Python多进程并发操作中进程池Pool的应用
Pool类
在使用Python进行系统管理时,特别是同时操作多个文件目录或者远程控制多台主机,并行操作可以节约大量的时间。如果操作的对象数目不大时,还可以直接使用Process类动态的生成多个进程,十几个还好,但是如果上百个甚至更多,那手动去限制进程数量就显得特别的繁琐,此时进程池就派上用场了。
Pool类可以提供指定数量的进程供用户调用,当有新的请求提交到Pool中时,如果池还没有满,就会创建一个新的进程来执行请求。如果池满,请求就会告知先等待,直到池中有进程结束,才会创建新的进程来执行这些请求。
下面介绍一下multiprocessing 模块下的Pool类下的几个方法
apply()
函数原型:
apply(func[, args=()[, kwds={}]])该函数用于传递不定参数,主进程会被阻塞直到函数执行结束(不建议使用,并且3.x以后不在出现)。
apply_async()
函数原型:
apply_async(func[, args=()[, kwds={}[, callback=None]]])与apply用法一样,但它是非阻塞且支持结果返回进行回调。
map()
函数原型:
map(func, iterable[, chunksize=None])Pool类中的map方法,与内置的map函数用法行为基本一致,它会使进程阻塞直到返回结果。
注意,虽然第二个参数是一个迭代器,但在实际使用中,必须在整个队列都就绪后,程序才会运行子进程。
close()
关闭进程池(pool),使其不在接受新的任务。
terminate()
结束工作进程,不在处理未处理的任务。
join()
主进程阻塞等待子进程的退出,join方法必须在close或terminate之后使用。
multiprocessing.Pool类的实例:
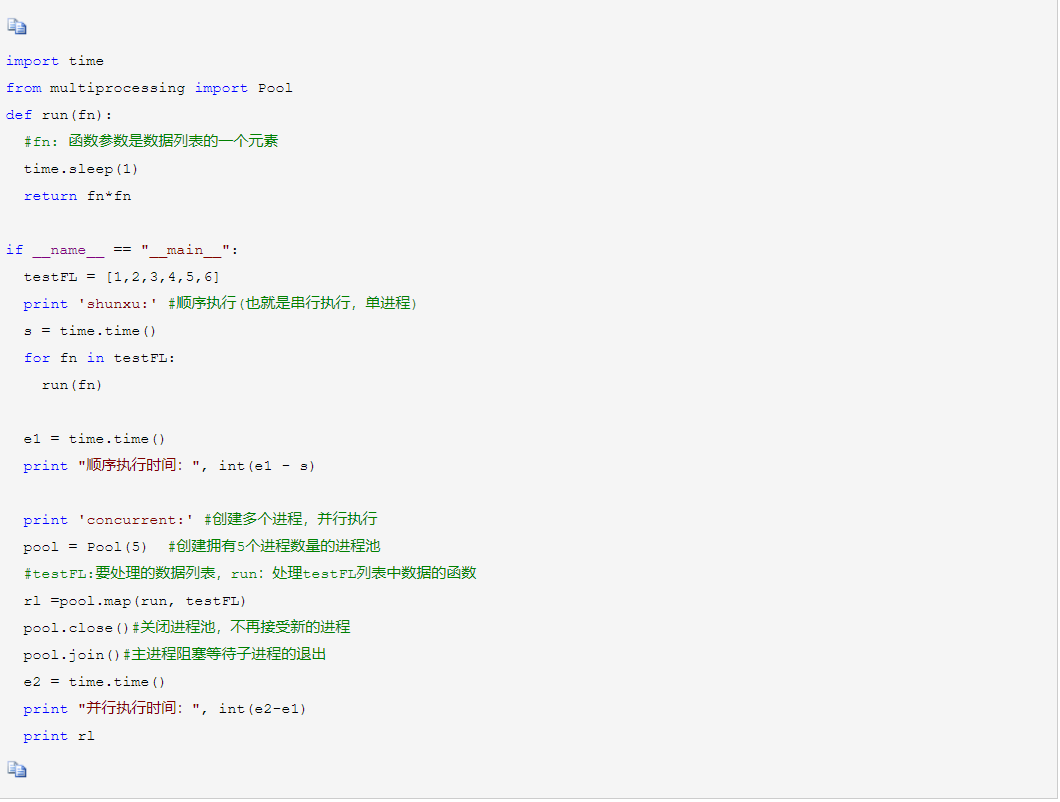
执行结果:

上例是一个创建多个进程并发处理与顺序执行处理同一数据,所用时间的差别。从结果可以看出,并发执行的时间明显比顺序执行要快很多,但是进程是要耗资源的,所以平时工作中,进程数也不能开太大。
程序中的r1表示全部进程执行结束后全局的返回结果集,run函数有返回值,所以一个进程对应一个返回结果,这个结果存在一个列表中,也就是一个结果堆中,实际上是用了队列的原理,等待所有进程都执行完毕,就返回这个列表(列表的顺序不定)。
对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),让其不再接受新的Process了。
再看一个实例:
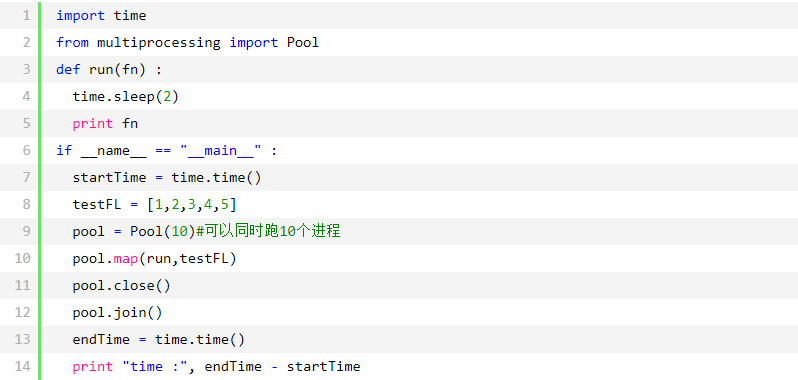
执行结果:
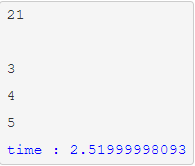
再次执行结果如下:
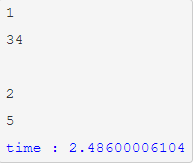
结果中为什么还有空行和没有折行的数据呢?其实这跟进程调度有关,当有多个进程并行执行时,每个进程得到的时间片时间不一样,哪个进程接受哪个请求以及执行完成时间都是不定的,所以会出现输出乱序的情况。那为什么又会有没这行和空行的情况呢?因为有可能在执行第一个进程时,刚要打印换行符时,切换到另一个进程,这样就极有可能两个数字打印到同一行,并且再次切换回第一个进程时会打印一个换行符,所以就会出现空行的情况。
在利用Python进行系统管理的时候,特别是同时操作多个文件目录,或者远程控制多台主机,并行操作可以节约大量的时间。当被操作对象数目不大时,可以直接利用multiprocessing中的Process动态成生多个进程,10几个还好,但如果是上百个,上千个目标,手动的去限制进程数量却又太过繁琐,这时候进程池Pool发挥作用的时候就到了。
Pool可以提供指定数量的进程,供用户调用,当有新的请求提交到pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来它。这里有一个简单的例子:
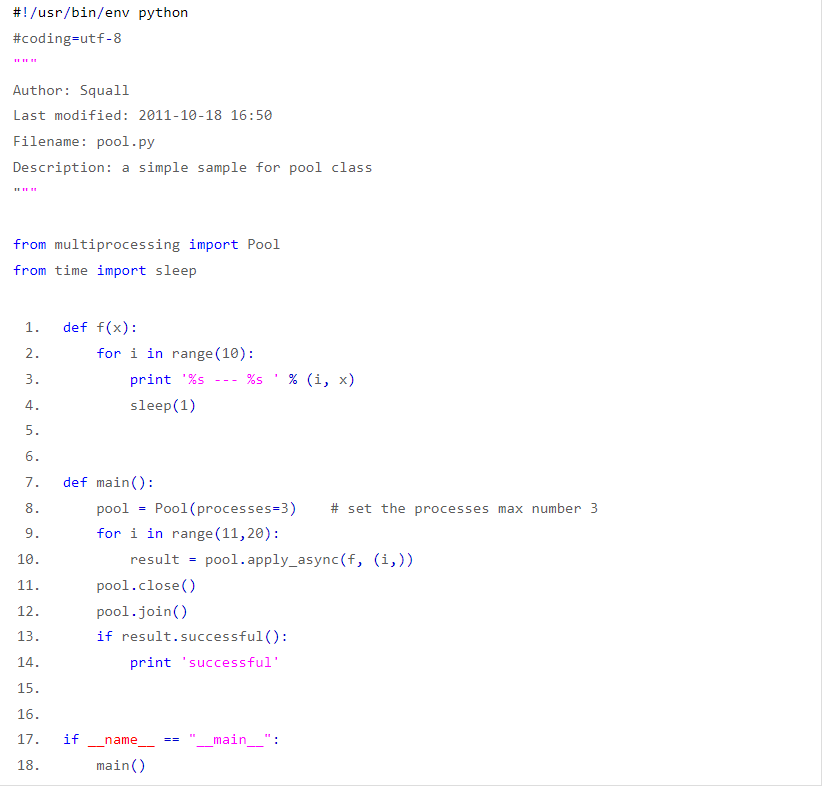
先创建容量为3的进程池,然后将f(i)依次传递给它,运行脚本后利用ps aux | grep pool.py查看进程情况,会发现最多只会有三个进程执行。pool.apply_async()用来向进程池提交目标请求,pool.join()是用来等待进程池中的worker进程执行完毕,防止主进程在worker进程结束前结束。但必pool.join()必须使用在pool.close()或者pool.terminate()之后。其中close()跟terminate()的区别在于close()会等待池中的worker进程执行结束再关闭pool,而terminate()则是直接关闭。result.successful()表示整个调用执行的状态,如果还有worker没有执行完,则会抛出AssertionError异常。
利用multiprocessing下的Pool可以很方便的同时自动处理几百或者上千个并行操作,脚本的复杂性也大大降低。
Python多进程并发操作中进程池Pool的应用的更多相关文章
- [转]Python多进程并发操作中进程池Pool的应用
Pool类 在使用Python进行系统管理时,特别是同时操作多个文件目录或者远程控制多台主机,并行操作可以节约大量的时间.如果操作的对象数目不大时,还可以直接使用Process类动态的生成多个进程,十 ...
- Python多进程并发操作进程池Pool
目录: multiprocessing模块 Pool类 apply apply_async map close terminate join 进程实例 multiprocessing模块 如果你打算编 ...
- Python多进程库multiprocessing创建进程以及进程池Pool类的使用
问题起因最近要将一个文本分割成好几个topic,每个topic设计一个regressor,各regressor是相互独立的,最后汇总所有topic的regressor得到总得预测结果.没错!类似bag ...
- Python多进程库multiprocessing中进程池Pool类的使用[转]
from:http://blog.csdn.net/jinping_shi/article/details/52433867 Python多进程库multiprocessing中进程池Pool类的使用 ...
- python学习笔记——multiprocessing 多进程组件 进程池Pool
1 进程池Pool基本概述 在使用Python进行系统管理时,特别是同时操作多个文件目录或者远程控制多台主机,并行操作可以节约大量时间,如果操作的对象数目不大时,还可以直接适用Process类动态生成 ...
- Python 之并发编程之manager与进程池pool
一.manager 常用的数据类型:dict list 能够实现进程之间的数据共享 进程之间如果同时修改一个数据,会导致数据冲突,因为并发的特征,导致数据更新不同步. def work(dic, lo ...
- python 使用进程池Pool进行并发编程
进程池Pool 当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process动态成生多个进程,但如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到mu ...
- Python 多进程编程之 进程间的通信(在Pool中Queue)
Python 多进程编程之 进程间的通信(在Pool中Queue) 1,在进程池中进程间的通信,原理与普通进程之间一样,只是引用的方法不同,python对进程池通信有专用的方法 在Manager()中 ...
- python 进程池pool简单使用
平常会经常用到多进程,可以用进程池pool来进行自动控制进程,下面介绍一下pool的简单使用. 需要主动是,在Windows上要想使用进程模块,就必须把有关进程的代码写if __name__ == ‘ ...
随机推荐
- 极路由hc5661安装tcpdump
原先有个tcpdump的插件,但是现在已经下架了. 条件: 已root的极1s HC5661 - 1.4.11.21001s 步骤: ssh进去后,opkg install http://downlo ...
- 剑指offer(44)单词翻转序列
题目描述 牛客最近来了一个新员工Fish,每天早晨总是会拿着一本英文杂志,写些句子在本子上.同事Cat对Fish写的内容颇感兴趣,有一天他向Fish借来翻看,但却读不懂它的意思.例如,“student ...
- Docker部署Bytom全节点钱包
微服务和容器目前比较流行,相信很多小伙伴都比较熟悉docker, 如果你不是太了解,可以查看文档docker学习手册.那如何用docker搭建比原链(Bytom)的节点呢? 在操作之前,请自行安装do ...
- jstack生成的Thread Dump日志线程 分析
文章转载自: https://www.javatang.com/archives/2017/10/25/36441958.html 前面文章中只分析了Thread Dump日志文件的结构,今天针对日志 ...
- (14)线程- Event事件和守护线程Daemon
<一>Event事件 线程Event基本和进程的Event语法是一样的 # wait() 动态给程序加阻塞 # set() 将内部属性改成True # clear() 将内部属性改成Fal ...
- 整合Druid数据源
pom依赖: <!--引入druid数据源--> <!-- https://mvnrepository.com/artifact/com.alibaba/druid --> & ...
- Otto.de:我为什么选择分布式垂直架构
Otto.de:我为什么选择分布式垂直架构 http://cloud.51cto.com/art/201510/493867.htm
- @RequestBody注解的参数仅仅读取一次的问题解决。
最近在写日志管理,想着使用拦截器加注解的方式,但是遇到了一个问题,就是如果使用@RequestBody注解接收的参数只能读取一次,造成了我在拦截器中如果接收了参数,在Controller层就接收不到了 ...
- 基于socket实现http请求
异步非阻塞模块原理 # 基于socket实现http请求 import socket # 多路IO复用模块 import select socket_list= [] url_list = [&quo ...
- weex playGround 扫码空白问题
首先安装 weex debug 用 weex debug调试可以看到报错 我做的demo扫码扫不出来 是因为:class的原因 weex中:class只支持数组形式 或者 换成:style就可以 ...