[java,2017-05-15] 内存回收 (流程、时间、对象、相关算法)
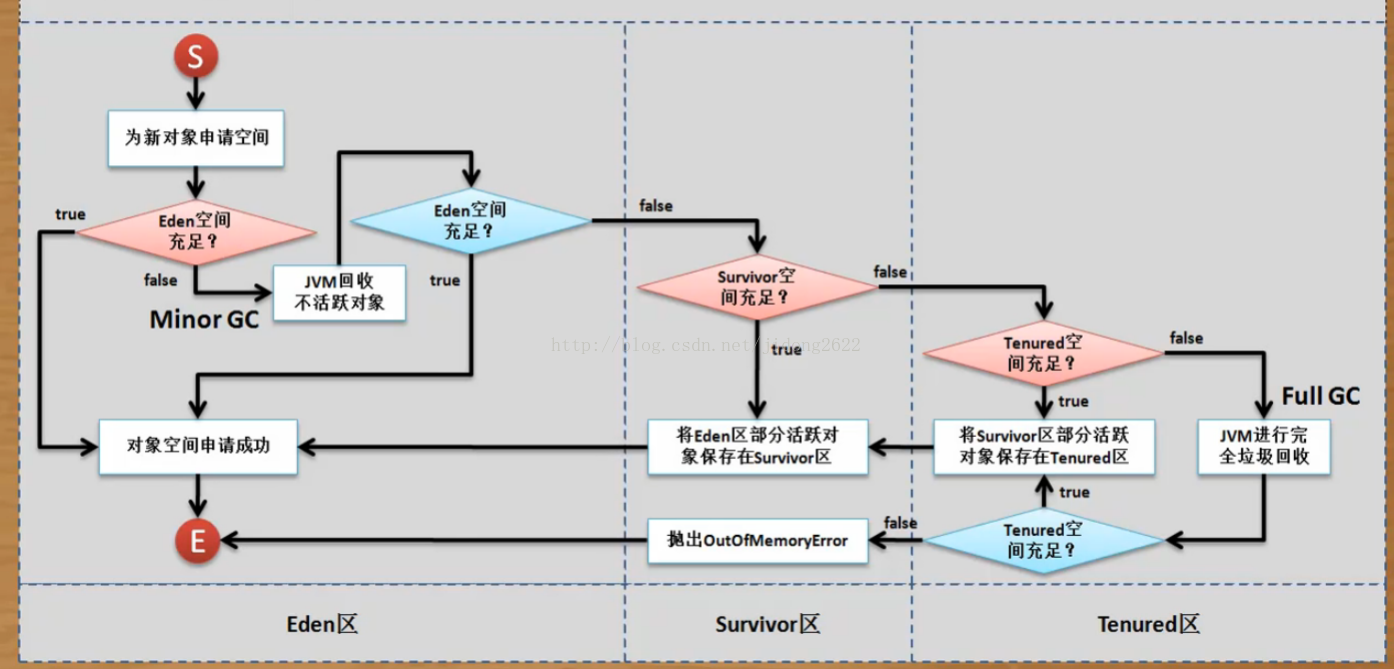
内存回收的流程
java的垃圾回收分为三个区域新生代、老年代、 永久代

一个对象实例化时 先去看伊甸园有没有足够的空间:
如果有 不进行垃圾回收 ,对象直接在伊甸园存储;
如果伊甸园内存已满,会进行一次minor gc;
然后再进行判断伊甸园中的内存是否足够;
如果不足 则去看存活区的内存是否足够;
如果内存足够,把伊甸园部分活跃对象保存在存活区,然后把对象保存在伊甸园;
如果内存不足,向老年代发送请求,查询老年代的内存是否足够;
如果老年代内存足够,将部分存活区的活跃对象存入老年代.然后把伊甸园的活跃对象放入存活区,对象依旧保存在伊甸园;
如果老年代内存不足,会进行一次full gc,之后老年代会再进行判断 内存是否足够,如果足够 同上;
如果不足 会抛出OutOfMemoryError。
内存回收的时间
java中的GC(内存回收)分为2种,minor GC 和 Full Gc(也称为Major GC)。
Minor GC 的触发条件:大多数情况下,直接在 Eden 区中进行分配。如果 Eden区域没有足够的空间,那就会发起一次 Minor GC;
Full GC(Major GC)的触发条件:也是如果老年代没有足够空间的话,那么就会进行一次 Full GC。
Ps:上面所说的只是一般情况下,实际上,需要考虑一个空间分配担保的问题:
在发生Minor GC之前,虚拟机会先检查老年代最大可用的连续空间是否大于新生代所有对象的总空间。如果大于则进行Minor GC,如果小于则看HandlePromotionFailure设置是否允许担保失败(不允许则直接Full GC)。如果允许,那么会继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果大于则尝试Minor GC(如果尝试失败也会触发Full GC),如果小于则进行Full GC。
但是,具体到什么时刻执行,这个是由系统来进行决定,是无法预测的。
内存回收的对象
主要根据可达性分析算法,如果一个对象不可达,那么就是可以回收的;如果一个对象可达,那么这个对象就不可以回收。
就像现在的汽车需要车牌号,定义一个变量的时候需要先声明,声明即可得到一个车牌号,在 new 的时候获得了一辆车,删除变量即拿走车牌号,并立即不会回收这辆车。对于没有车牌的车辆,就是一个不可达的对象,会在垃圾回收的时候回收掉(并不是删除变量名即回收此变量名所占用的空间)。
内存回收的相关算法
1、标记清除算法Mark-Sweep
这种算法是最简单最直接的算法,也是其它算法的一些最初思路。标记清除算法其实就是对内存中的对象依次的进行判断,如果对象需要回收那么就打一个标记,如果对象仍然需要使用,那么就保留下来。这样经过一次迭代之后,所有的对象都会被筛选判(防盗连接:本文首发自http://www.cnblogs.com/jilodream/ )断一次。紧接着会对内存中已经标记的对
象依次进行清除。 这个算法比较简单粗暴,实现起来比较简单。
但是会留下两个比较麻烦的问题:
(1)标记和清除需要两遍循环内存中的对象,标记本身也是一个比较麻烦的工作,因此这种算法的效率不是特别的高。
(2)对于分配的内存来说,往往是连续的比较好,因为这样有利于分配大数据的对象。倘若当前内存中都是小段的内存碎片,会知道需要分配大段内存时,没有可以放置的位置,而触发内存回收。也就是空间不足而导致频繁GC和性能下降。

2、复制算法Copying
我在使用数据库的过程中,曾经遇到这样一个问题,表中的数据量相对来说比较大,大概30万行,需要使用多个苛刻的条件删除其中的大部分数据(因此无法使用索引),而只保留其中的较少数据。常规的delete语法使用起来是超时的。于是我查看维护人员的sql,发现一个很有意思的逻辑。首先查出数据库表中需要保留的数据,放到一张临时表中。然后彻底删除掉原有的数据表。然后把这张临时创建表的表名,改为当初的表名。这是一种典型的空间换取时间的方法。而复制算法就是这样一个思路。 复制算法中,会将内存划分为两块相等大小的内存区域A/B,然后生成的数据会存放在A区,当A区剩余空间不足以存放下一个新创建的对象时,系统就会将A区中的有效对象全部复制到B区中,而且是连续存放的。然后直接清空A区中的所有对象。 由于编程语言中的对象,大部分在创建后很快就(防盗连接:本文首发自http://www.cnblogs.com/jilodream/ )会被回收掉,所以我们需要复制的对象其实并不多。 Java中的实现是这样的: Java中将Eden和Survivor区同时作为复制算法的使用区域。Survivor又分为From区和To区。这块内容可以参考我的另外一篇博客,博客中有详细的介绍:http://www.cnblogs.com/jilodream/p/6147791.html。每次GC的时候都会将Eden和Survivor的From区中的有效对象进行标记,一同复制到Survivor的To区。然后彻底清除原来的Eden区和From区的内存对象。与此同时To区就是下一次回收的From区。

复制算法的缺点: 算法使用了空间换取时间的思路,因此需要一块空白的区域作为内存对象要粘贴的区域。这无疑会造成一种浪费。尤其是内存较小时。 算法每次清除无效对象时,都要进行一次复制粘贴的对象转移,因此对使用场景是有限制的。只有在有效对象占据总回收内存是非常小的时候,这种算法的性价比才会达到最高。否则大量的复制动作所浪费的时间可能要远远大于空间换取时间得到的收益。因此这种算法在Jvm中,也只被用来作为初级的对象回收。因为这时的有效对象比例最低,算法的性价比是最高的。
3、 标记整理算法 Mark-Compact
复制算法需要一块额外的内存空间,用于存放幸存的内存对象。这无疑造成了内存的浪费。我们还可以在原有的标记清除算法的基础上,提出了优化方案。也就是标记到的可用对象整体向一侧移动,然后直接清除掉可用对象边界意外的内存。(防盗连接:本文首发自http://www.cnblogs.com/jilodream/ )这样既解决了内存碎片的问题。又不需要原有的空间换时间的硬件浪费。由于老年代中的幸存对象较多,而且对象内存占用较大。这就使得一旦出现内存回收,需要被回收的对象并不多,碎片也就相对的比较少。所以不需要太多的复制和移动步骤。因此这种方法常常被应用到老年代中。
标记整理算法的缺点: 标记整理算法由于需要不断的移动对象到另外一侧,而这种不断的移动其实是非常不适合杂而多的小内存对象的。每次的移动和计算都是非常复杂的过程。因此在使用场景上,就注定限制了标记整理算法的使用不太适合频繁创建和回收对象的内存中。

4、分代收集算法 Generational Collection
这种算法就是将内存以代的形式划分,然后针对情况分别使用性价比最高的算法进行处理。在Java中,一般将堆分为老年代和新生代。新创建的对象往往被放置在新生代中。而经过不断的回收,逐渐存活下来的对象被安置到了老年代中。越新的对象越可能被回收,越老的对象反而会存活的越久。因此针对这两种场景,新生代和老年代也会分别采用前文所述的两种算法进行清理。
相关链接:
1.https://blog.csdn.net/ni357103403/article/details/51943379
2.https://blog.csdn.net/jidong2622/article/details/78147364
3.https://www.cnblogs.com/jilodream/p/9038853.html
[java,2017-05-15] 内存回收 (流程、时间、对象、相关算法)的更多相关文章
- Java面向对象05——创建对象内存分析
- [Java初探实例篇02]__流程控制语句知识相关的实例练习
本例就流程控制语句的应用方面,通过三个练习题来深入学习和巩固下学习的流程控制语句方面的知识,设计到,if条件判断语句,switch多分支语句,for循环语句及其嵌套多层使用,while循环语句. 练习 ...
- 【读书笔记 - Effective Java】05. 避免创建不必要的对象
1. 如果对象是不可变的(immutable),它就始终可以被重用. (1) 特别是String类型的对象. String str1 = new String("str"); // ...
- 垃圾回收(GC)相关算法笔记
GC需要完成的3件事情: 哪些内存需要回收? 什么时候回收? 如何回收? 引用计数算法 给对象中添维护一个计数器,每当引用这个对象时,计数器加1:当引用失效时,计数器值减1:当计数器值为0时,表示这个 ...
- linux内存源码分析 - 内存回收(整体流程)
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/ 概述 当linux系统内存压力就大时,就会对系统的每个压力大的zone进程内存回收,内存回收主要是针对匿名页和文 ...
- (转)linux内存源码分析 - 内存回收(整体流程)
http://www.cnblogs.com/tolimit/p/5435068.html------------linux内存源码分析 - 内存回收(整体流程) 概述 当linux系统内存压力就大时 ...
- Java技术专题之JVM逻辑内存回收机制研究图解版
一.引言 JVM虚拟机内存回收机曾迷惑了不少人,文本从JVM实现机制的角度揭示JVM内存回收的原理和机制. 一.Java平台逻辑架构 二.JVM物理结构 通过从JVM物理结构图我们可以看到: 1.JV ...
- linux内存源码分析 - 内存回收(lru链表)
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/ 概述 对于整个内存回收来说,lru链表是关键中的关键,实际上整个内存回收,做的事情就是处理lru链表的收缩,所以 ...
- (转)linux内存源码分析 - 内存回收(lru链表)
原文:http://www.cnblogs.com/tolimit/p/5447448.html 概述 对于整个内存回收来说,lru链表是关键中的关键,实际上整个内存回收,做的事情就是处理lru链表的 ...
随机推荐
- 脚本自动部署及监控 web
1.编写脚本自动部署反向代理.web.nfs: I.部署nginx反向代理两个web服务,调度算法使用加权轮询 II.所有web服务使用共享存储nfs,保证所有web都对其有读写权限,保证数据一致性: ...
- [Leetcode 15]三数之和 3 Sum
[题目] Given an array nums of n integers, are there elements a, b, c in nums such that a + b + c = 0? ...
- Linux Shell基础(下)
Linux Shell基础(下) 目录 一.shell特殊符号cut命令 二.cut.sort.wc.uniq命令 三.tee.tr.split命令 四.简易审计系统 五.fork, exec, so ...
- 洛谷p1067
题目https://www.luogu.org/problemnew/show/P1067 #include<iostream> #include<cstdio> #inclu ...
- Altera FPGA SoC搭建步骤
Altera SoC 官方搭建指南: https://rocketboards.org/foswiki/Documentation/EmbeddedLinuxBeginnerSGuide 官方文档中除 ...
- FCC JS基础算法题(2):Check for Palindromes(检查回文字符串)
题目描述: 如果给定的字符串是回文,返回true,反之,返回false.如果一个字符串忽略标点符号.大小写和空格,正着读和反着读一模一样,那么这个字符串就是palindrome(回文).注意你需要去掉 ...
- leetcode题解 5. Longest Palindromic Substring
题目: Given a string s, find the longest palindromic substring in s. You may assume that the maximum l ...
- mybatis(一、原理,一对多,多对一查询)
MyBatis框架及原理分析 MyBatis 是支持定制化 SQL.存储过程以及高级映射的优秀的持久层框架,其主要就完成2件事情: 封装JDBC操作 利用反射打通Java类与SQL语句之间的相互转换 ...
- 安装jdk1.8
这是很普通的shell的脚本,只需要注意:echo 语句内出现的变量,需要转义! #!/bin/bash function get_current_time_stamp(){ echo `date & ...
- Linux系统-禁ping
1) Add the following line to your /etc/sysctl.conf net.ipv4.icmp_echo_ignore_all=1 Then : sysctl -p ...