python之str (字符型)
用途:
- 存储少量的数据,+ *int 切片, 其他操作方法
- 切片还是对其进行任何操作,获取的内容全部是strl类型
- 存储数据单一
格式: 在python中用引号引起来的就是字符串
'今天吃了没?'
1. 索引切片
索引顺序如下图:
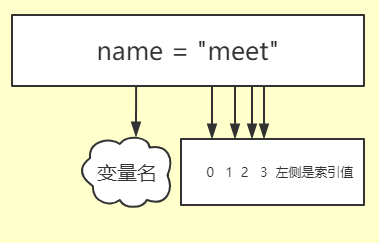
name = "meet,alex,wusir,wangsir,Eva_j"
01234567 (索引) #从左向右数数
-4-3-2-1 (索引) #从右向左数数
格式:
区间[起始位置:终止位置]
原则:
顾头不顾腚
例题:
name = 'hello'
name1 = name[:3]
print(name1) #输出结果:hel 根据顾头不顾尾原则后面的l被丢弃
切片字符的拼接:
name = "meet,alex,wusir,wangsir,Eva_j"
a = name[0]
b = name[1]
print(a + b)
# 输出结果
# me
2. 步长:
格式:
默认是1 [起始位置:终止位置:步长]
步长就是你走路迈的步子
例题:
name = "meet,alex,wusir,wangsir,Eva_j"
print(name[0:10:2])
# 输出结果
# me,lx
# 个人见解
# 这里的2为步长,从0(m)开始到10(,)结束,m一定要取,然后开始数0(m)取走、1(e)、2(e)取走、1(t)、2(,)取走、1(a)、2(l)取走、1(e)、2(x)取走、1(,)
识记点:
- 切片如果终止位置超出了不报错
print(name[0:100])不报错 - 索引取值的时候超出了索引的范围会报错
print(name[100])报错原因:取不到100索引的值 - 字符串,列表,元组 -- 都是有索引(下标)
- 索引是准确的定位某个元素
- 从左向右 0,1,2,3
- 从右向左 -1,-2,-3,-4
- 支持索引的都支持切片 [索引]
3. 反转
格式:
区间[起始位置:终止位置:-1]
例题:
name = "meet,alex,wusir,wangsir,Eva_j"
print(name[::-1])
输出结果
j_avE,risgnaw,risuw,xela,teem
字符串操作方法:
识记:
字符串的类型以 . 来调用 才叫做字符串方法
upper (全部大写)
例题:
name = "meet"
name1 = name.upper()
print(name1)
# 输出结果
# MEET
lower (全部小写)
例题:
name = "MEET"
name1 = name.lower()
print(name1)
# 输出结果
# meet
练习题: 验证码
yzm = "o98K"
input_yzm = input("请输入验证码(o98K):")
if yzm.upper() == input_yzm.upper():
print("正确")
else:
print("错误")
id (获取内存地址)
例题:
name = 'alex'
print(id(name))
# 输出结果
# 4543793504
startswith (以什么开头)
例题:
name = "alex"
print(name.startswith('a'))
# 判断name变量是以a开的头的
endswith (以什么结尾)
例题:
name = "zhuxiaodidi"
print(name.endswith("i"))
# 判断name就是以i结尾
count (统计)
例题:
# name = "zhudidi"
# print(name.count("zhu"))
# 查询某个内容出现的次数
replace (替换) *********
格式:
str.replace('n','s') 前面是要被替换的内容 后面是新的
例题:
# name = "alexnbnsnsn"
# name1 = name.replace('n','s') # 替换 前面是老的,后面是新的
# name1 = name.replace('n','s',2) # 替换 前面是老的,后面是新的 2是替换的次数
# print(name1)
strip (除去头尾两边的空格/换行符) *********
例题:
# name = " alex "
# name1 = name.strip() # 可以写想要去掉的内容
# print(name1)
# if name == "alex":
# print(666)
# name = " alex "
# print(name.strip())
split (分割) *********
例题:
name = 'alex,wusir'
print(name.split(","))
# ['alex', 'wusir']
# 默认是以空格分割 ,也可以自己制定分割
# 分割后返回的内容是一个列表
分割后返回的内容是一个列表
1. 无参数的情况
a="my name is john"
b="my\nname\nis\john"
c="my\tname\tis\john"
a=a.split()
b=b.split()
c=c.split()
print(a)
print(b)
print(c)
输出:
['my', 'name', 'is', 'john']
['my', 'name', 'is', 'john']
['my', 'name', 'is', 'john']
---------------------
2. 有参数的情况
d="my,name,is,john"
e="my;name;is;john"
f="my-name-is-john"
d=d.split(",")
e=e.split(";")
f=f.split("-")
print(d)
print(e)
print(f)
输出:
['my', 'name', 'is', 'john']
['my', 'name', 'is', 'john']
['my', 'name', 'is', 'john']
---------------------
3. 当具有两个参数的情况
a="My,name,is,john,and,I,am,a,student"
b1=a.split(",",1)
b2=a.split(",",2)
b8=a.split(",",8)
b9=a.split(",",9)
print(b1)
print(b2)
print(b8)
print(b9)
输出:
['My', 'name,is,john,and,I,am,a,student']
['My', 'name', 'is,john,and,I,am,a,student']
['My', 'name', 'is', 'john', 'and', 'I', 'am', 'a', 'student']
['My', 'name', 'is', 'john', 'and', 'I', 'am', 'a', 'student']
---------------------
format (第三种字符串格式化)
三种方法:
- 按照位置顺序去填充的
- 按照索引位置去填充
- 关键字填充(指名道姓 填充)
例题:
# name = "alex{}wusir{}"
# name1 = name.format('结婚了',"要结婚了") # 按照位置顺序去填充的
# name = "alex{1}wusir{0}"
# name1 = name.format('结婚了',"要结婚了") # 按照索引位置去填充
# name = "alex{a}wusir{b}"
# name1 = name.format(a="结婚了",b="马上结婚") # 指名道姓 填充
# print(name1)
isdigit (判断是不是阿拉伯数字)
例题:
# name = "②"
# print(name.isdigit())
isdecimal (判断是不是十进制 -- 用它来判断是不是数字)
例题:
# name = "666"
# print(name.isdecimal())
isalpha (判断的是中文和字母)
例题:
# name = "alexs你好"
# print(name.isalpha())
isalnum (判断的是不是字母,中文和阿拉伯数字)
例题:
# name = "alex666"
# print(name.isalnum())
python之str (字符型)的更多相关文章
- 字符型图片验证码识别完整过程及Python实现
字符型图片验证码识别完整过程及Python实现 1 摘要 验证码是目前互联网上非常常见也是非常重要的一个事物,充当着很多系统的 防火墙 功能,但是随时OCR技术的发展,验证码暴露出来的安全问题也越 ...
- 基于python语言的tensorflow的‘端到端’的字符型验证码识别源码整理(github源码分享)
基于python语言的tensorflow的‘端到端’的字符型验证码识别 1 Abstract 验证码(CAPTCHA)的诞生本身是为了自动区分 自然人 和 机器人 的一套公开方法, 但是近几年的 ...
- Python识别字符型图片验证码
前言 验证码是目前互联网上非常常见也是非常重要的一个事物,充当着很多系统的 防火墙 功能,但是随时OCR技术的发展,验证码暴露出来的安全问题也越来越严峻.本文介绍了一套字符验证码识别的完整流程,对于验 ...
- python学习(二):基本数据类型:整型,字符型
整型: type():显示数据类型 # 整型,int # python3里,不管数字有多大,都是int类型 # python2里,有大小区分,长整型:long int a = " print ...
- python的str,unicode对象的encode和decode方法, Python中字符编码的总结和对比bytes和str
python_2.x_unicode_to_str.py a = u"中文字符"; a.encode("GBK"); #打印: '\xd6\xd0\xce\xc ...
- [验证码识别技术] 字符型验证码终结者-CNN+BLSTM+CTC
验证码识别(少样本,高精度)项目地址:https://github.com/kerlomz/captcha_trainer 1. 前言 本项目适用于Python3.6,GPU>=NVIDIA G ...
- JSON转换类(一)--过滤特殊字符,格式化字符型、日期型、布尔型
/// <summary> /// 过滤特殊字符 /// </summary> private static string String2Json(String s) { St ...
- python的str,unicode对象的encode和decode方法
python的str,unicode对象的encode和decode方法 python中的str对象其实就是"8-bit string" ,字节字符串,本质上类似java中的byt ...
- 基于tensorflow的‘端到端’的字符型验证码识别源码整理(github源码分享)
基于tensorflow的‘端到端’的字符型验证码识别 1 Abstract 验证码(CAPTCHA)的诞生本身是为了自动区分 自然人 和 机器人 的一套公开方法, 但是近几年的人工智能技术的发展 ...
随机推荐
- 连接mysql报错-Can't connect to MySQL server on
1.问题: 在Windows 上远程连接数据库报错-Can't connect to MySQL server on... 但是重启系统后就可以连接: 2.这种原因大致是因为系统缓冲区空间不足或列队已 ...
- C#中的Webservice实例代码(vs2013)
2.1首先创建一个最基本的web service服务端,顾名思义就是提供服务,这儿实现一个简单的加法计算. 首先,vs2013--文件---新建项目---Asp.net 空Web 应用程序 (V ...
- POJ2105【进制转化】
直接瞎写就可以水过.我记得STL有很多好的函数,哎.水过去补多校的题. //#include <bits/stdc++.h> #include<cstdio> #include ...
- bzoj 4259 4259: 残缺的字符串【FFT】
和bzoj 4503 https://www.cnblogs.com/lokiii/p/10032311.html 差不多,就是再乘上一个原串字符 有点卡常,先在点值下算最后一起IDFT #inclu ...
- bzoj 4403: 序列统计【lucas+组合数学】
首先,给一个单调不降序列的第i位+i,这样就变成了单调上升序列,设原来数据范围是(l,r),改过之后变成了(l+1,r+n) 在m个数里选长为n的一个单调上升序列的方案数为\( C_m^n \),也就 ...
- (2)javascript的基本语法、数据结构、变量
本篇学习资料主要讲解javascript的基本语法.数据结构.变量 无论是传统的编程语言,还是脚本语言,都具有数据类型.常量和变量.运算符.表达式.注释语句.流程控制语句等基本元素构成,这些 ...
- 使用pytesseract识别验证码,报错WindowsError: [Error 2]
问题现象: 按照网上的方式进行代码编写,使用pytesseract模块,然后导入指定图片进行解析,报错WindowsError: [Error 2] 问题原因: 源代码里面的路径设置错误,这里有一个坑 ...
- (四)python自带解释器(IDLE)的使用
什么是IDE? Integrated Development Environment(集成开发环境) 打个不恰当的比方,如果说写代码是制作一件工艺品,那IDE就是机床.再打个不恰当的比方,PS就是图片 ...
- Codeforces Round #410 (Div. 2) C
Description Mike has a sequence A = [a1, a2, ..., an] of length n. He considers the sequence B = [b1 ...
- tsconfig.json No inputs were found in config file
Build:No inputs were found in config file '/tsconfig.json'. Specified 'include' paths were '["* ...