Netty精粹之轻量级内存池技术实现原理与应用
摘要: 在Netty中,通常会有多个IO线程独立工作,基于NioEventLoop的实现,每个IO线程负责轮询单独的Selector实例来检索IO事件,当IO事件来临的时候,IO线程开始处理IO事件。最常见的IO事件即读写事件,那么这个时候就会涉及到IO线程对数据的读写问题,具体到NIO方面即从内核缓冲区读取数据到用户缓冲区或者从用户缓冲区将数据写到内核缓冲区。NIO提供了两种Buffer作为缓冲区,即DirectBuffer和HeapBuffer。这篇文章主要在介绍两种缓冲区的基础之上再介绍Netty基于ThreadLocal的内存池技术的实现原理与应用,并给出一个简单维度的测试数据。
在Netty中,通常会有多个IO线程独立工作,基于NioEventLoop的实现,每个IO线程负责轮询单独的Selector实例来检索IO事件,当IO事件来临的时候,IO线程开始处理IO事件。最常见的IO事件即读写事件,那么这个时候就会涉及到IO线程对数据的读写问题,具体到NIO方面即从内核缓冲区读取数据到用户缓冲区或者从用户缓冲区将数据写到内核缓冲区。NIO提供了两种Buffer作为缓冲区,即DirectBuffer和HeapBuffer。这篇文章主要在介绍两种缓冲区的基础之上再介绍Netty基于ThreadLocal的内存池技术的实现原理与应用,并给出一个简单维度的测试数据。
DirectBuffer和HeapBuffer
DirectBuffer顾名思义是分配在直接内存(Direct Memory)上面的内存区域,直接内存不是JVM Runtime数据区的一部分,也不是JAVA虚拟机规范中定义的内存区域,但是这部分内存也被频繁的使用。在JDK1.4版本开始NIO引入的Channel与Buffer的IO方式使得我们可以使用native接口来在直接内存上分配内存,并用JVM堆内存上的一个引用来进行操作,当JVM堆内存上的引用被回收之后,这块直接内存才会被操作系统回收。HeapBuffer即分配在JVM堆内存区域的缓冲区,我们可以简单理解为HeapBuffer就是byte[]数组的一种封装形式。
基于HeapBuffer的IO写流程通常是先要在直接内存上分配一个临时的缓冲区,然后将数据copy到直接内存,然后再将这块直接内存上的数据发送到IO设备的缓冲区,最后销毁临时直接内存区域。而基于HeapBuffer的IO读流程也类似。使用DirectBuffer之后,避免了JVM堆内存和直接内存之间数据来回复制,在一些应用场景中性能有显著的提高。除了避免多次拷贝之外直接内存的另一个好处就是访问速度快,这跟JVM的对象访问方式有关。
DirectBuffer的缺点在于直接内存的分配与回收代价相对比较大,因此DirectBuffer适用于缓冲区可以重复使用的场景。
Netty中的Buffers
在Netty中,缓冲区有两种形式即HeapBuffer和DirectBuffer。Netty对于他们都进行了池化:

其中对应堆内存和直接内存的池化实现分别是PooledHeapByteBuf和PooledDirectByteBuf,在各自的实现中都维护着一个Recycler,这个Recycler就是本文关注的重点,也是Netty轻量级内存池技术的核心实现。
Recycler及内部组件
Recycler是一个抽象类,向外部提供了两个公共方法get和recycle分别用于从对象池中获取对象和回收对象;另外还提供了一个protected的抽象方法newObject,newObject用于在内存池中没有可用对象的时候创建新的对象,由用户自己实现,Recycler以泛型参数的形式让用户传入具体要池化的对象类型。
/**
* Light-weight object pool based on a thread-local stack.
*
* @param <T> the type of the pooled object
*/
public abstract class Recycler<T>Recycler内部主要包含三个核心组件,各个组件负责对象池实现的具体部分,Recycler向外部提供统一的对象创建和回收接口:
Handle
WeakOrderQueue
Stack
各组件的功能如下
Handle
Recycler在内部类中给出了Handle的一个默认实现:DefaultHandle,Handle主要提供一个recycle接口,用于提供对象回收的具体实现,每个Handle关联一个value字段,用于存放具体的池化对象,记住,在对象池中,所有的池化对象都被这个Handle包装,Handle是对象池管理的基本单位。另外Handle指向这对应的Stack,对象存储也就是Handle存储的具体地方由Stack维护和管理。
Stack
Stack具体维护着对象池数据,向Recycler提供push和pop两个主要访问接口,pop用于从内部弹出一个可被重复使用的对象,push用于回收以后可以重复使用的对象。
WeakOrderQueue
WeakOrderQueue的功能可以由两个接口体现,add和transfer。add用于将handler(对象池管理的基本单位)放入队列,transfer用于向stack输入可以被重复使用的对象。我们可以把WeakOrderQueue看做一个对象仓库,stack内只维护一个Handle数组用于直接向Recycler提供服务,当从这个数组中拿不到对象的时候则会寻找对应WeakOrderQueue并调用其transfer方法向stack供给对象。
Recycler实现原理
我先给出一张总的示意图,下面如果有看不懂的地方可以结合这张图来理解:
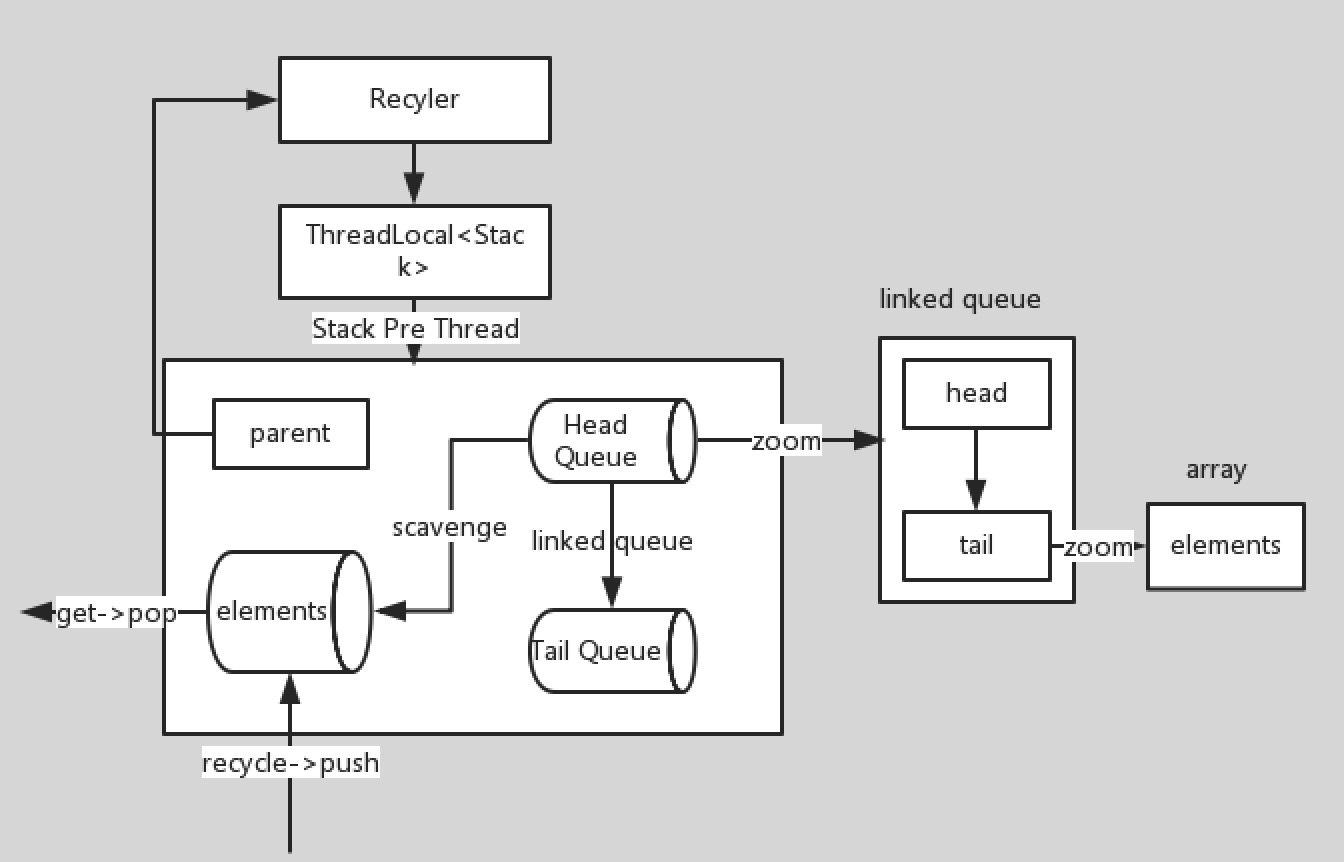
上图代表着Recycler的工作示意图。Recycler#get是向外部提供的从对象池获取对象的接口:
public final T get() {
Stack<T> stack = threadLocal.get();
DefaultHandle handle = stack.pop();
if (handle == null) {
handle = stack.newHandle();
handle.value = newObject(handle);
}
return (T) handle.value;
}
Recycler首先从当前线程绑定的值中获取stack,我们可以得知Netty中其实是每个线程关联着一个对象池,直接关联对象为Stack,先看看池中是否有可用对象,如果有则直接返回,如果没有则新创建一个Handle,并且调用newObject来新创建一个对象并且放入Handler的value中,newObject由用户自己实现。
当Recycler使用Stack的pop接口的时候,我们看看:
DefaultHandle pop() {
int size = this.size;
if (size == 0) {
if (!scavenge()) {
return null;
}
size = this.size;
}
size --;
DefaultHandle ret = elements[size];
if (ret.lastRecycledId != ret.recycleId) {
throw new IllegalStateException("recycled multiple times");
}
ret.recycleId = 0;
ret.lastRecycledId = 0;
this.size = size;
return ret;
}
首先看看Stack的elements数组是否有对象可用,如果有则将size大小减1,返回对象。如果elements数组中已经没有对象可用,则需要从仓库中查找是够有可以用的对象,也就是scavenge的实现,scavenge具体调用的是scavengeSome。Stack的仓库是由WeakOrderQueue连接起来的链表实现的,Stack维护着链表的头部指针。而每个WeakOrderQueue又维护着一个链表,节点由Link实现,Link的实现很简单,主要是继承AtomicInteger类另外还有一个Handle数组、一个读指针和一个指向下一个节点的指针,Link巧妙的利用AtomicInteger值来充当数组的写指针从而避免并发问题。
Recycler对象池的对象存储分为两个部分,Stack的Handle数组和Stack指向的WeakOrderQueue链表。
private DefaultHandle[] elements;
private volatile WeakOrderQueue head;
private WeakOrderQueue cursor, prev;
Stack保留着WeakOrderQueue链表的头指针和读游标。WeakOrderQueue链表的每个节点都是一个Link,而每个Link都维护者一个Handle数组。
池中对象的读取和写入
从对象池获取对象主要是从Stack的Handle数组,而Handle数组的后备资源来源于WeakOrderQueue链表。而elements数组和WeakOrderQueue链表中对象的来源有些区别:
public void recycle() {
Thread thread = Thread.currentThread();
if (thread == stack.thread) {
stack.push(this);
return;
}
// we don't want to have a ref to the queue as the value in our weak map
// so we null it out; to ensure there are no races with restoring it later
// we impose a memory ordering here (no-op on x86)
Map<Stack<?>, WeakOrderQueue> delayedRecycled = DELAYED_RECYCLED.get();
WeakOrderQueue queue = delayedRecycled.get(stack);
if (queue == null) {
delayedRecycled.put(stack, queue = new WeakOrderQueue(stack, thread));
}
queue.add(this);
}
从Handle的recycle实现看出:如果由拥有Stack的线程回收对象,则直接调用Stack的push方法将该对象直接放入Stack的数组中;如果由其他线程回收,则对象被放入线程关联的<Stack,WeakOrderQueue>的队列中,这个队列其实在这里被放入了stack关联的WeakOrderQueue链表的表头:
WeakOrderQueue(Stack<?> stack, Thread thread) {
head = tail = new Link();
owner = new WeakReference<Thread>(thread);
synchronized (stack) {
next = stack.head;
stack.head = this;
}
}
每一个没有拥有stack的线程回收对象的时候都会重新创建一个WeakOrderQueue节点放入stask关联的WeakOrderQueue链表的表头,这样做最终实现了多线程回收对象统统放入stack关联的WeakOrderQueue链表中而拥有stack的线程都能够读取其他线程供给的对象。
简单的测试数据说话
下面我们来看下基于轻量级内存池和原始使用方式带来的性能数据对比,这里拿Netty提供的一个简单的可以回收的RecyclableArrayList来和传统的ArrayList来做比较,由于RecyclableArrayList和传统的ArrayList优势主要在于当频繁重复创建ArrayList对象的时候RecyclableArrayList不会真的新创建,而是会从池中获取对象来使用,而ArrayList的每次new操作都会在JVM的对内存中真枪实弹的创建一个对象,因此我们可以想象对于ArrayList的使用,青年代的内存回收相对会比较频繁,为了简单期间,我们这个例子不涉及直接内存技术,因此我们关心的地方主要是GC频率回收的改善,看看我的两段测试代码:
代码1:
public static void main(String ...s) {
int i=0, times = 1000000;
byte[] data = new byte[1024];
while (i++ < times) {
RecyclableArrayList list = RecyclableArrayList.newInstance();
int count = 100;
for (int j=0;j<count;j++){
list.add(data);
}
list.recycle();
System.out.println("count:[" + count +
"]");
sleep(1);
}
}
代码2:
public static void main(String ...s) {
int i=0, times = 1000000;
byte[] data = new byte[1024];
while (i++ < times) {
ArrayList list = new ArrayList();
int count = 100;
for (int j=0;j<count;j++){
list.add(data);
}
System.out.println("count:[" + count +
"]");
sleep(1);
}
}
上面代码逻辑相同,分别循环100w次,每次循环创建一个ArrayList对象,放入100个指向1kb大小的字节数组的引用,消耗内存的地方主要是ArrayList对象的创建,因为ArrayList的内部是对象数组实现的,因此内存消耗比较少,我们只能通过快速的循环创建来达到内存渐变的效果。
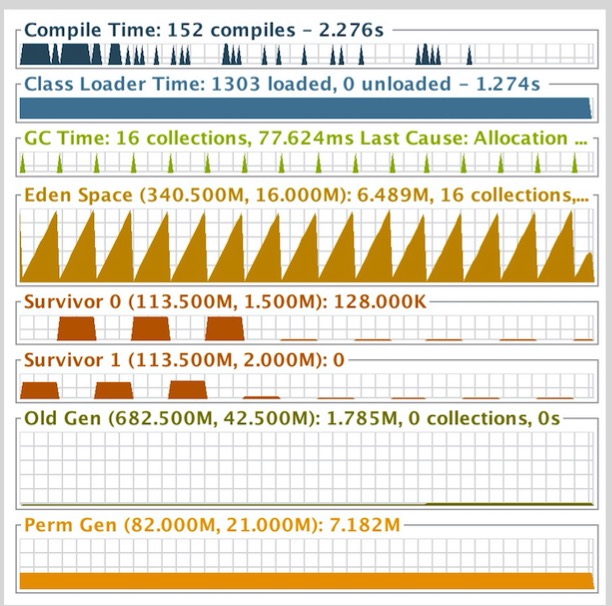

上面左图是使用传统的ArrayList测试数据,右图是使用RecyclableArrayList的测试数据,对于不可循环使用的ArrayList,GC频率相比使用RecyclableArrayList的GC频率高很多,上面的工具也给出了左图16次GC花费的时间为77.624ms而右图的3次GC花费的时间为26.740ms。
Recycler对象池总结
在Netty中,所有的IO操作基本上都要涉及缓冲区的使用,无论是上文说的HeapBuffer还是DirectBuffer,如果对于这些缓冲区不能够重复利用,后果是可想而知的。对于堆内存则会引发相对频繁的GC,而对于直接内存则会引发频繁的缓冲区创建与回收,这些操作对于两种缓冲区分别带来严重的性能损耗,Netty基于ThreadLocal实现的轻量级对象池实现在一定程度上减少了由于GC和分配回收带来的性能损耗,使得Netty线程运行的更快,总体性能更优。
总体上基于内存池技术的缓冲区实现,优点可以总结如下:
对于PooledHeapBuffer的使用,Netty可以重复使用堆内存区域,降低的内存申请的频率同时也降低了JVM GC的频率。
对于PooledDirectBuffer而言,Netty可以重复使用直接内存区域分配的缓冲区,这使得对于直接内存的使用在原有相比HeapBuffer的优点之外又弥补了自身分配与回收代价相对比较大的缺点。
Netty精粹之轻量级内存池技术实现原理与应用的更多相关文章
- 内存池技术(UVa 122 Tree on the level)
内存池技术就是创建一个内存池,内存池中保存着可以使用的内存,可以使用数组的形式实现,然后创建一个空闲列表,开始时将内存池中所有内存放入空闲列表中,表示空闲列表中所有内存都可以使用,当不需要某一内存时, ...
- Linux服务器内存池技术是如何实现的
Linux服务器内存池技术是如何实现的
- Netty源码解析 -- 内存池与PoolArena
我们知道,Netty使用直接内存实现Netty零拷贝以提升性能, 但直接内存的创建和释放可能需要涉及系统调用,是比较昂贵的操作,如果每个请求都创建和释放一个直接内存,那性能肯定是不能满足要求的. 这时 ...
- 常见C++内存池技术
原文:http://www.cppblog.com/weiym/archive/2013/04/08/199238.html 总结下常见的C++内存池,以备以后查询.应该说没有一个内存池适合所有的情况 ...
- Java对象池技术的原理及其实现
看到一片有关于java 对象基础知识,故转载一下,同时学习一下. 摘 要 本文在分析对象池技术基本原理的基础上,给出了对象池技术的两种实现方式.还指出了使用对象池技术时所应注意的问题. 关键词 对象池 ...
- boost::pool与内存池技术
建议看这个链接的内容:http://cpp.winxgui.com/cn:mempool-example-boost-pool Pool分配是一种分配内存方法,用于快速分配同样大小的内存块, ...
- netty学习心得2内存池
http://frankfan915.iteye.com/blog/2199600 https://www.jianshu.com/p/13f72e0395c8:一个性能调优的文档,还有一些linux ...
- Netty源码解析 -- 对象池Recycler实现原理
由于在Java中创建一个实例的消耗不小,很多框架为了提高性能都使用对象池,Netty也不例外. 本文主要分析Netty对象池Recycler的实现原理. 源码分析基于Netty 4.1.52 缓存对象 ...
- 感悟优化——Netty对JDK缓冲区的内存池零拷贝改造
NIO中缓冲区是数据传输的基础,JDK通过ByteBuffer实现,Netty框架中并未采用JDK原生的ByteBuffer,而是构造了ByteBuf. ByteBuf对ByteBuffer做了大量的 ...
随机推荐
- eclipse-查看继承层次图/继承实现层次图
阅读代码时,如果想要看某个类继承了哪些类.实现了哪些接口.哪些类继承了这个类,恰巧这个类的继承实现结构又比较复杂,那么如果对开发工具不是很熟练,这个需求是比较难以实现的.eclipse中的type h ...
- IP、TCP、DNS协议
·······················································IP协议························· 位于网络层,作用是把数据包传送 ...
- windows Sql server performance monitor
对于sql server 性能的监控主要从2个方面: 1. sql server自带的监控 Management->SQL Server Logs->Activity Monitor 在这 ...
- LOJ-10102(桥的判断)
题目链接:传送门 思路:找桥就行了,条件是num[v]<low[u],pre!=v; #include<iostream> #include<cstdio> #inclu ...
- python基本数据类型之列表和元组
python基本数据类型之列表与元组 python中list与tuple都是可以遍历类型.不同的是,list是可以修改的,而元组属于不可变类型,不能修改. 列表和元组中的元素可以是任意类型,并且同一个 ...
- hdmi中深度色彩像素打包
4个色彩像素包模式:24- 30- 36- 48- 不同模式下tmds时钟与与像素的比是位宽与24的比值 . 24 bit mode: TMDS clock = 1.0 x pixel clock ( ...
- Ubuntu 14.04 LTS 初装成
原先博客放弃使用,几篇文章搬运过来 Windows 7下使用win32diskimager 制作启动盘,安装Ubuntu OS安装完成后,安装DrclientLinux. 安装搜狗输入法 Linux下 ...
- java时间与js时间
这是一个由java获取的系统时间与js获取的系统时间不一致导致的测试缺陷 定义方式: java Date date = new Date(); js var Date date2 = new Date ...
- mysql 存储过程 CONCAT 字符串拼接
mysql 存储过程 CREATE PROCEDURE pro_province_report (IN startDate VARCHAR(),IN endDate VARCHAR(),IN Sour ...
- [Python] networkx入门 转
networkx是python的一个第三方包,可以方便地调用各种图算法的计算. 通过调用python画图包matplotlib能实现图的可视化. 1.安装 正好整理一下python第三方包的安装方法. ...