理分析
Spark SQL是为了让开发人员摆脱自己编写RDD等原生Spark代码而产生的,开发人员只需要写一句SQL语句或者调用API,就能生成(翻译成)对应的SparkJob代码并去执行,开发变得更简洁 注 ...
- spark sql 入门
package cn.my.sparksql import cn.my.sparkStream.LogLevel import org.apache.spark.{SparkConf, SparkCo ...
- Spark SQL概念学习系列之Spark SQL入门
前言 第1章 为什么Spark SQL? 第2章 Spark SQL运行架构 第3章 Spark SQL组件之解析 第4章 深入了解Spark SQL运行计划 第5章 测试环境之搭建 第6章 ...
- Spark SQL概念学习系列之Spark SQL入门(八)
前言 第1章 为什么Spark SQL? 第2章 Spark SQL运行架构 第3章 Spark SQL组件之解析 第4章 深入了解Spark SQL运行计划 第5章 测试环境之搭建 第6章 ...
- Spark SQL与Hive on Spark的比较
简要介绍了SparkSQL与Hive on Spark的区别与联系 一.关于Spark 简介 在Hadoop的整个生态系统中,Spark和MapReduce在同一个层级,即主要解决分布式计算框架的问题 ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- spark结构化数据处理:Spark SQL、DataFrame和Dataset
本文讲解Spark的结构化数据处理,主要包括:Spark SQL.DataFrame.Dataset以及Spark SQL服务等相关内容.本文主要讲解Spark 1.6.x的结构化数据处理相关东东,但 ...
- 59、Spark Streaming与Spark SQL结合使用之top3热门商品实时统计案例
一.top3热门商品实时统计案例 1.概述 Spark Streaming最强大的地方在于,可以与Spark Core.Spark SQL整合使用,之前已经通过transform.foreachRDD ...
- Spark SQL JSON数据处理
背景 这一篇可以说是“Hive JSON数据处理的一点探索”的兄弟篇. 平台为了加速即席查询的分析效率,在我们的Hadoop集群上安装部署了Spark Server,并且与我们的Hive数据仓 ...
随机推荐
- 码云私人代码 SSH 设置----https://blog.csdn.net/kkaazz/article/details/78667573
码云私人代码 SSH 设置 https://blog.csdn.net/kkaazz/article/details/78667573
- jsp之${CTX}理解
jsp之${CTX} 根据自己的需要选择以下标签. <%@ taglib uri="/struts-tags" prefix="s"%> <% ...
- Ubuntu 16.04安装GIMP替代PS
GIMP虽然不能完全替代PS,但是也能弥补一下. 系统默认源中已经包含了GIMP,不需要使用PPA这些. 安装: sudo apt-get install gimp 启动: 通过Dash搜索GIMP即 ...
- Ubuntu 16.04安装搜索拼音输入法
Linux下唯一一款大厂出的输入法 1.下载 http://pinyin.sogou.com/linux/?r=pinyin 2.安装 sudo dpkg -i sogoupinyin_2.1.0.0 ...
- Domino Server installation on Linux (Centos or Redhat) – something somewhere
something somewhere welcome in there…:) Just another techki site howto / Linux / Lotus Domino 0 Domi ...
- 阿牛的EOF牛肉串-记忆化搜索或动态规划
C - 阿牛的EOF牛肉串 Time Limit:1000MS Memory Limit:32768KB 64bit IO Format:%I64d & %I64u Submi ...
- Swift之闭包
swift中闭包是一个非常强大的东西,闭包是自包括的函数代码块,能够在代码中被传递和使用.跟C 和 Objective-C 中的代码块(blocks)非常相似 .这个大家必须掌握!必须掌握! 必须掌握 ...
- Cocos2d-html5入门之2048游戏
一.介绍 Cocos2d-JS是Cocos2d-x的Javascript版本,它的前身是Cocos2d-html5.在3.0版本以前叫做Cocos2d-html5,从3.0版本开始叫做Cocos2d- ...
- C#之反射(PropertyInfo类)
1.引入命名空间:System.Reflection:程序集:mscorlib(在mscorlib.dll中) 2.示例代码(主要是getType().setValue().getValue()方法) ...
- jqury+css实现可弹出伸缩层
1.使用可弹出伸缩窗调整了之前的页面布局,使用这样的布局使整个界面看起来更加清爽也更简洁 watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQv/font/5a6L ...